week 1
Java의 특성
Java는 컴파일 언어이자 인터프리터 언어의 특성을 지닌다.
- 컴파일 언어: 자바 코드는 먼저 javac 컴파일러를 사용하여 바이트코드(.class 파일)로 컴파일된다. 한 번 컴파일된 자바 프로그램은 어떠한 자바 가상 머신(JVM)에서도 실행될 수 있는 "쓰기 한 번, 어디서나 실행(Write Once, Run Anywhere)"의 원칙을 따른다.
- 인터프리터 언어의 특성: 컴파일된 바이트코드는 자바 가상 머신(JVM) 상에서 실행될 때 인터프리터를 통해 해석된다. JVM은 바이트코드를 해당 플랫폼의 기계어로 변환하고 실행하는 역할을 수행한다. ( 이 과정에서 JIT(Just-In-Time) 컴파일러와 같은 최적화 기술을 사용하여 실행 성능을 향상시킬 수 있다. )
Java의 메모리 할당 방식
메서드 영역, 스택 영역, 힙 영역
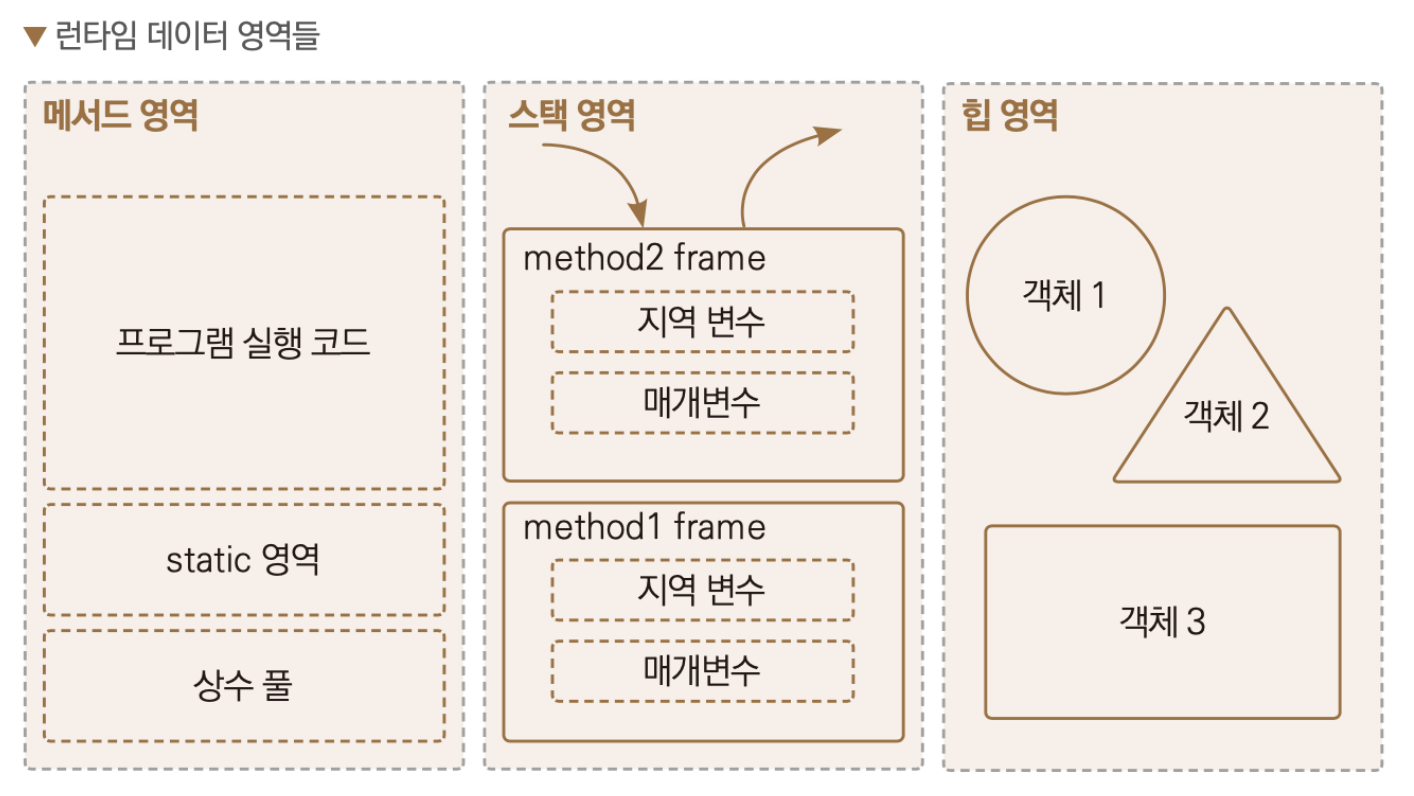
- 메서드 영역: 메서드 영역은 모든 스레드가 공유하는 메모리 영역으로, 클래스 정보, 상수(constant pool), 정적 변수, JIT 컴파일러에 의해 컴파일된 코드 등이 저장된다. 메서드 영역에 저장되는 정보는 클래스 또는 인터페이스를 로딩하는 동안 생성된다. 이 영역은 JVM의 시작과 함께 생성되며, 사용된 모든 클래스와 인터페이스에 대한 메타데이터를 유지한다. 여기에 저장된 데이터는 애플리케이션이 실행되는 동안 지속된다.
- 스택 영역: 스택 영역은 각 스레드마다 별도로 존재하는 메모리 영역으로, 메소드 호출과 로컬 변수에 사용된다. 스택은 메소드 호출 시 마다 각 호출에 대한 스택 프레임을 생성한다. 스택 프레임은 메소드에 대한 정보, 로컬 변수, 그리고 다른 메소드에 대한 참조를 포함한다. (메소드가 종료될 때 해당 스택 프레임은 스택에서 제거된다.) 스택 영역은 LIFO(Last In, First Out) 방식으로 동작하며, 메모리 할당과 해제가 매우 빠르다.
- 힙 영역: 힙 영역은 모든 자바 애플리케이션에 공통으로 사용되는 메모리 영역으로, 인스턴스(객체)와 배열이 할당되는 곳이다. 힙은 런타임에 동적으로 할당되며, 가비지 컬렉터에 의해 관리된다. 객체가 더 이상 참조되지 않을 때, 가비지 컬렉터는 이를 감지하고 메모리를 해제한다. 힙 메모리는 애플리케이션의 생명주기 동안 유지되며, 객체의 크기나 생명주기가 런타임에 결정된다.
String의 특성
다른 참조 자료형과의 비교
- 불변성 대 가변성: 스트링은 불변 객체인 반면, 많은 다른 참조 자료형은 가변적일 수 있다.
- 메모리 관리: 스트링 리터럴은 문자열 상수 풀에서 관리되며 재사용될 수 있다. 반면, 다른 참조 타입의 객체는 힙 메모리에 저장되고 가비지 컬렉터에 의해 관리된다. (여기서 말하는 스트링 리터럴은 new 키워드가 아닌 = 연산자로 바로 생성한 스트링을 말한다.)
- 스트링 리터럴은 원래 메서드 영역의 상수 풀에서 관리되었으나 java7 버전 이후 힙 영역으로 이동했다.
- 인스턴스 생성: 스트링은 리터럴 방식 또는 new 키워드를 사용하여 생성될 수 있지만, 다른 참조 타입은 주로 new 키워드로 인스턴스를 생성한다.
static
static 키워드 사용 시의 메모리 관리 방법과 베스트 프랙티스
static 키워드는 클래스 레벨의 변수나 메소드에 사용되며, 인스턴스가 아닌 클래스 자체와 연결된다. static 변수나 메소드는 해당 클래스의 모든 인스턴스에 의해 공유되며, 클래스가 메모리에 로드될 때 생성되고, 프로그램이 종료될 때까지 메모리에 남아있다. 이는 특정 데이터를 모든 인스턴스가 공유해야 할 때 유용하지만, 메모리 관리 측면에서 주의가 필요하다.
메모리 관리 방법:
한정된 사용: static 변수는 프로그램 실행 동안 계속 메모리를 차지하기 때문에, 필요한 경우에만 사용하는 것이 좋다. 불필요한 static 변수 사용은 메모리 낭비를 초래할 수 있다.
해제 메커니즘 없음: Java와 같은 언어에서는 static 변수를 프로그램 실행 중에 메모리에서 해제할 방법이 없다. 따라서, 대용량의 데이터를 static 변수에 저장하는 것은 피해야 한다.
초기화 블록 사용: static 초기화 블록을 사용하여 static 변수를 초기화할 수 있다. 이는 복잡한 초기화 로직을 수행해야 할 때 유용하다.
베스트 프랙티스:
상수 정의에 사용: static final 키워드를 사용하여 클래스 레벨의 상수를 정의한다. 이러한 상수는 변경될 수 없으며, 클래스의 모든 인스턴스에서 동일한 값을 가진다.
유틸리티 메소드 정의에 사용: 인스턴스 변수에 접근할 필요가 없는 메소드는 static으로 선언하여, 인스턴스 생성 없이 호출할 수 있도록 한다. 예를 들어, 수학적 계산을 수행하는 메소드들은 대부분 static으로 선언한다.
싱글톤 패턴 구현: static 변수를 사용하여 클래스의 단일 인스턴스를 저장하고 관리할 수 있다. 이 방법은 싱글톤 패턴을 구현할 때 자주 사용된다.
자원 관리에 주의: static 변수를 사용하여 생성한 자원(예: 파일 핸들러, 데이터베이스 연결 등)은 프로그램이 종료될 때까지 메모리에 남아 있으므로, 이러한 자원을 적절히 관리하고 해제하는 것이 중요하다.
메모리 누수 방지: static 변수가 객체 참조를 유지하고 있을 경우, 해당 객체는 가비지 컬렉션의 대상이 되지 않아 메모리 누수가 발생할 수 있다. 가능하면 기본 데이터 타입이나 불변 객체를 static 변수로 사용하는 것이 좋다.
Java의 자료 형태
기본자료형(primitive)과 참조자료형(reference)
기본 자료형 (Primitive Types)
기본 자료형은 자바에서 가장 기본적인 데이터 유형으로, 정수, 부동 소수점 숫자, 문자, 불리언 값을 직접 저장한다. 이들은 스택 메모리에 값이 직접 저장되며, 메모리 사용량이 적고 접근 속도가 빠르다. 기본 자료형은 객체가 아니며, 따라서 메소드나 속성을 가지고 있지 않다.
자바에서 제공하는 8가지 기본 자료형은 byte, short, int, long, float, double, char, boolean이다.
참조 자료형 (Reference Types)
참조 자료형은 객체의 참조(메모리 주소)를 저장한다. 이 자료형에는 배열, 클래스, 인터페이스 등이 포함된다. 참조 자료형 변수는 힙 메모리에 저장되는 객체를 가리키며, 변수 자체(객체의 메모리 주소를 저장하는 참조변수)는 스택 메모리에 저장된다. 참조 자료형은 메서드와 속성을 포함할 수 있으며, 사용자 정의 타입을 만드는 데 사용된다.
String, 배열, 래퍼 클래스(wrapper classes) 같은 클래스 인스턴스가 여기에 해당된다. 래퍼 클래스는 기본 자료형을 객체로 감싸는 클래스로, 각 기본 자료형에 대응하는 Integer, Float, Double 등이 있다. 이를 통해 기본 자료형에 대해서도 객체 지향적인 작업을 수행할 수 있다.
주요 차이점
저장되는 내용: 기본 자료형은 실제 값이 스택 메모리에 직접 저장되는 반면, 참조 자료형은 힙 메모리에 저장된 객체의 주소를 스택메모리에 저장한다.
메모리 사용: 기본 자료형은 스택 메모리에 저장되고, 참조 자료형은 객체가 힙 메모리에 저장된다. (참조 변수는 스택 메모리에 저장된다.)
성능: 기본 자료형은 메모리 공간과 처리 시간 측면에서 더 효율적이다.
기능: 기본 자료형은 데이터만 저장할 수 있으며 메서드나 속성을 가질 수 없다. 반면, 참조 자료형(객체)은 메서드와 속성을 가질 수 있다.
기본값: 기본 자료형에는 각 타입에 따른 기본값이 있다(예: int는 0). 반면 참조 자료형의 기본값은 null이다.
int vs Integer
int와 Integer의 차이점
int (기본 자료형)
메모리 사용: int는 스택 메모리에 직접 정수 값이 저장된다. 이로 인해 메모리 사용이 효율적이며, 값에 대한 접근 속도가 빠르다.
기본값: 선언된 int 변수에 별도의 값을 할당하지 않을 경우, 기본값으로 0이 할당된다.
메서드나 속성 없음: int는 기본 자료형이기 때문에, 객체 지향 프로그래밍의 속성이나 메서드를 가지고 있지 않다.
예시: int number = 100;
Integer (참조 자료형)
메모리 사용: Integer는 힙 메모리에 객체 형태로 저장되며, 이 객체를 가리키는 참조가 스택 메모리에 저장된다. 객체로서의 오버헤드가 있기 때문에 int보다 메모리 사용이 더 많을 수 있다.
기본값: Integer 변수에 별도의 값을 할당하지 않을 경우, 기본값으로 null이 할당된다.
메서드와 속성 사용 가능: Integer는 객체이기 때문에, Integer.parseInt(), Integer.valueOf() 등과 같은 유용한 메서드와 속성을 사용할 수 있다.
오토 박싱과 언박싱 지원: 자바 5부터는 int와 Integer 간의 변환을 자동으로 처리하는 오토박싱(automatic boxing)과 언박싱(unboxing)을 지원한다. 예를 들어, Integer 객체에 int 값을 할당하거나 반대의 경우가 이에 해당한다.
예시: Integer number = Integer.valueOf(100);
또는 Integer number = 100; (오토 박싱)
요약하면, int는 효율적인 메모리 사용과 빠른 접근 속도를 제공하는 기본 자료형이며, Integer는 객체 지향의 이점을 제공하는 참조 자료형이다. 사용 상황에 따라 적절한 타입을 선택하는 것이 중요하다.
week 2
Checked / Unchecked(Runtime) Exception
예외를 처리하는 방식과 발생 시점
Checked Exception
정의: 컴파일 시점에 처리해야 하는 예외다. 즉, 컴파일러가 이러한 예외를 명시적으로 처리하도록 요구한다.
목적: 개발자가 안정적인 프로그램을 작성할 수 있도록 돕기 위해, 예외적인 상황을 감지하고 적절히 대응하도록 강제한다.
예시: IOException, SQLException 등
처리 방법: try-catch 블록을 사용하거나, 예외를 던지는 메소드에서 throws 키워드를 사용하여 예외를 명시해야 한다.
Unchecked Exception (Runtime Exception)
정의: 실행 시점(Runtime)에 발생할 수 있는 예외다. 컴파일러는 이러한 예외를 명시적으로 처리하도록 강제하지 않는다.
목적: 프로그램의 오류(버그)로 인해 발생하는 예외적 상황을 처리하기 위해 사용된다. 대부분 프로그램 로직의 오류에서 비롯되며, 개발자가 미리 예측하여 처리하기 어려운 경우가 많다.
예시: NullPointerException, IndexOutOfBoundsException 등
처리 방법: 명시적인 처리를 강제하지 않으므로, 개발자의 선택에 따라 try-catch로 잡거나, 무시하고 넘어갈 수 있다.
+) @Transactional에서의 예외 처리
Spring Framework의 @Transactional 어노테이션은 선언적 트랜잭션 관리를 제공한다. 이 어노테이션을 사용할 때 예외 처리 방식은 다음과 같다:
Checked Exception: @Transactional 안에서 checked exception이 발생하면, 이 예외는 트랜잭션 롤백을 자동으로 유발하지 않는다. 왜냐하면 이미 컴파일 시점에 예외 처리를 강제했기 때문에, 이를 롤백의 사유로 간주하지 않기 때문이다. 명시적으로 롤백 처리를 하고 싶다면, @Transactional(rollbackFor = Exception.class)와 같이 롤백 정책을 지정해야 한다.
Unchecked Exception (Runtime Exception): @Transactional 안에서 unchecked exception (runtime exception)이 발생하면, 스프링은 이를 롤백의 이유로 간주하고 자동으로 트랜잭션을 롤백한다.
+) Runtime Exception 처리 방식에 관한 현업에서의 접근법
실제 개발 현장에서는 unchecked exception을 잡지 않고 그대로 던지는 경우가 종종 있다.
버그 및 로직 오류 해결: Unchecked exception은 대부분 프로그램의 버그나 로직 오류에서 비롯된다. 이러한 오류는 가능한 빨리 감지하고 수정하는 것이 좋으며, 예외를 잡아서 숨기기보다는 발생시 그대로 던져서 로그 등을 통해 명확하게 드러내는 것이 오류 진단과 수정에 유리하다.
