Intro
-
실전 프로젝트를 진행하며 마주했던 문제 상황과
해결 과정들을 상세하게 정리할 예정입니다. -
문제 정의 / 사실 수집 / 원인 추론 / 조사 방법 결정 및 구현 / 결과 관찰 / 문서 작성
조사 방법을해결 방안으로 워딩 변경
-
프로젝트가 끝날 때까지 계속 업데이트 될 예정이며,
트러블 슈팅이 아닌 간단한 오류 해결 내역도 기록할 예정입니다.
Trouble-Shooting
1주차
1. 논리자료형(원시 타입 vs 참조 타입) getter setter
postman으로 보낸 논리자료형 값이 boolean 타입의 멤버 변수에 set이 안되는 현상
1) 사실 수집 - 원인 추론:
- 구글링 결과 논리 자료형 멤버 변수의 이름에
is를 붙이면
원시 타입 boolean과 참조 타입 Boolean은
lombok이 생성하는 getter, setter의 메서드 명이 다르다.
//boolean의 경우
private boolean isComplete
//getter, setter에 is가 누락된다.
public isComplete(){
return this.isComplete;
}
public setComplete(boolean bool){
this.isComplete = bool;
}
//Boolean의 경우
private Boolean isComplete
//getter, setter에 is가 포함된다.
public getIsComplete(){
return this.isComplete;
}
public setIsComplete(Boolean bool){
this.isComplete = bool;
}
- For boolean fields that start with is immediately followed by a title-case letter, nothing is prefixed to generate the getter name.
- Any variation on boolean will not result in using the is prefix instead of the get prefix; for example, returning java.lang.Boolean results in a get prefix, not an is prefix.
- 🔗 출처: lombok 공식 홈페이지
2) 해결 방안 결정 및 구현
- 우리 팀은 논리 자료형의 변수 명에
isprefix를 붙이기로 했으므로, 정상적으로 getter, setter를 호출할 수 있도록
참조자료형 논리자료형인Boolean을 사용한다.
3) 결과
- 변경 후 setter가 정상적으로 작동된다.
2주차
1. websocket 통신 시 발생한 인증 오류
websocket 통신 시 SecurityContextHolder에 인증 정보가 없어 발생한 오류
1) 사실 수집 - 원인 추론:
-
우리 웹의 인증 방식은 프론트가 보내온 요청의 Header에 담긴 (Authorization - Bearer xxx.xxx.xxx) JWT를 검증하는 방식이다.
-
현재 코드 상 이러한 인증은
OncePerRequestFilter를 상속받는 JwtFilter라는 구현 클래스에 의해 이루어진다. -
JwtFilter는 HTTP 통신으로 오는 request의 Header에서 JWT를 추출하여 검증하는 코드로 구성되어 있다.
-
즉, ws 통신으로 오는 request는 당연히 JwtFilter에서 필터링되지 않는다.
2) 해결 방안 결정 및 구현
-
따라서 HTTP 통신으로 오는 request의 Header에 담긴 토큰을 추출하여 검증하듯 ws 통신으로 오는 request에 담긴 JWT를 검증하는 로직이 필요하다.
-
이를 구현하기 위해 처음에 StompHandler의 preSend() 메서드에서 ws통신의 Command가
SEND인 경우 해당 요청에 담긴 JWT를 통해 인증 정보를 SecurityContextHolder에 저장하는 코드를 추가했다. -
그러나 preSend()는 말 그대로 본 요청 이전에 미리 보내는 과정이었고, 저장된 후 본 요청을 처리할 때에는 저장 정보가 사라진 이후였다.
-
따라서 본 요청을 처리하는, @MessageMapping을 붙인 메서드를 정의한 ChatMessageController에서 받아온 Message 객체 (HTTP 통신의 request와 비슷한 객체)에 담겨있는 JWT를 통해 저장하는 코드를 추가하여 해결했다.
3) 결과
- ws 통신 상황에서도 SecurityUtil(인증 정보를 가져오는 모듈화 객체)을 사용할 수 있게 되었다.
