
드디어 DolDol 프로젝트를 성공적으로 마치고 배포를 했습니다👍 이글을 보시는 분들도 서비스를 한번 이용해보시면 좋을것 같습니다!!
서비스를 배포했으면 끝 아닌가?? 🧐🧐 왜 글을 올렸을까요??
서비스를 만들고 배포를 하는것까지가 아닌, 이제 유지 보수를 해야하죠!!
기존 코드를 리팩토링을 하고, 로그를 바탕으로 모니터링을 해보려고합니다.
평소에 로그를 개발 중 오류가 발생했을 때, 값이 제대로 설정되어있는 지, 해당 메서드를 호출했는 지 등 로컬에서 개발 할 때 확인 용도로 사용했습니다.
운영 서버에서도 예상치 못한 오류가 발생했을 시, 서버에 직접 접속해서 "docker logs -f"로 확인을 해야한다는 불편한 점이 있었습니다.
그래서 문제가 발생 할 시, 로그를 바탕으로 알림을 보내고 모니터링을 통해 분석해서 관리를 하면 좋겠다고 판단을 했습니다.
로그 단계가 뭘까요?? 🤔
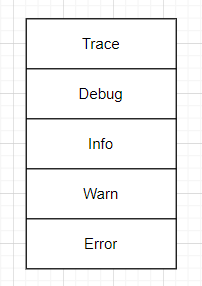
Trace
- 가장 상세한 디버깅 정보
- 코드의 실행 흐름 추적
- 보통 개발 단계에서만 사용
Debug
- 개발자를 위한 디버깅 정보
- 변수 값, 함수 호출 등
- 개발/테스트 환경에서 주로 사용
