5.1 소트연산에 대한 이해
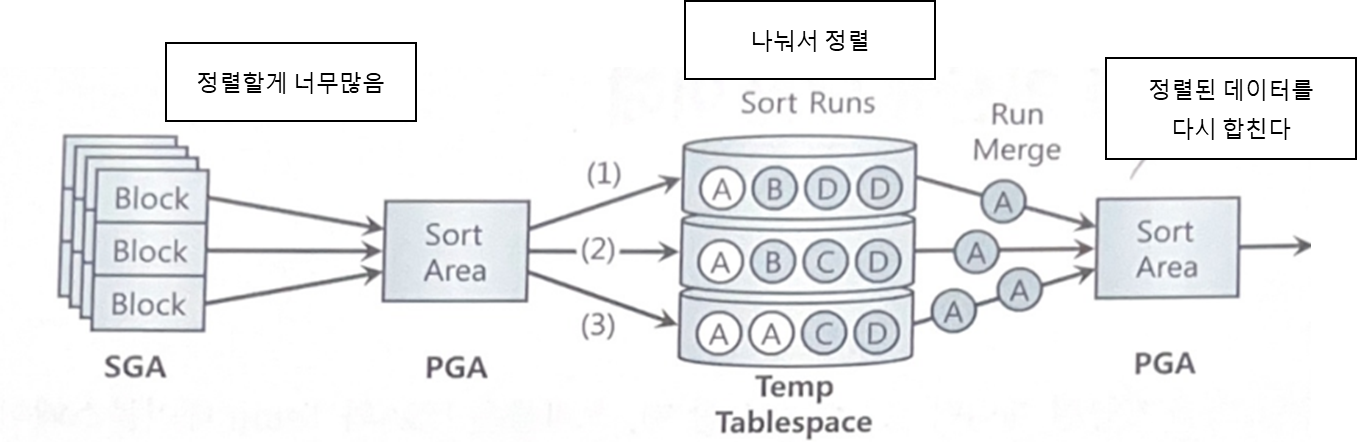
정렬된 최종 집합을 얻으려면 이를다시 Merge 해야한다.
각 Sort Run 내에서는 이미 정렬된 상태이다
소트연산은 메모리집약적일 뿐만 아니라 CPU 집약적 이기도 하다
(계속 정렬하니까 좋지 않음)
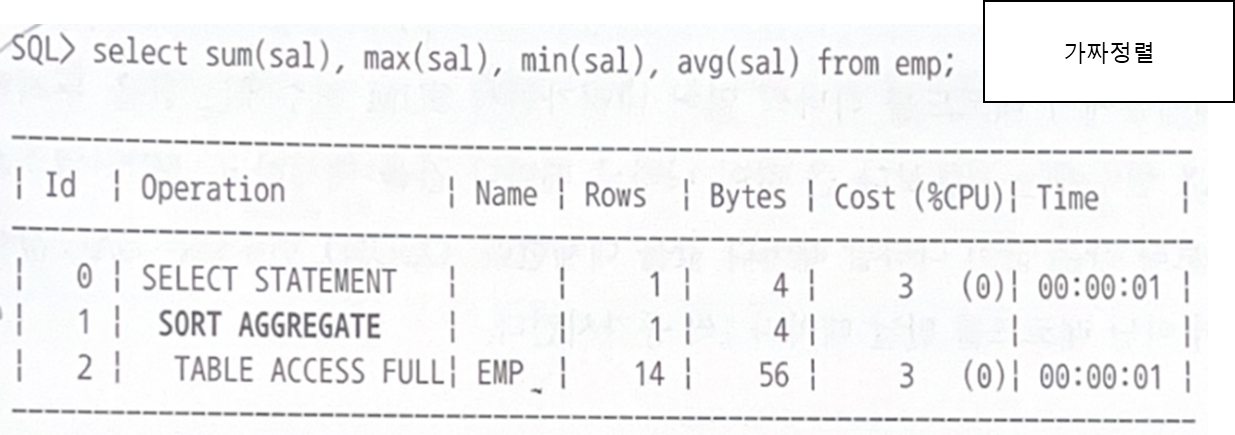
소트 오퍼레이션
sort의 어떤종류가 실행계획에 어떻게 나오는지
Sort Aggregate : 가짜정렬
Sort라는 표현을 사용하지만 실제로 데이터를 정렬하진 않는다
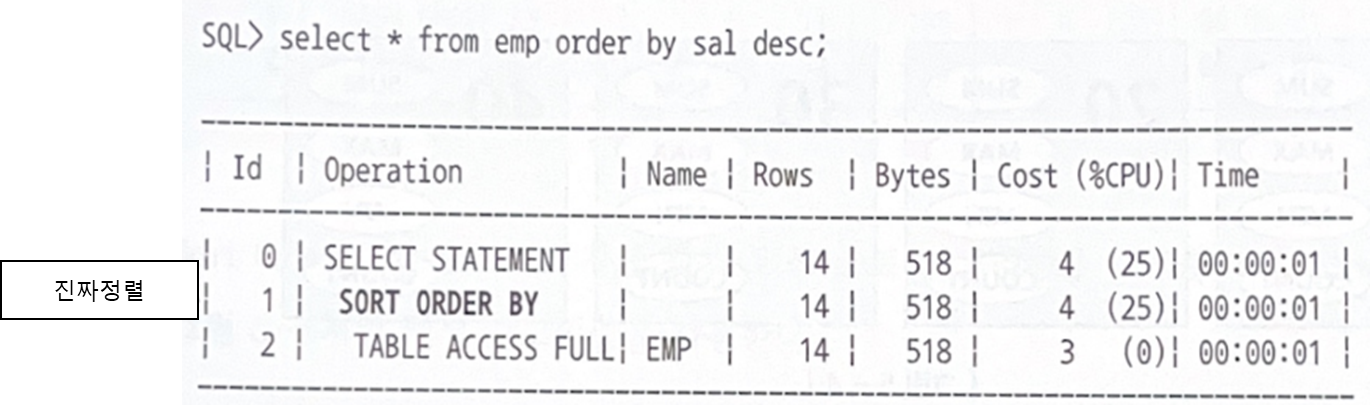
Sort Order By : 진짜정렬
Sort Order By는 데이터를 정렬할 때 나타난다
5.2 소트가 발생하지 않도록 SQL 작성
Union(교집합), Minus(차집합), Distinct(중복제거) 연산자는 중복 레코드를 제거하기 위한 소트 연산을 발생시킨다. 꼭 필요한경우에만 사용해야한다
Union vs Union All
결론: 될수있으면 Union All을 사용해야한다

결제일자와 주문일자가 같은 결제데이터가 중복으로 출력되기때문에 UNION으로 작성해야하지만 소트연산이 일어나지않도록 Union All로 변경하면 결제일자와 주문일자 데이터가 중복해서 출력된다

-- 소트연산이 일어나지 않도록 Union All을 사용하면서도 데이터 중복을 피하는방법
select 결제번호, 결제수단코드, 주문번호, 결제금액, 결제일자, 주문일자...
from 결제
where 결제일자 = '20180316'
UNION ALL
select 결제번호, 결제수단코드, 주문번호, 결제금액, 결제일자, 주문일자...
from 결제
where 주문일자 = '20180316'
