
https://www.acmicpc.net/problem/1012
문제
차세대 영농인 한나는 강원도 고랭지에서 유기농 배추를 재배하기로 하였다. 농약을 쓰지 않고 배추를 재배하려면 배추를 해충으로부터 보호하는 것이 중요하기 때문에, 한나는 해충 방지에 효과적인 배추흰지렁이를 구입하기로 결심한다. 이 지렁이는 배추근처에 서식하며 해충을 잡아 먹음으로써 배추를 보호한다. 특히, 어떤 배추에 배추흰지렁이가 한 마리라도 살고 있으면 이 지렁이는 인접한 다른 배추로 이동할 수 있어, 그 배추들 역시 해충으로부터 보호받을 수 있다. 한 배추의 상하좌우 네 방향에 다른 배추가 위치한 경우에 서로 인접해있는 것이다.
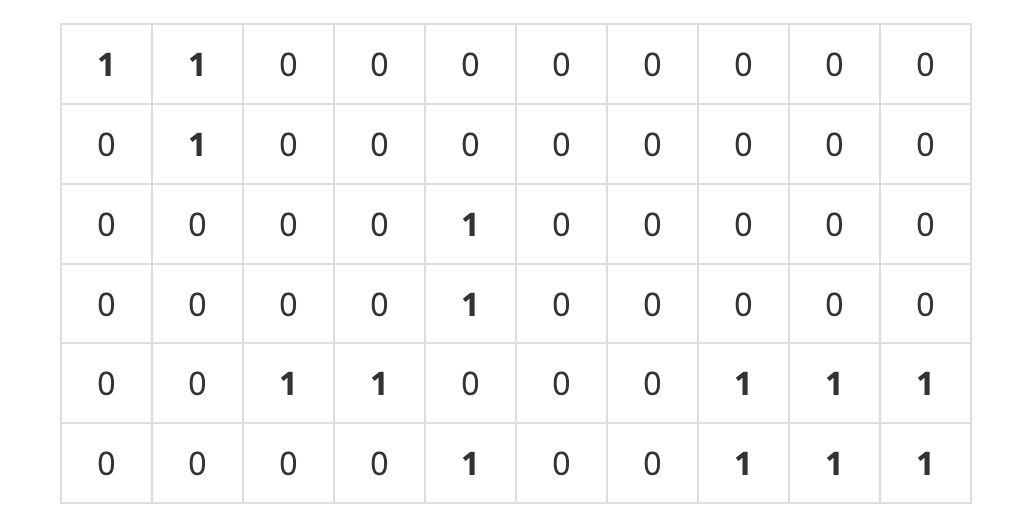
한나가 배추를 재배하는 땅은 고르지 못해서 배추를 군데군데 심어 놓았다. 배추들이 모여있는 곳에는 배추흰지렁이가 한 마리만 있으면 되므로 서로 인접해있는 배추들이 몇 군데에 퍼져있는지 조사하면 총 몇 마리의 지렁이가 필요한지 알 수 있다. 예를 들어 배추밭이 아래와 같이 구성되어 있으면 최소 5마리의 배추흰지렁이가 필요하다. 0은 배추가 심어져 있지 않은 땅이고, 1은 배추가 심어져 있는 땅을 나타낸다.
입력
입력의 첫 줄에는 테스트 케이스의 개수 T가 주어진다. 그 다음 줄부터 각각의 테스트 케이스에 대해 첫째 줄에는 배추를 심은 배추밭의 가로길이 M(1 ≤ M ≤ 50)과 세로길이 N(1 ≤ N ≤ 50), 그리고 배추가 심어져 있는 위치의 개수 K(1 ≤ K ≤ 2500)이 주어진다. 그 다음 K줄에는 배추의 위치 X(0 ≤ X ≤ M-1), Y(0 ≤ Y ≤ N-1)가 주어진다. 두 배추의 위치가 같은 경우는 없다.
출력
각 테스트 케이스에 대해 필요한 최소의 배추흰지렁이 마리 수를 출력한다.
