join은 두 테이블을 합쳐 하나의 정보로 보여주는 연산이다. 테이블은 일종의 배열로 볼 수 있다. 테이블의 레코드를 자바로 따지면 객체 하나이므로, User테이블은 1급 컬렉션 같은 것이다.
조인을 어떻게 구현하는 것일까?
List U , List t가 있다. 유저가 쓴 글을 보여주고 싶으면?
u X t 테이블을 만들어서 2중 루프문 돌면서
for(user u)
for(text t)
if(u.uid = t.uid)
print(u.name t.title)
-> cross join(카테시안). 크로스 조인이 의미 있으려면 user와 text에 if문 더해줘서 같은 사용자일 때 프린트한다. 이것을 inner join이라고 한다. 이너 조인의 문제는 null이 사라지는 문제가 있었다. user가 (id기준) 1,2,3가 있고, board에 게시물의 작성자로 1,2 , null 이 있을 것이다. 이 두개를 조인하면, 작성자 3 ,4, 는 안보이고, uid가 null인 것은 의미적으로 불가능하다. 매칭되는 record가 없을 때 레코드가 사라지고 보여지지 않는다. 이것을 Inner Join이라고 한다.
반대는 Outer Join이다. 성능이 나빠질 가능성이 조금 있다. 둘다 쓸 수 있다면 잠재적 성능 문제가 없는 inner을 쓰고, 반드시 아우터를 써야할 때만 outer join을 써야한다.
조인의 복잡도는 n X m 이다. 두 테이블을 다 읽어야하기 때문이다.
테이블에서 U(n) B(m) 을 처음부터 합치는 것은 어떨까? 한 테이블로 합치는 것의
장점: 성능이 빠르다. 왜냐면 join이 필요없다. max(n,m)의 성능이다.
단점: 중복 발생, 공간낭비 있음.
처음 만들어진 1970년대엔 디스크가 $$$ 매우 비쌌다. 요즘엔 문방구에도 디스크를 팔정도로 저렴하다. 그래서 요즘 시대엔 처음부터 테이블을 합치는 것도 한가지 방법이다. (row하나가 수백개 칼럼을 갖게 되기도 한다.)
NoSql을 배울 땐 애플리케이션 설계방법을 먼저 배워야한다. join을 지원하지 않는다. 몽고db 3.0에 생기긴 하는데, 별로 좋진 않다.
좋은 테이블이란 무엇일까?
테이블이란? 코딩 객체 하나가 테이블 하나가 될 가능성이 높다. User, Question. 자바를 기반으로 생각하기에 Object하나를 테이블로 생각하는 경향이 있다. 테이블은 원자적이지 않고, 더 잘게 쪼갤수있다. 정확히는 Record도 아니고 칼럼의 값 하나를 원자적이라고 부를 수 있다. 속성 하나가 의미있는 최고 단위이다. 속성들의 집합을 테이블이라고 할 수 있다. 어떻게 묶어야 잘 묶었다고, 좋은 테이블이라고 할 수 있을까? 어플리케이션을 분석해서 무수히 많은 속성이 나왔는데 어떻게 묶어야할까? 잘묶는 방법이 정규화이다. 안전하게 잘 묶어서 테이블을 만드는 것이다. 칼럼을 묶을 때 양 극단은 1)한테이블당 속성 하나만 담고, 관계 생길때마다 foreign키 줄 때 2)테이브 하나가 어플리케이션 전체인 경우이다. 1) 2) 도 아닌 가운데 지점의 3)이 최고의 방법이다. 값만 보고 결정하는 1)정규화 2) ERD의미로 정하는 ...
1970년대부터 좋은 테이블이란, 공간효율성이 좋고, 개발자들이 실수하지 않는(구현 편의성) 테이블이다. 이를 위해 정규화가 나왔다. 잘못 설계된 테이블에선 이상 현상이 발생할 수 있따.
한 테이블 만들때 이상현상이 벌어진다.
사용자 없는 글을 넣을(pk=null)수없다. key값은 절대 null이 될 수 없다. 익명으로 하려면 가상의 사용자를 하나 넣어야한다. (삽입이상: 원하는 것을 넣기 위해 다른 것을 넣어야한다.) 삭제이상, 갱신이상 등도 존재. 갱신이상은 하나 뭐 수정시 전부 다 값을 바꿔줘야하는데, 실수하기 쉽고 비용도 크다. 삭제이상은 사용자 삭제시 게시글도 같이 삭제되는 원치않는 삭제가 발생하는 것이다. 삽입이상, 갱신이상 등이 발생하는 것을 잘못된 테이블이라고 하기에 이런일이 벌어지지않도록 테이블을 만들어야한다. 이상현상이 발생하지 않게 해주는 작업방식 중 하나가 정규화이다. 예전과 달리 그렇게 중요하진 않다. (메모리가 싸지고, 인건비가 비싸졌기 때문이다)
기본키란?
모든 엔티티는 유니크한 값이 있다. 이것을 후보키라고 하는데, 가장 적절한 것을 골라 데이터베이스 테이블의 pk가 된다. userId, 주민번호, email이 있다면, userId가 가장 무난한 pk가 될 것이다. pk로인덱스를 만들면 인덱스가 변경될일이없어서 좋다.
