Aggregation
- Collection 데이터를 변환하거나 분석하기 위해 사용하는 집계 Framework.
- Aggregation은 Find 함수로 처리할 수 없는, SQL의 Group By와 Join 구문 같은 복잡한 데이터 분석 기능들을 제공한다.
- Aggregation Framework는 Pipline 형태를 갖춘다.
- MongoDB 2.2부터 제공되었고 이전에는 Map Reudce를 사용했다.
Example
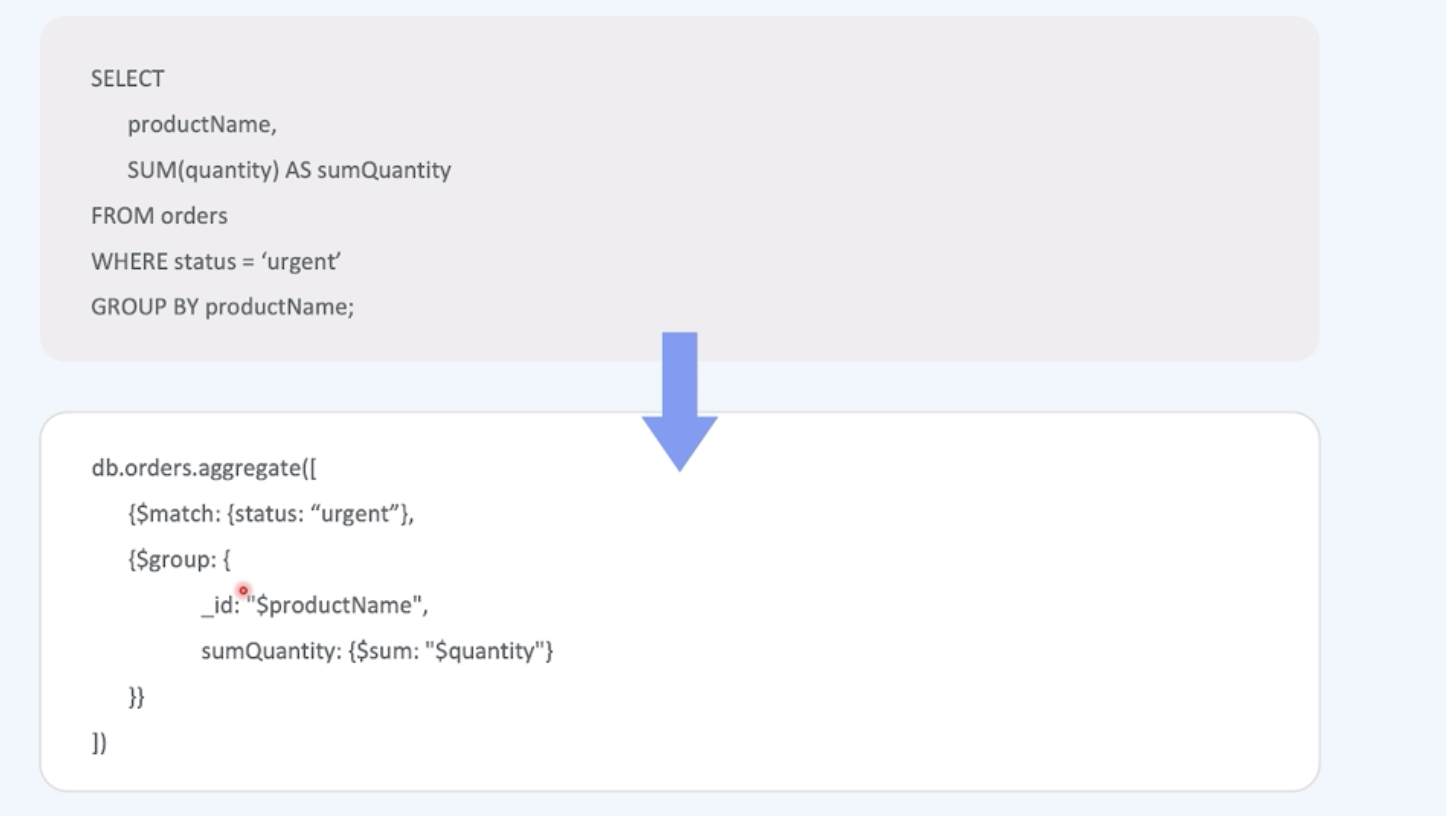
Aggregation Pipeline stream

Aggregation vs Map Reudce
MongoDB 서버는 이미 맵리듀스라는 분석기능을 가지고 있는데, 새롭게 Aggregation 기능을 도입한 이유는 대표적으로 두 가지 이유를 생각할 수 있다.