코드의 간결성 유지: 모든 예외를 명시적으로 처리하려고 하면 코드가 복잡해지고 가독성이 떨어질 수 있다. 중요하지 않은 예외를 무시하고 중요한 예외에만 집중함으로써, 코드의 간결성과 유지보수성을 향상시킬 수 있다.
GC (Garbage Collection)
Java, Python, Javascript의 GC
Java의 가비지 컬렉션
Java에서는 주로 힙 메모리 영역에서 가비지 컬렉션이 활동한다. 힙 영역은 객체를 저장하는 런타임 데이터 영역으로, 객체가 더 이상 사용되지 않을 때 GC의 대상이 된다.
Java GC의 기본 메커니즘:
가비지 컬렉션의 기준: Java에서 객체가 가비지 컬렉션의 대상이 되는 기준은 '도달 가능성(Reachability)'이다. 즉, 루트 집합(Root Set)에서부터 시작하여 참조를 통해 도달할 수 없는 객체들이 수거 대상이 된다. 루트 집합은 활성 스레드, 정적 변수, JNI(Java Native Interface) 참조 등으로 구성된다.
가비지 컬렉터의 종류와 알고리즘: 여러 종류의 가비지 컬렉터가 있으며, 각각 다른 알고리즘을 사용한다. 주요 가비지 컬렉터로는 Serial GC, Parallel GC, CMS GC, G1 GC 등이 있다. 이들은 마킹-앤-스위핑(Mark-and-Sweep), 복사(Copying), 표시-정리(Mark-and-Compact) 등의 알고리즘을 활용하여 메모리를 관리한다.
GC 작업의 단계: 대부분의 가비지 컬렉션 알고리즘은 '마킹' 단계에서 가비지로 판단된 객체를 식별하고, '스위핑' 또는 '정리' 단계에서 이를 수거한다. 일부 알고리즘에서는 메모리를 효율적으로 사용하기 위해 객체를 이동시키기도 한다.
Python의 가비지 컬렉션
Python의 주 메모리 관리 메커니즘은 참조 카운팅(Reference Counting)이다. 객체에 대한 참조가 생성될 때마다 해당 객체의 참조 카운트가 증가하고, 참조가 소멸되면 참조 카운트가 감소한다. 참조 카운트가 0이 되면, 해당 객체는 메모리에서 해제된다.
그러나 참조 카운팅만으로는 순환 참조(Circular References) 문제를 해결할 수 없다. 따라서 Python은 추가적으로 가비지 컬렉터를 제공하여 순환 참조가 포함된 객체 그룹을 감지하고 수거한다.
JavaScript의 가비지 컬렉션
JavaScript 엔진은 다양하며, 각 엔진은 자체적인 가비지 컬렉션 알고리즘을 구현한다. 그러나 일반적으로 JavaScript의 가비지 컬렉션은 '도달 가능성' 개념을 기반으로 한다.
JavaScript GC의 기본 원리:
글로벌 객체, 현재 실행 중인 함수의 지역 변수와 매개변수, 체인을 통해 접근할 수 있는 변수 등이 '도달 가능한' 객체로 간주된다.
이러한 도달 가능성의 루트에서부터 참조되지 않는 객체는 가비지로 판단되어 수거된다.
각 언어의 가비지 컬렉션 메커니즘은 자동 메모리 관리의 복잡성을 추상화하고, 개발자가 메모리 관리에 신경 쓰지 않도록 돕는다. 하지만 GC 작업은 실행 시점에 오버헤드를 발생시킬 수 있으므로, 효율적인 코드 작성을 통해 불필요한 객체 생성을 최소화하는 것이 좋다.
Generic
Generic 사용 이점
제네릭의 기본 형태
클래스나 인터페이스: class ClassName<T> 또는 interface InterfaceName<T> 여기서 T는 타입 파라미터를 의미한다.
메소드: 메소드에서 제네릭을 사용할 때는 메소드 반환 타입 앞에 타입 파라미터를 선언한다. 예: <T> void methodName(T param)
제네릭을 사용하는 근본적인 이유는 타입 안정성을 제공하는 동시에, 코드의 재사용성을 높이기 위함이다.
타입 안정성(Type Safety)
제네릭을 사용하면 컴파일 시점에 타입 체크를 할 수 있어, 실행 시간에 발생할 수 있는 ClassCastException 같은 오류를 예방할 수 있다. 예를 들어, ArrayList<String>에는 문자열만 추가할 수 있으며, 다른 타입의 객체를 추가하려고 하면 컴파일 오류가 발생한다. 이는 타입 안정성을 강화한다.
코드 재사용성(Code Reusability)
제네릭을 사용하면, 다양한 타입에 대해 동일한 코드를 재사용할 수 있다. 예를 들어, ArrayList<T>를 사용하면, Integer, String, Double 등 어떤 타입의 객체도 저장할 수 있는 유연한 컬렉션을 만들 수 있다. 이는 코드의 재사용성을 높이며, 같은 코드를 여러 타입에 대해 중복해서 작성할 필요를 없애준다.
타입 강제 vs. 유연성
ArrayList<String>처럼 특정 타입을 강제하는 것이 타입 안정성을 보장하는 것처럼 보일 수 있지만, 이는 해당 컬렉션을 문자열만 저장하는 용도로 제한한다. 반면, 제네릭을 사용하면, 컬렉션, 메소드, 클래스 등을 더 유연하게 사용할 수 있다. 제네릭은 타입 파라미터를 사용하여 다양한 타입의 객체를 처리할 수 있는 범용 코드를 작성할 수 있게 해준다. 이는 라이브러리나 프레임워크를 작성할 때 특히 유용하며, 사용자가 자신의 타입을 제네릭 타입으로 전달할 수 있게 해준다.
결론
제네릭의 사용은 단순히 타입 안정성을 넘어서 코드의 재사용성을 높이고, 유연성을 제공한다. 제네릭을 통해 개발자는 보다 안전하고 유지보수가 용이한 코드를 작성할 수 있으며, 다양한 타입으로 작업할 때 발생할 수 있는 일반적인 버그를 컴파일 시점에 잡아낼 수 있다. 따라서, 제네릭은 현대 프로그래밍에서 광범위하게 사용되며, 특히 타입 체크가 중요한 곳에서 그 가치가 더욱 부각된다.
자료구조
Array / LinkedList
Array (배열)
시간 복잡도
접근(Access): O(1). 배열은 인덱스를 통해 각 요소에 직접 접근할 수 있기 때문에 매우 빠르다.
검색(Search): O(n). 특정 값에 대해 전체 배열을 순회해야 하므로 선형 시간이 소요된다.
삽입(Insertion)/삭제(Deletion): O(n). 배열에서 요소를 삽입하거나 삭제하는 경우, 해당 요소 이후의 모든 요소를 이동시켜야 하므로 시간이 많이 소요된다.
자료구조적 특성 및 메모리 저장 방식
배열은 연속적인 메모리 공간에 데이터를 순서대로 저장한다. 이로 인해 배열의 각 요소는 고정된 크기의 메모리 블록을 차지하며, 특정 요소에 대한 인덱스를 사용해 직접 접근이 가능하다. (즉, 임의 접근 / Random Access 가능)
배열의 크기는 생성 시에 정해지며, 크기를 동적으로 변경하기 어렵다. 따라서 초기에 충분한 크기를 설정하거나, 크기 변경이 필요할 때는 새 배열을 생성하고 기존 데이터를 복사해야 하는 단점이 있다.
Java의 ArrayList는 위와 같은 단점을 보완한 동적 배열을 구현한 것!LinkedList (연결 리스트)
시간 복잡도
접근(Access): O(n). 연결 리스트에서는 첫 번째 노드부터 시작해 원하는 위치의 노드까지 순차적으로 탐색해야 하므로 접근 시간이 더 길어진다.
검색(Search): O(n). 배열과 마찬가지로 특정 값을 찾기 위해서는 리스트를 순차적으로 탐색해야 한다.
삽입(Insertion)/삭제(Deletion): O(1). 이미 위치가 정해져 있거나 특정 노드를 알고 있다면, 노드의 연결만 변경하면 되므로 작업이 매우 빠르다. 하지만 특정 위치에 삽입/삭제를 하려면 해당 위치까지 탐색하는 시간이 추가로 O(n)이 소요된다.
자료구조적 특성 및 메모리 저장 방식
연결 리스트는 각 요소(노드)가 데이터와 다음 노드를 가리키는 포인터(또는 참조)를 포함하여, 서로 연결되어 있는 형태로 데이터를 저장한다.
연결 리스트의 노드들은 메모리 상의 연속적인 위치에 저장되지 않아도 되며, 각 노드는 어디에든 존재할 수 있다. 이는 배열과 대비되는 특징으로, 동적으로 크기를 변경하는 것이 매우 쉽다. (순차적 접근 / Sequential Access)
연결 리스트는 추가적인 메모리를 필요로 한다(각 노드의 포인터/참조를 저장하기 위해) 하지만, 데이터의 삽입과 삭제가 빈번하게 발생하는 경우 효율적일 수 있다.
종합
배열은 인덱스를 통한 빠른 접근이 필요하고, 데이터의 크기가 고정되어 있는 경우에 적합하다.
연결 리스트는 데이터의 크기가 동적으로 변하거나 삽입과 삭제가 빈번하게 발생하는 경우 유리하다.
HashSet / HashMap
HashSet과 HashMap은 해시 테이블을 사용하는 자료구조로, 데이터의 저장, 검색, 삽입, 삭제 등을 빠르게 수행할 수 있도록 설계되었다. 이들은 해시 함수를 사용하여 각 요소의 저장 위치를 결정하므로, 이론적으로는 상수 시간(O(1))에 대부분의 연산을 수행할 수 있다. 그러나 해시 충돌이 발생할 경우 이 시간 복잡도가 악화될 수 있다.
해시 충돌(Hash Collision)이란 두 개 이상의 키(Key)가 해시 함수(Hash Function)를 통과했을 때 동일한 해시 값을(해시 코드) 생성하여, 같은 위치(버킷)에 저장되어야 하는 상황을 말한다. 해시 테이블의 기본 원리는 각 키에 대해 해시 함수를 적용하여 고유한 해시 값을 생성하고, 이 값을 사용하여 키-값 쌍을 저장할 위치를 결정하는 것이다. 그러나 모든 키에 대해 고유한 해시 값을 보장하기는 불가능하므로, 해시 충돌은 필연적으로 발생하게 된다.
HashSet
시간 복잡도
접근(Access): HashSet은 접근 연산을 제공하지 않음.
검색(Search): 평균 O(1); 최악의 경우 O(n) (해시 충돌이 많을 때)
삽입(Insertion): 평균 O(1); 최악의 경우 O(n)
삭제(Deletion): 평균 O(1); 최악의 경우 O(n)
자료구조적 특성 및 메모리 저장 방식
HashSet은 해시 테이블을 기반으로 하는 컬렉션으로, 유일한 값을 저장하는 데 사용된다. 각 요소에 대해 해시 함수를 적용하여, 그 결과를 사용해 요소를 저장할 위치를 결정한다.
메모리에서는 이러한 요소들이 해시 테이블 내의 "버킷"이라고 불리는 위치에 저장된다. 이 때 한 버킷에 여러 요소가 할당될 수 있는데, 이는 해시 충돌을 해결하기 위한 메커니즘이다. 해시 충돌이 발생하면, 동일한 버킷 내에 요소들을 연결 리스트 또는 트리 구조로 저장하여 관리한다.
HashMap
시간 복잡도
접근(Access): 평균 O(1); 최악의 경우 O(n) (특정 키에 대한 값을 조회할 때)
검색(Search): 평균 O(1); 최악의 경우 O(n) (특정 키의 존재 여부를 확인할 때)
삽입(Insertion): 평균 O(1); 최악의 경우 O(n)
삭제(Deletion): 평균 O(1); 최악의 경우 O(n)
자료구조적 특성 및 메모리 저장 방식
HashMap은 키-값 쌍을 저장하는 해시 테이블 기반의 자료구조이다. 각 키에 대해 해시 함수를 적용하여, 그 결과를 사용해 키-값 쌍을 저장할 위치를 결정한다.
메모리에서는 이 키-값 쌍들이 내부적으로 해시 테이블의 버킷에 저장된다. 해시 충돌이 발생하는 경우, HashMap은 연결 리스트 또는 균형 이진 탐색 트리를 사용하여 충돌을 관리할 수 있다. Java 8 이후의 HashMap 구현에서는 특정 버킷 내 요소의 수가 많아지면 연결 리스트를 더 효율적인 트리 구조로 전환하여 검색 시간을 개선한다.
해시 테이블의 자료구조적 특성 요약
데이터 저장: 해시 함수를 사용해 데이터의 저장 위치를 결정한다. 이로 인해 대부분의 경우 상수 시간 내에 데이터를 처리할 수 있다.
메모리 사용: 해시 테이블은 메모리 내에 연속적인 공간을 할당하지 않으며, 각 버킷은 독립적으로 요소를 저장한다. 해시 충돌 해결 메커니즘에 따라 추가 메모리 사용이 발생할 수 있다.
해시 충돌 관리: 해시 충돌이 발생할 경우, 연결 리스트 또는 트리 구조를 사용하여 충돌을 관리한다. 이는 최악의 경우 성능을 O(n)으로 떨어뜨릴 수 있지만, 적절한 해시 함수와 크기 조정으로 충돌을 최소화할 수 있다.
HashSet과 HashMap의 성능은 해시 함수의 질과 내부적으로 발생하는 해시 충돌의 관리 방법에 크게 의존한다.
+) 해시충돌 해결 메커니즘
체이닝 기법:
체이닝 방법에서 해시 충돌 처리
체이닝 방법에서는 충돌을 처리하기 위해 각 버킷을 연결 리스트(또는 트리 구조)로 구현한다.
충돌이 발생하면, 즉 여러 키가 해시 함수를 통해 동일한 버킷 위치를 가리킬 때,
해당 버킷의 연결 리스트에 요소를 추가하여 충돌이 발생한 모든 키-값 쌍을 저장한다.
---
이 접근법의 핵심은 각 버킷이 단일 요소 대신 여러 요소를 저장할 수 있는 구조로 확장될 수 있다는 것이다.
해시 테이블의 각 "슬롯"이나 "버킷"이 연결 리스트(또는 기타 동적 자료구조)의 헤드 역할을 하게 되며,
이 리스트에는 같은 버킷에 매핑되는 모든 요소가 저장된다.
---
오픈 어드레스 기법:
오픈 어드레싱 방법에서는 모든 요소를 해시 테이블의 버킷 배열 내에 직접 저장한다.
해시 충돌이 발생하면, 다른 버킷(위치)을 찾아 요소를 저장한다.
이를 위해 여러 가지 탐색 기법(선형 탐색, 이차 탐색, 더블 해싱 등)이 사용될 수 있다.
오픈 어드레싱 방법의 장점은 체이닝 방법에 비해 추가적인 메모리 할당이 필요 없다는 것이다.
하지만, 해시 테이블이 가득 차게 되면 성능이 저하되거나 새로운 요소를 추가할 수 없게 되므로,
적절한 시점에 해시 테이블의 크기를 조정하는 리해싱(Rehashing) 과정이 필요할 수 있다.
---
체이닝 기법은 메모리 사용량이 중요한 고려 사항이 아닌 경우나 해시 테이블의 적재율이 높을 것으로 예상되는 경우에 특히 유리하다.
반면, 메모리 사용을 최소화해야 하는 상황에서는 오픈 어드레싱 방식이 더 적합할 수 있다.Heap / Stack / Queue
Heap
시간 복잡도
접근(Access): O(1) (최대값 또는 최소값 접근)
검색(Search): O(n)
삽입(Insertion): O(log n)
삭제(Deletion): O(log n) (최대값 또는 최소값 삭제)
자료구조적 특성 및 메모리 저장 방식
힙은 완전 이진 트리를 기반으로 하는 자료구조로, 최대 힙(max-heap)과 최소 힙(min-heap)의 두 가지 변형이 있다. 최대 힙에서는 부모 노드의 값이 자식 노드의 값보다 항상 크거나 같으며, 최소 힙에서는 부모 노드의 값이 자식 노드의 값보다 항상 작거나 같다.
메모리에서는 배열을 사용하여 힙을 표현한다. 완전 이진 트리의 특성을 활용하여, 각 요소를 트리의 레벨별로 순차적으로 배열에 저장한다. 이렇게 하면 부모-자식 관계를 배열 인덱스를 통해 쉽게 계산할 수 있다 (예: 인덱스가 i인 요소의 부모는 i/2에 위치하고, 자식은 2i 및 2i+1에 위치함).