Info
- 일반적인 정보성 메시지
- 애플리케이션의 정상 동작 상황
- "사용자 로그인", "서버 시작" 등
Warn
- 경고 메시지
- 문제가 될 수 있지만 동작은 계속됨
- "deprecated 함수 사용", "메모리 부족" 등
Error
- 오류 발생
- 기능이 제대로 동작하지 않음
- 즉시 확인이 필요한 문제
알림을 보내는게 꼭 좋은가?? 🤔
문제가 발생하면 알림이 오는 기능은 꼭 필요하다고 생각합니다.
하지만, 에러가 아닌 경고와 정상적인 로그 알림도 오는게 좋을까요??

아마 저라면... 처음에는 "우와~~ 알림이 정상적으로 되구나!!" 이러다가 시간이 지나면 오히려 알림을 끄고싶어질것 같습니다 🤨🤨
그래서 정말 꼭 필요한 운영환경일때 ERROR 🚨 단계의 로그들이 발생 할 때 슬랙으로 알림을 보내려고합니다.
DolDol은 로그 관리를 어떻게 하는가?? 🤔
-
이전 아키텍처
-
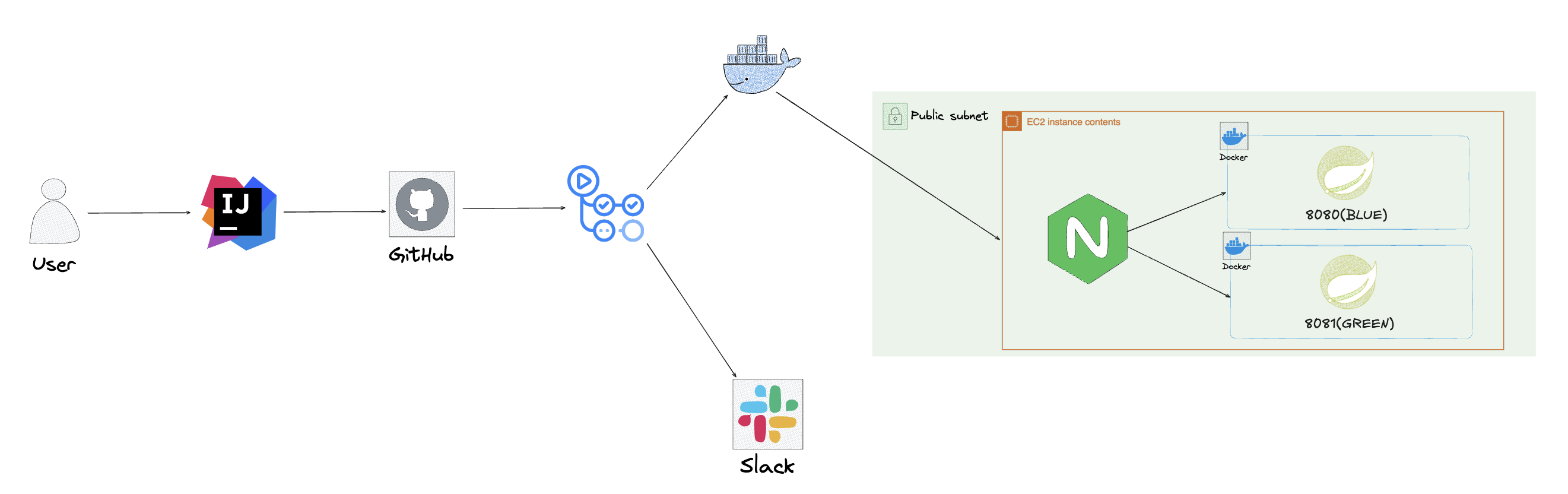
현재 아키텍처
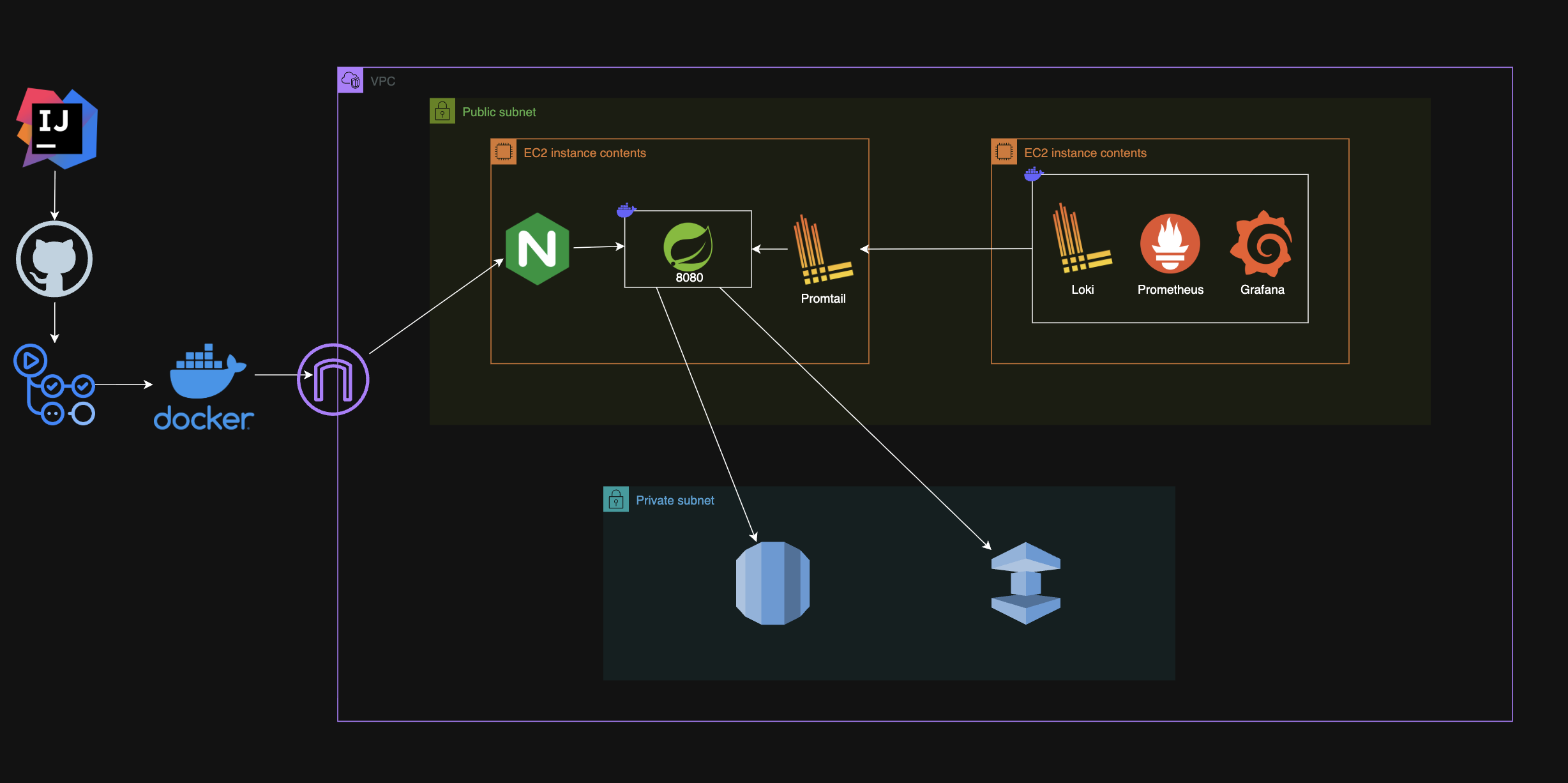
해당 아키텍처를 보여준 이유는 로그 수집 및 모니터링을 위해 아키텍처를 변경했습니다..!!
