ViT(Vision Transformer)는 이미지 분야에서 Transformer 구조를 이용한 최초의 논문입니다. 기존에는 Convolutional networks로 이루어진 모델들이 computer vision 분야에서 사용되고 있었는데, ViT를 기점으로 self-attention 기법을 활용한 모델들이 많이 탄생하였고 현재도 그 추세가 이어지고 있습니다. ViT는 자연어 분야에서 주로 사용되던 BERT Transformer 구조를 메인으로 차용한 점을 참고하시면 이해에 더 도움이 될 것입니다.
Introduction
Transformer에서 사용되는 Self-attention 기반 모델 구조는 자연어 처리 분야에서 가장 많이 사용되고 있습니다. Transformer의 계산적 효율성과 확장성 덕분에 100B보다 큰 parameter를 가진 큰 모델들을 학습하는 것이 가능해졌습니다. (GPT-4는 무려 1.7 trillion parameters를 가집니다.) 이러한 Transformer에 영감을 받아 이미지에 이를 사용해보는 것을 고안하였고, 자세한 방법은 아래에서 소개하겠습니다.
하지만 Transformer는 Inductive bias들이 부족하다는 단점이 존재합니다. 따라서 불충분한 양의 데이터들로는 좋은 성능을 낼 수 없습니다. 하지만 pre-trained 모델을 fine-tunning하는 방법을 통해서 비교적 적은 데이터로도 ViT를 사용할 수 있습니다.
Method
Model Overview
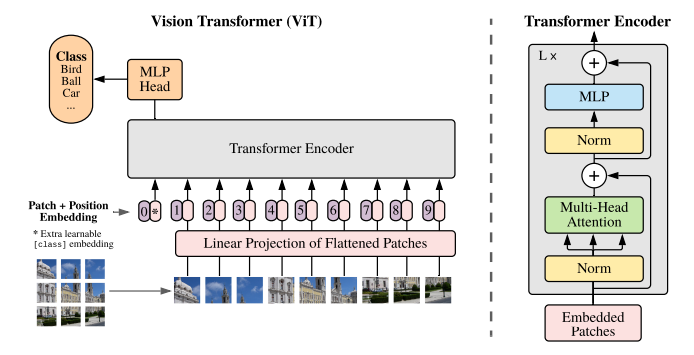
- 모델에 이미지를 input으로 넣을 때, 이미지를 고정된 사이즈의 패치들로 나누는 작업을 먼저 수행합니다.
- 패치들을 각각 선형적으로 임베딩하여 Transformer encoder에 넣어줍니다. 임베딩 시에 position embedding 기법을 같이 사용합니다.
- classification을 수행하기 위해서, 추가적으로 학습 가능한 ‘classification token’을 시퀀스에 추가하였습니다. 위의 그림에선 0번째 패치에 해당합니다.
Vision Transformer(ViT)
기존 트랜스포머에서는 input을 1차원의 token embedding sequence로 받았습니다. 하지만 2차원인 이미지를 input으로 받기 위해서는 이미지를 reshape하는 과정이 필요하였습니다. 이미지를 고정된 크기의 패치들로 쪼갠 후에 각각의 패치를 1차원으로 flatten시켜 ViT에 input으로 넣어주게 됩니다. 즉 이미지를 쪼개서 만든 패치들이 NLP에서의 token들과 같은 의미를 띄게 됩니다.
- : 이미지의 resolution(height, width) 및 채널의 수
- : 이미지 패치의 resolution
- : 패치의 개수
BERT에서의 class token과 같이, 학습 가능한 임베딩을 첫 번째 패치에 추가하였습니다. 해당 임베딩은 Transformer encoder의 output으로, image representation 를 나타냅니다. pre-training과 fine-tuning 시에 모두 classification head가 에 해당하는데, pre-training 시에는 1개의 hidden layer로 이루어진 MLP에서 이용되고 fine-tuning 시에는 1개의 single layer에서 이용됩니다.
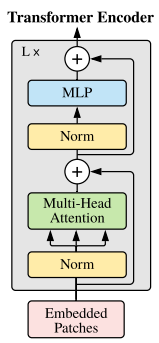
최종적인 Transformer block의 수행 과정을 수식으로 표현하면 다음과 같습니다.