Stack
시간 복잡도
접근(Access): O(n)
검색(Search): O(n)
삽입(Push): O(1)
삭제(Pop): O(1)
자료구조적 특성 및 메모리 저장 방식
스택은 LIFO(Last In, First Out) 정책을 따르는 선형 자료구조이다. 가장 마지막에 추가된 요소가 가장 먼저 제거된다.
메모리에서는 동적 배열 또는 연결 리스트로 구현할 수 있다. 동적 배열 구현에서는 배열의 끝을 가리키는 포인터(또는 인덱스)를 사용하여, 요소의 추가 및 제거를 관리한다. 연결 리스트를 사용하는 경우, 리스트의 시작 부분에 요소를 추가하고 제거한다.
Queue
시간 복잡도
접근(Access): O(n)
검색(Search): O(n)
삽입(Enqueue): O(1)
삭제(Dequeue): O(1)
자료구조적 특성 및 메모리 저장 방식
큐는 FIFO(First In, First Out) 정책을 따르는 선형 자료구조이다. 가장 먼저 추가된 요소가 가장 먼저 제거된다.
메모리에서는 연결 리스트 또는 동적 배열을 사용하여 구현할 수 있으며, 각 요소는 순차적으로 저장된다. 연결 리스트를 사용하는 경우, 각 노드는 데이터와 다음 요소를 가리키는 포인터를 포함한다. 동적 배열을 사용하는 경우, 배열의 인덱스를 조절하여 큐의 시작과 끝을 관리한다.
큐는 작업 스케줄링, 스택은 깊이 우선 탐색(DFS) 같은 알고리즘에,
그리고 힙은 우선순위 큐와 같은 상황에서 유용하게 사용된다.week 3
GC 심화
다양한 GC 알고리즘
마크 앤 스윕(Mark and Sweep)
작동 원리: 이 알고리즘은 두 단계로 이루어진다.
- '마크' 단계에서는 모든 도달 가능 객체를 식별하고 마킹한다.
- '스윕' 단계에서는 마킹되지 않은 객체들을 메모리에서 제거한다.
장점: 메모리에서 사용되지 않는 객체를 효율적으로 식별하고 제거한다.
단점: 가비지 컬렉션 도중에 모든 애플리케이션 작업이 중단될 수 있으며(Stop The World), 메모리 단편화가 발생할 수 있다.
참조 카운팅(Reference Counting)
작동 원리: 객체가 다른 객체에 의해 참조될 때마다 참조 카운트를 증가시키고, 참조가 제거될 때마다 감소시킨다. 참조 카운트가 0이 되면 객체를 가비지로 간주하고 메모리에서 해제한다.
순환 참조 문제 해결: 순환 참조는 서로를 참조하는 객체 그룹이 서로의 참조 카운트를 0으로 만들지 못해 메모리에서 해제되지 않는 문제다. 이를 해결하기 위해 약한 참조(Weak References)를 사용하거나, 추가적인 가비지 컬렉션 알고리즘(예: 마크 앤 스윕)을 사용하여 순환 참조를 감지하고 해결할 수 있다.
세대별 가비지 컬렉션(Generational Garbage Collection)
필요성: 대부분의 객체는 생성된 직후 짧은 시간 동안만 사용되는 경향이 있다. 세대별 가비지 컬렉션은 객체를 젊은 세대와 오래된 세대로 분류하여, 젊은 세대에서 더 자주 가비지 컬렉션을 수행함으로써 전체 성능을 향상시킨다.
'Stop The World' 현상
발생 이유: 가비지 컬렉터가 메모리를 정리하는 동안 정확한 메모리 관리를 위해 애플리케이션의 실행을 일시 정지한다.
- 최소화 방법: 증분 가비지 컬렉션, 병렬 가비지 컬렉션, 저우선 순위 스레드에서의 배경 가비지 컬렉션 실행 등의 방법으로 중단 시간을 줄일 수 있다.
실시간 시스템에서의 가비지 컬렉션 최적화
실시간 시스템에서는 가비지 컬렉션으로 인한 지연을 최소화해야 한다. 이를 위해 저지연 가비지 컬렉션 알고리즘을 사용하거나, 가비지 컬렉션 작업을 작은 단위로 나누어 수행하는 증분 GC를 활용할 수 있다.
언어별 가비지 컬렉션 알고리즘
-
자바(Java): 주로 세대별 가비지 컬렉션을 사용하며, 다양한 GC 알고리즘을 제공한다(G1, CMS, Parallel GC 등). 자바는 마크 앤 스윕 방식을 개선한 여러 알고리즘을 사용하여, 큰 힙 메모리와 다중 프로세서 환경에서도 효율적인 메모리 관리를 할 수 있도록 설계되었다.
-
파이썬(Python): 주로 참조 카운팅을 사용하며, 순환 참조를 처리하기 위해 세대별 가비지 컬렉션을 추가적으로 사용한다.
-
자바스크립트(JavaScript): 대부분의 자바스크립트 엔진은 마크 앤 스윕 기반의 세대별 가비지 컬렉션을 사용한다. 이는 메모리 관리를 최적화하고, 'Stop The World' 현상을 최소화하는 데 도움이 된다.
Java의 GC 알고리즘
Parallel GC
주 목적: 처리량(throughput) 최대화
설계 목표: Parallel GC는 멀티 쓰레드 환경에서의 처리량(throughput)을 최대화하기 위해 설계되었다. 이를 위해 가비지 컬렉션 동안 가능한 많은 CPU 코어를 활용하여 작업을 병렬로 처리한다.
작동 방식: 가비지 컬렉션 단계(마킹, 스위핑 등)를 여러 스레드가 동시에 수행하여 처리 시간을 줄인다. 하지만 이 과정 중에는 애플리케이션의 모든 스레드가 일시 중지된다('Stop The World').
적합한 사용 사례: 처리량을 최우선으로 고려하는 대규모 배치 처리 애플리케이션, 백엔드 시스템 등에 적합하다.
CMS (Concurrent Mark Sweep)
주 목적: 응답 시간 최소화
설계 목표: CMS는 'Stop The World' 현상의 지속 시간을 최소화하여 애플리케이션의 응답 시간을 개선하기 위해 설계되었다. (오래된 세대의 가비지 컬렉션을 최적화하여, 애플리케이션의 중단 시간을 줄이는 것에 중점을 둔 것이다.)
작동 방식: CMS는 가비지 컬렉션의 대부분의 단계를 애플리케이션 스레드와 동시에(concurrently) 실행한다. 특히, 마킹 단계와 스위핑 단계의 대부분을 애플리케이션의 실행을 중단하지 않고 수행한다. 그러나 초기 마크 단계와 재마크 단계에서는 짧은 'Stop The World' 이벤트가 발생한다.
단계 별 설명:
- 초기 마크(Initial Mark): STW 이벤트로 시작한다. 이 단계에서는 가비지 컬렉션이 루트 세트에서 직접 참조하는 객체와 그 객체들이 참조하는 객체들을 빠르게 마킹한다. 이는 전체 가비지 컬렉션 과정의 시작점을 설정하는 것이다.
- 동시 마크(Concurrent Mark): 애플리케이션의 실행과 동시에 진행되며, 초기 마크 단계에서 마킹된 객체로부터 도달 가능한 모든 객체를 마킹한다. 이 단계는 애플리케이션의 작업을 중단하지 않고 수행된다.
- 재마크(Remark): 이 단계는 다시 STW 이벤트이다. 동시 마크 단계에서 변경된 참조를 정확하게 파악하고 처리하기 위해 필요하다. 재마크는 가비지 컬렉션 과정 중 발생한 변경사항을 처리하여, 마킹 과정을 완료한다. 이 단계는 최적화 기법(예: 카디널리티 테이블, SATB(Snapshot At The Beginning) 마킹 알고리즘 등)을 사용하여 가능한 짧게 유지된다.
- 동시 스위프(Concurrent Sweep): 재마크 단계 이후에 시작되며, 애플리케이션의 실행과 동시에 진행된다. 이 단계에서는 마킹되지 않은 객체, 즉 가비지 객체를 메모리에서 실제로 제거한다. 스위프 단계는 애플리케이션의 작업을 방해하지 않으므로, 애플리케이션의 응답성에 미치는 영향이 최소화된다.
적합한 사용 사례: 낮은 지연 시간을 요구하는 인터랙티브 애플리케이션, 웹 서버 등에 적합하다.
G1 (Garbage First) GC
주 목적: 지연 시간 최소화 및 대규모 힙 관리
설계 목표: G1 GC는 큰 힙 크기를 가진 멀티 프로세서 시스템에서 'Stop The World' 현상을 예측 가능하게 유지하면서, 가비지 컬렉션에 의한 지연 시간을 줄이기 위해 설계되었다.
작동 방식: G1은 힙을 여러 영역(region)으로 나누고, 각 영역에 대해 가비지 컬렉션을 독립적으로 수행한다. 이를 통해 가장 가비지가 많은 영역부터 우선적으로 수집하여 효율을 극대화한다. 가비지 컬렉션의 대부분은 백그라운드에서 실행되지만, 여전히 짧은 'Stop The World' 이벤트가 발생한다.
단계 별 설명:
- 초기 마크(Initial Mark): STW 이벤트로, 생존 객체의 일부를 마킹한다.
- 루트 리전 스캔(Root Region Scanning): 초기 마크 단계와 동시에 실행된다.
- 동시 마크(Concurrent Mark): 애플리케이션 실행과 동시에 나머지 힙 영역을 스캔하여 생존 객체를 마킹한다.
- 재마크(Remark): STW 단계로, 동시 마크 단계에서 변경된 참조를 처리한다.
- 클린업(Cleanup): 애플리케이션 실행과 동시에 수행되며, 회수할 준비가 된 영역을 식별하고 비운다.
- 실제 회수(Evacuation): STW 이벤트로, 선택된 영역에서 사용되지 않는 객체를 제거하고 생존 객체를 다른 영역으로 이동시킨다.
적합한 사용 사례: 큰 힙을 관리해야 하거나, 가비지 컬렉션으로 인한 지연 시간을 제어해야 하는 애플리케이션에 적합하다.
각 가비지 컬렉션 알고리즘은 특정 상황과 요구 사항에 맞게 설계되었으며, 'Stop The World' 현상은 가비지 컬렉션 과정의 필연적인 부분이다.
young generation 의 GC를 minor GC
old generation 의 GC를 major GC, full GC 라고 칭한다.GC 별 장단점
Parallel Garbage Collector
장점: 여러 스레드를 사용하여 가비지 컬렉션을 병렬로 수행하여 빠른 처리 속도를 제공한다.
대규모 데이터 처리에 적합하며, 고성능을 필요로 하는 애플리케이션에서 유용
단점: 가비지 컬렉션 동안 애플리케이션 스레드가 일시 정지된다 ("stop-the-world" 정지).
정지 시간이 길어질 수 있어 사용자 인터페이스가 민감한 애플리케이션에서는 부적합할 수 있다.
CMS (Concurrent Mark Sweep) Garbage Collector
장점: 가비지 컬렉션의 대부분을 애플리케이션 스레드와 동시에 수행하여 정지 시간을 최소화한다.
응답성이 중요한 애플리케이션에서 유리하다.
단점: 동시성으로 인해 CPU 자원을 많이 사용하며, 이로 인해 전체적인 처리량이 감소할 수 있다.
메모리 조각화 문제가 발생할 수 있고, 이로 인해 긴급 정리 작업이 필요할 수 있다.
CMS (Concurrent Mark Sweep) 가비지 컬렉터에서 메모리 조각화가 발생하는 주된 이유는
이 컬렉터가 객체를 회수하는 방식과 관련이 있다.
CMS는 주로 "마킹"과 "스위핑" 단계로 작동하며,
객체의 재배치나 압축을 하지 않는 방식으로 메모리를 관리한다.
마킹 단계가 완료된 후, "스위핑" 단계가 시작되는데,
이 단계에서는 마킹되지 않은 객체들, 즉 가비지로 식별된 객체들을 힙에서 제거한다.
하지만 중요한 점은, CMS가 가비지 객체를 제거한 후
그 자리를 즉각적으로 재사용하지 않는다는 것이다.
그 결과, 살아남은 객체들 사이에 작은 "공백"이 생기게 된다. ( -> 메모리 조각화)G1 (Garbage-First) Garbage Collector
장점: 힙을 여러 영역으로 나누고, 가장 가비지가 많이 쌓인 영역을 우선적으로 처리하여 더 효율적으로 메모리를 관리한다.
CMS의 문제점인 메모리 조각화와 긴 정지 시간을 해결하려고 설계되었다.
사용자가 정지 시간 목표를 설정할 수 있으며, 이에 맞추어 가비지 컬렉션을 조절한다.
보완 방법: G1은 힙을 여러 개의 소규모 영역으로 분할하여 관리함으로써, 가비지 컬렉션의 필요성이 높은 영역을 우선적으로 처리한다. 이는 전체 힙을 한 번에 정리할 필요 없이, 필요한 부분만 빠르게 정리할 수 있게 해주며, 정지 시간을 짧게 유지할 수 있다.
동시성과 병렬 처리를 적절히 조합하여 CPU 자원 사용을 최적화하고 처리량을 극대화한다.
G1 GC의 동작 메커니즘
G1 가비지 컬렉터는 효율적으로 메모리를 관리하기 위해 힙을 여러 개의 작은 영역(region)으로 나누고, 각 영역의 메모리 사용량과 가비지 수준을 추적한다. G1 컬렉터의 주요 메커니즘과 가비지가 많이 쌓인 영역을 판단하고 처리하는 방법은 다음과 같다:
- 힙의 분할
G1 컬렉터는 힙을 여러 개의 작은 영역으로 나눈다. 이 영역들은 동일한 크기로 구성되며, 각각은 일반적으로 일련의 물리적으로 연속된 메모리 블록이다. 영역들은 다음과 같은 유형으로 분류된다
- Eden: 새 객체가 할당되는 곳.
- Survivor: 최근 가비지 컬렉션에서 살아남은 객체들이 위치하는 곳.
- Old: 오래된 객체가 저장되는 곳.
-
가비지 비율 추적
G1 가비지 컬렉터는 각 영역에서 사용 가능한 공간과 가비지(회수 가능한 객체)의 양을 추적한다. 이 정보는 주로 마킹 단계에서 수집되며, 객체가 살아있는지 여부를 판단하여 메모리 내 위치를 기록한다. -
우선 순위 지정
G1 컬렉터는 "Garbage-First"라는 이름에서 알 수 있듯이, 가비지 비율이 높은 영역을 우선적으로 처리한다. 컬렉터는 가비지 비율이 높은 영역을 식별하고, 이러한 영역에서 가비지 컬렉션을 먼저 수행하여 메모리 회수 효율을 최대화한다. -
복사와 정리
G1 컬렉터는 살아있는 객체만을 새로운 영역으로 복사하고, 이 과정에서 메모리를 압축한다. 이렇게 하면 메모리 조각화를 줄이고, 효율적인 메모리 사용이 가능해진다. -
동시성과 병렬 처리
G1 컬렉터는 여러 단계에서 동시성과 병렬 처리를 활용한다. 마킹과 복사 단계는 여러 스레드를 사용하여 동시에 수행될 수 있으며, 이는 컬렉션 시간을 단축시키고 애플리케이션의 정지 시간을 최소화하는 데 도움을 준다.
G1의 각 영역 별 처리 방식
G1 가비지 컬렉터에서 에덴(Eden), 서바이버(Survivor), 올드(Old) 영역의 처리 방식은 각 영역의 특성과 객체들의 생명 주기에 따라 다르다.
-
에덴(Eden) 영역
에덴 영역은 새로 생성된 객체들이 할당되는 곳이다. 대부분의 객체는 생성 후 금방 접근되지 않게 되므로 ("대부분의 객체는 젊게 죽는다"는 원칙), 가비지 컬렉션이 발생할 때 대량의 객체가 여기서 회수된다.
에덴 영역에서 살아남은 객체들은 서바이버 영역으로 이동한다. -
서바이버(Survivor) 영역
서바이버 영역은 에덴 영역에서 살아남은 객체들이 임시로 저장되는 곳이다. 이 객체들은 몇 차례의 가비지 컬렉션을 거쳐 계속 살아남을 경우 최종적으로 올드 영역으로 승격된다.
서바이버 영역은 일반적으로 두 개의 서브 영역(From Space와 To Space)으로 나뉘어져 있으며, 객체들은 이 두 영역 사이를 이동하며 생존한다. -
올드(Old) 영역
올드 영역은 더 오래 살아남은 객체들이 저장되는 곳이다. 이 영역의 객체들은 이미 여러 차례의 가비지 컬렉션을 거쳐온 것들이기 때문에, 이 영역의 가비지 컬렉션 빈도는 에덴이나 서바이버 영역보다 낮다.
