자주사용하는 쿼리의 응답이 빠른 이유
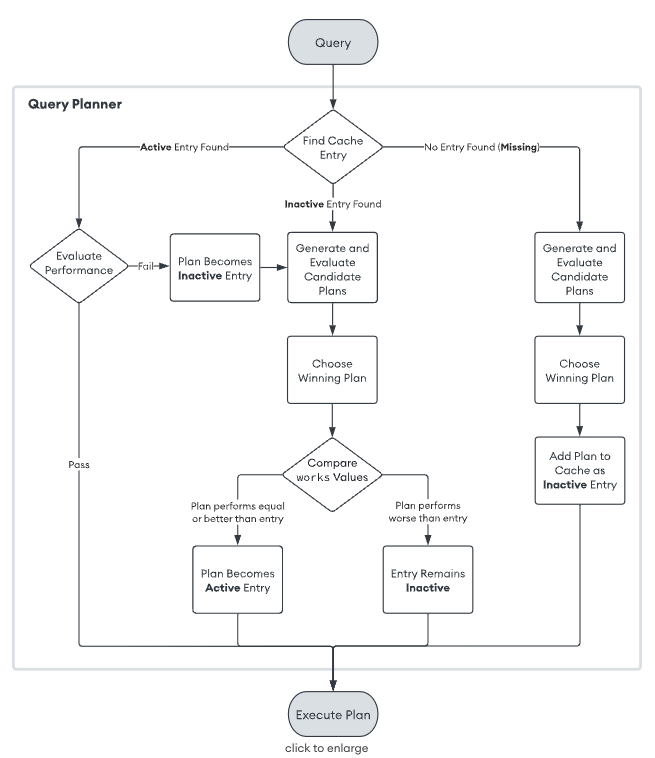
처음 쿼리를 실행했을 때 보다 두 번쨰 쿼리 실행 응답이 빠른 이유는 뭘까? 그림을 통해 알아보자.
-
쿼리 최초 실행: 캐쉬에서 매칭되는 엔트리 확인(캐쉬에 존재하지 않음) -> 실행 계획 후보 생성 -> 후보 실행 계획 수행 -> 옵티마이저가 가장 빠른 계획을 위닝 플랜으로 선택 -> 캐쉬에 생성 후 반환
-
재조회: 캐쉬에 있다면 바로 리턴, 없다면 캐쉬에서 오래된 데이터 삭제 후 위와 동일한 흐름으로 실행
요약
일반적으로 한번(자주 또는 최근) 실행한 쿼리는 캐쉬에 적재되어 응답이 빠르다.
- 느린 응답: query -> disk -> cache -> return
- 빠른 응답: query -> cache -> return
위에서 설명했듯이 대부분의 데이터베이스 관리 시스템(DBMS)은 빠른 처리 속도를 위해 내부 스토리지 엔진과 함께 캐시 영역을 갖추고 있다. 캐시는 자주 접근하는 데이터를 빠르게 불러오기 위해 사용된다.
예를 들어, 메시지 서비스의 경우를 생각해보자. 서비스에는 10년 치의 메시지 데이터가 저장되어 있지만, 실제로 사용자들이 주로 확인하는 것은 최근 한 달 치의 메시지이다.
이런 상황에서 캐시의 역할은 다음과 같다:
-
캐시 적재: 자주 조회되는 데이터, 즉 최근 한 달 치의 메시지를 캐시에 저장한다.
-
Working Set과 캐시 크기: 만약 자주 사용되는 데이터의 크기(Working Set)가 캐시의 크기를 초과한다면, 캐시에서는 실시간으로 데이터를 교체하는 작업(Cache Eviction)이 일어난다. 이는 캐시에 저장된 일부 데이터를 제거하고 새로운 데이터로 대체하는 과정이다.
-
Cache Eviction 방지하기: Cache Eviction이 발생하지 않도록 하기 위해서는 서버 사양의 향상, 데이터 모델링 개선, 쿼리 튜닝, 비즈니스 요구사항 조정 등의 방안을 고려할 수 있다.
이러한 해결 방안들을 탐색하기 전에, 문제의 원인을 정확히 파악하고 분석하는 것이 필요하다. MongoDB의 옵티마이저가 설정하는 실행 계획을 분석하는 것이 필요하다. 쿼리에 대한 실행 계획을 분석함으로써, 문제의 근본적인 원인을 이해하고 최적의 해결 방안을 도출할 수 있다.