- : Multihead Self Attention layer
- : 2개의 layer와 GELU non-linearity 사용
- : LayerNorm, 모든 block 전에 LayerNorm 사용
- 모든 block이후에는 residual connection 사용
Multihead Self-Attention
기존 qkv self-attention과 거의 동일한 방법입니다.
- : input sequence
- = query와 key의 행렬 곱
input seqence인 에 대하여 query, key, value를 나눕니다. 이후 attention wights인 는 query 와 key 의 pairwise similarity를 기초하여 만들어집니다. q와 k의 행렬곱에 스케일을 거친 후, softmax를 거쳐서 attention matrix인 A를 얻습니다. 마지막으로 A와 v의 weighted sum과의 행렬 곱으로 나온 결괏값이 Self-Attention matrix 가 됩니다.
Multihead self-attention은 위에서의 self-attention의 연장 버전입니다. k개의 헤드에서 self attention을 병렬적으로 수행한 후에 concatenated outputs들을 project합니다. (B x heads x N x Dim_heads → B x N x D)
Experiments
Results
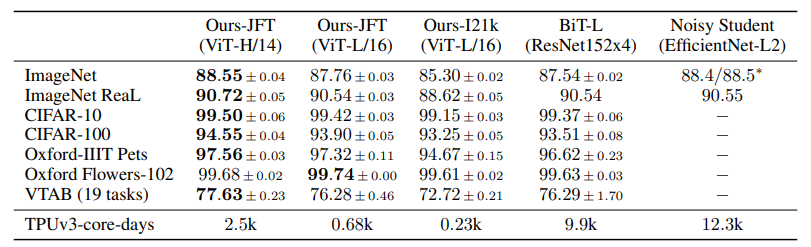
논문에 기재된 image classification accuracy입니다. 당시의 SOTA 모델들과 비교하였을 때 더 좋은 성능을 보여주고 있음을 확인할 수 있습니다. 이때 JFT는 구글에서 내부적으로 사용하는 JFT-300M dataset을 의미하며, 이름에서도 알 수 있듯이 약 3억 개의 이미지로 이루어진 거대한 데이터셋입니다.
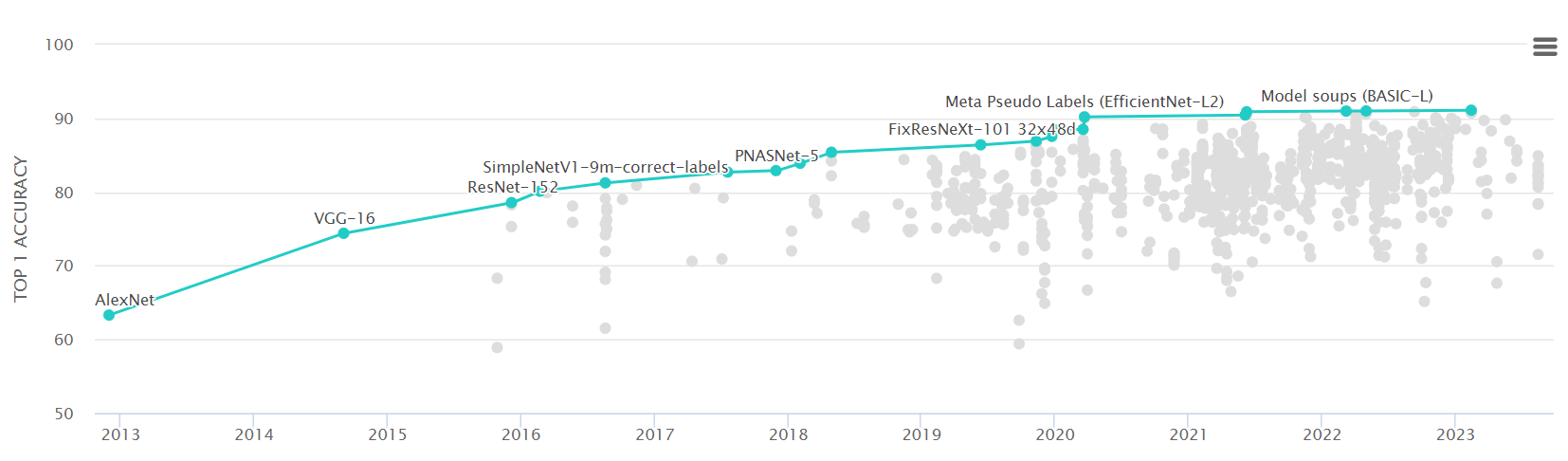
또한 현재 ImageNet Benchmark 데이터셋에서 가장 높은 accuracy를 보여주는 top 10 모델 모두 transformer 구조를 활용하고 있습니다.