올드 영역의 가비지 컬렉션은 일반적으로 더 많은 시간과 자원을 요구하며, 이 영역에서의 가비지 컬렉션을 "Major GC" 또는 "Full GC"라고 부른다. -
가비지 컬렉션 우선 순위
G1 컬렉터는 가비지의 양이 많은 영역을 우선적으로 처리한다. 하지만, 이 우선 순위는 에덴, 서바이버, 올드 영역 전반에 걸쳐 다르게 적용될 수 있다:
에덴 영역은 객체 회수가 빈번하게 일어나므로 정기적으로 가비지 컬렉션이 수행된다.
서바이버 영역은 객체들이 일정 기간 동안 생존할 수 있도록 관리되며, 필요에 따라 가비지 컬렉션이 수행된다.
올드 영역은 보다 덜 빈번하지만 더 큰 규모의 가비지 컬렉션이 필요할 때 선택적으로 처리된다.
G1 컬렉터는 이러한 각각의 영역들에서 발생하는 가비지의 양과 특성을 고려하여 최적의 성능과 효율성을 유지하도록 설계되어 있다.
최신 GC에 대해..
G1 컬렉터의 단점
복잡성: G1 가비지 컬렉터는 힙을 여러 영역으로 분할하고, 각 영역의 가비지를 추적하는 복잡한 로직을 가지고 있다. 이러한 복잡성은 가비지 컬렉션의 성능 최적화를 위해 많은 튜닝을 필요로 할 수 있다.
CPU 사용량: G1 컬렉터는 여러 단계의 가비지 컬렉션 과정에서 상당한 양의 CPU 자원을 사용할 수 있다. 특히 대규모 힙과 많은 프로세스를 가진 시스템에서는 이러한 CPU 사용량이 문제가 될 수 있다.
메모리 오버헤드: G1 컬렉터는 각 힙 영역의 메타데이터를 관리하기 위해 추가 메모리를 사용한다. 이로 인해 다른 가비지 컬렉터들에 비해 상대적으로 더 많은 메모리 오버헤드가 발생할 수 있다.
가비지 컬렉션 시간 예측의 어려움: 비록 G1이 정지 시간 목표를 설정할 수 있는 기능을 제공하지만, 모든 경우에 이 목표를 정확히 맞추는 것은 어렵다. 특히, 매우 큰 객체나 많은 수의 살아 있는 객체를 처리할 때 예측하기 어려운 성능 저하가 발생할 수 있다.
최신 가비지 컬렉터 ZGC와 Shenandoah
최근에는 G1의 단점을 보완하기 위해 두 가지 새로운 가비지 컬렉터가 등장했다.
- ZGC (Z Garbage Collector):
특징: ZGC는 매우 큰 힙을 대상으로 설계되었으며, 정지 시간을 10ms 미만으로 유지하도록 설계되었다. ZGC는 힙 메모리를 압축하고, 포인터 기반의 가비지 컬렉션으로 메모리 조각화를 방지한다.
장점: 매우 짧은 가비지 컬렉션 정지 시간과 큰 힙에서도 높은 성능을 제공한다.
보완점:
짧은 정지 시간: ZGC는 최대 10ms의 짧은 정지 시간을 목표로 한다. 이는 G1에서 경험할 수 있는 더 긴 정지 시간을 크게 단축시킨다. ZGC는 가비지 컬렉션 동안 대부분의 작업을 동시에 처리하여 애플리케이션의 실행에 거의 영향을 미치지 않는다.
메모리 조각화 방지: ZGC는 힙을 컴팩션하는 과정에서 살아있는 객체들을 논리적 주소 공간에 다시 배치한다. 이 과정은 'colored pointers'와 'load barriers' 기술을 사용하여 구현되어, 메모리 조각화 문제를 효과적으로 해결한다.
스케일링 및 CPU 사용 최적화: ZGC는 크기가 큰 힙과 다중 프로세서 시스템에서도 효율적으로 작동하도록 설계되었다. CPU 자원을 효율적으로 사용하며, 병렬 처리를 최대화하여 성능을 높인다. - Shenandoah:
특징: Shenandoah 역시 G1의 낮은 정지 시간 목표를 달성하기 위해 설계되었으나, 가비지 컬렉션 동안 애플리케이션 스레드가 계속 실행될 수 있도록 향상된 동시성 메커니즘을 사용한다.
장점: 매우 짧은 정지 시간을 제공하며, 메모리 조각화를 최소화한다.
보완점:
극도로 짧은 정지 시간: Shenandoah는 G1과 유사하게 저지연 가비지 컬렉션을 목표로 하지만, 더욱 발전된 동시성을 통해 정지 시간을 극단적으로 줄인다. Shenandoah는 마킹, 정리 및 압축 단계에서도 애플리케이션 스레드와 거의 동시에 작업을 수행하여 정지 시간을 최소화한다.
메모리 조각화 방지: Shenandoah 역시 ZGC처럼 살아있는 객체들을 새로운 위치로 이동시키면서 메모리를 압축한다. 이는 조각화된 메모리를 효과적으로 재구성하여 효율성을 높이고, 큰 객체를 위한 연속된 공간 확보가 가능하게 한다.
CPU 및 메모리 오버헤드 최적화: Shenandoah는 고도의 동시성을 활용하여 CPU 자원을 균등하게 사용한다. 이는 G1에서 경험할 수 있는 높은 CPU 사용의 피크를 피하면서도, 전반적인 시스템 성능을 유지한다. 또한, Shenandoah는 G1 대비 더 효율적인 메모리 오버헤드 관리를 통해 작은 힙 크기에서도 효과적으로 작동할 수 있다.
week 4
Thread
개념
- 스레드는 가장 작은 실행 단위로, 프로세스 내에서 동작하는 여러 실행 경로 중 하나이다.
- 각 스레드는 독립적인 실행 경로를 가지지만, 프로세스의 메모리와 자원은 다른 스레드와 공유한다.
Process와 비교
- 스레드
- 정의: 프로세스 내의 실행 흐름, 같은 프로세스 내의 다른 스레드와 메모리 및 자원을 공유.
- 메모리 및 자원: 프로세스의 메모리 공간을 공유하지만, 스레드마다 별도의 스택을 가짐.
- 통신: 동일 프로세스 내에서 데이터 공유가 쉬움, 별도의 IPC 필요 없음.
- 생성 및 관리 비용: 낮은 생성 및 관리 비용, 이미 존재하는 프로세스의 자원을 활용.
- 독립성: 낮은 독립성, 하나의 스레드 문제가 전체 프로세스에 영향을 줄 수 있음.
- 성능: 빠른 컨텍스트 스위칭과 자원 공유로 더 높은 성능을 제공할 수 있음.
- 프로세스
- 정의: 독립적인 실행 단위, 자신만의 메모리 공간을 가진 프로그램의 인스턴스.
- 메모리 및 자원: 독립적인 메모리 공간(힙, 코드, 데이터, 스택 등)을 가짐.
- 통신: IPC(Inter-Process Communication)를 통해 통신, 예를 들어 파이프, 소켓, 공유 메모리 등.
- 생성 및 관리 비용: 상대적으로 높은 생성 및 관리 비용, 독립적인 메모리 공간 할당으로 인해 오버헤드 큼.
- 독립성: 높은 독립성, 한 프로세스의 실패가 다른 프로세스에 영향을 주지 않음.
- 성능: 자원 독립성으로 인해 전환 비용이 높아 성능 저하 가능성 있음.
멀티 스레드
-
하나의 애플리케이션 내에서 여러 스레드가 동시에 작업을 수행하는 기법으로, 각 스레드는 동일한 메모리 공간을 공유하면서 독립적인 작업을 실행한다. 이는 자원의 효율적 사용과 동시에 여러 작업을 처리할 수 있는 능력을 제공한다.
-
멀티스레딩의 주의사항
-
오버헤드:
멀티스레딩은 스레드의 생성과 관리, 컨텍스트 스위칭에 추가적인 계산 비용을 발생시킨다. 특히 작업이 작거나 수행 시간이 짧은 경우, 스레드 관리에 드는 비용이 실제 작업의 성능을 저하시킬 수 있다. -
자원 사용 및 경합:
멀티스레드 환경에서는 여러 스레드가 동시에 자원에 접근하려 할 때 자원 경합 상태가 발생할 수 있다. 이는 데이터의 일관성을 해치거나 입출력 자원의 부족을 초래할 수 있으며, 프로그램의 안정성과 성능에 부정적인 영향을 미칠 수 있다. -
복잡성 및 버그의 가능성:
멀티스레딩의 구현과 유지 관리는 복잡하며, 동기화 문제, 데드락, 레이스 컨디션 등의 버그를 초래할 가능성이 높다. 이러한 문제들은 디버깅이 매우 어려울 수 있으며, 때로는 심각한 시스템 오류를 야기할 수 있다.
-
따라서 멀티스레딩은 아래 사항을 고려해봐야 한다.
성능 테스트 및 프로파일링: 멀티스레딩을 적용하기 전에
애플리케이션의 성능을 테스트하고 프로파일링을 통해
멀티스레딩이 실제로 성능 향상에 도움이 되는지 검증해야 한다.
설계 단계에서의 고려: 멀티스레딩을 도입할 때는
애플리케이션의 요구 사항과 환경을 면밀히 평가하고,
각 스레드의 역할과 자원 사용을 명확히 해야한다.
적절한 동기화 도구 사용: 공유 자원에 대한 접근을 관리하기 위해
락, 세마포어, 모니터 등과 같은 동기화 메커니즘을 적절하게 사용해야 한다.
단, 동기화는 성능을 저하시킬 수 있으므로 주의해야 한다.싱글 스레드 VS 멀티 스레드
- 싱글 스레드가 우세한 케이스
- 간단한 순차적 작업:
- 프로그램의 작업이 단순하고 순차적으로 진행되며, 병렬 처리로 인한 이점이 없는 경우.
- 예: 간단한 데스크탑 애플리케이션, 텍스트 편집기, 계산기 프로그램 등.
- 리소스가 제한된 환경:
- 시스템의 자원(예: 메모리, 처리 능력)이 매우 제한적인 환경에서는 멀티 스레딩의 오버헤드가 오히려 성능 저하를 초래할 수 있음.
- 예: 임베디드 시스템, 일부 모바일 애플리케이션.
- 간단한 순차적 작업:
- 멀티 스레드가 우세한 케이스
- I/O 바운드 작업:
- 하나의 스레드가 I/O 작업(디스크 I/O, 네트워크 통신 등)으로 블록될 때, 다른 스레드가 CPU를 활용하여 작업을 계속 수행할 수 있어 전체적인 응답성과 처리량이 향상될 수 있음.
- 예: 파일 다운로드, 데이터베이스 작업 등 대규모 I/O 요구 작업을 처리하는 서버.
- CPU 집약적 작업:
- 멀티코어 CPU를 활용하여 복수의 스레드가 동시에 실행되며, 작업 처리 시간을 단축시킬 수 있음.
- 예: 과학적 계산, 데이터 분석, 이미지 처리, 비디오 렌더링 등.
- 단! 컨텍스트 스위칭의 오버헤드를 관리하며, CPU 자원을 최대한 활용하기 위해 스레드 수와 CPU 코어 수의 균형을 맞추는 것이 중요. (스레드의 수가 CPU 코어 수를 초과하면 컨텍스트 스위칭에 따른 오버헤드로 인해 성능이 저하될 수 있음)
- 대화형 및 네트워크 애플리케이션:
- 사용자 인터페이스가 빠른 응답성을 유지하면서 백그라운드에서 데이터 처리나 다운로드를 진행해야 하는 경우.
- 동시에 많은 클라이언트 요청을 처리해야 하는 웹 서버의 경우.
- 예: 웹 서버, 복잡한 그래픽 편집 소프트웨어, 대화형 게임 등.
- I/O 바운드 작업:
그렇다면 멀티스레드는 항상 우세할까?
멀티스레드 방식이 싱글스레드 방식보다 우세하다고 생각하기 쉽지만, 멀티스레드 방식 또한 트레이드 오프를 지닌다.
- 임계 영역에 대한 동기화 비용
- 동시성 문제를 방지하기 위해 락을 사용한다면 락 획득 및 해제 작업에 추가적인 시간이 소요되며, 나머지 스레드의 실행을 중지하거나, 대기하게 만들어야 하므로 프로그램의 성능이 저하될 수 있다.
- 여러 개의 스레드가 동시에 공유하는 메모리나 데이터에 대해 수정을 가할때 특정 CPU 코어의 캐시에 저장된 데이터와 다른 CPU 코어의 캐시에 저장된 데이터가 일치하지 않는 경우가 발생한다. 이럴 경우, 다른 CPU 코어에서 변경한 데이터가 현재 CPU 코어의 캐시에 반영되지 않은 상태로 사용되어 문제가 발생할 수 있어, CPU 캐시에서 데이터를 불러오는 비용이 발생하므로 성능에 영향을 미치게 된다.
- 단, 멀티코어가 탑재된 프로세서의 경우 멀티 스레드가 우세하다. 위의 내용은 무조건 적으로 우세하다고 볼 수 없는 트레이드 오프에 관한 내용이다.
- 컨텍스트 스위칭 오버헤드
- CPU가 현재 프로세스나 스레드의 상태를 저장하고 다른 프로세스나 스레드로 전환될 때 발생하는 비용을 의미한다. 이 스위칭 하는 과정에서 CPU 시간과 자원을 소모하므로 성능에 영향을 미치게 된다.
- 하지만 이 역시 트레이드 오프의 관점이다. 멀티 스레드는 CPU 코어를 효율적으로 활용하기 때문에 아주 옛날의 싱글 코어 프로세서가 아닌 이상 멀티 스레드의 컨텍스트 스위칭 오버헤드쪽이 더 느리다고 단언할 수는 없다.
- 잔여 스레드의 리소스 낭비
- 멀티 스레드 어플리케이션에서 이용률이 한산하여 스레드를 한두개 밖에 이용하지 않을때, 나머지 잔여 스레드들이 CPU, 메모리, 네트워크 등의 자원을 불필요하게 점유해서 성능 저하나 오류의 원인이 될 수 있다.
- 그런데 놀고 있음에도 CPU는 다른 스레드에게 CPU 시간을 양도하도록 설계 되어 있기 때문에 노는 스레드와 다른 스레드 간에 컨텍스트 스위칭을 하여 CPU의 효율성을 떨어뜨린다. 즉, 스레드가 작업을 수행하지 않더라도 존재 자체만으로 여전히 리소스를 소비하고 오버헤드를 생성하기 때문에 잔여 스레드의 문제는 결코 가볍지 않다.
- 따라서 노는 스레드의 개수를 최소화하고, 스레드 풀(Thread Pool)과 같은 매커니즘을 사용하여 스레드의 개수를 관리하여 리소스 낭비를 최소화하는 것이 중요하다.
- 어플리케이션 성격에 따른 제약
- CPU 바운드 어플리케이션: 오라클에서 아키텍트로 일하고 있는 Goetz가 2002, 2006년에 발표한 자바 병렬 프로그래밍에 관한 책과 논문에 따르면 CPU 바운드 작업에서 적절한 스레드 수는 코어 수 + 1 이라고 주장했다.
- CPU 바운드 어플리케이션은 cpu를 많이 쓰기 때문에 코어수와 비슷한 수준 이상으로 스레드 수를 늘려봤자 별 이점이 없으며, 오히려 각 코에서 쓰레드 수가 많아질수록 컨텍스트 스위칭 때문에 오버헤드만 더 많아져서 성능이 안 좋은 영향을 주게 된다. 그래서 스레드의 개수가 적절하게 설정되어야 최적의 성능을 얻을 수 있다.
- I/O 바운드 어플리케이션: 멀티 스레드는 I/O 작업이 처리될 동안 다음에 이행할 작업들을 다른 스레드에게 자원을 할당하여 수행할 수 있도록 할 수 있다. 네트워크 통신도 마찬가지로 네트워크 상황에 따라 전송 시간이 오래 걸릴 수 있으므로 통신 지연동안 스레드를 재활용 한다.
- 따라서 I/O 작업이 많은 상황에서는 CPU 코어 수보다 2배 3배 혹은 그 이상으로 스레드 수를 늘려주는 것이 코어들을 더 효율적으로 쓸 수 있기 때문에 성능 면에서 이점이 얻을 수 있다. 그러나 우리가 앞서 배웠듯이 스레드를 늘리면 늘릴수록, 잔여 스레드의 컨텍스트 오버헤드와 동기화 등의 문제점이 동반 될 수 있기 때문에, I/O 바운드 어플리케이션에 멀티 스레드 모델 대신 비동기 I/O 처리에 특화된 이벤트 기반 프로그래밍 모델을 접목하기도 한다.
