Architecture
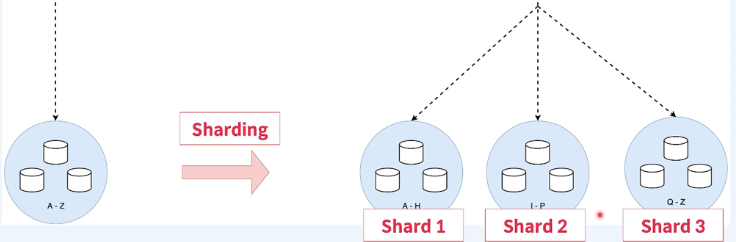
장점
- 용량의 한계를 극복할 수 있다.
- 데이터 규모와 부하가 크더라도 처리량이 좋다.
- 고가용성을 보장한다(모든 샤드는 Replica Set으로 구성되어 있기 떄문)
- 하드웨어에 대한 제약을 해결할 수 있다.
단점
- 관리가 비교적 복잡하다.
- Replica Set과 비교해서 쿼리가 느리다.
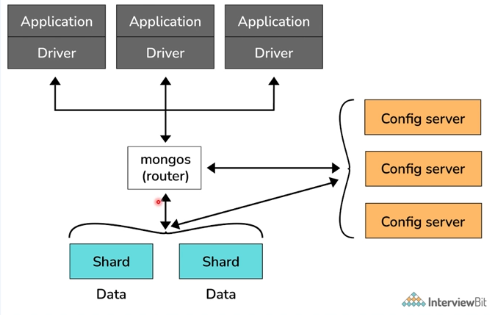
- mongos: 라우팅 역할을 한다. 쿼리를 샤드에 전달하고 결과를 다시 머지하여 App단에 전송한다.
- shard: 데이터를 직접적으로 들고있다.
- Config: shard의 메타 데이터를 가지고 있다.(어떤 샤드가 무슨 데이터를 들고 있는지)
Sharding Collections
- 샤딩은 컬렉션 단위다.
- 모든 컬렉션을 샤딩하진 않는다 (자주사용되는 데이터는 분산시키면 조회 이점이 떨어진다)
- 청크라고 불리는 논리적인 단위로 나누어 분산시킨다.
Sharding Strategy
-
Ranged Sharding: 몽고디비 인덱스를 생성하고 해당 필드들을 샤드키로 지정한다. 샤드키의 값을 기준으로 따라 데이터를 범위별로 나누어 여러 샤드에 분산 저장하는 방식이다. 각 샤드는 선택된 샤딩 키의 값에 따라 데이터의 범위를 갖게 되며, 이를 통해 데이터 조회 및 관리의 효율성을 높일 수 있다.
예시
온라인 쇼핑몰의 주문 데이터를 관리하는 MongoDB 데이터베이스가 있다고 가정 해보자. 주문 데이터에는 각 주문의 고유 ID, 주문 날짜, 고객 정보, 주문 항목, 총액 등 다양한 정보가 포함될 수 있다. 이 데이터베이스를 효율적으로 관리하기 위해 Ranged Sharding 전략을 적용할 수 있다.
샤딩 키 선택
주문 날짜(orderDate)를 샤딩 키로 선택한다.데이터 분할과 할당
샤드 1: 2023년 1월 1일부터 2023년 3월 31일까지의 주문 데이터
샤드 2: 2023년 4월 1일부터 2023년 6월 30일까지의 주문 데이터
샤드 3: 2023년 7월 1일부터 2023년 9월 30일까지의 주문 데이터
샤드 4: 2023년 10월 1일부터 2023년 12월 31일까지의 주문 데이터
이렇게 주문 데이터를 샤딩 키(orderDate)에 기반하여 시간 범위별로 나누어 각 샤드에 저장함으로써, 데이터베이스의 성능과 확장성을 개선할 수 있다. 특정 기간에 대한 조회 요청이 들어올 때, 해당 기간이 포함된 샤드만 조회하면 되기 때문에 전체 데이터베이스를 검색하는 것보다 훨씬 빠른 응답 속도를 기대할 수 있다. -
Hashed Sharding: 샤딩 키에 해시 함수를 적용한 후, 그 결과를 기반으로 데이터를 샤드에 분배하는 전략이다. 이 방법은 데이터를 균등하게 분배하기 위해 사용되며, 특정 샤드에 데이터가 집중되는 것을 방지할 수 있다.
Hashed Sharding은 Ranged Sharding의 단점을 보안하기 위해 등장했다.