2. ws 통신 시 DB 저장 순서에 따른 오류
ws 통신 (메세지를 send 하는 상황)에서 간헐적으로 send한 메세지가 조회되지 않고 딜레이 되었던 현상
1) 사실 수집 - 원인 추론:
-
프론트 엔드 코드와 백 엔드 코드를 모두 살펴보며 채팅 메세지 보내기 버튼을 클릭했을 경우 어떠한 흐름으로 채팅방에 메세지가 조회되는 지 파악했다.
-
전체적인 흐름은 아래와 같았다.
- 채팅 메세지 전송 버튼을 클릭하면
pubprefix가 붙은 백엔드 서버 API url로 토큰을 담아 요청을 보낸다. - 백엔드 @MessageMapping API에서 해당 메세지를 받아 ChatMessage 객체를 생성하고 저장하며
subprefix가 붙은 해당 채팅방을 구독하고 있는 곳으로 돌려 보낸다. - 프론트 엔드 코드에서 ws.subscribe() 메서드가 실행되며 해당 채팅방의 모든 메세지를 조회한다.(보낸 메세지를 포함하여)
- 채팅 메세지 전송 버튼을 클릭하면
-
모든 흐름이 정상적이라고 생각이 들었기에, 각 함수가 실행되는 순서를 확인하기 위해 로그를 남겨봤다.
-
로그 결과는 백엔드에서 받아온 메세지를 저장하는 것보다 프론트에서 새로 메세지 목록을 조회하는 것이 먼저 실행됨을 보여줬다.
2) 해결 방안 결정 및 구현
- 이를 해결하기 위해 백엔드 API 코드에서 메세지를 저장하는 코드와, 채팅방을 구독하고 있는 토픽 구독자들에게 메세지를 보내는 코드의 순서를 변경했다. 즉, 메세지 저장을 먼저 하고난 후에 구독자들에게 메세지를 보내는 것으로 변경했다.
3) 결과
- 간헐적으로 채팅 메세지가 저장되는 시간보다 해당 채팅방의 메세지 목록을 조회하는 속도가 빠를 경우 나타났던 딜레이 현상이 사라졌다.
- 메세지를 먼저 저장함으로써 프론트 엔드 코드에서 (ws.subscribe()에서) 메세지를 받는 상황은 확정적으로 보냈던 메세지가 저장된 후의 상황이 된 것이다.
3주차
1. MultipleBagFetchException
N+1 문제를 해결하기 위해 @ManyToOne으로 설정된 여러 컬렉션을 한번에 fetch join 하다가 발생한 예외
1) 사실 수집 - 원인 추론:
-
Member라는 사용자 객체에는 Post, Dog, Apply, Review 컬렉션들이 @OneToMany 연관관계로 설정 되어있다.
-
순서대로 내가 작성한 게시글, 내가 등록한 반려견, 나의 신청, 나의 후기로 Member 객체와 생명주기를 같이해야 할 객체들을 Cascade로 관리하기 위해 설정했다.
-
~ToMany는 Default로 Lazy 로딩 전략을 따르는데, 이렇게 되면 Member를 조회하는 첫 쿼리에 연관관계로 설정된 컬렉션들을 조회하지 않고, 필요한 곳에서 사용되어 추가적으로 쿼리가 발생하는 N+1 문제가 발생한다.
-
이는 상당히 비효율적인 방식이라고 생각되어 모든 컬렉션을 fetch join 하여 첫번 째 쿼리에 모든 것을 조회하도록 했으나
MultipleBagFetchException이 발생했다. -
발생 원인에 검색해본 결과, 조회 시 Bag Type의 컬렉션을 2개 이상 조회하려고 했기에 발생한 것으로, outer join이 중복을 허용하는 list 타입의 컬렉션에 걸린다면 합집합으로 필요했던 데이터 보다 많은 데이터를 생성하기에 미리 방지한 것이 아닐까라는 결론을 얻을 수 있었다.
2) 해결 방안 결정 및 구현
-
해결 방안으로는 batch-fetch-size를 지정해주는 방안이 있었는데, 이는 지정된 size 만큼
in절에 부모 key를 사용하게 해주는 옵션이다. -
단순히 생각해봐도 size가 1000이라면, 1000개의 쿼리를 하나의 쿼리에서 in절로 한번에 처리할 수 있는 것이다.