- CPU 바운드 어플리케이션: 오라클에서 아키텍트로 일하고 있는 Goetz가 2002, 2006년에 발표한 자바 병렬 프로그래밍에 관한 책과 논문에 따르면 CPU 바운드 작업에서 적절한 스레드 수는 코어 수 + 1 이라고 주장했다.
- 프로그래밍 난이도
- 멀티스레드는 싱글스레드에 비해 프로그래밍 과정에서 관리해야할 포인트들이 많다.
동시성 문제
- 스레드의 동시성 문제란 여러 스레드가 동시에 같은 자원에 접근할 때 발생하는 문제들을 말한다. 이러한 문제는 데이터의 불일치, 예상치 못한 결과, 프로그램의 잘못된 동작 등을 초래할 수 있다.
주요 동시성 문제들
-
경쟁 상태 (Race Condition):
- 정의: 두 개 이상의 스레드가 데이터를 동시에 읽거나 쓰려고 할 때, 그 순서에 따라 실행 결과가 달라지는 현상.
- 해결 방법:
- 락(Locks): 공유 자원에 대한 접근을 동기화하여 한 시점에 하나의 스레드만 접근할 수 있도록 한다.
- 세마포어(Semaphores): 카운터를 사용하여 제한된 수의 스레드만 자원에 접근할 수 있도록 제어한다.
- 모니터(Monitors): 객체 내에 동기화 메커니즘을 포함시켜 스레드간의 상호작용을 관리한다. 모니터는 자동적으로 락 관리를 수행하며, 객체의 메소드를 호출할 때 내부적으로 락을 획득하고 메소드 실행이 완료되면 락을 해제한다. 모니터 내부에서는 조건 변수도 사용할 수 있어, 특정 조건이 충족될 때까지 스레드가 대기하도록 할 수 있다. 이는 데드락 회피와 자원 효율성 증대에 도움을 준다.
-
데드락 (Deadlock):
- 정의: 두 개 이상의 스레드가 서로의 작업이 끝나기를 무한히 기다리는 상황으로, 결국 어떤 스레드도 진행할 수 없는 상태.
- 해결 방법:
- 자원 할당 순서 정의: 모든 스레드가 자원을 일정한 순서로만 요청하도록 하여 순환 대기를 방지한다. 순환 대기는 데드락의 네 가지 필요 조건 중 하나로, 각 스레드가 순환적으로 다음 스레드가 요청한 자원을 보유하고 있어야만 발생한다. 자원 할당에 일정한 순서를 두면, 스레드가 순환적으로 다른 스레드의 자원을 기다리는 상황을 피할 수 있다.
- 자원 할당 제한: 한 번에 하나의 자원만 요청할 수 있도록 제한하여 데드락 가능성을 줄인다.스레드가 필요로 하는 모든 자원을 한꺼번에 요청하고, 그 중 하나라도 사용할 수 없다면 모든 요청을 취소하고 나중에 다시 시도하는 방식이다. 이 접근 방식은 자원이 서로 겹치는 요구가 많은 시스템에서 특히 유용하다.
- 데드락 감지 및 회복: 데드락 발생을 감지하고, 자원을 강제로 회수하여 데드락을 해결한다. 일반적으로 자원 할당 그래프를 분석하여 데드락의 존재를 확인한다. 감지된 데드락을 해결하기 위해서는 일부 스레드를 종료하거나 일부 자원 할당을 강제로 취소하여 자원을 해제하는 방식을 사용한다. 이는 시스템에 부하를 줄 수 있으며, 때로는 사용자 작업에 영향을 줄 수 있기 때문에 섬세한 처리가 필요하다.
-
라이브락 (Livelock):
- 정의: 스레드들이 계속해서 상태를 변경하지만, 실제로는 어떠한 진행도 이루어지지 않는 상태.
- 해결 방법:
- 랜덤화 기법: 스레드가 자원을 요청할 때 무작위 대기를 도입하여 충돌 가능성을 줄인다. 즉, 스레드가 자원에 접근하려 할 때 또는 특정 상태로 전환하기 전에 무작위로 대기 시간을 적용한다. 이는 스레드들이 항상 동시에 같은 자원을 요청하지 않도록 하여 충돌의 가능성을 줄인다
-
스타베이션 (Starvation):
- 정의: 하나 이상의 스레드가 자원을 필요로 하지만 다른 스레드가 계속해서 자원을 점유하여 영원히 자원을 사용하지 못하는 상태.
- 해결 방법:
- 우선순위 할당: 우선순위가 낮은 스레드도 공정하게 자원을 할당받을 수 있도록 우선순위를 조정한다. 우선순위 인버전 문제를 해결하기 위해 우선순위 상속(priority inheritance) 또는 우선순위 천장(priority ceiling) 프로토콜 같은 전략을 사용할 수 있다. 이러한 전략은 낮은 우선순위의 스레드가 높은 우선순위의 자원을 점유하고 있을 때, 해당 스레드의 우선순위를 일시적으로 높여 자원을 빠르게 해제하도록 돕는다.
- 라운드 로빈 스케줄링: 각 스레드가 동등한 시간 동안 자원을 사용할 수 있도록 순환 스케줄링을 사용한다. 모든 스레드가 균등한 기회로 자원을 접근할 수 있게 하여 스타베이션 문제를 효과적으로 방지할 수 있다.
스레드 심화
Lock 인터페이스와 synchronized 블록의 차이
- 기본 동작 및 사용법.
- synchronized 블록:
- synchronized 키워드는 메소드 전체 또는 특정 객체에 대한 블록을 동기화하는 데 사용된다.
- synchronized는 객체의 모니터 락을 사용하여 동기화를 수행한다. 메소드나 블록에 진입하는 스레드는 락을 획득하고, 블록이나 메소드를 빠져나갈 때 락을 자동으로 해제한다.
- Lock 인터페이스:
- Lock 인터페이스는 java.util.concurrent.locks.Lock 패키지에 포함되어 있으며, 더 세밀한 락 관리를 가능하게 한다.
- Lock을 사용하려면 Lock 객체를 명시적으로 생성하고, 락을 획득(lock())하고 해제(unlock())하는 메소드를 직접 호출해야 한다.
- Lock 인터페이스는 락 획득 시 시간 제한을 설정하거나, 인터럽트를 허용하는 락 획득 등 추가적인 기능을 제공한다.
- 유연성 및 기능
- 유연성:
- Lock 인터페이스는 락을 보다 유연하게 관리할 수 있도록 해준다. 예를 들어, 락을 시도적으로 획득할 수 있으며(tryLock()), 락을 획득할 때 타임아웃을 설정하거나 인터럽트를 처리할 수 있다.
- tryLock(): 메소드는 락을 즉시 획득하려 시도하고, 락을 획득할 수 없으면 즉시 false를 반환한다. 이는 블로킹 없이 락의 상태를 검사하고, 다른 작업으로 넘어갈 수 있게 해준다. 또한, tryLock()은 타임아웃을 설정할 수 있는 오버로드 버전을 제공하여, 지정된 시간 동안만 락을 획득하려 시도하고 시간이 초과하면 실패한다. 이 기능은 리소스에 대한 접근을 기다리는 시간을 제한하여 애플리케이션의 반응성을 향상시키는 데 유용하다.
- lockInterruptibly(): 스레드가 락을 기다리는 동안 인터럽트에 반응하여 락 대기 상태에서 벗어날 수 있게 해준다. 이는 스레드가 데드락 상태에 빠지는 것을 방지하고, 더 중요한 작업을 위해 대기를 중단할 수 있는 기능을 제공한다.
- synchronized는 메소드나 지정된 블록에 대해서만 락을 설정할 수 있으며, 락의 획득과 해제는 자동으로 처리된다.
- Lock 인터페이스는 락을 보다 유연하게 관리할 수 있도록 해준다. 예를 들어, 락을 시도적으로 획득할 수 있으며(tryLock()), 락을 획득할 때 타임아웃을 설정하거나 인터럽트를 처리할 수 있다.
- 추가 기능:
- Lock 인터페이스는 read/write 락과 같은 고급 동기화 기능을 제공한다. 이는 읽기 작업과 쓰기 작업이 동시에 일어나는 애플리케이션에 유용하게 사용될 수 있다.
- Read/Write Lock: java.util.concurrent.locks 패키지의 ReentrantReadWriteLock 클래스는 읽기 락과 쓰기 락을 구분하여 더 세밀한 락 관리를 가능하게 한다. 이 기능은 읽기 작업이 많고 쓰기 작업이 비교적 적은 애플리케이션에서 유용하다.
- 읽기 락(Read Lock): 읽기 락은 여러 스레드가 동시에 데이터를 읽을 수 있게 허용한다. 읽기 작업은 데이터의 일관성을 유지하면서 동시에 수행될 수 있기 때문에, 읽기 락을 사용하면 성능을 크게 향상시킬 수 있다.
- 쓰기 락(Write Lock): 쓰기 락은 단 한 스레드만 데이터를 수정할 수 있도록 제한한다. 이 락이 활성화되어 있는 동안 다른 스레드는 해당 데이터에 대한 읽기 또는 쓰기 작업을 수행할 수 없다. 이는 데이터가 변경되는 동안 일관성과 무결성을 유지하는 데 중요하다.
- Read/Write Lock: java.util.concurrent.locks 패키지의 ReentrantReadWriteLock 클래스는 읽기 락과 쓰기 락을 구분하여 더 세밀한 락 관리를 가능하게 한다. 이 기능은 읽기 작업이 많고 쓰기 작업이 비교적 적은 애플리케이션에서 유용하다.
- Lock 인터페이스는 read/write 락과 같은 고급 동기화 기능을 제공한다. 이는 읽기 작업과 쓰기 작업이 동시에 일어나는 애플리케이션에 유용하게 사용될 수 있다.
멀티스레드 환경에서 데드락을 방지하는 전략
- 데드락 예방 (Deadlock Prevention)
데드락이 발생하기 위한 네 가지 필수 조건(상호 배제, 점유 대기, 비선점, 순환 대기) 중 하나 이상을 제거하여 데드락 발생 자체를 불가능하게 만드는 방법.
- 상호 배제 (Mutual Exclusion): 가능하면 자원을 공유하도록 설계하여 상호 배제 조건을 제거한다. 예를 들어, 프린터 같은 자원을 여러 스레드가 동시에 접근할 수 있도록 하여 상호 배제를 없앨 수 있다.
- 점유 대기 (Hold and Wait): 스레드가 자원을 요청할 때 다른 어떤 자원도 보유하고 있지 않도록 한다. 즉, 스레드는 필요한 모든 자원을 한 번에 요청하고, 그 자원들을 사용한 후에만 다음 자원을 요청할 수 있다.
- 비선점 (No Preemption): 이미 할당된 자원을 선점할 수 없다는 조건을 제거한다. 운영체제나 스레드 관리자가 필요할 경우 스레드로부터 자원을 강제로 회수할 수 있어야 한다.
- 순환 대기 (Circular Wait): 자원 할당에 순서를 부여하고, 스레드가 더 높은 순서의 자원만 요청할 수 있도록 한다. 이는 자원 할당 그래프에서 사이클이 형성되는 것을 방지한다.
- 데드락 회피 (Deadlock Avoidance)
시스템의 상태를 지속적으로 검사하여 자원 할당이 안전 상태에서만 이루어지도록 보장하는 방법. 대표적인 알고리즘으로는 은행원 알고리즘(Banker's Algorithm)이 있다.
- 은행원 알고리즘: 시스템에 있는 모든 자원의 수와 각 스레드가 최대로 요구할 수 있는 자원의 수, 현재 할당된 자원의 수 등을 고려하여 안전한 순서로 자원을 할당한다. 이 알고리즘은 각 요청이 시스템을 데드락으로 이끌 가능성이 있는지를 판단하고, 안전하지 않다고 판단되면 요청을 거절한다.
- 데드락 탐지 및 복구 (Deadlock Detection and Recovery)
시스템에서 데드락 발생을 주기적으로 체크하고, 데드락이 탐지되면 이를 해결하기 위한 조치를 취하는 방법.
- 탐지: 자원 할당 그래프를 사용하여 사이클을 탐지한다. 사이클이 존재하면 데드락이 발생한 것.
- 복구: 데드락을 일으킨 스레드를 종료하거나, 스레드로부터 일부 자원을 선점하여 다른 스레드에게 할당함으로써 데드락을 해결한다. 이는 비용이 많이 들고 위험할 수 있기 때문에 신중하게 수행되어야 한다.
- 데드락 무시 (Ignoring Deadlocks)
일부 시스템에서는 데드락이 매우 드물게 발생하거나 데드락이 발생해도 시스템에 치명적인 영향을 미치지 않는 경우가 있다. 이런 경우, 데드락 문제를 간단히 무시하고, 발생할 때 사용자가 시스템을 재시작하는 것을 허용할 수도 있다. 이 방법은 처리 비용과 복잡성을 줄이고자 할 때 고려할 수 있다.
Atomic 변수를 활용한 락-프리(lock-free) 알고리즘
해당 알고리즘은 공유 자원에 대한 접근을 동기화할 때 락을 사용하지 않고, 대신 원자적(atomic) 연산을 통해 데이터 일관성과 동시성을 보장한다. Java에서는 java.util.concurrent.atomic 패키지를 통해 다양한 원자적 변수(예: AtomicInteger, AtomicLong, AtomicReference 등)를 제공한다.
-
락-프리 알고리즘이란
- 락 프리(lock-free) 알고리즘은 멀티스레딩 프로그래밍에서 락을 사용하지 않고, 스레드 간의 동기화를 처리하는 동시성 프로그래밍의 한 방식이다. 이러한 알고리즘은 공유 자원에 대한 접근을 제어하기 위해 전통적인 뮤텍스 또는 세마포어 같은 락 메커니즘을 사용하지 않고, 대신 원자적 연산을 활용하여 스레드 간의 경쟁을 관리한다. 락 프리 알고리즘의 목표는 높은 동시성과 성능을 유지하면서도, 데드락의 위험이나 락 경합으로 인한 성능 저하 없이 안정적인 시스템 동작을 보장하는 것이다.
-
원자적 변수의 기본 개념
- 원자적 변수들은 compareAndSet, getAndIncrement, incrementAndGet 등과 같은 원자적 연산을 지원한다. 이 연산들은 멀티스레드 환경에서 단일 연산으로 처리되며, 이는 중간에 다른 스레드에 의해 방해받지 않는다는 것을 보장한다.
예시: 원자적 카운터
AtomicInteger를 사용하면 락을 사용하지 않고도 스레드-세이프하게 카운터를 관리할 수 있다.
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 원자적으로 카운터를 1 증가시킵니다.
}
public int getCount() {
return count.get(); // 현재 카운터 값 반환
}
}
이 예제에서 increment() 메소드는 내부적으로 AtomicInteger의 incrementAndGet() 메소드를 호출하여 카운터를 원자적으로 1 증가시킨다. 이 메소드는 카운터의 현재 값을 읽고, 값을 1 증가시킨 후, 새 값을 메모리에 저장하는 작업을 단일 연산으로 수행한다. 이 과정에서 다른 스레드의 간섭을 받지 않으므로, 별도의 동기화 메커니즘 없이도 데이터의 일관성을 유지할 수 있다.
- 락-프리 알고리즘의 장점
- 성능 향상: 락을 사용하지 않기 때문에, 락으로 인한 오버헤드가 없고, 스레드의 블로킹이 발생하지 않는다. 이는 특히 고성능을 요구하는 애플리케이션에서 중요하다.
- 데드락 회피: 락을 사용하지 않으므로 데드락의 위험이 없다.
- 스케일러빌리티: 원자적 연산은 하드웨어 수준에서 지원되므로 많은 스레드가 동시에 실행될 때 더욱 효율적이다.
동기 / 비동기, 블로킹 / 논블로킹
개념 정리
동기(Synchronous)와 비동기(Asynchronous)
요청한 작업에 대한 완료 여부에 따라 작업을 순차적으로 수행할지 아닌지에 대한 관점
- 동기 프로그래밍
- 동기 방식에서는 작업 처리 순서가 연속적이다.
- 동기 방식은 코드의 흐름을 이해하기 쉽고, 데이터의 일관성과 순차적인 처리가 중요한 작업에 적합하다.
- 하지만, 무거운 작업을 처리할 때 UI가 멈추거나 응답하지 않는 문제가 발생할 수 있다.
- 비동기 프로그래밍
- 비동기 방식에서는 호출이 즉시 반환된다.
- 비동기 작업은 일반적으로 콜백 함수, 프로미스, async/await과 같은 메커니즘을 사용하여 결과를 처리한다.
- 비동기 프로그래밍은 I/O가 많은 애플리케이션에서 성능을 개선할 수 있지만, 콜백 지옥과 같은 문제를 야기할 수 있고, 코드의 흐름을 추적하기 어렵게 만들 수 있다.
