list
v = [0,100,200,300]
v[0] == 0
v[1] == 100
v[0:1] == [0] # vector을 자른 것이기 때문에 하나의 값을 가진 벡터matrix
list of lists
m = [[0,1],[2,3]]
tuple
(a,b) = (5,6)
a,b = 5,6좌변 우변에 괄호가 없어도 같은 값이다
dictionary
사전에 단어와 뜻이 있듯이 key값과 value값이 있다.
z={'year':2021, 'month':5, 'day':5}
print(z['year']) 2021이 프린트 됨.
z['day']=1day가 1로 변경된다.
boolean
v = [0,100,200]일 때,
-
in
0 in v == True
1 in v == False -
비교 연산자
==, !=, >, <, >=, <=
조건문
- if와 else
if 0 in v:
print(x, 'is in v.')
else:
print(x, 'is not in v')- 파이썬만의 특별한 조건문
x=1
y=2\*x+5 if x>1 else -5x가 1보다크면 y는 앞의 식이고, x가 1보다 작거나 같으면 y는 -5
반복문
for i in v:
print(i)v안의 모든 원소 i에 대해 프린트 해줘라.
for each i in v, print i.
for i in v:
print(i)
print('abcd')파이썬에선 조건문, 반복문 등 콜론: 을 이용하는 문장에서 반드시 탭을 쳐줘야한다. 탭으로 띄어쓰기가 되어있어야 조건문, 반복문에 묶인다. 탭으로 띄어쓰기가 되어있지 않은 부분부터 조건문, 반복문에서 벗어난다.
조건문, 반복문 이후에 탭을 쳐주지 않으면 에러가 난다.
위의 예시에서 print('abcd')까지 for 루프에 걸려있기 때문에,
0
abcd
100
abcd
200
abcd
300
abcd
와 같은 결과가 나온다.
x=0
for i in range(11): #0~10까지의 정수들이 나열된다.
x=x+i 마지막 x는 0~10의 합으로 55가 된다.
range(11) == range(0,11)
list(range(11)) == [0 ,1,2,3,4,5,6,7,8,9, 10]
[ x+str(y+1) for x in ['a', 'b', 'c', 'd'] for y in range(3) ]대괄호 사이에 있는 것은 리스트를 만드는 것이다.
규칙이 존재하는 원소들을 가진 리스트를 만들기 위해서 위의 방법을 사용한다.
y를 스트링으로 변환해 x에 붙여준다. x는 abcd란 스트링 리스트 안에 있는 값들을 가진다. y는 range 3 이란 숫자들의 값을 갖는다.
결과는 다음과 같다.
['a1', 'a2', 'a3', 'b1', 'b2', ~~~ 'd3']
함수만들기
def isABiggerThanB(a,b):
if a>=b:
print('yes, a is bigger than or same as b')
else:
print('no, a is smaller than b')
return a>=bTrue, False 중 하나가 리턴될 것이다.
def sumTwoNumbers(a,b):
return a+bprint(sumTwoNumbers(1,2))3이 프린트 된다.
- 람다로 함수 정의할 수 있다.
sumTwoNumbers=lambda a, b: a+b
sumTwoNumbers(1,2)Numpy
-
파이썬에는 모듈이란 것이 존재한다. 파이썬 자체의 기능이 아니라, 라이브러리처럼 파이썬을 이용해 새로운 기능을 만들어줄 수 있다. 새로운 함수, 새로운 클래스를 만들 수 있다. Numpy란 기능들의 모음, 도구상자를 오픈소스로 공개해뒀다. 수학적인 것, 매트릭스 계산 등에 쓰인다.
-
import numpy as np
-
array사용하기
vec=np.array(v)
#list형태의 v를 array로 바꿔서 사용할 것이고, 이름은 vec이다.
print(vec)
# [0 100 200 300 ]와 같이 콤마가 사라지고 벡터의 형태가 나타난다.
vec.sum()
#벡터의 모든 값을 더해주는 기능, 결과는 600
vec.mean()
#벡터의 평균, 결과는 150.0
vec[2:].sum()
#200, 300의 합.np의 array함수를 이용해라. list와 같은 선상의 데이터 형태를 나타내는 방식이 array이다. list보단 numpy의 array가 np의다른 벡터 계산 기능을 활용할 때 편리하다.