DB Design: 속성들을 잘 묶는 법
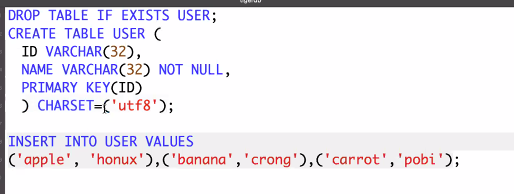
묶어서 user, board, comment 나눈다. 객체처럼 묶는 경향이 있지만 이것들을 묶으면 관계가 성립한다.
정규화한 테이블에서 원래의 정보를 복원하기 위해서는 조인이 필요하다. foeign key외래키를 가지고 얘를 참조해서 이 uid 값을 null이거나 부모 테이블의 값이어야한다. 이것을 외래키는 부모테이블의 값을가지거나 null이어야하는 것을 참조 무결성 제약조건이라고 한다.
SELECT * FROM USER;
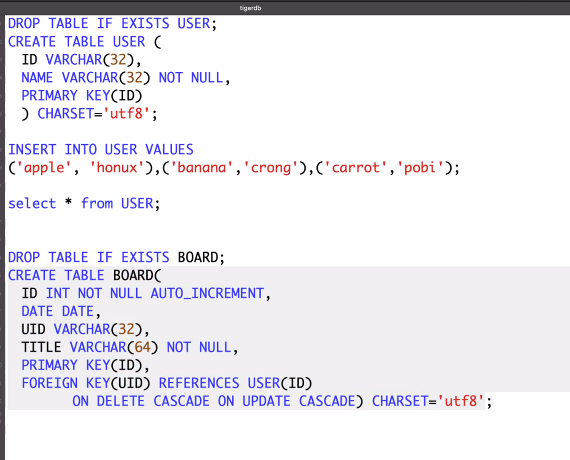
ON UPDATE CASCADE, ON DELETE CASCADE: 탈퇴/삭제해도 삭제되지 않는다.
INNER JOIN은 값이 사라진다.
JOIN조건은 ON으로 사용하고, (필터링되는게 WHERE과 동일하지만) 가독성 때문.
디폴트가
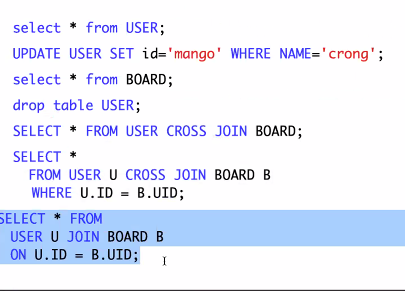
lEFT OUTER JOIN: 글 안 쓴 사람이 나옴
RIGHT OUTER JOIN: 해커의 글이 나옴
OUTER JOIN은 조인되지 않는 레코드를 보여주는 조인이다. INNER JOIN은 조인 안되는 정보는 표시 안됨. LEFT OUTER JOIN하면 왼쪽 테이블인 USER을 보여준다. RIGHT OUTER JOIN은 오른쪽의 것을 보여준다.
PULL OUTER JOIN: 전부 다, 합집합을 보여준다. MYSQL엔 없기 때문에 UNION을 해줘얗야 합집합을 볼 수 있다. 전부다 볼수있따.

보드가 훨씬 많다는 가정하에, 두 연산은 다를까? 복잡도로 따지면 N*M인데, 다르다.
왼쪽 것을 먼저 읽는다는 전제하에,
PK에 인덱스가 있다. USER테이블에 인덱스는 ID에 PK인덱스가 있다. BOARD에는 ID에 PK인덱스가 있고, UID에 FK INDEX가 있다. 두개는 다르다. SECONDARY INDEX라고 해서 PK와는 다른 인덱스이다. FK 제약조건만족하면 자동으로 인덱스가 만들어진다. 효율적인 인ㄷ게스를 한다 .
JOIN순서가 성능에 영향을 끼친다!
OUTER TALE에 PK값과 FK인ㄷ게스를 가지고 조인을 쉽게할수있다. 그리고 조인 순서는 개수에 따라 영향을 미친다. 그렇다며 ㄴDB가 INNER JOIN시 우리가 정한 순서를 지켜주지 않고, 옵티마이저를 사용해 쿼리 최적화를 해준다. 둘중 어떤 것을 먼저하는지 얘가 잘 알기 때문에 조인 순서를 얘가 정한다 .OUTER JOIN은 순서를 정해 조인할수있는데, 대체적으로 바깥쪽 테이블과 안쪽 테이블 중에 바깥 테이블이 성능을 영향을 끼치고, 어떤 것을 바깥 쪽으로 하냐도 잘 정해야한다..?? JOIN할 때는 두 테이블 중 하나는 OUTER, 하나는 INNER TABLE이 된다. 이너 조인에선 DB에서 알아서 정해주고, 아우터 조인에서는 쿼리에 따라 OUTER가 정해지기 때문에 성능에 영향을 줄 수 있다.
OUTER JOIN을 하면 조인 대상이 아니엇던, 레코드들을 볼 수 있는 (글안쓴포비와 해커) 조인이다.
외래키를 만들면 인덱스가 자동생성된다. 테이블 이상현상을 막기 위해 테이블을 나누는 것을 정규화라고 한다. 정규화 안된 테이블엔 삽입삭제갱신시 이상현상이 발생할 수 있다.
