AWS S3에서 json으로 저장된 파일을 SQL의 형태로 질의하여 정형 데이터를 가져올 수 있다.
쿼리당 청구로 비용이 산정되며, 쿼리로 스캔된 데이터에 대한 요금만 청구된다.(실패한 쿼리나, DDL(CREATE, DROP) 과 같은 명령에는 비용이 청구되지 않는다.) TB 단위로 청구된다.
사용법
1. 쿼리 결과 저장 설정
- S3에서 쿼리를 저장할 경로를 설정
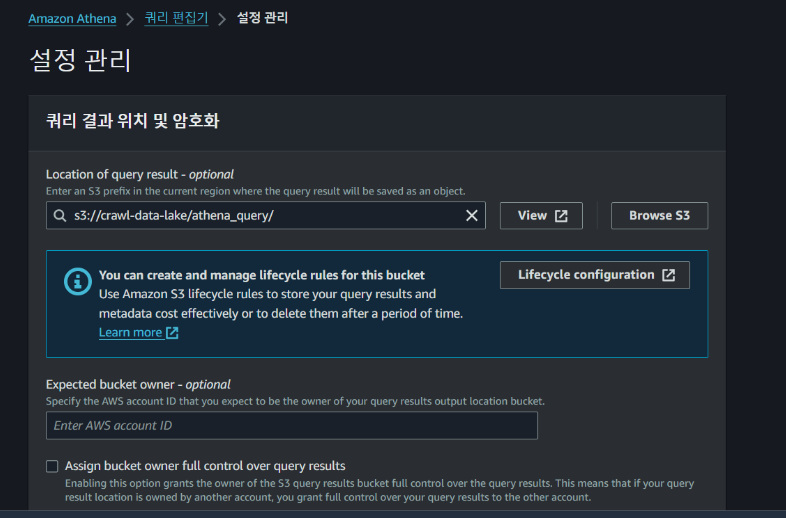
2. 편집기에서 데이터베이스 생성
- 생략가능(Default로 저장되는 데이터베이스가 있음)
CREATE DATABASE rocketpunch;3. 편집기에서 테이블 생성
CREATE EXTERNAL TABLE rocketpunch (
company_id INT,
company_name STRING,
description STRING,
job_id INT,
job_title STRING,
job_career STRING,
timestamp DATE,
crawl_domain STRING,
job_url STRING,
date_end STRING,
date_start STRING,
job_task STRING,
job_specialties STRING,
job_detail STRING,
job_industry STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://crawl-data-lake/rocketpunch/data/';
# 칼럼에 타입값만 넣어줌
# LOCATION에는 가져올 파일의 디렉토리를 설정4. 쿼리 조회
SELECT * FROM rocketpunch limit 5;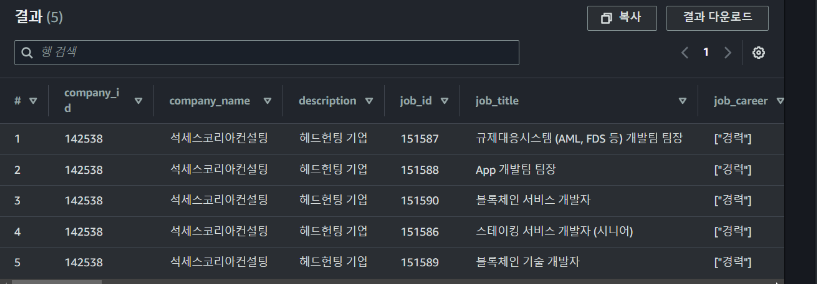

Learner until Ending