지금까지 지점 간 데이터를 복사하는 잡다한 방법
로그는 다른 말로 스트림이고 스트림 처리의 핵심
스트림 처리?
- 클러스터 RPC 레이어?
- 비동기 메시지 처리 시스템?
- 전체 데이터를 즉시 처리 후 폐기하는 모델?
스트림 처리는 SQL과 무관하며 실시간 처리에 국한된 개념도 아니다. 스트림 데이터는 오래 전에 있던 데이터여도 처리 못할 이유가 없고 원본 데이터는 어떠한 일이 있어도 폐기해선 안된다.
스트림 처리 : 연속적인 데이터를 처리하기 위한 인프라. 연산 모델은 맵리듀스나 다른 분산 처리 프레임워크처럼 일반적일 수 있으나, 신속하게 결과를 산출할 수 있어야 함
데이터를 수집하는 방법이 이 처리 모델의 진정한 동인이다.
배치로 수집된 데이터는 배치로 처리. 데이터가 연속적으로 수집된다면 연속적으로 처리
대규모 덤프를 처리할 유일한 방법 : 배치!!
배치 처리를 연속적인 피드로 교체하면 자연스럽게 연속적인 처리를 지향, 필요한 처리 자원을 균등하게 배분하고 지연 시간을 단축
현대 웹에는 배치 데이터 수집이 전혀 필요없음. 웹 데이터는 활동 데이터나 데이터베이스 변경 중 하나, 이들은 모두 연속적으로 발생함.
어떤 비즈니스라도 언제나 실시간으로 발생하는 이벤트, 즉 연속적인 프로세스.
데이터를 배치 수집한다는 건 수작업으로 처리하는 단계가 남아있거나 디지털화가 덜 되었다는 소리. 아니면 과거의 습관과 관행 때문.
어떤 종류는 스트림 처리가 불가능하고 배치 처리해야한다고 주장함. 예로 통계치를 계산 하는 경우. 하지만 스트림에서도 문제 없다. 윈도 내부에서 블로킹 연산을 할 수 있도록 윈도윙의 정확한 의미를 부여하는 것
일반적인 스트림 처리 : 블로킹/논블로킹 연산 여부와 무관, 단지 처리할 기반 데이터에 시간 개념이 포함된 처리로, 처리할 데이터의 정적인 스냅샷은 필요하지 않다. 즉, 스트림 처리에서는 데이터 끝에 도달할 때까지 마냥 기다리지 않고, 사용자가 임의로 설정한 빈도에 맞춰 결과를 산출.
스트림 처리 : 배치 처리를 일반화시킨 것, 실시간 데이터가 대부분인 환경에서 매우 중요한 일반화
스트림 처리에서 중요한 몇 가지 기술적인 문제들이 로그를 이용하면 해결 가능. 그중 실시간 다중 구독자 데이터 피드 환경에서 데이터를 사용할 수 있게 해주는 로그는 정말 고마운 해결사
3.1 데이터 흐름 그래프
스트림 처리가 흥미로운 점 : 처리 시스템의 내부 구조와는 상관 없고, 데이터 피드의 대상을 확장하는 방법.
피드 : 주요 데이터의 로그. 다른 피드로부터 계산된 피드 포함. 소비 측에서는 파생된 피드가 계산 소스인 주 데이터 피드와 똑같은 부류처럼 인식
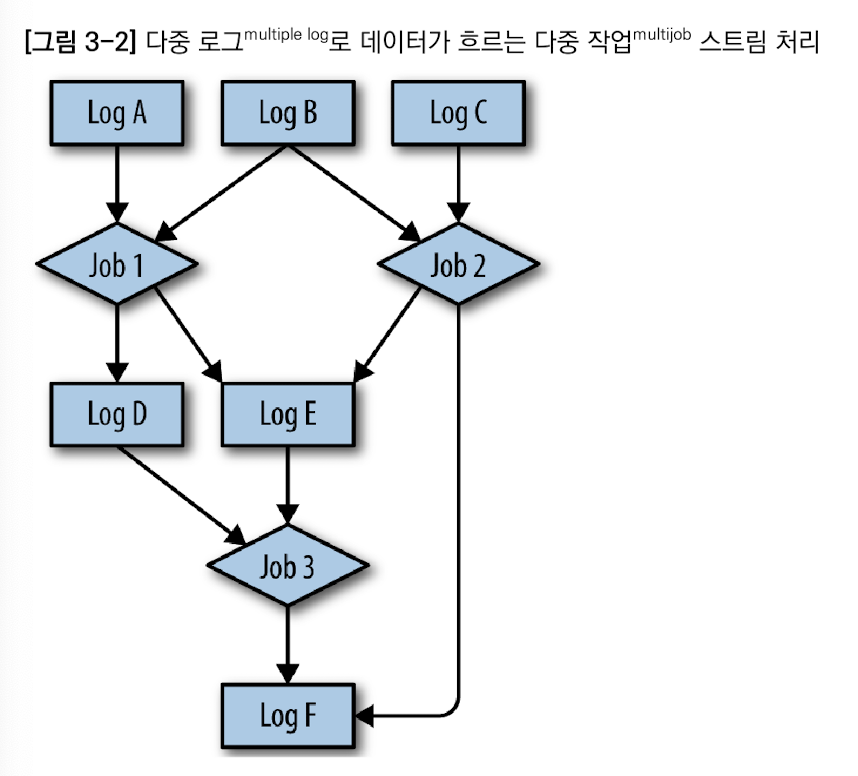
파생된 피드는 임의의 복잡한 처리 로직을 캡슐화시킬 수 있으므로 유용함.