블로킹(Blocking)과 논블로킹(Non-blocking)
현재 작업의 block(차단, 대기) 여부에 따라 다른 작업을 수행할 수 있는지에 대한 관점
- 블로킹
- 블로킹 호출은 호출된 함수가 특정 조건이 충족될 때까지 호출자를 대기시킨다. 예를 들어, 데이터베이스에서 데이터를 조회하거나 파일 시스템에서 파일을 읽을 때 그 결과를 즉시 받기 전까지 실행이 멈춘다.
- 블로킹 방식은 동기 방식에서 주로 발생하며, 리소스 사용에 효율적일 수 있지만 응답성이 떨어질 수 있다.
- 논블로킹
- 논블로킹 호출은 호출된 함수가 즉시 반환되어, 호출자가 다른 작업을 계속할 수 있도록 한다.
- 논블로킹 방식은 비동기 처리와 자주 결합되어 사용되며, 리소스를 효율적으로 사용하고 시스템의 응답성을 높이는 데 도움을 줄 수 있다.
차이점
- 동기 / 비동기: 프로그램의 전체 작업 흐름(코드라인)이 순차적으로 진행되는가
- 블로킹 / 논블로킹: 작업의 차단(block)에 따라 다른 작업이 수행되는가
동기 / 비동기, 블로킹 / 논블로킹의 결합
- 동기 블로킹: 작업 실행이 순차적이며, 각 작업이 완료될 때까지 프로그램의 다른 부분이 대기한다.
- 동기 논블로킹: 이론적으로는 드물지만, 특정 상황에서 동기적으로 요청을 하고 즉시 결과를 확인하지 않고 다른 작업을 수행할 수 있다.
- 이를테면 I/O 작업과 같이 시간이 많이 소요되는 작업을 요청한 후 다른 작업을 실행하며 반복문을 통해 요청했던 작업이 끝났는지 확인.
- 비동기 블로킹: 드물게 사용되는 조합으로, 작업 요청 후에 결과가 나올 때까지 대기하지만, 이 대기 과정이 다른 비동기 작업과 병행되어 실행된다.
- 비동기 논블로킹: 작업 요청이 즉시 반환되고, 프로그램은 결과를 기다리지 않고 다른 작업을 계속한다. 결과는 나중에 콜백 등을 통해 처리된다.
이벤트 루프 (비동기 논블로킹 프로그래밍)
이벤트 루프(event loop)는 비동기 프로그래밍에서 중심적인 역할을 하는 개념으로, 프로그램이 여러 작업을 효율적으로 처리할 수 있게 해 주는 메커니즘이다. 이벤트 루프의 주요 역할은 이벤트 또는 작업들을 관리하고, 실행할 작업이 준비될 때까지 기다리고, 준비된 작업을 순차적으로 실행하는 것이다. 이를 통해 단일 스레드에서도 비동기적으로 여러 작업을 처리할 수 있게 된다.
이벤트 루프의 핵심 기능
- 이벤트 관리: 이벤트 루프는 입출력(IO), 사용자 입력, 타이머 설정과 같은 다양한 이벤트를 감지하고 관리한다.
- 작업 스케줄링: 이벤트 루프는 작업(코루틴, 콜백 등)의 실행을 스케줄링한다. 코루틴이나 비동기 함수에서 await를 만나면, 해당 작업이 완료될 때까지 기다린다. 이벤트 루프는 이러한 대기 상태의 작업을 관리하고, 완료될 때까지 다른 작업을 실행한다.
- 비동기 작업 실행: 대기 중인 작업들이 완료 조건을 만족하면, 이벤트 루프는 이를 다시 활성화하고 실행한다. 이 과정은 비동기적으로 수행되어, 작업이 블로킹 없이 계속 진행될 수 있도록 한다.
이벤트 루프의 작동 방식
- 루프 시작: 이벤트 루프를 실행하는 것은 프로그램의 비동기 작업 처리를 시작하는 것을 의미한다. Python의 asyncio에서는 asyncio.run(main())과 같은 방식으로 이벤트 루프를 시작할 수 있다.
이벤트 대기 및 감지: 이벤트 루프는 다양한 소스로부터 발생할 수 있는 이벤트를 대기하고 감지한다. - 작업 실행: 이벤트 또는 준비된 작업에 대한 응답으로, 이벤트 루프는 해당 작업을 실행한다. await 키워드를 사용한 작업이 완료되면, 이벤트 루프는 해당 작업을 다시 시작하고 결과를 처리한다.
- 루프 종료: 모든 작업이 완료되면 이벤트 루프는 종료된다.
이벤트 루프는 효율적인 비동기 프로그래밍을 가능하게 하는 핵심 구성 요소로서, Python에서 asyncio 라이브러리를 사용하여 구현되며, FastAPI 같은 프레임워크에서도 이를 기반으로 비동기 요청을 처리한다.
week 5
Thread 2
mutex, semaphore lock
- 멀티스레드 프로그래밍에서 동시성을 관리하기 위해 사용되는 동기화 기법
뮤텍스 (mutex) 락
-
정의: Mutex는 Mutual Exclusion(상호 배제)의 약자로, 한 번에 하나의 스레드만이 특정 자원을 사용할 수 있도록 제한하는 락.
-
용도: 주로 공유 자원에 대한 접근을 제어하여 데이터의 일관성을 유지하는 데 사용된다.
-
특징: 뮤텍스를 소유하고 있는 스레드만이 뮤텍스를 해제할 수 있다. 이는 소유권 개념을 갖고 있어, 뮤텍스를 잠그고 해제하는 동작이 동일한 스레드에 의해 수행되어야 한다.
-
작동 원리
- 뮤텍스는 특정 자원이나 코드 섹션에 대한 접근을 단일 스레드로 제한하기 위해 사용된다. 스레드가 뮤텍스를 요청하면, 해당 뮤텍스가 사용 가능한 상태라면 스레드는 뮤텍스를 "잠그고" (lock) 자원에 접근한다.
- 이후, 자원 사용이 끝난 스레드는 뮤텍스를 "풀어주어" (unlock) 다른 스레드가 접근할 수 있도록 한다.
- 뮤텍스가 이미 다른 스레드에 의해 잠겨 있을 경우, 요청한 스레드는 뮤텍스가 해제될 때까지 대기한다.
-
장단점
-
장점: 간단하고 명확한 동기화를 제공하여 데이터 일관성과 무결성을 보장한다. 스레드 간의 데드락을 방지할 수 있는 구조를 가지고 있다.
-
단점: 뮤텍스의 소유권이 있기 때문에, 잠금을 해제하는 것을 잊어버릴 경우 데드락(deadlock)이 발생할 수 있다. 성능 면에서 오버헤드가 발생할 수 있으며, 잘못 사용할 경우 성능 저하를 일으킬 수 있다.
- 과도한 잠금 범위 (Overlocking)
- 뮤텍스를 사용할 때 코드에서 잠금을 너무 넓은 범위에 걸쳐서 적용하면, 필요 이상으로 많은 작업이 잠금 상태에서 수행된다.
- 이 경우 다음과 같은 문제가 발생할 수 있다:
- 응답 시간 증가: 다른 스레드들이 잠금을 획득하기 위해 더 오래 기다려야 한다.
- 컨텍스트 스위칭 증가: 스레드들이 잠금을 기다리는 동안, 운영 체제는 실행 가능한 다른 스레드로 전환한다. 이로 인해 컨텍스트 스위칭이 빈번하게 발생하고, 이는 성능 저하로 이어진다.
- 잠금 대기 시간 (Lock Contention)
- 높은 잠금 경쟁: 여러 스레드가 동시에 같은 뮤텍스를 획득하려고 할 때, 잠금 대기 시간이 증가하고 이는 전반적인 처리량을 감소시킨다.
- 리소스 이용률 저하: 잠금으로 인해 스레드들이 대기 상태에 빈번하게 머무르게 되어, 실제 유용한 작업을 수행하는 시간이 줄어든다.
- 데드락 (Deadlock)
- 잘못된 잠금 순서: 두 스레드가 서로 다른 순서로 여러 뮤텍스를 잠그려고 할 때, 각 스레드가 이미 다른 스레드가 소유한 뮤텍스의 해제를 무한히 기다리는 상황이 발생할 수 있다. 이는 시스템이 완전히 멈추는 데드락 상태를 초래할 수 있다.
- 불필요한 잠금
- 잠금이 필요 없는 영역에 잠금 적용: 병렬로 안전하게 실행될 수 있는 코드에 뮤텍스를 적용하는 경우, 이는 불필요한 오버헤드를 발생시키고 성능을 저하시킨다.
- 과도한 잠금 범위 (Overlocking)
-
세마포어 (Semaphore) 락
- 정의: 세마포어는 일정 수량의 동시 접근을 허용하는 일종의 카운팅 메커니즘. 세마포어의 값은 허용되는 동시 실행의 최대 수를 나타낸다.
- 용도: 여러 스레드가 동시에 자원에 접근하도록 허용할 때 사용된다. 예를 들어, 데이터베이스의 최대 동시 접속자 수를 제한하는 데 사용할 수 있다.
- 특징: 세마포어는 특정 스레드에 의해 소유되지 않는다. 따라서 어느 스레드나 세마포어를 획득하거나 반환할 수 있다. 이는 뮤텍스와의 주요 차이점 중 하나이다.
- 작동 원리
- 세마포어는 카운터를 기반으로 동작한다. 세마포어의 카운터 값은 동시에 접근할 수 있는 최대 스레드 수를 나타낸다.
- 스레드가 자원에 접근하고자 할 때, 세마포어의 카운터를 감소시키며, 이 값이 0 이상이면 접근이 허용된다.
- 자원 사용을 마친 스레드는 세마포어를 "반환"하여 카운터를 증가시킨다. 이렇게 해서 다른 스레드가 자원에 접근할 수 있도록 한다.
- 장단점
- 장점: 다수의 스레드가 동시에 자원을 사용할 수 있어 유연성이 높다. 다양한 동기화 문제에 적용할 수 있는 범용성을 갖추고 있다.
- 단점: 세마포어를 잘못 사용하면 복잡한 동기화 문제와 데드락을 일으킬 수 있다. 세마포어의 카운터 관리가 올바르지 않을 경우 무결성 문제가 발생할 수 있으며, 이는 디버깅이 어려울 수 있다.
- 종류
- 바이너리 세마포어 (Binary Semaphore): 이 유형의 세마포어는 카운트가 0 또는 1만 가능하며, 이를 이용해 뮤텍스와 유사한 상호 배제 동작을 구현할 수 있다. 바이너리 세마포어는 주로 두 개의 상태(잠김 또는 해제)만을 나타내는 데 사용된다. 따라서 이 경우에는 스레드가 세마포어를 획득하면 카운트가 0이 되고, 해제하면 카운트가 1이 된다.
- 카운팅 세마포어 (Counting Semaphore): 카운팅 세마포어는 0 이상의 임의의 정수값을 카운트로 가질 수 있다. 이 유형의 세마포어는 동시에 여러 스레드가 자원에 접근할 수 있도록 허용할 때 사용된다. 예를 들어, 특정 리소스에 대해 5개의 동시 접근을 허용하고 싶다면, 세마포어는 초기에 5로 설정된다. 스레드가 리소스에 접근할 때마다 카운트를 1씩 감소시키고, 리소스 사용을 완료하면 다시 1씩 증가시킨다. 이 때 카운트는 0에서 5까지의 값을 가질 수 있다.
context switching
개념 및 기본 원리
컨텍스트 스위칭(context switching)은 컴퓨터에서 멀티태스킹을 가능하게 하는 프로세스 또는 스레드 간의 전환을 말한다. 이 작업은 운영 체제의 일부로서 CPU가 여러 프로세스나 스레드를 효율적으로 처리할 수 있도록 돕는다.
- 컨텍스트 스위칭의 기본 원리:
- 현재 실행 중인 프로세스(또는 스레드)의 상태 저장: CPU가 현재 실행 중인 프로세스를 다른 프로세스로 전환하기 전에, 현재 프로세스의 상태를 저장한다. 이 상태에는 프로그램 카운터, 레지스터 값들, 메모리 상태 등이 포함된다.
- 이전에 저장된 상태 불러오기: 다음에 실행할 프로세스의 상태를 불러온다. 이 상태는 이전에 해당 프로세스가 중지되었을 때 저장된 상태이다.
- 프로세스 전환: 저장된 상태를 바탕으로 새로운 프로세스가 CPU에서 실행을 시작한다.
JVM(Java Virtual Machine)과 같은 가상 머신 환경에서도 유사한 컨텍스트 스위칭이 일어난다.
JVM 내에서는 다양한 스레드가 실행되고, 각 스레드는 자바 애플리케이션의 일부분을 동시에 실행할 수 있게 해준다.
JVM 내의 스레드 컨텍스트 스위칭은 JVM이 운영 체제 위에서 실행되기 때문에,
실제로는 JVM 스레드들이 운영 체제의 스레드 관리 기능을 사용하여 처리된다.컨텍스트 스위칭 발생 조건
컨텍스트 스위칭은 컴퓨터 시스템에서 멀티태스킹을 수행하며 여러 프로세스나 스레드 사이에서 CPU 점유 시간을 공유할 때 필수적으로 발생한다. 일반적으로 컨텍스트 스위칭이 발생하는 몇 가지 주요 조건은 다음과 같다.
- 시간 할당 만료: 대부분의 운영 시스템에서는 프로세스나 스레드에게 제한된 시간(타임 슬라이스 또는 퀀텀)을 할당한다. 이 시간이 만료되면 운영 시스템은 다른 프로세스나 스레드에게 CPU를 할당하기 위해 컨텍스트 스위칭을 실행한다.
- I/O 요청 처리: 프로세스가 입출력(I/O) 작업을 요청하는 경우, 이러한 작업은 일반적으로 많은 시간이 소요된다. 프로세스가 I/O 작업을 대기하는 동안, 운영 시스템은 CPU를 다른 작업이 가능한 프로세스에게 할당하기 위해 컨텍스트 스위칭을 수행할 수 있다.
- 우선순위 변경: 다양한 프로세스나 스레드가 다른 우선순위를 가지고 있을 때, 더 높은 우선순위를 가진 작업이 실행 준비가 되면 운영 시스템은 현재보다 낮은 우선순위의 작업을 중단하고 더 높은 우선순위 작업으로 컨텍스트를 스위칭할 수 있다.
- 인터럽트 처리: 하드웨어나 소프트웨어 인터럽트가 발생하면 운영 시스템은 인터럽트를 처리하기 위해 현재 실행 중인 프로세스의 컨텍스트에서 인터럽트 처리 루틴으로 스위칭해야 할 수 있다.
- 멀티코어 프로세싱: 멀티코어 또는 멀티프로세서 시스템에서는 여러 프로세스나 스레드가 동시에 실행될 수 있다. 이러한 시스템에서는 각 코어가 별도의 스레드나 프로세스를 실행할 수 있으므로, 컨텍스트 스위칭은 자주 발생할 수 있다.
이러한 컨텍스트 스위칭은 시스템의 반응성과 자원 사용의 효율성을 증가시키지만, 자주 일어날 경우 오버헤드가 발생하여 시스템의 전반적인 성능을 저하시킬 수 있다. 따라서 스레드 또는 프로세스의 수와 컨텍스트 스위칭의 빈도를 적절히 관리하는 것이 중요하다.
프로세스의 컨텍스트 스위칭
프로세스의 컨텍스트 스위칭이 스레드 스위칭보다 더 큰 오버헤드를 발생시키는 주된 이유는 관련된 상태 정보와 자원의 양 때문이다.
- 메모리 상태: 프로세스는 각각 독립된 메모리 공간을 가진다 (예: 각 프로세스에 할당된 독립적인 가상 메모리 주소 공간). 이로 인해 프로세스 간 스위칭 시에는 CPU의 메모리 관리 장치(MMU) 설정을 변경해야 하며, 종종 페이지 테이블 전체를 교체해야 한다. 반면에 같은 프로세스 내의 스레드들은 같은 메모리 공간을 공유하기 때문에 스레드 간 스위칭에서는 이러한 메모리 관련 오버헤드가 발생하지 않는다.
- 캐시 초기화: 프로세스 간 스위칭 시 CPU 캐시에 저장된 데이터가 무효화될 수 있다. 새로운 프로세스는 서로 다른 메모리 위치에 접근할 가능성이 높기 때문에, 이전 프로세스에서 사용된 캐시 정보는 종종 쓸모없게 된다. 이는 캐시 미스를 증가시켜 성능 저하를 초래할 수 있다. 스레드 간 스위칭에서는 동일한 메모리 공간을 사용하므로 캐시를 재사용할 가능성이 더 높다.