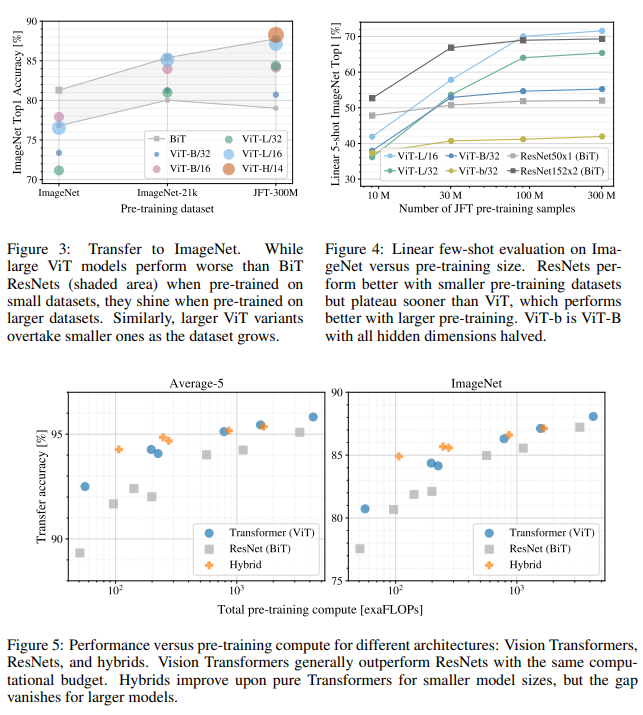
ViT는 많은 양의 데이터셋에서 좋은 성능을 보입니다. 즉 적은 양의 데이터셋에서 pre-training할 경우, BiT ResNets보다 좋은 성능을 내지 못하게 됩니다.
반면 attention 기법을 사용했기 때문에 연산 효율성이 ResNet 모델보다 월등히 뛰어나다는 점도 제시하고 있습니다.
Inspecting ViT
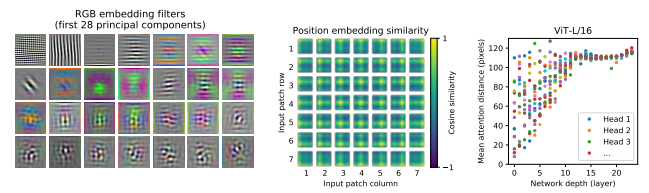
(1) RGB embedding fileters
ViT의 첫 번째 layer인 linear layer를 분석하였습니다. 해당 레이어는 flattened patch들을 낮은 차원으로 projection할 때 사용됩니다. 해당 필터들을 시각화하여 보여지는 구성 요소들이 마치 CNN에서 보여지는 lower dim에서의 필터 모습과 흡사한 점을 확인할 수 있습니다.
(2) Position embedding simliarity
projection 이후 position embedding을 patch들에 더하는 과정에서, 이미지 내의 거리를 기반으로 position embedding의 유사도를 시각화하였습니다. 거리가 가까운 패치들일 수록 유사한 position embedding을 나타내는 것을 확인할 수 있습니다. 또한 같은 행/열에 해당하는 패칭들도 유사한 embedding을 가지고 있습니다.
(3) Size of attened area and Network depth
Network depth에 따라 attention distance를 측정한 그래프입니다. attention distance는 attention weights에 기반하여 측정되었고 CNN에서의 receptive field size와 유사한 개념입니다.
