데이터 통합 : 조직의 서비스와 시스템에 필요한 모든 데이터를 사용할 수 있게 하는 것(데이터를 정보로 바꾸는 작업)
ETL : 관계형 데이터 웨어하우스에 데이터를 채워 넣는 한정된 개념
지금부터 하는 내용 ETL을 일반화 시킨 것
데이터 웨어하우스 : 사용자의 의사 결정에 기초를 제공하기 위해 기간계 데이터베이스에 축적된 데이터를 일정한 형식으로 가공하여 관리하는 데이터베이스
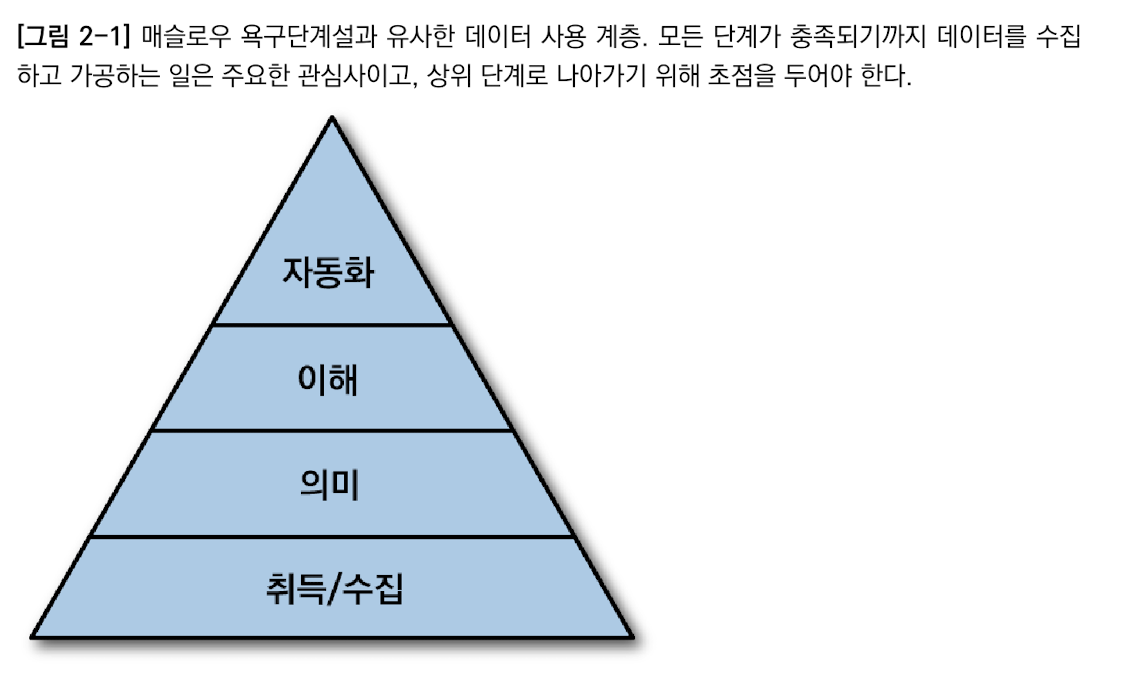
결국, 관건은 조직의 데이터 시스템 전반에 걸쳐 어떻게 신뢰성 있는 데이터 흐름을 구축할 것인가 하는 점
2.1 데이터 통합: 두 가지 문제
데이터 통합을 어렵게 만드는 대표적인 두 가지 트렌드
2.1.1 데이터는 의외로 다양하다
요즘 기업들이 가진 이벤트 데이터 : 현재 상태 → 발생한 사건을 기록
사물인터넷은 물리적인 기기를 디지털 세계와 연결하려는 흐름을 대변
이벤트 데이터는 트랜잭션 데이터와 비교하면 계산 차수가 몇 단계 높으므로 기본의 데이터 통합 방식과는 근본부터 다르다
2.1.2 전문 데이터 시스템의 폭증
전문 데이터 시스템 : OLAP, Elasticsearch(검색), rethinkdb(간단한 온라인 스토리지), hadoop(일괄처리), graphlab(그래프 분석) 등이 특화된 솔루션
2.2 로그 구조의 데이터 흐름