- matrix 사용하기
m=[[1,2],[3,4]]
mat=np.array(m)
mat[0] #결과는 [1 2]. 가로로 첫번째 줄, 첫 행
mat[0,0] #결과 1
mat[0,1] #결과 2np.array(m)을 한 결과 mat은, 우리가 알고있는 매트릭스의 형태이자, 컴도 매트릭스란 것을 인식하고 있다. mat을 프린트하게 되면
[[1 2][3 4]] 와 같이 된다.
mat.sum() # 결과는 모든 원소의 합인 10
mat.sum(axis=0) #결과는 [4 6]으로 1+3, 2+4 세로방향합
mat.sum(axis=1) #결과는 [3 7]으로 1+2, 3+4 가로방향합axis가 축이므로, 세로방향을 axis=0이라고 한다. 가로방향은 axis=1.
mat.T #matrix에서 2X2 array로 transfer 된다..?
#결과 array([[1,2],[3,4]])
mat.ravel() #다차원 array 차원을 축소해준다. 결과적으로 array([1,2,3,4,])
v1=[1,2,3]
v2=[4,5,6]
z=np.c_[v1,v2]
y=np.r_[v1,v2] c_ 함수는 두개의 칼럼을 묶어서, 3*2 행렬을 만들어준다. column bind.
1열에 v1의 3개 값이 오고, 2열에 v2의 3개 값이 와서
[[1 4]
[2 4]
[3 6]] 의 결과가 된다.
r_함수는 row bind 해줘서, [1 2 3 4 5 6]을 만들어준다. z.shape # (3,2) 3*2 행렬이란 것을 알려준다.
z.shape[0] # 결과 3
z.shape[1] # 결과 2
매트릭스 모양을 확인할 수 있다.
- 그 외
np.arrange(5) #결과 [0 1 2 3 4]
np.array(range(5)) # 위와 동일한 것이다.
np.linspace(0,4,5) # 0부터 4까지 5개로 쪼갠 array를 뱉어라.
np.zeros(1) # zeros: 0으로만 이뤄진 벡터, 괄호 안은 차원
np.zeros(5)
np.ones(1) #1이 하나인 벡터 [1]
np.ones(5) #1이 다섯개인 벡터 [1 1 1 1 1]
np.sqrt(2) #2의 square root
np.sqrt([1,2,3,4]) # 각 원소의 square root
np.log(2)
np.exp(2)- random number generator
시뮬레이션을 할 때 유용하다.
np.random.rand(2,3) # 2행, 3열로 랜덤 숫자를 6개 뱉어준다. 각 숫자는 0~1 사이 랜덤 숫자다.
np.random.randn(2,3) # standard normal로 2행3열 매트릭스를 만들어준다.
np.random.seed(1234)
np.random.randn(2,3)
np.random.seed(1234)
np.random.randn(2,3)
- seed: seed가 없으면 매번 랜덤 시행마다 랜덤으로, 독립적으로 숫자를 내놓는다. seed를 정해주면, random이 실행될때마다 같은 랜덤 숫자가 만들어진다.
Pandas
- dataframe이다. 엑셀 스프레드시트와 비슷하다. 이런 데이터 형태를 데이터프레임이라고 하는데, 이런 데이터 형태로 작업할 때 사용하는 도구를 모아두었다.
- numpy 기반으로 만들었기에 numpy와 호환이 잘된다.
- import pandas as pd
np.random.seed(1234)
df=pd.DataFrame(np.random.randn(20,4), index=np.arrange(101,121),columns=['a','b','c','d'])pd에서 DataFrame을 만들어라
20*4 행렬의 랜덤 넘버를 만들어라,
인덱스는 101~121까지의 숫자를 집어넣어라.
각 (20*4 행렬의 4열) 컬럼 이름은 알파벳 ABCD로 해라.