초기 레이어에서 Average attention distance가 매우 다양하게 나타나는데, 특정한 부분에서는 초기 레이어임에도 불구하고 이미지의 대부분을 반영하고 있는 반면 특정 head에서는 일관성 있게 작은 attention distance를 나타내기도 합니다. 레이어가 깊어질수록 attention distance는 모든 head에서 증가합니다.
- Attention Maps

output token을 input space에 넣어 attention을 표현한 Attention map입니다. 모든 heads에서의 attention weights를 평균화하고, 재귀적으로 weights matrices를 곱하는 방법으로 map을 계산하였습니다. Attention Rollout은 추후 자세하게 다룰 예정입니다.
Appendix
Inductive bias
학습으로 얻는 bias와 달리 모델이 정확한 예측을 하게 하기 위한 추가적인 가정을 의미합니다. CNN은 지역 특성(locality), translation eqivariance 등을 가정하여 합성 곱 연산이 이루어지는 반면, Transformer는 attention 기법으로 데이터 요소 간의 관계를 파악하는 연산이 이루어집니다. 따라서 Transformer로 이미지 데이터를 다루게 될 경우, CNN에 비해 Inductive bias가 부족하다고 볼 수 있습니다. Introduction에서 소개했던 것처럼, Inductive bias가 부족하다는 단점은 충분한 scale로 ViT를 pre-training한 후에 적은 데이터들로 fine-tunning하는 방법을 통해서 해결하였습니다.
Position Embedding
Position Embedding은 이미지의 위치 정보를 인코딩하기 위해서 사용된 기법입니다. Transformer는 1차원의 임베딩 벡터를 input으로 받기 때문에, 이미지를 쪼개 만든 patch들을 flatten하여 1차원의 벡터로 만드는 과정이 요구됩니다. 벡터를 1차원으로 펼쳐버리니, 2차원인 이미지의 공간 정보를 잃어버리게 되는 것입니다. 따라서 Position Embedding 벡터들을 1차원의 패치들에 더하여 이미지의 위치 정보를 유지할 수 있습니다.
(1) 1-dimensional positional embedding (default)
input을 raster order sequence로 고려하여 1차원으로 positional embedding을 구현하였습니다.
(2) 2-dimensional positional embedding
input을 이미지의 그리드로 고려하여 X-embedding과 Y-embedding을 나누어 positional embedding을 구현하였습니다.
(3) Relative positional embeddings
패치간의 상대적인 거리를 이용하여 positonal embedding을 구현하였습니다. attention mechanism 시에, 추가적인 original query와 positional embeddings을 key로 활용하여 추가적인 attention 연산을 수행하고 bias로 취급하여 main attention logis에 추가하는 방식입니다.
Self supervision
Self-supervised learning은 라벨링되지 않은 데이터셋을 이용해 해당 데이터셋에 대한 전반적인 pre-training을 하는 학습 방법입니다. pre-training 후에는, downstream task에 라벨링된 작은 데이터셋으로 fine-tunning이 이루어집니다. 많은 양의 데이터들을 라벨링하지 않고도 pre-training이 가능하다는 장점을 가지고 있습니다. ViT에서는 BERT에서 사용하는 masked patch prediction을 따서 self-supervisied learning을 진행하였습니다.
50%의 패치 임베딩들 중 80%는 [mask] embedding, 10%는 random other patch embedding, 10%는 가만히 놔두는 방식으로 masked prediction을 진행하였습니다.
학습 방법 및 세팅들은 논문에서 자세하게 설명하고 있으며, 참고해보시면 좋을 것 같습니다.
Reference
[1] Google Research (2021), “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”, https://arxiv.org/pdf/2010.11929.pdf
[2] Samira Abnar, Willem Zuidema (2020), “Quantifying Attention Flow in Transformers”, https://arxiv.org/pdf/2005.00928.pdf
[3] Google AI Language (2018), “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, https://arxiv.org/pdf/1810.04805.pdf
[4] Paperswithcode, Image Classification on ImageNet, https://paperswithcode.com/sota/image-classification-on-imagenet