로그 : 시스템 간 데이터 흐름을 다루기 위한 데이터 구조
조직의 데이터를 모두 취합하여 실시간 구독이 가능하도록 중앙 로그에 넣는다
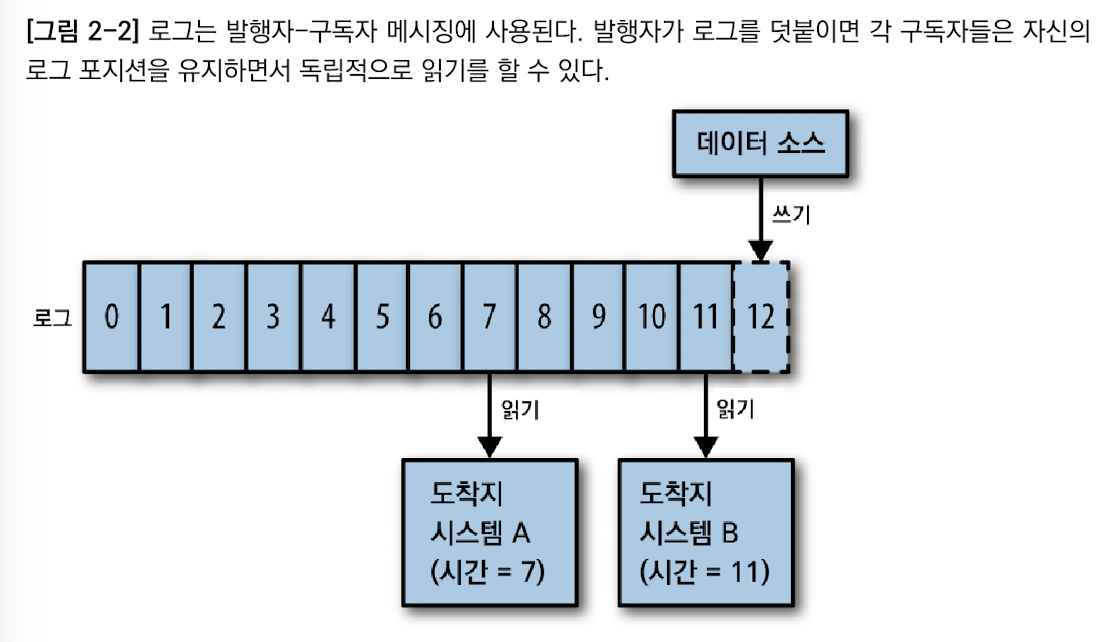
로그 : 개념적으로 구독 시스템에 적용할 변경 사항에 대한 논리적인 시간
구독 시스템 각각에 마지막으로 읽은 시간이 저장되어 있으므로 구독 시스템 상호의 동기화 문제는 아주 간단히 해결된다.
로그 : 데이터 생산 시점과 소비 시점을 비동기화하기 위한 버퍼 기능도 함
구독 시스템에 장애가 나서 가동이 일시 중단되었을 때 북구가 완료되면 중단되었던 시간만큼 따라잡아야 하는데, 시스템마다 컨트롤 가능한 데이터 소비 속도가 제각각이다.

여기서는 “메시징 시스템” 이나 “발생/구독” 대신 “로그”라는 용어를 씀
데이터 복제를 실제 구현 하는데 필요한 장치
로그 : 지속성이 보장된, 엄격한 정렬 개념을 찾춘 메시징 시스템의 한 유형
분산 시스템에서는 원자적 방송이라는 끔찍한 이름으로 부르기도 함
로그 : 여전히 인프라이다
데이터 흐름을 마스터하기 위해서는 메타데이터, 스키마, 호환성, 데이터 구조와 진화에 대해 더 알아야 함
2.3 링크드인에서 나의 경험
링크드인 에는 여러가지 주요 데이터 시스템이 있었음

소스 데이터 베이스와 로그 파일에 눈길을 돌려 키-값 저장소에 데이터를 적재하는 파이프라인을 새로 구현에 성공