and 결제일자 <> '20180316'Exists 활용
중복 레코드를 제거할 목적으로 Dustubct 연산자를 종종 사용하면 조건에 해당하는 데이터를 모두 읽어서 중복을 제거해야하기떄문에 데이터를 읽는과정에서 많은 I/O가 발생한다.
(=부담이 더 많이가니까 Exists를 사용하라)
Exists 서브쿼리는 데이터 존재여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.
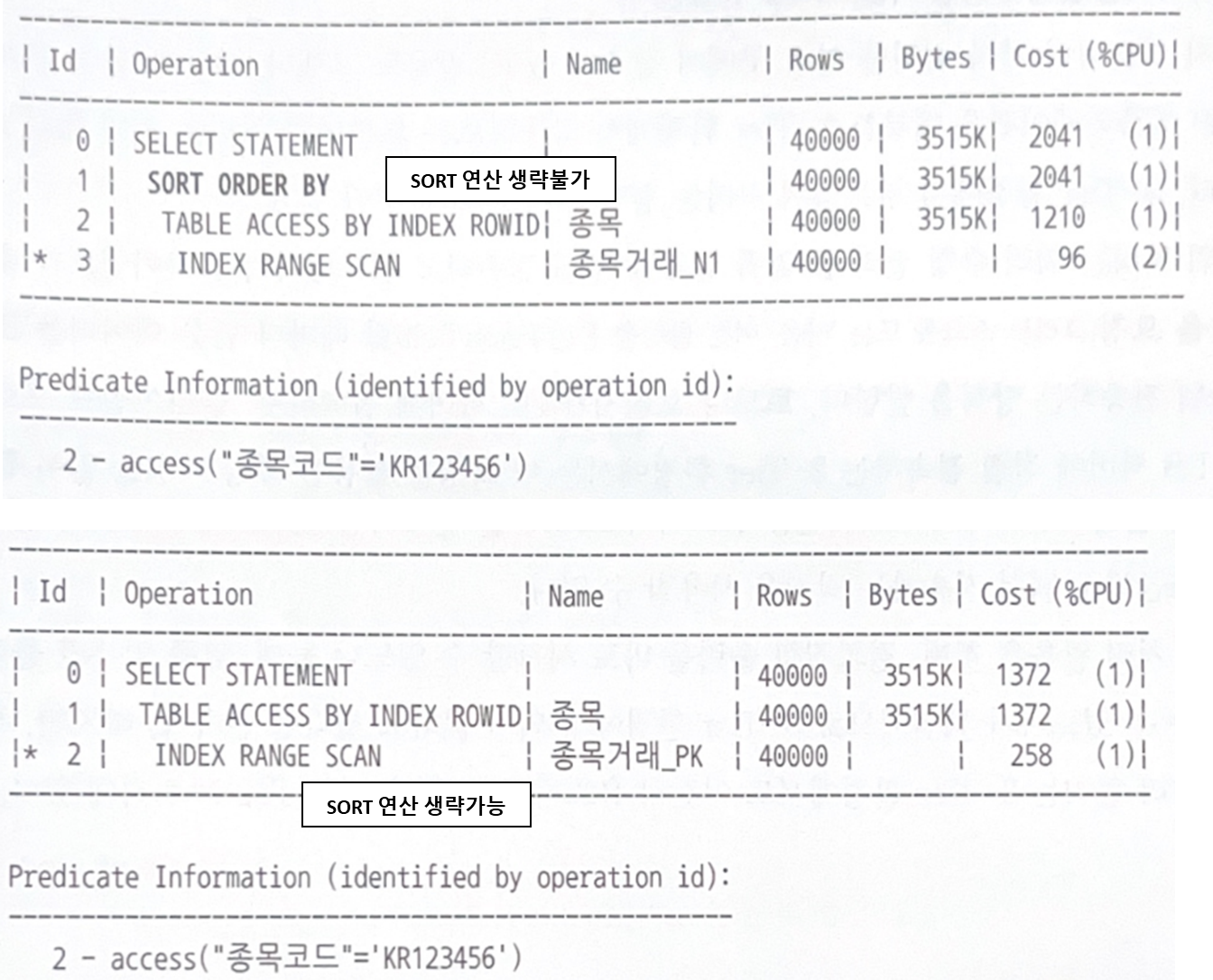
5.3 인덱스를 이용한 소트 연산 생략
TOP N 쿼리
select * from (
select 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20180304'
order by 거래일시
)
where rownum <= 10
-- 정렬먼저 하고 , 몇개를 보여줄건지 rownum을 사용. TOP 10 검색인덱스를 이용해 최소/최대값 구하기
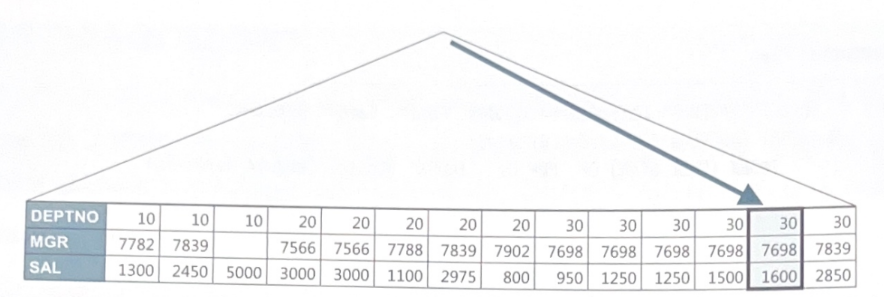
아래는 인덱스를 "DEPTNO + SAL + MGR" 순으로 구성한경우다
DEPTNO = 30조건을 만족할수있는 MAX(SAL)값을 쉽게 찾을수있다.

TOP N쿼리 이용해 최소/최대값 구하기
-- MAX(SAL) 함수 없이 ROWNUM 으로 TOP 1 찾는 방법
CREATE INDEX EMP_X1 ON EMP(DEPTNO, SAL)
SELECT *
FROM (
SELECT SAL
FROM EMP
WHERE DEPTNO = 30
AND MGR = 7698
ORDER BY SAL DESC
)
WHERE ROWNUM <= 1;5.4 Sort Area를 적게 사용하도록 SQL작성
어느쪽이 Sort Area를 적게 사용할까
1번