입출력 예
| 입력 | 출력 |
|---|---|
| 2 | 5 |
| 10 8 17 | 1 |
| 0 0 | |
| 10 | |
| 1 1 | |
| 4 2 | |
| 4 3 | |
| 4 5 | |
| 2 4 | |
| 3 4 | |
| 7 4 | |
| 8 4 | |
| 9 4 | |
| 7 5 | |
| 8 5 | |
| 9 5 | |
| 7 6 | |
| 8 6 | |
| 9 6 | |
| 10 10 1 | |
| 5 5 |
풀이
dfs로 풀었는데 이유는 배추가 모여있는 부분이 몇 개인지를 찾아야하기 때문에 하나의 배추를 만나면 그 배추들이 모여있는 부분을 깊이 탐색하기 위해서(?) 이다.
일단 저는 두 개의 이차원 리스트를 만들어줬습니다. 하나(아래 코드에서 graph)는 배추가 심어진 부분은 1로, 안 심어진 부분은 0으로 하는 배추밭을 만들기 위함이었고 하나(checked)는 이미 확인한 배추는 다시 볼 필요가 없으니까 checked에 1로 체크해두려고 만들었다. 그렇게 입력받은 배추의 위치를 체크해주고 count를 0으로 정해둔다. 여기까지가 입력받은 내용으로 미리 세팅을 해둔거고 이제부터는 배추밭의 (0,0)부터 (N,M)까지 돌면서 배추가 있고(graph[i][j] == 1) 처음 확인하는 배추라면 (checked[i][j] == 0) dfs 함수를 i와 j를 인자로 전달해서 호출한다. 이 때 dfs 함수는 재귀함수인데 이 함수는 재귀를 통해 주변에 있는 모든 배추를 확인하면 끝나기 때문에 이 작업 이후에 count += 1을 해주면 된다. dfs 함수의 동작을 살펴보면 먼저 x와 y를 인자로 받아서 checked 함수에 방문했다는 처리를 해준다. 그 다음에는 미리 선언해둔 dx, dy를 통해 상,하,좌,우를 확인하는데, 이 때 상,하,좌,우로 이동했을 때의 인덱스를 nx, ny라고 했을 때 배추가 심어져 있고 방문하지 않았다면 nx, ny를 인자로 dfs함수를 다시 호출하는 방식으로 동작한다.
아마 코드를 보고 이해하는게 빠를지도.. 나는 이 문제를 풀면서 막혔던 부분이 두가지가 있었다.
첫번째는 이차원 리스트를 초기화하는 과정에서 생긴 문제이다. 전에 리스트를 선언할 때 아래와 같이 코드를 짠 적이 있다.
list = [0] * n그래서 이번에도 처음에 코드 짜면서 graph를 초기화할 때 아래와 같은 방식으로 코드를 짰다.
graph = [[0] * m] * n 그랬더니 죽어도 답이 안나와서 원인을 찾으려고 print로 문제인 부분을 찾았는데 그게 바로 graph였다. 구글링 해보니 위의 방식으로 이차원 배열을 초기화하면 [0] m을 모두 같은 객체로 인식해서 하나의 값만 바꿔도 n개의 리스트가 다 바뀐다는 사실을 알았다.. 그래서 graph = [[0 for _ in range(m)] for _ in range(n)] 하거나 graph = [[0] n for _ in range(n)] 이렇게 초기화해주어야 한다고 했다. 이제 다시는 틀릴 일 없을 듯ㅎ..
두번째는 재귀의 깊이 때문에 런타임 에러가 나는 것이다. 찾아보니 백준에서는 최대 재귀 깊이를 1000으로 정해두었는데 이 깊이를 초과해서 재귀를 호출하기 때문에 런타임 에러가 난다고 했다. 그래서 sys.setrecursionlimit(10**6) 로 재귀의 limit를 더 늘려주는 방법을 통해 해결했다.
코드
import sys
sys.setrecursionlimit(10**6)
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
def dfs(x,y):
checked[x][y] = 1
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < n and 0 <= ny < m:
if graph[nx][ny] == 1 and checked[nx][ny] == 0:
dfs(nx,ny)
tc = int(input())
for _ in range(tc):
m, n, k = map(int, input().split())
graph = [[0 for _ in range(m)] for _ in range(n)]
checked = [[0 for _ in range(m)] for _ in range(n)]
for _ in range(k):
a, b = map(int, input().split())
graph[b][a] = 1
count = 0
for i in range(n):
for j in range(m):
if graph[i][j] == 1 and checked[i][j] == 0:
dfs(i,j)
count += 1
print(count)