위에말 원문
For example, Google has described some details on how it rebuilt its web crawling, processing, and indexing pipeline—what has to be one of the most complex, largest scale data processing systems on the planet—on top of a stream processing system.
크고 복잡한처리 → 스트림 처리 시스템? 이런 뜻인가요? 아시는 분 댓글 달아주세요 ㅠㅠ
스트림 처리 : 로그를 읽어서 로그나 다른 시스템에 쓰기 처리를 하는 모든 작업.
입/출력용 로그는 이러한 프로세스들을 처리 단계의 그래프에 연결. 이런 식으로 중앙의 한 로그를 이용하면 여러분은 조직 전체 데이터의 스냅샷과 변환, 흐름을 일련의 로그와 로그를 대상으로 읽기/쓰기 한 프로세스들로부터 파악 가능
스트림 프로세서 : 로그를 읽고 쓰는 프로세스는 스트림 프로세서가 될 수 있다. 준 실시간 처리 코드를 관리, 확장하는데 도움을 주기 위해 인프라를 덧붙이거나 지원할 수 있는데, 이것이 스트림 처리 프레임워크가 하는 일.
3.2 로그와 스트림 처리
로그 모델일 지지하는 확고한 이유
- 로그는 각 데이터 집합을 다중 구독자로 만듬.
- 소비하는 측의 처리과정에서 순서 유지 가능
- (가장중요) 로그는 개별 프로세스에 버퍼링과 고립화를 제공하는 용도
소비 시스템보다 더 빨리 만든다면?
- 하위 작업이 따라 잡을 수 있을 때까지 상위 작업을 차단(결국 망함)
- 데이터를 버림(말도 안됨)
- 두 프로세스 간에 데이터 버퍼를 둠
비슷한 방식!!
맵리듀스 워크플로우 : 파일을 이용하여 중간 결과에 대해 체크포인트를 설정하고 이를 공유
SQL 처리 파리으라인 : 많은 중간/임시 테이블을 생성
둘 다 데이터인모션에 적합하게 추상화시킨 패턴, 즉 로그를 활용한 예
3.3 데이터 재 처리: 람다 아키텍처와 다른 대안
람다 아키텍처 : 로그 지향적 데이터 모델링의 한 부류. 스트림 처리와 오프라인 처리를 결합시킨 접근 방법.