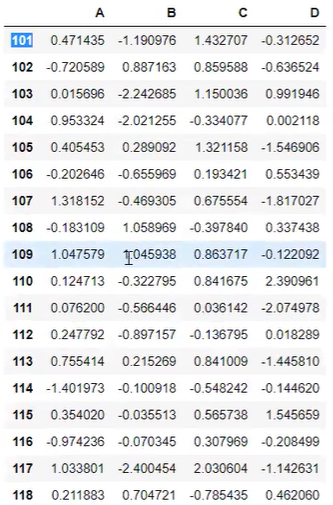
이런 결과가 나온다.
type(df)하면 pandas.core.frame.Dataframe으로 타입 결과가 나온다.
df.dtypes각 칼럼이 어떤 값으 ㄹ갖고 ㅣㅇㅆ는지 알려준다. 모두 유리수이기 때문에 abcd 모두 float64(64자리 유리수)를 갖는다고 나온다.
df['a']
df.a둘다 a칼럼만 가져올수있다.
df.[0:3]df역시 2차원 이기 때문에 어떻게 나올지 확인해야하는데, 이 경우 3개의 row가 나온다. 101~103행까지 나오고, abcd열 모두 나온다.
df.loc[101,'a']
df.iloc[0,0]
df.at[101,'a']
df.iat[0,0]모두 101행 a열을 선택하는 방법이다. row name과 column name을 사용해서 가져올 수가 있고, i가 붙은 애들은 숫자를 해서 1행1열을 index로 치환해서 0행0열로 가져올 수 있다. loc과 at은 서로 왅전히 동치이고 iloc과 iat도 그렇다.
df.[df.a>0]
dfA=df.[df.a>0]
df.loc[df.a>0]df중에서 df의 a가 0보다 큰 값들만 subset으로 가져오라고 한다. 결과를 살펴보면 a열의 값들만 전부 양수인 값들이고, bcd열에는 여전히 음수값들이 남아있다. a가 양수인 row들만 선택해 subset을 만든 것이다. 둘째줄과 같이 새로운 서브셋으로 받아와서 사용할 수도 있다.
df['e']=df.a+df.ba와 b칼럼을 합친 새로운 e칼럼을 만들고 싶다.
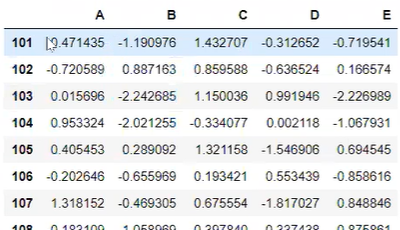
결과는 이렇다. 아직 e칼럼이 존재하지 않기 때문에, df.e와 같이 사용하면 안된다. 새로운 칼럼을 생성하기에 df.['e']와 같이 대괄호로 감싸줘야한다.
- 데이터 다룰 때 크기가 아주 큰데, 일부만 확인하고 싶다.
df.head() #위에 5줄?정도만 보여줌.
df.head(10) #10줄 보여줌
df.tail() # 끝에서 4줄
df.tail(10) # 끝에서 10줄. head, tail모두 max값이 있다.
df.columns # column 명들을 Index로 받아준다.
df.describe # count, mean, std 등 요약정보 알려준다.
df.sort_values('a') # a값 기준으로 오름차순으로 정렬한다.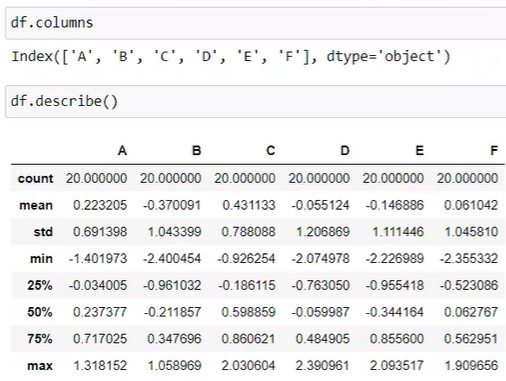
matplotlib
- 그래프 그릴때 자주 사용되는 모듈이다.
- import matplotlib.pyplot as plt
plt.plot(df.a) # df.a을 플롯하라하면, 가로 인덱스로 값이 변하는 것을 보여준다.
plt.scatter(df.a, df.b) 가로축 a 세로축 b로하는 스캐터 플롯을 보여준다. 