프롬프트 평가가 중요한 이유
- 프롬프트 엔지니어링의 핵심은 반복적인 개선이다. 하지만 측정할 수 없으면 개선할 수 없다. 그러므로 지속적인 프롬프트 평가가 중요하다
프롬프트 평가의 구성 요소
- Output : 모델의 출력 결과로 평가 대상이 된다
- Golden Answer(Optional) : 모델의 출력을 평가하기 위한 정답이나 이상적인 응답
- Score : Output과 Golden Answer를 비교해서 나온 점수
프롬프트 평가의 특징
- 프롬프트 평가는 소프트웨어 개발에서 테스트 설계와 유사한 점이 많다
- 테스트는 입력에 대해서 명확한 출력이 정해져 있지만 프롬프트의 출력은 자연어 기반이므로 평가하기 어려울 수 있다(물론 작업마다 다르다)
다양한 프롬프트 평가 방법
- Human-based grading : 사람이 직접 프롬프트에 대한 모델의 응답을 평가하고 채점하는 방법
- Code-based grading : 코드를 사용해서 모델의 응답을 자동으로 평가하고 채점하는 방법
- Model-based grading(LLM-as-a-judge) : LLM을 이용해서 모델의 응답을 자동으로 평가하고 채점하는 방법 -> 추가적인 평가 프롬프트 필요
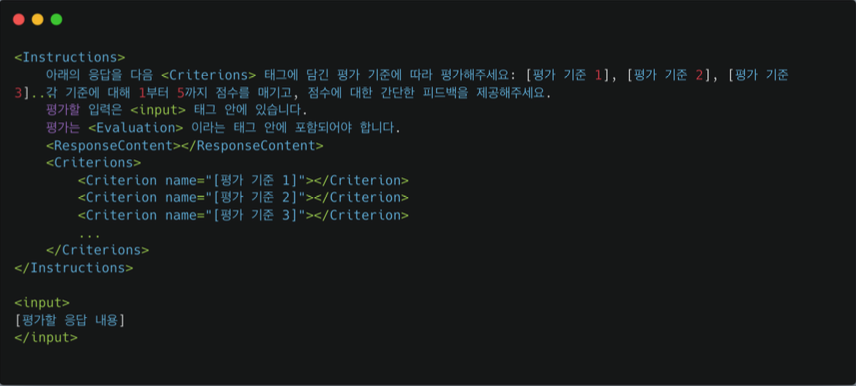
모델 기반 평가
평가 방식
- 평가를 위한 프롬프트에는 평가 대상과 평가 기준과 평가 척도가 포함되어 있다
- 평가 척도 : 모델이 평가할때 평가를 측정하는 기준. 즉, 평가할 떄 얼마나 잘했는지, 못했는지를 어떤 숫자나 선택지로 나타내는 방법
-> 선형 척도 : 1부터 5 또는 1부터 10까지 숫자로 평가하는 방법
-> 리커트 척도 : "전혀 동의하지 않음","약간 동의함","완전 동의함" 같은 방법
-> 이진 척도 : "예" 또는 "아니오" 같은 두 가지 선택지로 평가하는 방법
-> 쌍 비교 : 두 개의 응답을 한 쌍으로 비교하여 누가 더 우수한지 결정하는 방법
평가 기술
- Output Format 지정 : 평가 결과를 XML이나 JSON 포맷으로 작성
- In-Context Learning : Evaluation을 어떻게 하는지 예시를 추가하는 식
- Role-based Prompting : 역할을 부여해서 평가
- Chain-of-Thought : 중간 추론 과정을 명시해서 더 정확하게 평가
- Model-Generated Guidelines : 모델 스스로 평가 추론 과정을 생성해서 평가
- Batch Prompting : 모델 평가를 하나씩 하는게 아니라 배치로 한번에 평가
한계점
- 위치 편향 : LLM이 특정 위치를 다른 위치보다 선호하는 현상
- 긴 응답 편향 : LLM이 보다 긴 응답을 선호하는 현상
- 자신의 답변 선호 편향 : LLM이 자신의 응답을 보다 더 선호하는 현상
극복방법
- 위치 편향을 해결하기 위해서 순서를 바꿔서 호출해서 평가를 하고 평균을 내자
- 대규모 데이터를 평가해야 한다면 순서를 랜덤으로 지정하자
- 답변의 길이를 제한시키는 것도 방법이다
- 하나의 LLM만을 이용하지 말고 다양한 LLM을 사용해서 Cross-check를 적용하자
- Chain-of-thought 방법을 사용하는건 편향을 없애는데 도움을 준다
- LLM이 가진 편향을 체크하고 편향에 대해 설명하고 편향에 휘둘리지 말라고 말해준다
프롬프트 평가 도구