4. select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(고객명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
1. from 주문상품
2. where 주문일시 between :start and :end
3. order by 상품번호2번
5. select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(고객명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
from (
3. select 상품번호, 상품명, 고객ID, 고객명, 주문일시
1. from 주문상품
2. where 주문일시 between :start and :end
4. order by 상품번호
)2번 쿼리가 데이터를 조금만 가지고 정렬을 실행하므로
2번 SQL이 SORT AREA를 훨씬 적게 사용한다
1번
select * from 예수금원장
order by 총예수금 desc2번
select 계좌번호, 총예수금 from 예수금원장
order by 총예수금 desc1번 SQL은 모든 컬럼을 Sort Area에 저장하지만
2번은 계좌번호와 총예수금만 저장하기 때문에 2번이 Sort Area를 적게사용한다.
Top N 쿼리의 소트예시 (Top N StopKey 알고리즘)
전교생 100명중 가장 큰학생 10명을 선발
1. 전교생을 운동장에 집합
2. 맨앞줄 맨왼쪽에 있는 학생 10명을 키순서대로 세운다
3. 나머지 90명을 한명씩 교실로 들여보내면서 현재 TOP 10 위치에 있는 학생과 키를
비교한다.
더 큰학생이 나타나면 현재 TOP 10 위치에 있는 학생을 교실로 들여 보낸다
4. TOP 10에 새로 진입한 학생 키에 맞춰 자리를 재배치한다.