- 시스템 자원: 프로세스는 각각 별도의 시스템 자원(예: 파일 핸들, 네트워크 연결)을 관리한다. 프로세스 간 스위칭은 이러한 자원의 할당 및 해제 관련 오버헤드를 동반할 수 있다. 반면 스레드는 이러한 자원을 프로세스와 공유하므로 자원 관련 컨텍스트 스위칭이 발생하지 않는다.
- 보안 및 격리: 프로세스는 서로 격리되어 있어 보안상 이점을 제공하지만, 이로 인해 컨텍스트 스위칭 시 추가적인 보안 검사가 필요할 수 있다. 스레드는 프로세스 내에서 실행되므로 이러한 추가적인 검사가 필요하지 않는다.
이런 차이점들로 인해 프로세스 간 컨텍스트 스위칭은 스레드 간 스위칭에 비해 일반적으로 더 큰 오버헤드를 수반하며, 이는 시스템의 성능에 영향을 줄 수 있다.
멀티 프로세스 VS 멀티 스레드
-
멀티 프로세스
- 멀티 프로세스 방식은 각 프로세스가 독립적인 메모리 공간을 가지며 서로의 자원을 공유하지 않는다. 이 방식은 주로 격리와 안정성이 중요한 경우에 사용된다.
- 장점
- 격리: 각 프로세스는 독립적인 메모리 공간을 사용하기 때문에, 하나의 프로세스에서 발생하는 문제가 다른 프로세스에 영향을 미치지 않는다.
- 안정성: 프로세스 하나가 실패하더라도 시스템 전체에 영향을 주지 않아, 애플리케이션의 전체적인 안정성이 향상된다.
- 단점
- 자원 사용: 독립된 메모리 공간과 시스템 자원을 사용하기 때문에, 멀티 스레드 방식에 비해 더 많은 메모리와 CPU 자원을 소모한다.
- 상호작용의 복잡성: 프로세스 간 통신(IPC)이 스레드 간 통신보다 구현하기 복잡하고 성능 면에서 느릴 수 있다.
- 베스트 유즈 케이스
- 크롬 브라우저와 같은 웹 브라우저: 각 탭이 별도의 프로세스로 실행되어 하나의 탭에서 발생하는 문제가 전체 브라우저에 영향을 미치지 않는다.
- 고립된 서비스가 필요한 시스템: 보안이 중요한 애플리케이션에서 각 컴포넌트를 독립적으로 운영하여 보안을 강화할 수 있다.
-
멀티 스레드
-
멀티 스레드 방식은 하나의 프로세스 내에서 여러 스레드가 메모리와 자원을 공유하면서 동시에 실행된다. 이 방식은 자원을 효율적으로 사용하고 싶을 때 주로 사용된다.
-
장점
- 자원 효율성: 동일한 프로세스 내의 스레드들은 메모리를 공유하기 때문에, 프로세스 간 컨텍스트 스위칭보다 더 적은 자원을 사용한다.
- 응답성 향상: 스레드를 이용하여 비동기적 작업을 처리하면 애플리케이션의 응답성이 향상될 수 있다.
-
단점
- 복잡한 동기화: 공유 메모리를 사용하기 때문에 데이터의 일관성과 동기화를 위한 추가적인 로직이 필요하다.
- 오류의 전파: 하나의 스레드에서 발생한 문제가 프로세스 전체에 영향을 줄 수 있으므로, 오류 관리가 더 어려워질 수 있다.
-
베스트 유즈 케이스
- 서버 애플리케이션: 멀티 스레드를 사용하여 클라이언트 요청을 동시에 처리할 수 있어, 네트워크 서버나 웹 서버 같은 곳에서 효율적이다.
- 백그라운드 작업 처리: 애플리케이션의 UI 스레드를 방해하지 않으면서 백그라운드에서 데이터 처리나 로딩 같은 작업을 수행할 수 있다.
-
-
고려 사항
- 안정성 vs. 자원 사용: 멀티 프로세스는 높은 안정성을 제공하지만 자원 사용이 많고, 멀티 스레드는 자원을 효율적으로 사용하면서 높은 처리량을 제공한다. 안정성이 중요한 경우 멀티 프로세스를, 자원 사용의 최적화가 중요한 경우 멀티 스레드를 선택할 수 있다.
- 개발의 복잡성: 멀티 스레드는 공유 자원의 동기화로 인해 개발이 복잡해질 수 있다. 반면 멀티 프로세스는 프로세스 간 통신의 복잡성을 관리해야 한다. 개발의 용이성을 고려할 때 이 두 가지 접근 방식 중 하나를 선택할 수 있다.
- 성능 요구사항: 멀티 스레드는 컨텍스트 스위칭 비용이 낮고 자원 공유로 인해 성능이 더 우수할 수 있다. 반면 멀티 프로세스는 자원 사용량이 많고 스위칭 비용이 높지만, 격리된 환경으로 인해 보안과 안정성이 요구되는 곳에서 선호된다.
- 오류 격리의 필요성: 멀티 프로세스 방식은 오류 격리가 중요한 애플리케이션에 적합하다. 하나의 프로세스에서 발생한 오류가 시스템 전체로 전파될 가능성이 낮다.
동시성(Concurrency)과 병렬성(Parallelism)
동시성 (Concurrency)
동시성은 여러 작업이 시간을 공유하면서 동시에 실행되는 것처럼 보이도록 하는 프로그래밍 기법이다. 실제로 여러 작업이 동시에 실행되지 않더라도, 작업들 사이에서 자주 전환되어 마치 동시에 수행되는 것처럼 보인다. 이는 하나의 프로세서에서 멀티 스레딩을 사용하여 이루어질 수 있다.
목적: 동시성은 자원을 효율적으로 사용하여 응용 프로그램의 반응성과 처리량을 개선하는 데 목적이 있다.
적용 예: 웹 서버는 동시에 여러 클라이언트의 요청을 처리할 수 있어야 하며, 각 요청을 별도의 스레드로 처리하여 동시성을 구현한다.
병렬성 (Parallelism)
병렬성은 실제로 여러 처리 작업이 동시에 실행되는 것을 의미한다. 이는 멀티코어 또는 멀티프로세서 하드웨어에서 여러 스레드나 프로세스가 각각의 코어에서 동시에 실행되어 작업을 수행함으로써 달성된다.
목적: 병렬성은 작업을 더 빠르게 완료하기 위해 계산 작업을 여러 코어에 분산시키는 데 초점을 맞춘다.
적용 예: 과학 계산이나 이미지 처리 같은 무거운 계산 작업을 여러 코어에서 병렬로 처리하여 전체 실행 시간을 단축시킨다.
동시성과 병렬성의 차이점
처리 방식: 동시성은 한 번에 하나의 작업만 처리할 수 있는 단일 코어 CPU에서도 구현할 수 있다. 반면, 병렬성은 여러 코어를 이용하여 실제로 여러 작업을 동시에 처리한다.
하드웨어 요구 사항: 동시성은 특별한 하드웨어 요구 사항이 없지만, 병렬성은 여러 처리 유닛(코어)이 필요하다.
성능 향상: 동시성은 시스템의 반응성과 자원 사용의 최적화에 도움을 주며, 병렬성은 작업의 완료 시간을 단축시키는 데 더 큰 영향을 미친다.
이 두 개념은 서로 보완적이며, 많은 현대 응용 프로그램에서는 동시성과 병렬성을 모두 활용하여 더 높은 성능과 효율성을 달성하고 있다.
멀티스레드는 동시성? 병렬성?
- 하드웨어가 단일 코어인 경우
- 동시성: 스레드는 동시성을 통해 실행된다. 이는 시간을 분할하여 스레드가 번갈아가며 실행되는 것을 의미한다. 각 스레드는 짧은 시간 동안 실행되고, 운영 체제의 스케줄러에 의해 다음 스레드로 전환된다. 이렇게 하면 모든 스레드가 거의 동시에 실행되는 것처럼 보이지만, 실제로는 한 번에 하나의 스레드만이 CPU를 사용하고 있다.
- 하드웨어가 멀티 코어인 경우
- 병렬성: 여러 스레드가 실제로 동시에 실행될 수 있다. 각 스레드는 다른 CPU 코어에서 동시에 실행되기 때문에, 실제 병렬 처리가 일어난다. 이 경우에는 멀티스레딩이 병렬성을 구현하는 한 방법으로 작용한다.
결론
하나의 프로세스에서 멀티스레딩을 이용할 때, 단일 코어 시스템에서는 동시성이 구현되는 것이며, 멀티 코어 시스템에서는 병렬성이 구현된다. 따라서 동시성과 병렬성은 프로세스의 스레드가 실행되는 하드웨어의 특성에 따라 다르게 적용된다.
멀티스레딩은 기술적으로 두 가지 상황 모두를 포괄할 수 있으며, 프로그램의 설계와 실행 환경에 따라 동시성 또는 병렬성의 이점을 얻을 수 있다.
동기 블로킹 vs 비동기 논블로킹
흔히 쓰이는 두 조합을 비교해보자
동기 블로킹 (Synchronous Blocking)
- 장점
- 간단한 흐름 제어:
- 동기 블로킹 방식은 코드의 실행 흐름이 선형적이므로 이해하기 쉽고, 코드가 작성된 순서대로 실행된다.
- 데이터 일관성 보장:
- 데이터 처리 작업이 순차적으로 이루어지므로, 의존적인 데이터 작업에서 일관성을 유지하기 쉽다. 이는 복잡한 트랜잭션이나 금융 서비스 같은 환경에서 매우 중요하다.
- 에러 핸들링 용이성:
- 에러 발생 시 즉시 처리할 수 있으며, 호출 스택이 명확하기 때문에 디버깅이 용이하다.
- 간단한 흐름 제어:
동기 방식이 필수적인 경우
데이터베이스 트랜잭션:
데이터베이스 트랜잭션은 여러 작업을 포함할 수 있으며, 이러한 작업들은 모두 하나의 일관된 단위로 처리되어야 한다.
작업 중 하나라도 실패하면 트랜잭션 전체가 롤백되어야 하며, 이는 작업들이 엄격한 순서대로 실행되어야 함을 의미한다.
금융 거래:
금융 서비스에서는 계좌 이체, 결제 처리 등의 작업이 정확한 순서대로 실행되어야 한다.
예를 들어, 이체를 처리할 때는 먼저 출금이 이루어지고, 그 다음 입금이 성공적으로 처리되어야 한다.
이러한 순차적 처리는 금융 거래의 정확성을 보장하는 데 필수적이다.
시스템 명령의 실행:
특정 시스템 명령이나 스크립트를 실행할 때 명령들이 정확한 순서대로 실행되어야만 올바른 결과를 얻을 수 있다.
명령의 실행 순서가 뒤바뀌면 시스템의 상태가 예상과 다르게 변경될 수 있다.- 단점
- 자원 활용 비효율:
- I/O 작업(디스크 접근, 네트워크 통신 등) 동안 스레드가 블록되어 CPU가 다른 작업을 수행할 수 없게 되어 리소스 활용도가 떨어진다.
- 응답성 저하:
- 한 작업이 완료될 때까지 다음 작업이 대기해야 하므로, 특히 멀티유저 환경에서 시스템의 응답성이 저하될 수 있다.
- 자원 활용 비효율:
비동기 논블로킹 (Asynchronous Non-Blocking)
- 장점
- 자원 활용 최적화:
- 비동기 논블로킹 방식은 I/O 작업이 백그라운드에서 수행되면서 메인 스레드가 다른 작업을 계속할 수 있게 해 자원 활용을 극대화한다.
- 시스템 응답성 향상:
- 작업을 대기하지 않고 즉시 다음 작업으로 넘어갈 수 있어 사용자와 시스템의 응답성이 크게 향상된다.
- 확장성 증가:
- 동시에 많은 요청을 처리할 수 있으므로, 대규모 처리가 필요한 애플리케이션에 적합하다.
- 자원 활용 최적화:
- 단점
- 복잡한 프로그래밍 모델:
- 콜백, 프로미스, 이벤트 루프 등 비동기 패턴을 사용해야 하므로 프로그램의 로직이 복잡해지고, 디버깅이 어려워질 수 있다.
- 경합 조건과 버그의 위험:
- 여러 작업이 동시에 실행되면서 데이터 경합이 발생할 수 있으며, 이는 프로그램의 버그로 이어질 수 있다.
- 동기화 문제:
- 데이터를 공유하는 여러 비동기 작업 사이에서 적절한 동기화 없이는 데이터 무결성 문제가 발생할 수 있다.
- 복잡한 프로그래밍 모델:
결론
동기 블로킹 방식은 단순하고 직관적이며, 데이터 의존성이 높은 환경에서 안정적인 데이터 처리가 가능하다. 반면, 비동기 논블로킹 방식은 자원 활용과 시스템 응답성을 극대화하며 대규모 데이터 처리에 유리하다. 각 방식의 선택은 애플리케이션의 요구 사항, 처리해야 할 작업의 종류, 개발자의 편의성을 고려하여 결정되어야 한다.
TCP
TCP vs UDP
TCP (Transmission Control Protocol)와 UDP (User Datagram Protocol)는 인터넷상에서 데이터를 전송하는 데 사용되는 두 가지 주요 프로토콜이다. 두 프로토콜의 가장 큰 차이점은 데이터 전송의 신뢰성과 연결 상태다.
-
TCP는 연결 지향적이고 신뢰성 있는 데이터 전송을 제공한다. 데이터 전송 전에 연결을 설정하고 데이터가 올바르게 전송되었는지 확인한다. 손실된 패킷은 재전송된다. 이는 데이터의 순서가 보장되며, 에러 없이 데이터가 전송됨을 의미한다.
- 적합한 애플리케이션 예: 웹 브라우징 (HTTP/HTTPS), 이메일 (SMTP, IMAP/POP), 파일 전송 (FTP), 데이터베이스 서버 연결 등
-
UDP는 비연결 지향적이고 신뢰성이 낮은 데이터 전송을 제공한다. 연결 설정 과정이 없으며, 패킷 손실에 대해 자체적으로 복구하지 않는다. 이는 높은 전송 속도를 요구하는 응용 프로그램에 적합하다.
- 적합한 애플리케이션 예: 스트리밍 서비스, 온라인 게임, VoIP, 실시간 비디오 회의 등
TCP의 3-way 핸드셰이크 과정
TCP 연결 설정은 "3-way 핸드셰이크"라는 과정을 통해 이루어진다. 이 과정은 다음과 같다:
- SYN: 클라이언트가 서버에 연결 요청을 보냅니다. 클라이언트는 SYN(Synchronize Sequence Number) 패킷을 보내어 연결을 시작하고자 한다.
SYN-ACK: 서버는 클라이언트의 SYN 패킷을 받고, 클라이언트에게 SYN과 ACK(Acknowledgement) 패킷을 보내어 요청을 수락했음을 알린다.
ACK: 클라이언트는 서버의 SYN-ACK에 대해 ACK 패킷을 보내고 이로써 양방향 연결이 설정된다.
SYN 패킷을 먼저 보내는 이유
연결 매개변수 협상: TCP 연결은 각 호스트의 초기 시퀀스 번호와 같은 중요한 매개변수를 협상하는 과정을 포함한다.
SYN 패킷은 이 초기 시퀀스 번호를 전달하며, 호스트는 이 번호를 기반으로 모든 후속 데이터 패킷의 순서를 추적한다.
연결의 양방향성 확인: TCP는 양방향 통신을 제공한다.
클라이언트가 서버에 SYN을 보내면, 서버는 SYN과 함께 ACK을 클라이언트에게 보냄으로써 두 호스트 간의 양방향 통신 경로가 활성화되었음을 확인한다.
자원 할당: SYN 패킷을 받은 서버는 해당 연결에 필요한 자원(메모리, 포트 등)을 할당한다. 이 과정을 통해 서버는 동시에 여러 클라이언트와 안정적으로 통신할 수 있다.UDP에서 데이터 전송의 신뢰성 보장 방법
UDP의 장점을 살리며 특정 단점만 보완하는 방식으로도 사용할 수 있다.
이를테면 UDP 자체는 신뢰성을 보장하지 않지만, 애플리케이션 레벨에서 추가 메커니즘을 구현하여 신뢰성을 높일 수 있다.
- 응답 메시지: 데이터 수신자가 수신 확인 응답을 보내어 데이터가 도착했는지 확인할 수 있다.
- 재전송 로직: 손실된 데이터 패킷의 재전송을 위한 로직을 구현할 수 있다.
- 순서 번호 및 체크섬: 패킷에 순서 번호를 부여하고 체크섬을 사용하여 데이터의 무결성을 검사할 수 있다.
TCP 통신의 문제점 및 해결 방안
- 혼잡 제어(congestion control) 문제: 네트워크 혼잡 시 패킷 손실과 지연이 발생할 수 있다.
- 해결 방안: slow start, cogestion avoidance 알고리즘, fast recovery 및 fast retransmit 같은 혼잡 제어 프로토콜을 사용한다.