왜 이렇게 변경했냐...
다음과 같은 이유입니다.
1. Spring 컨테이너에 로그를 쌓으면 되자나
실제로 Spring 컨테이너의 로그를 컨테이너 내 /logs 경로에 쌓았습니다. 하지만 문제가 생길때마다 컨테이너에 직접 접속해서 디렉토리 내 error.log 파일을 찾아봐야합니다.
2. 그럼 Volume 통해서 ec2에 로그를 쌓으면 되자나
컨테이너에 접속을 안해도된다는 점이있지만 어쨌든 터미널에 접속해야하잖아요... 또한 에러 로그 파일을 일자별로 해놓는다고 해도 grep 명령어를 통해 어떤 에러인지 찾아야한다는 불편한점과 가독성이 떨어져서 에러 찾기가 쉽지 않았습니다. 또한 실시간 모니터링 불가능합니다.
3. 그럼 Spring에 로그를 실시간으로 탐지하면 되잖아
넵. 그래서 이를 위해서 Spring 컨테이너가 존재하는 같은 서버에 promtail이라는 컨테이너를 띄었습니다. promtail은 실시간으로 파일을 감지하여 로그의 발생을 바로 확인 할 수 있습니다.
4. 근데 loki는 왜 필요해?
promtail은 로그를 실시간으로 감지 할 뿐아니라, 전송을 해야합니다. Grafana에서도 로그를 저장하지 않고, 수신 기능이 없습니다. 그래서 loki라는 로그 저장소를 둬서 promtail은 loki로 로그를 전송을하고 Grafana에서는 loki로 데이터를 실시간으로 가져오죠.
╔══════════════╗
║ Spring App ║
║ (로그 파일) ║
╚═════╤════════╝
│
▼
╔══════════════╗
║ Promtail ║ ← 로그 파일을 감시하고
║ (수집 & 전송)║ → 로그를 Loki로 보냄
╚═════╤════════╝
│ (HTTP Push)
▼
╔══════════════╗
║ Loki ║ ← 로그 저장 + 검색 엔진
╚═════╤════════╝
│ (데이터 조회용 API)
▼
╔══════════════╗
║ Grafana ║ ← Loki에게 요청해서
║ (시각화 UI) ║ 로그를 웹 UI로 보여줌
╚══════════════╝
5. 하나의 ec2 서버에서 compose로 다 띄우면 되잖아
서버 터졌습니다. 그래서 ec2를 새로 했습니다.
6. Prometheus는 왜 했지?
처음엔 INFO 로그를 바탕으로 각 요청당 평균 TPS, 서버 전체의 평균 TPS를 로그 분석을 통해 Grafana에서 시각화를 한다고 생각했습니다.
로그는 무슨 일이 있었는지의 상세 기록이고 메트릭은 어떤 수치가, 시간에 따라 어떻게 변했는지를 나타내는 지표입니다.
이런 메트릭 데이터를 프로메테우스에서 스프링 컨테이너에 /actuator/prometheus 라는 api를 호출해서 자동으로 수집을 해줍니다.
