혼자공부하는SQL
1.혼자 공부하는 SQL 11강

어느 상황에서 사용할까?예시로 출입시간을 태그 할 때마다 실시간으로 INSERT하고 싶을 때
2.혼자공부하는 SQL 10강
두개의 테이블을 묶는 것대부분 이것을 의미함ex. 회원과 구매 테이블한명의 회원은 여러번 구매할 수 있다-> 회원 테이블의 PK인 아이디는, 구매 테이블에서는 FK로 설정해야함=> 결과=> 위에는 오류이유: 회원 테이블, 구매 테이블 모두 mem_id라는 속성을 가지고
3.혼자공부하는 SQL 9강
TINYINT - 1byteSMALLINT - 2byteINT - 4byteBIGINT - 8byteError code 1264: Out of range=> 적은 수를 기록해야하는 속성은 굳이 int 보다는 tinyint로 지정하는 것이 효율적이다!like 인원수 et
4.혼자 공부하는 SQL 12강
테이블 만들기 만들기 전에 설계를 해야함 -> 어떠한 정보를 넣을지 AUTO_INCREMENT -> 데이터가 insert 될 때 마다 자동으로 id값이 하나씩 커지게 됨 PK 지정 FK지정
5.혼자 공부하는 SQL 13강
데이터 무결성을 위해 필요함!🤔데이터 무결성이란? 데이터 내의 혼란이 없고, 결함이 없는 것을 의미기본키: 데이터를 구분 할 수 있는 식별자중복 불가NULL값 불가ex. 회원 아이디 중복 안됨, 아이디 없이 회원가입 안됨자동으로 클러스터형 인덱스가 생성됨테이블당 기본
6.혼자 공부하는 SQL 14강
= 가상의 테이블데이타베이스 개체 중에 하나'바로가기'와 같은 역할실체는 없지만, 테이블과 연결되어있는 것사용자의 입장에서는 테이블과 다르게 보이지 않음!생성 방법뷰이름을 v_tableName으로 지어주면 좋다테이블의 모든 정보가 담기는 것이 아닌 사용자에게 보여주고
7.혼자 공부하는 SQL 15강
데이터의 양이 매우 많기 떄문에 빠르게 찾기 위해서는 반드시 필요함!필요없는 index를 만드는 것은 오히려 디비의 차지하는 공간만 늘어나 느려질 수 있다.장점SELECT문으로 검색하는 속도가 매우 빨라짐\-> 전체 시스템의 성능이 향상됨단점공간 차지 -> 디비 안에
8.혼자 공부하는 SQL 16강
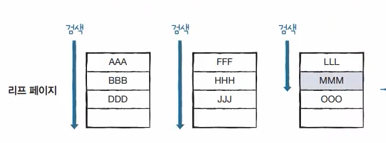
클러스터형 인덱스와 보조 인덱스는 모두 균형 트리로 이루어져 있다. 인덱스의 내부 작동 원리 균형 트리 개념 데이터가 저장되는 공간: node
9.혼자 공부하는 SQL 17강
인덱스 생성 및 제거 인덱스 생성 기본: ASC DESC는 거의 쓸 경우가 없음 UNIQUE 쓸 때는 중복이 안된다는 것을 잘 기억해야함 -> 이름은 중복일 수도 있으니 안됨 인덱스 제거 => 생성&제거는 추가로 만든 것 PK는 자동으로 생성됨 -> 제거시 PK
10.혼자 공부하는 SQL 18강
개념스토어드 프로시저 = SQL + 프로그래밍생성만드는 것과 실행(호출)은 다른 문제만들었으면,, 실행을 해야지..?실행으로 실행함삭제명명 규칙명명 할 때도 proc을 붙여주면, 보고 바로 이해할 수 있음아하! 프로시저네!!()는 비어있어도 됨입력 매개변수자판기에 넣을
11.혼자 공부하는 SQL 19강
스토어드 함수 개념과 형식 개념 내가 원하는 함수 만들기 SUM(), CAST(), CONCAT() 등등 말고 생성 형식 CREATE FUNCTION 스토어드함수_이름(매개변수) 매개변수는 모두 입력 매개변수임 출력 매개변수는 RETURNS 반환 형식 RETURN
12.혼자 공부하는 SQL 20강