Ranged Sharding 단점은 데이터가 균등하게 저장되지 못 할 수 있다는 것이다. 아래 예시를 보자.고객 데이터를 '고객 ID' 범위에 따라 분할하는 경우를 생각해볼 수 있다. '고객 ID'가 1에서 1000인 데이터는 샤드 1에, 1001에서 2000은 샤드 2에 저장되는 방식이다.
- 불균형한 데이터 분포: 만약 고객 ID가 순차적으로 할당되고, 최근 고객일수록 더 많은 데이터를 생성한다면, 최신 데이터가 몰리는 샤드에 부하가 집중될 수 있다. 이러한 '핫스팟' 현상은 시스템의 전반적인 성능 저하를 초래할 수 있다.
- 범위 쿼리 최적화 한계: 범위 쿼리는 특정 샤드에만 집중될 수 있어, 쿼리 성능이 샤드의 데이터 분포에 크게 의존하게 된다. 이는 데이터가 특정 샤드에 치우쳐 있을 경우 성능 병목 현상을 일으킬 수 있다.
Ranged Sharding의 단점을 보안하는 Hashed Sharding 예시
여전히 고객 ID를 샤딩 키로 사용한다고 가정해 보자. Hashed Sharding을 사용할 경우, 각 고객 ID에 대해 해시 함수를 적용하고, 이 해시 값을 기준으로 데이터를 샤드에 할당한다. 예를 들어, 해시 함수의 결과가 0부터 999까지 나올 수 있다고 할 때, 해시 값 0부터 333까지는 샤드 1에, 334부터 666까지는 샤드 2에, 667부터 999까지는 샤드 3에 데이터를 할당하는 방식이다. 이 방식은 샤딩 키 값의 범위에 관계없이 데이터를 균등하게 분산시킬 수 있는 장점이 있다.
Hashed Sharding 단점
범위조건을 검색할 시, 범위조건에 대한 데이터가 모든 샤드에 균등하게 분배되어 있어 성능저하가 발생한다.
-
Zone Sharding: MongoDB에서 지리적 위치, 사용자 그룹, 특정 범위의 데이터 값 등을 기준으로 데이터를 특정 샤드(또는 샤드 그룹)에 명시적으로 할당하는 샤딩 전략이다.
예시
글로벌 온라인 상점: 글로벌 온라인 상점이 다양한 지역에 걸쳐 고객을 가지고 있으며, 각 지역의 고객 데이터를 해당 지역에 더 가까운 데이터 센터에 저장하고자 한다고 가정 해보자. 이 경우, 지역별로 데이터를 분할하여 지역에 가까운 샤드에 데이터를 저장할 수 있다.
예를 들어, 유럽 고객의 데이터는 유럽 데이터 센터의 샤드에, 아시아 고객의 데이터는 아시아 데이터 센터의 샤드에, 북미 고객의 데이터는 북미 데이터 센터의 샤드에 저장된다. 이렇게 구성된 시스템은 다음과 같은 이점을 제공한다.
- 지연 시간 감소: 각 지역의 사용자는 자신의 지역 데이터 센터에 저장된 데이터에 액세스하기 때문에, 데이터 액세스에 필요한 지연 시간이 줄어들어 더 빠른 응답 시간을 경험할 수 있다.
- 규제 준수: 일부 지역에서는 데이터를 해당 지역 내에서만 처리하고 저장하도록 요구하는 법적 규제가 있습니다. Zone Sharding을 사용하면 이러한 요구 사항을 준수할 수 있다.
- 트래픽 분산: 지역별 트래픽의 피크 시간이 다를 수 있다. 각 지역의 데이터가 해당 지역에 위치하면, 시스템은 전체적으로 트래픽 부하를 더 효율적으로 관리할 수 있다.
결론
- Sharded Cluster는 몽고디비의 분산 솔루션이다.
- 컬렉션 단위로 샤딩이 가능하다.
- 샤딩은 샤드키를 선정해야 하고, 해당 필드에는 인덱스가 만들어져 있어야 한다.
- 반드시 Router를 통해 접근한다. (고아 도큐먼트가 발생할 수 있다)
- 가능하면 Hashed Sharding으로 분산한다.
용어정리
- 샤딩: 하나의 큰 데이터를 여러 장비에 걸쳐 분활하는 것 (여러 공간의 분할)
- 샤드: 분활된 데이터의 모음
- 샤드키: 분산이 되는 기준이다. 컬렉션 필드에 생성된 인덱스를 사용한다.
- 파티셔닝: 하나의 큰 데이터를 하나의 장비아래 여러 테이블로 나누는 것