-
적용 방법은 엔티티 클래스 내 해당 컬렉션 위에
@BatchSize(size=1000)어노테이션을 붙이는 방식과 -
application.properties(yml) 파일에서 전역으로
spring.jpa.properties.hibernate.default_batch_fetch_size=1000을 작성하는 방식이 존재한다. -
결론적으로 나는 가장 많이 쿼리를 발생시키는 컬렉션을 fetch join을 걸어줬으며, 나머지는 batch-fetch-size를 적용시켜 in절을 활용했다.
3) 결과
- Member 객체 조회 시 불필요한 쿼리가 나가는 것을 제거하여 TPS 성능 낭비를 방지할 수 있었다.
- fetch join, outer join(합집합) vs inner join(교집합), batch fetch size에 대해 학습할 수 있었다 :)
4주차
1. ConcurrentModificationException
향상된 for 문을 사용하다가 마주한 예외
java.util.concurrentmodificationexception is typically thrown when code attempts to modify a data collection while that collection while that collection is actively in use, such as being iterated
1) 사실 수집 - 원인 추론:
-
그동안 향상된 for 문의 정확한 동작 원리를 파악하지 않고 무지성으로 사용해왔었다.
-
일반적인 for문의 경우 int 타입의 인덱스 변수를 지정하고 인덱스를 증가시키며 반복 횟수를 지정해줬었는데, 향상된 for문은 인덱스에 대한 설정을 해준 적이 없다.
-
그렇다면 향상된 for문은 어떻게 반복문이 되는 것일까?
- 우선
iterator에 대해 알아야 한다. - iterator란 자바의 컬렉션에 저장되어 있는 요소들을 순회하는 인터페이스다.
- 메서드는 다음 요소가 있는 지 판단하는 hasNext(), 다음 요소를 가져오는 next(), 가져온 요소를 삭제하는 remove()가 존재한다.
- 우선
-
향상된 for 문은 foreach문 으로도 불리며 아래와 같이 정의 되어있다.
for (type var : iterate){
body-of-loop
}-
즉 iterable이 되는 자료구조들에 한해서 사용할 수 있는 것이다.
-
서론이 길었는데, 사실 위의 개념을 모두 알아야 ConcurrentModificationException이 왜 발생했는 지를 알 수 있다.
-
해당 예외는 iterate을 하는 과정에서 발생하는 것으로 iterate할 대상 (컬렉션 등)이 iterate을 하는 도중에는 무결성이 보장되어야 하는데, 무결성이 깨졌을 경우 발생하는 것으로 추측할 수 있었다.
-
코드 단에서 살펴보면 iterator의 next() 메소드에서 항상 호출하는 checkForComodification() 메소드에는 modCount와 expectedModCount를 비교하는 조건문이 존재한다.
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
...-
여기에서 modCount는 변경이 일어난 횟수를 뜻하며, expectedModCount는 기대되는 변경 횟수를 뜻하는데 내가 이해한 바로는 expectedModCount가 0으로 무결성을 기대하는데 반복문 내에서 add, remove 등 iterate 대상의 상태가 변경되어 modCount가 ++될 경우 ConcurrentModificationException을 던지게 되는 것이다.
-
즉, 향상된 for 문 내부에서는 iterate의 대상 컬렉션의 상태를 무결하게 유지해야 함을 학습했다.
2) 해결 방안 결정 및 구현
-
내가 구현한 코드에서는 향상된 for문 내부에 iterate 대상 컬렉션의 상태를 변경하는 코드가 존재했다.
-
연관관계로 설정된 부모 객체가 동일한 객체들이 존재하여 modCount가 동시에 증가한 객체들이 있던 것이다.
-
다행히 로직 상 반복문이 끝난 후에 변경사항을 적용해줘도 되었고
- 반복문 이전에 대상 객체를 null로 초기화 해둔 후
- 반복문 내부에서 대상 객체로 할당 시킨 후
- 반복문 종료 후 대상 객체로 변경 코드를 수행했다.