첫째, 신규 처리 시스템에서 데이터를 사용할 수 있게 함. 이전에 힘들었던 새 데이터 연산이 가능, 과거에 특정 시스템에 묶여있던 수많은 데이터 조각들을 한데 모아 새로운 제품 개발과 분석에 활용할 수 있게 됨
둘째, 데이터 파이프라인이 탄탄히 뒷바침되어야만 확실한 데이터 적재가 가능함. 필요한 데이터 구조를 모두 손에 넣은 상태에서는 더 이상의 수작업이 필요 없이 데이터가 소스의 컬럼에 맞게 자동 생성됨
셋째, 데이터 커버리지는 여전히 매우 낮은 수준
수집 개의 이르는 데이터 시스템과 저장소에 대해 각각의 소스와 목적지별로 데이터를 파이프라인으로 연결하면 아래 모습(다연결시 최대 O(N^2) 파이프라인)
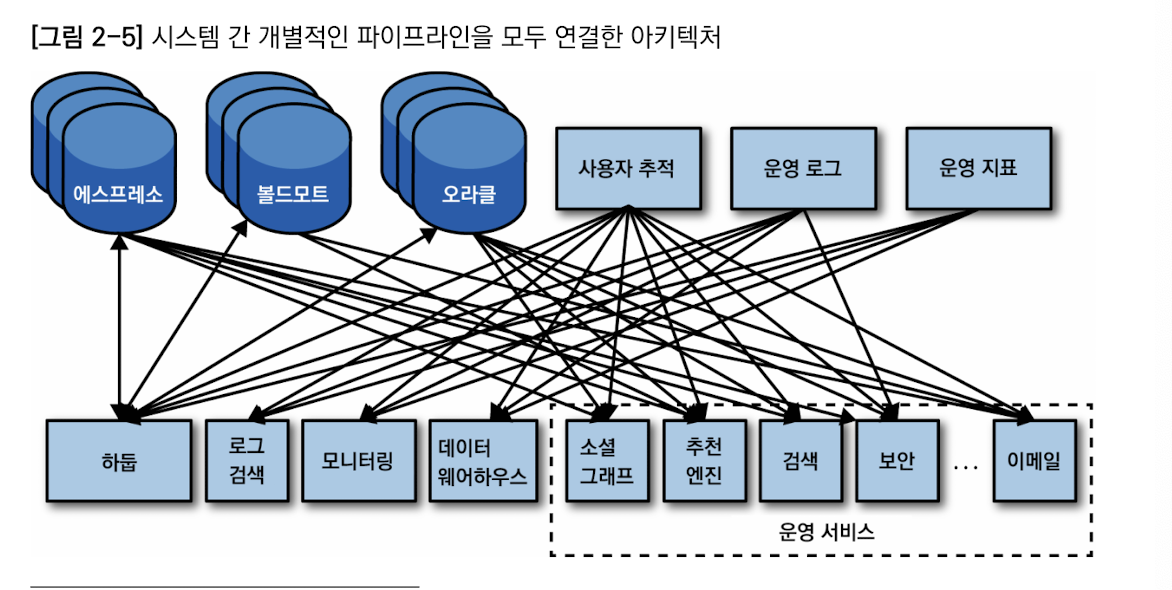
아래와 같은 뭔가가 절실함
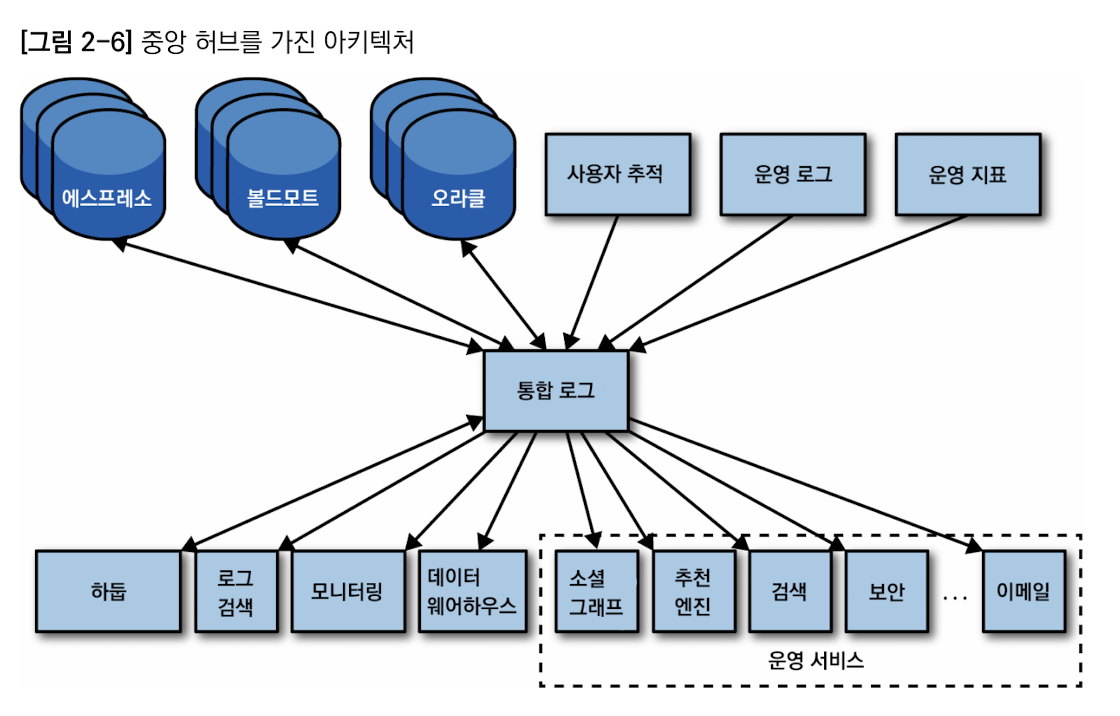
데이터 소비 시스템을 데이터 소스와 가능한 한 분리.
소비 시스템을 모두 단일한 데이터 저장소에 통합시켜 전체 소스 데이터를 바라볼 수 있게한다면 이상적일 것
소스든 타겟이든 데이터 시스템을 새로 추가할 때, 각 소비 시스템을 일일이 연결하는 것이 아닌 하나의 파이프라인에 연결
데이터베이스와 분산 시스템 내부 구현에 널리 활용된 로그 개념을 이용한 메시징 시스템 : 카프카!!!
다음에 계속~~
