Modeling이란?
어플리케이션의 요구사항과 데이터베이스 성능의 균형을 맞추는 것 즉 하나의 공략법이다.
다음은 몽고디비에서 모델링을 위해 고려할 키포인트들이다.
Embedding vs Referencing
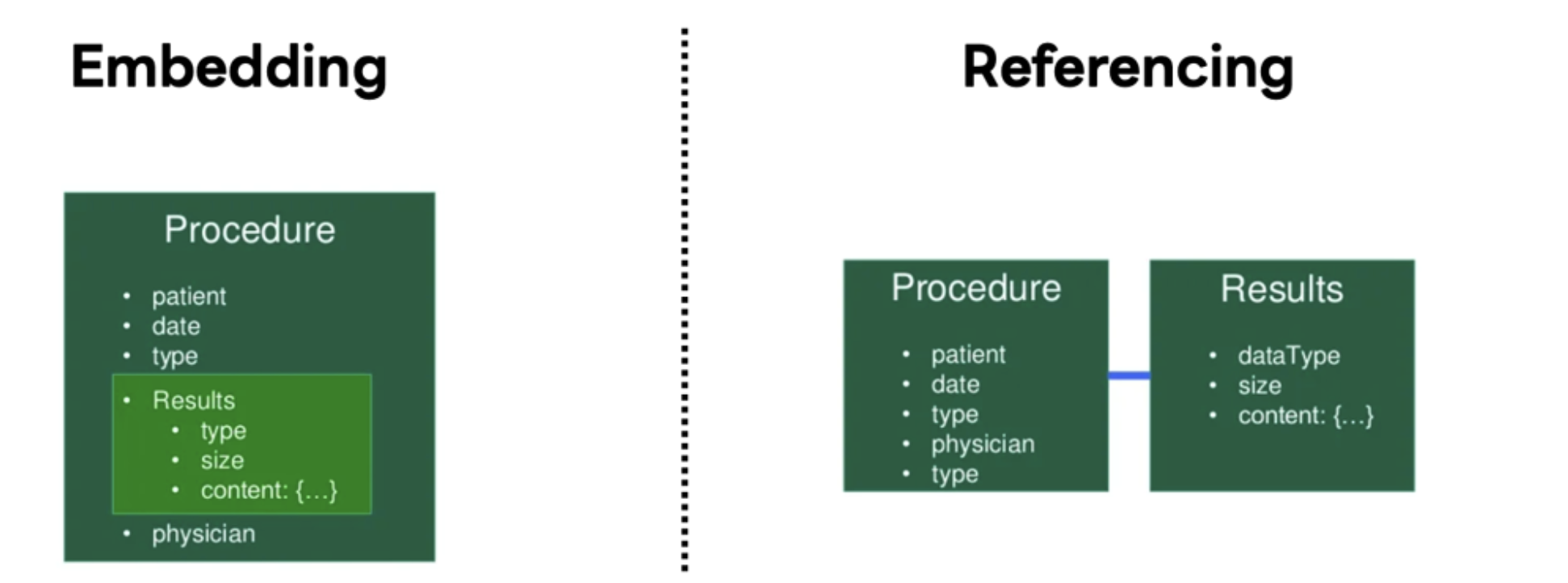
왼쪽처럼 데이터를 내장시키는 방식은 하나의 Collection만 조회해서 Read에 대한 속도가 빠르고 Document 단위로 원자성이 보장되어 데이터의 일관성을 유지시키는 방식이 쉽지만, 데이터의 중복이 발생하고 내장된 데이터의 수정이 필요하다면 모든 내장된 Document를 다 수정해야하기 때문에 Write에 대한 성능이 저하될 것이다.
반면에 오른쪽처럼 데이터를 참조하는 형태로 가면 데이터의 중복이 없고 단일 건에 대해서만 수정하면 되기 때문에 Write에 대한 속도는 좋다.
하지만, 반대로 MongoDB에서 말하는 Join인 Lookup을 사용해서 여러 Collection을 읽어야하기 때문에 Read에 대한 속도가 많이 느리고 Collection이 쪼개져 있기 때문에 데이터의 일관성을 보장해야하는 경우 Transaction을 사용해야할 수도 있다. 역정규화를 기본 철학으로 갖는 MongoDB에서 는 이게 최악일 수도 있지만, 때로는 데이터의 크기 때문에 참조형태를 선택해야하는 경우도 있다.
(참고: 몽고디비 배열의 최대 크기는 16MB이다. 이 부분을 고려해서 모델링을 진행해야 한다.)
배열의 16mb이기 때문에 사전에 잘 고려해서 모델링을 진행하자
Reducing Resources
-
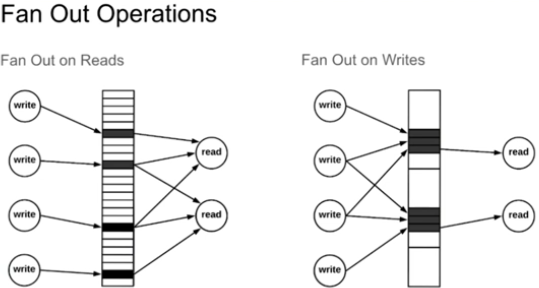
요구사항에 따라 fan out read 또는 fan out read 고려하기
-
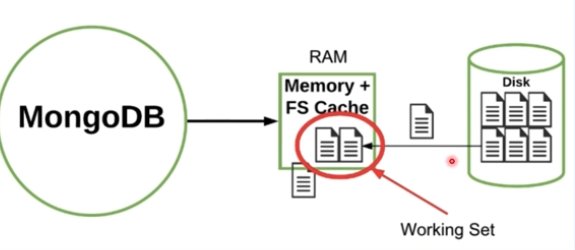
Working Set을 줄여 캐시가 디스크로 접근하는 횟수 줄이기
-
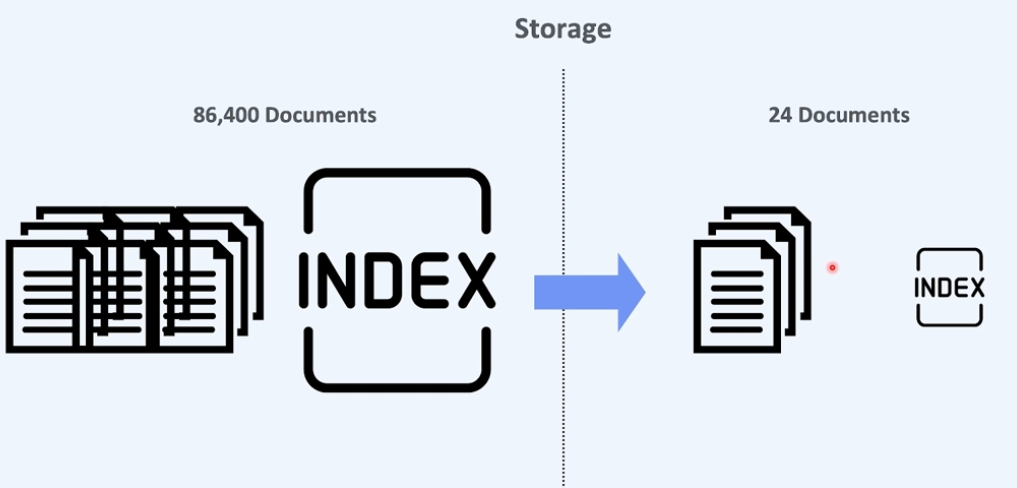
Storage 최적화(도큐먼트 수를 줄여 인덱스 크기를 줄여보자)
Easy Managing
- 컬렉션과 필드의 최대한 줄여보자