시간 흐름에 따라 데이터가 어떻게 변화했는지 추적 가능하기에 해당 데이터를 Grafana로 모니터링을 했습니다.
최종 모니터링!! 😄
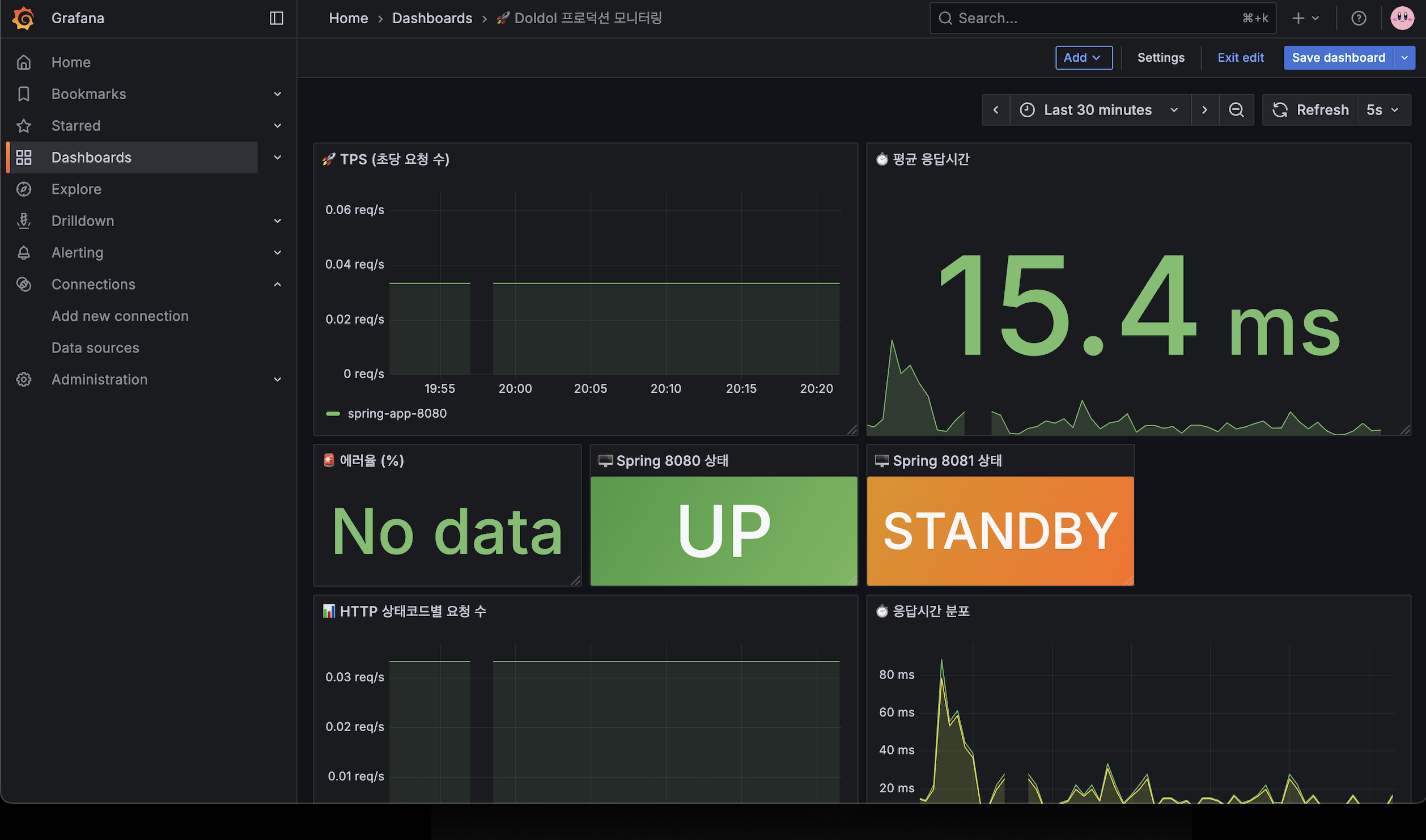
Grafana에 익숙하지 않아서 기능 숙지 후 다시 리팩토링을 해보겠습니다.
이상으로 시리우스의 개발 일대기편 마치겠습니다...👍