3) 결과
- 그동안 향상된 for문 (foreach문)을 사용하기 편하다는 이유로 사용 방법만 익히고 무지성으로 사용했던 것을 반성한다..
- ConcurrentModificationException이 터진 덕에, 향상된 for문의 동작 방식에 대해 나름 깊이 있게 공부할 수 있었다..
- 고맙다 ConcurrentModificationException!!!! 👍
5주차
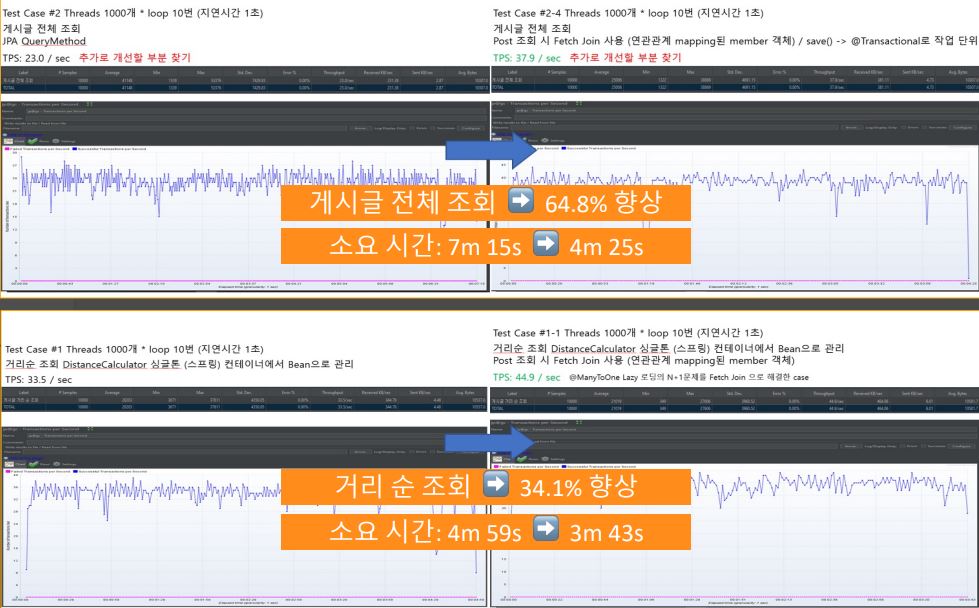
1. Jmeter 부하 테스트와 TPS 성능 개선
5주차에 실제 개발한 프로젝트를 배포하여 유저 테스트를 받기 시작했다. 실제로 많은 유저들을 받기 전에 가장 빈번하게 호출되는 API들을 점검하기로 했다. 이에 JMeter 툴을 통해 전체 게시글 조회와 게시글 거리 순 조회의 부하 테스트를 진행했다.
1) 사실 수집 - 원인 추론:
-
두 API는 모두 DB에 저장된 모든 POST 객체를 불러와 연관 관계 설정된 객체들까지 모두 responseDto에 담아 보내주는 기능을 수행한다.
-
부하 테스트의 조건은 아래와 같다
- Threads 개수: 1000
- 지연시간: 1초
- loop count: 10
-
즉 1초만에 1000명의 유저가 접속하여 10번씩 반복적으로 API를 호출하는 경우로 설정했다.
-
최초로 측정했던 TPS는 아래와 같다
- 전체 게시글 조회: 23.0 / sec
- 게시글 거리 순 조회: 33.5 / sec
-
생각했던 것 보다 저조한 성능이 나와 디버깅하며 실제 쿼리가 어떻게 실행되고 있는 지를 찍어봤다.
- 그 결과 Post를 JPA QueryMethod로 findAll() 해올 때 Post에 @ManyToOne 연관 관계로 설정된 Member 객체 (작성자) 를 모두 조회해오는 것을 알 수 있었다.
- ~ToOne은 default로 eager loading을 하지만, 해당 객체를 여러개 조회한다면 얘기가 달라진다. 해당 객체가 속한 ~ToOne 객체의 개수만큼 추가적으로 select 쿼리가 날아가는 N+1 문제가 발생한다. 이 지점이 우리가 고쳐야 할 타겟이다..!