3.3.1 람다 아키텍처는 무엇이고 어떻게 해야 람다 아키텍처가 되는가
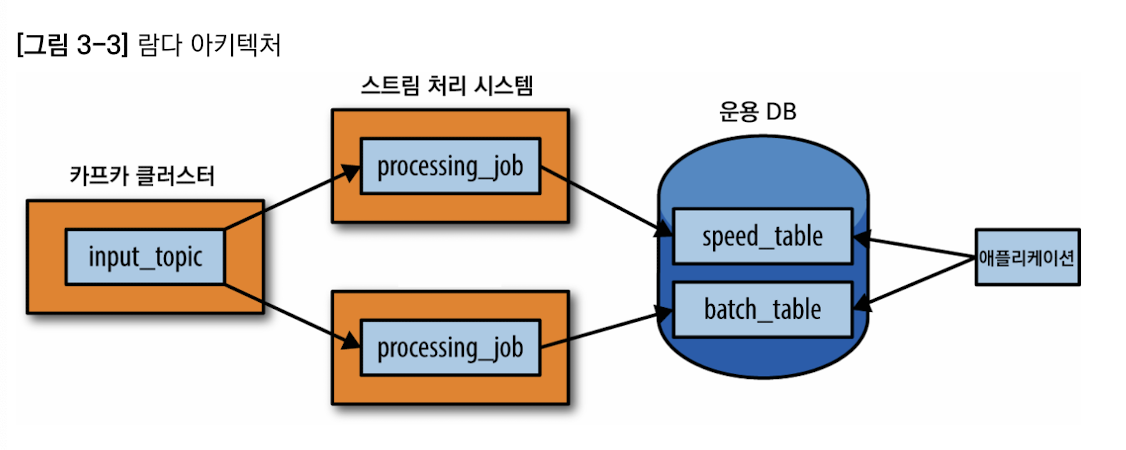
불변성 레코드 시퀀스를 포착하여 배치-및-스트림 처리 시스템에 병렬로 입력. 변환 로직은 배치 시스템과 스트림 처리 시스템에서 각각 한 번씩, 총 두 차례 수행. 그런 다음 양쪽에서 쿼리로 결과를 병합한 뒤 전체 결과물을 생성
3.3.2 람다 아키텍처의 장점
람다 아키텍처의 사상 : 원래 입력 데이터를 훼손되지 않은 채로 갖고 있어야 한다. 어떤 데이터가 들어오고 나갔는지를 알면 복잡한 데이터 흐름을 처리하는 데 매우 큰 도움이 된다.
데이터 재처리 문제를 집중 조명한 점도 맘에 듬. 재처리는 스트림 처리에서 가장 중요한 이슈 중 하나인데 흔히 무시되곤 한다.
재처리 : 입력 데이터로 결과를 다시 생성하는 것.
3.3.3 람다 아키텍처의 단점
단점 : 복잡한 분산 시스템 두 곳에서 같은 결과를 산출하기 위한 코드를 관리하는 것이 골치 아픔. 운영이 복잡함.
3.3.4 대안
스트림 처리의 기본적인 추상화는 데이터 흐름의 DAG(방향성 비순환 그래프, 모든 노드가 서로 다른 노드를 향하는 비순환 그래프)
스트림 처리 재처리 방법
- 카프카 부류 시스템 사용. 카프카 보유 기간을 30일로 설정
- 재처리할 때, 스트림 처리 작업 인스턴스를 하나 더 기동시켜 보유한 데이터의 처음부터 처리를 시작하되 결과 데이터는 새 결과 테이블에 적재
- 두 번째 처리 작업이 따라붙으면 새 테이블에서 읽어오도록 애플리케이션을 스위칭
- 구 버전의 작업을 중지하고 구 결과 테이블을 삭제
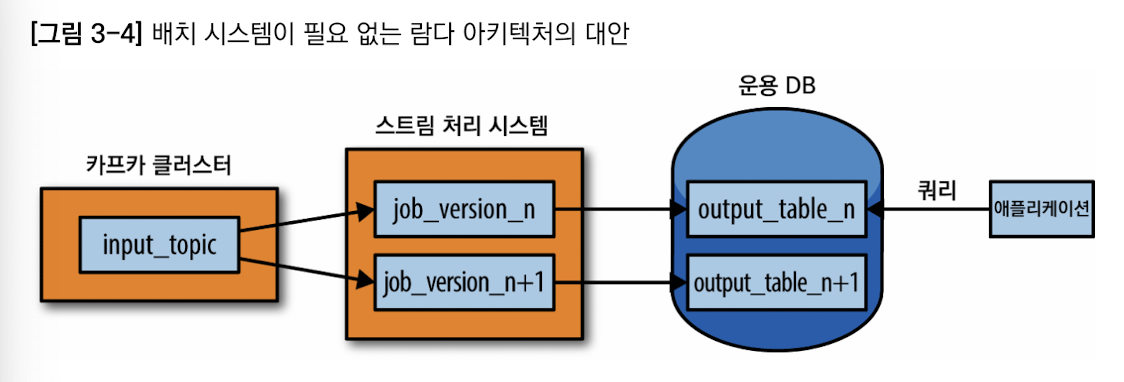
하둡만으로는 처리가 어렵겠지만 카프카와 함께라면 다루기 쉽다.