- 순서 및 신뢰성 문제: 패킷 순서가 바뀌거나 손실될 수 있다.
- 해결 방안: 패킷 재정렬, 재전송 요청 등을 통해 해결한다.
TCP 혼잡 제어 방식
Congestion Window(cwnd)는 TCP에서 네트워크의 혼잡 상태를 고려하여 조정하는 데이터 전송량의 크기를 말한다.
이 윈도우는 TCP 연결의 송신 측에서 관리하는 변수로, 네트워크를 통해 안전하게 전송할 수 있는 데이터 양의 상한을 나타낸다.-
Slow Start (느린 시작)
목적: TCP 연결 초기에 네트워크의 용량을 모르기 때문에, 네트워크의 혼잡을 피하기 위해 송신 속도를 점진적으로 증가시킨다.
작동 원리: TCP 연결이 시작될 때 Congestion Window(cwnd)를 1 패킷으로 설정한다. 매 ACK가 도착할 때마다 Congestion Window를 1 패킷씩 증가시키므로, 윈도우 크기는 RTT(Round Trip Time)마다 두 배씩 증가하는 지수적 성장을 보입니다. Congestion Window 크기가 임계값(threshold)에 도달하면, 혼잡 회피 단계로 전환된다. -
Congestion Avoidance (혼잡 회피)
목적: Congestion Window가 네트워크 용량에 근접하거나 이를 초과하지 않도록 조절하여 네트워크 혼잡 상태를 방지한다.
작동 원리: Congestion Window가 임계값을 초과하면, Congestion Window의 증가 속도를 줄여서 매 ACK마다 윈도우 크기를 1/cwnd 패킷씩 증가시킵니다. 이는 선형 증가로, 네트워크 혼잡이 발생할 때까지 윈도우 크기를 점진적으로 늘린다. -
Fast Retransmit (빠른 재전송)
목적: 패킷 손실을 빠르게 감지하고 해결하여 데이터 전송을 계속 진행할 수 있도록 한다.
작동 원리: 만약 하나의 패킷에 대해 세 번의 중복 ACK가 도착하면, 해당 패킷이 손실되었다고 판단하고 해당 패킷만을 즉시 재전송한다. 이는 패킷 손실을 빠르게 복구하는 효과적인 방법이다. -
Fast Recovery (빠른 회복)
목적: 패킷 손실 후 네트워크 혼잡 상태를 빠르게 극복하고 데이터 전송을 정상적으로 재개한다.
작동 원리: 빠른 재전송 후, Congestion Window 크기를 줄이지만, 완전히 느린 시작으로 돌아가지는 않는다. 대신 Congestion Window를 반으로 줄이고, 임계값을 새로운 Congestion Window 값으로 설정한 다음, 혼잡 회피 단계로 들어간다. 이를 통해 네트워크의 혼잡 상태를 빠르게 벗어날 수 있다.
AIMD
AIMD (Additive Increase Multiplicative Decrease)
AIMD 알고리즘은 TCP 혼잡 제어의 핵심이다. 이 알고리즘은 네트워크의 혼잡 상태를 기반으로 데이터 전송 속도를 동적으로 조절한다. 구체적으로는 두 가지 방식으로 작동한다:
- Additive Increase (AI): 네트워크에서 패킷 손실이 감지되지 않을 때, AIMD는 각 RTT(Round Trip Time)마다 혼잡 윈도우 크기를 점진적으로 증가시킨다. 일반적으로 1 MSS(Maximum Segment Size)만큼 증가시키는 이 방법은 데이터 전송률을 점진적으로 늘리며, 네트워크의 용량을 점진적으로 탐색한다.
- Multiplicative Decrease (MD): 패킷 손실이 발생하면, 이는 네트워크의 혼잡을 나타낼 수 있으며, AIMD는 혼잡 윈도우 크기를 반으로 줄인다. 이 감소는 네트워크의 부하를 급격히 줄여 더 이상의 패킷 손실을 방지하고 네트워크가 회복할 시간을 제공한다.
RTT(Round-Trip Time)는 네트워크 통신에서 데이터 패킷이 송신자로부터 수신자에게 전송되고,
그 응답이 다시 송신자에게 돌아오는 데 걸리는 전체 시간을 말한다.
다시 말해, 패킷이 한 지점에서 출발하여 목적지에 도달한 뒤,
그 응답이 원래 지점으로 돌아오는 데까지의 시간이다.빠른 재전송
빠른 재전송 (Fast Retransmit)
빠른 재전송 메커니즘은 TCP에서 패킷 손실을 보다 효과적으로 처리하기 위한 방법이다. 기존의 TCP에서는 타임아웃이 발생할 때까지 손실된 패킷의 재전송을 기다려야 했다. 그러나 빠른 재전송은 다음과 같이 작동한다:
수신자는 순서대로 도착하지 않은 패킷(Segment)을 감지하고, 이미 받은 패킷에 대해 중복된 ACK를 전송한다.
송신자가 동일한 ACK를 세 번 연속으로 받으면, 해당 패킷이 손실된 것으로 간주하고 즉시 재전송을 시작한다.
이 메커니즘은 타임아웃을 기다리지 않고 빠르게 문제를 해결할 수 있어 전송 효율을 크게 향상시킨다.
Week6 ~ 프로젝트 주간
- 프로젝트 주간 동안 추가적으로 학습한 내용
Transaction, @Transactional
Transaction
-
트랜잭션(Transaction)은 데이터베이스 관리 시스템에서 데이터의 상태를 변환시키기 위해 수행하는 작업의 단위를 의미한다.
-
트랜잭션은 데이터베이스의 일관성을 보장하기 위해 여러 작업을 하나의 단위로 묶어서 처리하는 것을 말한다.
-
트랜잭션은 ACID 특성을 만족해야 한다.
-
Atomicity (원자성):
- 트랜잭션 내의 모든 작업이 전부 수행되거나 전혀 수행되지 않아야 한다.
- 만약 트랜잭션 중 일부 작업이 실패하면 전체 트랜잭션은 실패하고 데이터베이스는 원래 상태로 되돌아간다.
- 예: 은행 계좌 이체 시, 돈을 보내는 계좌에서 출금되었지만 받는 계좌에 입금되지 않는 경우가 없도록 해야하는 등.
-
Consistency (일관성):
- 트랜잭션이 수행된 후 데이터베이스가 일관된 상태를 유지해야 한다.
- 데이터베이스는 트랜잭션 전후의 무결성 제약 조건을 항상 만족해야 한다.
- 예: 은행 계좌의 총 잔액이 트랜잭션 전후에 변하지 않아야 한다.
-
Isolation (고립성):
- 각각의 트랜잭션은 독립적으로 수행되어야 하며, 동시에 여러 트랜잭션이 수행될 때 다른 트랜잭션의 영향을 받지 않아야 한다.
- 예: 두 사용자가 동시에 같은 계좌에서 출금을 시도해도 트랜잭션 간섭이 없어야 한다.
-
Durability (영속성):
- 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 데이터베이스에 반영되어야 한다.
- 예: 시스템 장애가 발생해도 완료된 트랜잭션의 결과는 손실되지 않아야 한다.
-
@Transactional
Spring 프레임워크에서 @Transactional 어노테이션은 메서드나 클래스 수준에서 트랜잭션을 관리하기 위해 사용된다.
@Transactional은 트랜잭션의 시작과 종료를 자동으로 처리하여 데이터베이스의 일관성을 유지하는 데 중요한 역할을 한다.
@Transactional을 사용하면 개발자가 직접 트랜잭션 관리를 하지 않아도 되므로 코드가 더 간결해지고 유지보수가 쉬워진다.
@Transactional 동작 원리와 작동 방식
Proxy 기반 AOP (Aspect-Oriented Programming):
Spring의 @Transactional은 기본적으로 AOP 프록시를 통해 동작한다. 트랜잭션이 적용된 메서드를 호출할 때, 실제 메서드 호출 전에 프록시가 개입하여 트랜잭션을 시작한다.
메서드 호출이 완료되면 프록시가 트랜잭션을 커밋하거나 롤백한다.
트랜잭션 전파 (Transaction Propagation):
@Transactional은 트랜잭션 전파 속성을 통해 메서드 간 트랜잭션의 경계를 정의할 수 있습니다. 주요 전파 속성은 다음과 같다:
- REQUIRED: 기본값. 현재 트랜잭션이 존재하면 그 트랜잭션을 사용하고, 없으면 새 트랜잭션을 시작한다.
- REQUIRES_NEW: 항상 새로운 트랜잭션을 시작한다. 기존 트랜잭션은 일시 중지된다.
- MANDATORY: 현재 트랜잭션이 존재하지 않으면 예외를 발생시킨다.
- SUPPORTS: 현재 트랜잭션이 존재하면 사용하고, 없으면 트랜잭션 없이 실행한다.
- NOT_SUPPORTED: 트랜잭션 없이 실행하며, 현재 트랜잭션이 존재하면 일시 중지한다.
- NEVER: 트랜잭션 없이 실행하며, 현재 트랜잭션이 존재하면 예외를 발생시킨다.
- NESTED: 현재 트랜잭션이 존재하면 중첩 트랜잭션을 시작하고, 없으면 새로운 트랜잭션을 시작한다.
격리 수준 (Isolation Level):
트랜잭션의 격리 수준을 지정할 수 있다. 격리 수준은 트랜잭션이 서로 간섭하지 않도록 하는 정도를 설정한다. 주요 격리 수준은 다음과 같다:
- DEFAULT: 데이터베이스의 기본 격리 수준을 사용한다.
- READ_UNCOMMITTED: 다른 트랜잭션이 커밋하지 않은 데이터를 읽을 수 있다.
- READ_COMMITTED: 다른 트랜잭션이 커밋한 데이터만 읽을 수 있다.
- REPEATABLE_READ: 트랜잭션이 시작된 이후 다른 트랜잭션이 커밋한 변경 사항을 읽을 수 없다.
- SERIALIZABLE: 가장 높은 격리 수준으로, 완벽한 트랜잭션 격리를 보장한다.
Rollback 조건:
@Transactional은 기본적으로 RuntimeException이나 그 하위 클래스가 발생하면 롤백을 수행한다. checked exception이 발생해도 롤백을 원하면 rollbackFor 속성을 사용한다.
예: @Transactional(rollbackFor = Exception.class)
JPA 사용 전략
- JPA Query Method
JPA Repository 인터페이스에서 메서드 이름을 통해 자동으로 쿼리를 생성하는 방식이다. 메서드 이름을 통해 쿼리를 자동으로 생성하므로 코드를 간결하게 유지할 수 있다.
사용 예시:
public interface UserRepository extends JpaRepository<User, Long> {
List<User> findByLastName(String lastName);
User findByEmail(String email);
}적절한 사용 전략:
단순한 쿼리나 자주 사용하는 기본적인 CRUD 연산에 적합하다.
메서드 이름이 길어지거나 복잡해질 때는 가독성이 떨어질 수 있으므로 주의 필요.
복잡한 쿼리에는 다른 방법을 사용하는 것이 더 좋을 수 있다.
- Named Query
엔티티 객체에 이름이 지정된 쿼리를 작성하여 사용하는 방식이다. 엔티티 클래스 위에 정의하는 방법과 JPA 레포지토리 메서드 위에 @Query를 통해 직접 작성하는 방법이 있다.
엔티티 클래스에 정의:
@Entity
@NamedQuery(name = "User.findByStatus", query = "SELECT u FROM User u WHERE u.status = :status")
public class User {
// 필드 및 메서드
}@Query를 사용하는 방법:
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.status = :status")
List<User> findByStatus(@Param("status") String status);
}적절한 사용 전략:
재사용성이 높은 쿼리나 여러 곳에서 사용되는 쿼리를 미리 정의해 놓을 때 유용하다.
복잡한 비즈니스 로직이 있는 쿼리를 명확하게 정의하고 관리할 수 있다.
쿼리가 엔티티 클래스와 연관되어 있으므로, 쿼리의 수정이 엔티티 클래스에 영향을 줄 수 있다.
- @Query를 사용한 네이티브 쿼리
네이티브 쿼리를 통해 SQL 쿼리를 직접 작성하여 사용하는 방식이다. 이는 복잡한 SQL 쿼리를 작성하거나 JPA가 제공하지 않는 기능을 사용할 때 유용하다.
사용 예시:
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM users WHERE status = ?1", nativeQuery = true)
List<User> findByStatusNative(String status);
}적절한 사용 전략:
복잡한 SQL 쿼리나 성능 최적화가 필요한 경우 유용하다.
JPA에서 제공하지 않는 특정 데이터베이스 기능을 사용할 때 필요하다.
SQL 쿼리를 직접 작성하므로 데이터베이스 종속성이 높아질 수 있다.
- EntityGraph
JPA 2.1에서 도입된 기능으로, 엔티티 그래프를 사용하여 연관된 엔티티를 함께 로딩하는 방식을 정의할 수 있다. 이를 통해 N+1 문제를 해결하거나 필요한 엔티티만 로딩할 수 있다.
사용 예시:
@Entity
@NamedEntityGraph(name = "User.detail", attributeNodes = @NamedAttributeNode("address"))
public class User {
// 필드 및 메서드
@OneToOne
private Address address;
}
public interface UserRepository extends JpaRepository<User, Long> {
@EntityGraph(value = "User.detail", type = EntityGraph.EntityGraphType.LOAD)
List<User> findAll();
}적절한 사용 전략:
복잡한 엔티티 관계를 효율적으로 로딩할 때 유용하다.
필요에 따라 특정 속성만을 로딩하여 성능을 최적화할 수 있다.
@EntityGraph를 적절히 사용하여 N+1 문제를 방지할 수 있다.
- Criteria API
Criteria API는 동적 쿼리를 타입 세이프하게 작성할 수 있는 방법을 제공한다. 이는 쿼리를 프로그래밍 방식으로 생성하므로, 컴파일 시점에 오류를 확인할 수 있고, 복잡한 쿼리를 유연하게 작성할 수 있다.
사용 예시:
public List<User> findByStatus(String status) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<User> query = cb.createQuery(User.class);
Root<User> user = query.from(User.class);
query.select(user).where(cb.equal(user.get("status"), status));
return entityManager.createQuery(query).getResultList();
}적절한 사용 전략:
동적 쿼리를 작성할 때 유용하다.
컴파일 시점에 쿼리 오류를 확인할 수 있어 안정성이 높다.
쿼리가 복잡해질 경우 코드의 가독성이 떨어질 수 있다.
- JPQL (Java Persistence Query Language)
JPQL은 객체 지향 쿼리 언어로, SQL과 유사하지만 엔티티 객체를 대상으로 쿼리를 작성한다. 이를 통해 데이터베이스와 독립적인 쿼리를 작성할 수 있다.
사용 예시:
public List<User> findByStatus(String status) {
return entityManager.createQuery("SELECT u FROM User u WHERE u.status = :status", User.class)
.setParameter("status", status)
.getResultList();
}적절한 사용 전략:
SQL과 유사한 구문으로 쉽게 배울 수 있다.
객체 지향적으로 쿼리를 작성할 수 있어 JPA의 장점을 살릴 수 있다.
네이티브 쿼리보다 성능이 약간 떨어질 수 있다.
- Specification (Spring Data JPA)
Spring Data JPA에서 제공하는 Specification은 동적 쿼리를 작성하는 데 유용하며, Criteria API를 기반으로 구현된다. 이는 복잡한 검색 조건을 조합하여 사용할 수 있다.
사용 예시:
public class UserSpecification implements Specification<User> {
private String status;
public UserSpecification(String status) {
this.status = status;
}
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return cb.equal(root.get("status"), status);
}
}
public List<User> findByStatus(String status) {
return userRepository.findAll(new UserSpecification(status));
}적절한 사용 전략:
복잡한 검색 조건을 동적으로 조합할 때 유용하다.
재사용 가능한 검색 조건을 쉽게 만들 수 있다.
코드가 복잡해질 수 있으므로 잘 구조화하는 것이 중요하다.
- Projection
Projection은 특정 엔티티의 일부 필드만을 조회할 때 사용된다. 인터페이스 기반 프로젝션과 클래스 기반 프로젝션 두 가지 방식이 있다.
사용 예시 (인터페이스 기반):
public interface UserProjection {
String getFirstName();
String getLastName();
}
public interface UserRepository extends JpaRepository<User, Long> {
List<UserProjection> findByStatus(String status);
}적절한 사용 전략:
필요한 필드만 조회하여 성능을 최적화할 수 있다.
엔티티 전체를 조회할 필요가 없을 때 유용하다.
인터페이스 기반 프로젝션은 간결하지만, 복잡한 변환 로직이 필요할 때는 클래스 기반 프로젝션이 유용할 수 있다.