-
간단한 분석 쿼리에도 자바스크립트를 이용해서 맵리듀스 프로그램을 작성해야 한다. 자바스크립트 기반의 맵리듀스는 많은 제약을 가지고 있으며, 자바스크립트 언어를 알고 있어야 한다.
-
자바스크립트로 작성된 맵리듀스 작업은 자바스크립트 엔진과 MongoDB 엔진 간의 빈번한 데이터 맵핑으로 인해서 성능적 제약이 심했다.
그에 반해 Aggregation은 이런 특징을 가지고 있다.
- Aggregation은 순수하게 C++로 개발돼서 MongoDB엔진의 일부로 내장되었다. 따라서 별도의 자바스크립트 언어 엔진이 필요하지 않으며, 변수 맵핑 과정도 필요 없다.
이러한 이유로 실제 성능 테스트를 진행해보면 2.5배에서 3배 이상의 차이가 발생한다. (환경에 따른 차이가 있을 수 있습니다.)
작동방식(샤딩환경)
db.orders.aggregate([
{
$match: {
size: "medium",
},
},
{
$group: {
_id: { $getField: "name" },
totalQuantity: {
$sum: { $getField: "quantity" },
},
},
},
]);몽고디비에서는 여러 샤드에서 데이터를 수집해야 하는 경우 대표 샤드를 선정한다. 이후 순서를 적어보자면
-
MongoDB 라우터(Mongos)는 사용자로부터 쿼리를 전달받으면 우선 요청된 A쿼리의 파이프라인 선두에 "$match" 스테이지가 있는지와 $match 스테이지의 검색 조건이 샤드 키를 포함하는지를 비교한다. 만약 검색 조건이 필요로 하는 도큐먼트가 단일 샤드에만 있다면 MongoDB 라우터는 해당 샤드로만 쿼리를 전송한다. 만약 그렇지 않다면 MongoDB 라우터는 쿼리를 대표 샤드로 전달한다.
-
대표 샤드는 Aggregation 쿼리를 전달받으면 필요한 나머지 샤드로 쿼리를 전송한다. 그리고 요청을 전달받은 샤드들이 쿼리 결과를 반환하면 대표 샤드는 그 결과를 병합하고 정렬하는 작업을 수행해서 라우터로 최종 결과를 전달한다.
-
MongoDB 서버는 Aggregation 파이프라인을 각 샤드가 실행할 수 있는 부분과 그렇지 않은 부분으로 나눠서 처리를 수행한다. 대표적으로 $match나 $project와 같은 스테이지는 각 샤드가 개별로 실행할 수 있는 부분에 속하며, $sort 또는 $group 스테이지는 각 샤드가 개별로 실행하지 못하는 부분( $match 조건이 2개 이상의 샤드를 참조야 하는 경우 )에 속한다고 볼 수 있다. 그리고 $out 이나 $looukp 그리고 $graphlookup 등과 같은 스테이지도 각 샤드가 개별로 실행하지 못하는 부분이다.
TIP
db.collection.count(query) 명령은 db.collection.find(query).count()는 skip과 limit 옵션이 사용되면 차이가 발생하는데,
실제 count( ) 명령은 skip과 limit 옵션을 활용해서 도큐먼트의 건수를 확인하는 반면,
find( ).count( ) 명령은 limit나 skip 옵션을 무시하기 때문이다.
만약 find().count() 명령을 사용할 때 skip이나 limit가 적용되게 하고자 한다면 applySkipLimit옵션을 true로 설정해야 한다.
