
1. 3 Layer (3 계층)
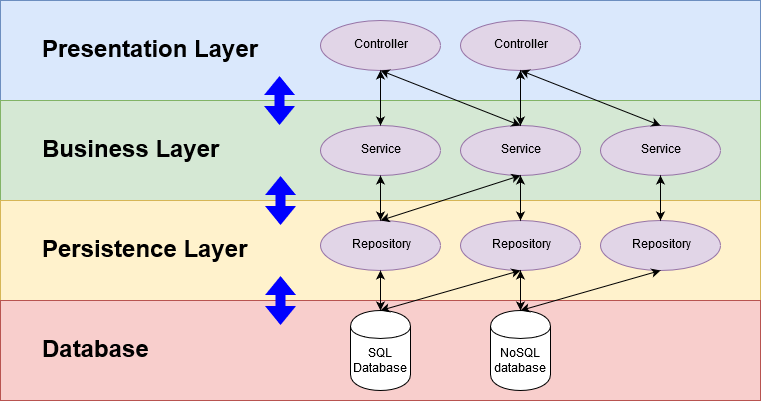
1) Controller
Presentation Layer- 화면에 보여주는 기술을 사용하는 영역.
- 스프링 부트에서 view 영역과 가장 가까운 서버 영역이다.
- 컨트롤러, 뷰, 모델이 포함된다.
- 클라이언트는 필요 정보를 얻기 위해 서버에 요청을 보내는데, 이러한 요청을 받는 API들의 집합이라고 생각하면 된다.
- 즉 프론트 엔드와 백엔드의 소통 창구이기 때문에, 원활한 소통을 위해 개발 전 API 명세 작성과정 등에서 협의가 필요하다.
2) Service
Business Layer- 순수한 비즈니스 로직을 담고있는 영역.
- 고객이 원하는 요구사항을 반영하는 계층이다.
- Presentation Layer와 Persistence Layer의 중간다리 역할을 한다.
- Controller에 의해 호출되어 실제 비즈니스 로직과 트랜잭션(@Transactional)을 처리한다.
- 트랜잭션이란 DB의 상태를 변경시키는 작업 또는 한번에 수행되어야하는 연산들을 의미하며, 트랜잭션이 끝나면 Commit 혹은 Rollbakc된다.
- Repository를 호출하여 JPA를 통해 DB CRUD를 처리하고 필요하다면 정보를 재가공하여 Controller로 리턴한다.
- 정보 변동의 위험이 큰 로직은 service에서 데이터를 옮겨주는 Dto를 통해 진행하는 것이 controller에서 모두 처리하는 것 보다! 안정성 측면에서도, 유지보수성(모듈화) 측면에서도 좋다.
3) Repository
Persistence Layer- 영속 계층 (데이터 계층)으로, 데이터를 어떤 방식으로 보관하고 사용하는 가에 대한 설계가 들어가는 계층이다.
- JpaRepository<>를 상속받아 쿼리문으로 자동 번역되어 날아갈 메서드들을 정의해준다.
- 🔗Jpa Query 모음_스프링Docs
➕ JPA 란?
정의:
Java Persistence API의 약자로 자바 진영의표준 ORM 기술
- ORM은 Object Relational Mapping의 약자로 객체와 RDBMS를 매핑하는 기술을 의미
- JPA를 구현한 프레임워크로는
Hibernate, EclipeseLink, DataNucleus 등이 있다.- 현재 나의 개발환경에 대입해보면 @Entity로 지정한 객체 클래스와 사용중인 H2, 사용할 예정인 MYSQL를 매핑해주는 기술이다. (Hibernate를 사용중이다. HHH000412: Hibernate ORM core version 5.6.9.Final)
JPA를 사용하는 목적
- 과거 스프링MVC 프로젝트에서 사용했던 MyBatis의 단점을 떠올려본다.
- MyBatis를 사용했을 때는 테이블마다 중복되는 SQL 쿼리문을 반복적으로 사용했었다.
- 또한 테이블에 컬럼이 하나 추가된다면 관련된 모든 SQL의 수정이 필요했다.
- 즉 데이터 중심 모델링(테이블 설계)에 무게가 실리며 객체지향의 장점을 못살리고 단순히 객체를 데이터 전달용으로만(VO, DTO) 사용했다.
- 이를 패러다임 불일치라고 한다.
- 따라서 이러한 문제를 보완한! 객체와 테이블을 매핑해주는 JPA의 사용률이 급격히 상승했다!
Hibernate (JPA 구현체)의 장/단점
장점
- 생산성
- SQL을 직접 사용하지 않고, 메서드 호출만으로 쿼리가 수행됨
- 즉, SQL 반복 작업이 없어 생산성이 매우 높음
- 유지보수
- 테이블 컬럼이 변경되었을 경우, MyBatis는 관련 DAO의 파라미터, SQL등을 전부 확인하고 수정해야하지만! JPA는 객체 클래스의 정보만 변경하면 JPA가 알아서 다 처리해준다.
- 특정 벤더에 종속적이지 않다.
- DB 벤더 마다 세부적인 SQL 쿼리문이 조금씩 다르기 때문에 처음 선택한 DB를 나중에 바꾸는 것은 매우 어렵지만,
- JPA는 추상화된 데이터 접근 계층을 제공하기에 특정 벤더에 종속적이지 않다. 따라서 JPA에게 어떤 DB를 사용할 지만 알려주면 된다.
단점
- 성능
- 메서드 호출로 쿼리를 실행하는 것은 raw한 SQL 쿼리를 직접 호출하는 것보다 성능이 떨어진다. (그러나 현재는 계속 발전해가며 성능이 점차 좋아지고 있다고 한다)
- 세밀함
- 메서드 호출로 SQL을 실행하기에 세밀함이 떨어져 의도치 않은 동작을 수행할 수도 있다.
- 러닝커브
- JPA를 사용하려면 당연히 SQL에 대한 선수지식이 필요하다. 내가 호출한 JPA 메서드가 어떠한 SQL 쿼리문을 실행하는 지, 성능은 어떠한 지에 대한 파악은 필수이기 때문이다.
- 하지만 현재 항해에서는 spring에 초점을 두기에 러닝커브가 발생하는 SQL에 대한 학습은 빠져있고, 이를 JPA로 대체했다. 나중을 위해서라면 SQL에 대한 학습은 필수이다!

BackEnd Developer