2) 해결 방안 결정 및 구현
-
해결 방안은 총 2가지로 생각했다.
-
- ToOne으로 설정된 객체의 fetchType을 lazy로 지정한다.
-
- ToOne으로 설정된 객체를 첫 쿼리에 fetch join해온다.
-
-
첫 번째 방안은 ToOne으로 설정된 객체를 사용하지 않는다면 전혀 문제가 되지 않지만, 만약 member를 사용해야 하거나 트랜잭션 내에서 toString(), property 복사 같은 작업을 한다면 역시 N+1 문제가 발생한다.
-
또한 트랜잭션 밖에서 접근한다면 LazyInitializationException이 발생한다.
-
따라서! 두 번째 방안으로 선택했다.
- ~ToOne으로 mapping된 Member 객체를 @EntityGraph(attributePath='member')로 JPQL 쿼리에서 바로 사용할 수 있도록 했으며 left fetch join을 통해 outer join을 걸어줘 모든 Post 객체를 Member와 동시에 조회하는 쿼리를 구현했다.
3) 결과
- 역시 서론이 길었지만, 결론은 fetch join을 통해 연관 관계 설정된 객체 수 만큼 select 쿼리가 날아가는 것을 막을 수 있었다!
- 이를 통해 TPS 성능을 유의미하게 개선할 수 있었다.
-
JPA는 정말 편리하게 자바 객체 지향적인 관점에서 DB를 관리할 수 있다는 장점이 있지만 N+1 문제는 꼭 성능적인 측면에서 검토해야할 부분임을 알 수 있었다.
-
또한 JPA도 좋지만 결국 JPA는 SQL을 대신 날려주는 방식이기에 SQL 문이 의도한 대로 날아가고 있는 지! 오류는 어디에서 발생했는 지를 파악하려면 SQL 학습 역시 필수임을 뼈저리게 깨달았다.
-
SQL도 꼭 학습하기로 결심하게 되었다! 백엔드 개발자의 근본 역량 중 하나!!! ✔✔✔
-
+) 처음으로 부하테스트를 해봐서 애를 먹었는데, TPS를 고려하며 개발하는 것도 백엔드 개발자의 기본 소양이기에 친숙해져야겠다는 생각을 했다.
-
TPS까지 고려할 수 있는 개발자로 성장할 것이다.
2. EC2 프리티어 서버 안정화 작업
우리 팀은 EC2 프리티어 서버에 도커 컨테이너를 띄워 배포를 진행했는데, 사용자가 많아질 경우 제한된 메모리 1GB가 부족하여 최악의 경우 서버가 다운될 수도 있다는 생각에 이를 보완하고자 했다.
1) 사실 수집:
- EC2 프리티어의 경우 제공되는 메모리 용량이 1GB이다.
- 스프링 프로젝트만 돌렸을 경우에도 이미 500MB 이상을 사용한다.
- 우리 서비스는 채팅 기능을 제공하기에 사용자가 급격히 많아진 상태에서 채팅이 급격히 많아진다면..?
- 과연 남은 300MB의 메모리가 이를 버틸 수 있을까..?
- 위와 같은 고민을 하게 되었다.
2) 해결 방안 결정 및 구현
-
현재 메모리가 부족하다면 서버가 다운되거나 장애가 발생할 것으로 예측되기에
- 유료 서버를 구매해 메모리 전체 용량을 키우거나,
- 메모리를 보조할 수 있는 무언가가 필요했다..
-
다행히 구글링 하던 중 swap memory에 대해 알게 되었다..!
-
swap memory는 실제 메모리가 가득 차고 더 많은 메모리가 필요할 때 디스크 공간(가상 메모리)으로 대체하는 것이라고 한다.
-
바로 서버에 swap memory를 생성해서 할당해줬다.
3) 결과

- 위와 같이 swap 공간 할당이 잘 되어있다.
- 이제 사용 가능한 memory가 353MB 여도 swap 공간이 있기 때문에 서버가 다운되진 않을 것 같다. (아직까지 서버가 다운된 적이 없었다 :) )
