Chain-of-Thouht
- LLM의 추론 능력을 향상시키기 위해 나온 방법
- 프롬프트에 자연어 추론 과정을 넣는 것으로 추론 작업에 도움이 된다
- 모델이 문제를 해결할 때 단계별로 생각 과정을 거쳐서 해결하도록 하는 방법
- (입력, 사고 과정, 결과)의 예시들을 프롬프트에 추가시키는 방법
Few-shot CoT Prompting
- 모델에게 몇 가지 예제를 제공하여 모델이 복잡한 문제를 논리적으로 단계별로 해결할 수 있도록 유도하는 기법
- 보통 8~32개의 예시를 넣고 다양한 예시를 포함시켜서 LLM의 성능을 향상시킨다

- 높은 주석 처리 비용 : 프롬프트에 포함시킬 다양한 추론 예시를 준비해야 한다
- 예시 선택의 중요성 : 프롬프트에 포함시킬 예시가 성능을 결정한다
- 여러 한계점이 존재한다(자연어 기반 추론, CoT 작동 원리 이해 부족 등)
- 추론 과정의 품질이 떨어질 때는 오히려 성능이 떨어진다
Zero-shot CoT
- 예시없이 LLM에게 단순히 "차근차근 생각해보자(Let's think step by step)"이라는 문구를 추가하는 기법
- Few-shot CoT 방법보다 광범위하게 적용할 수 있다
- Few-shot CoT 보다는 성능이 낮게 나오지만 그래도 성능 향상의 효과는 있다.
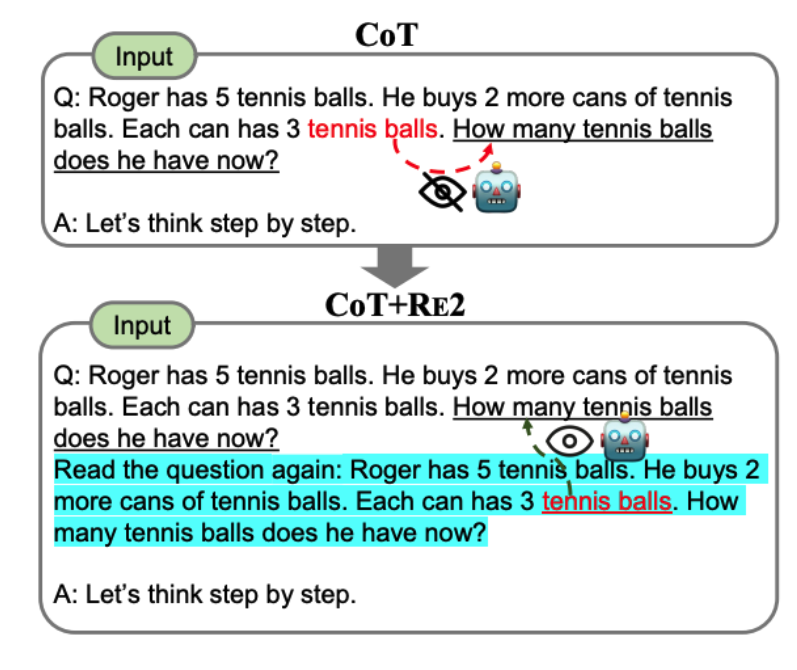
RE2(Re-Reading)
- LLM에게 처리해야하는 작업의 질문을 두 번 읽도록 하는 기법
- 추론 단계를 유도하는 기법이라기 보다는 입력 단계의 이해를 향상시키는 기법
- 현재의 LLM들은 decoder-only 아키텍쳐를 사용하기 때문에 사용가능
- 다른 프롬프트 기법과 연계해서 사용하기 쉽다
- 질문이 복잡할수록 효과가 크다
- 질문 다시 읽기는 최대 2회까지만 하는 것이 좋다
Stepback prompting
- 구체적인 내용들로부터 고차원적인 개념과 기본 원칙을 추출해서 이를 활용하는 기법
- 질문을 받았을 때 이 질문에 대한 의도는 무엇인지 생각해 보는것
- 구체적인 내용들을 LLM이 필요햔 정보를 효과적으로 사용하지 못할 수 있기 때문에 나옴
- 일부 작업에서는 CoT보다 높은 성능을 달성
- STEM 분야, 지식 기반 질문 응답, 다중 단계 추론에서 높은 성능 향상을 이룸
- LLM의 추론 능력을 쉽게 향상 시킬 수 있는 또 다름 프롬프트 기법
- 많은 세부 정보를 그대로 취하지 않고 한 단계 물러서서 생각해보면 좋은 작업에 효과적
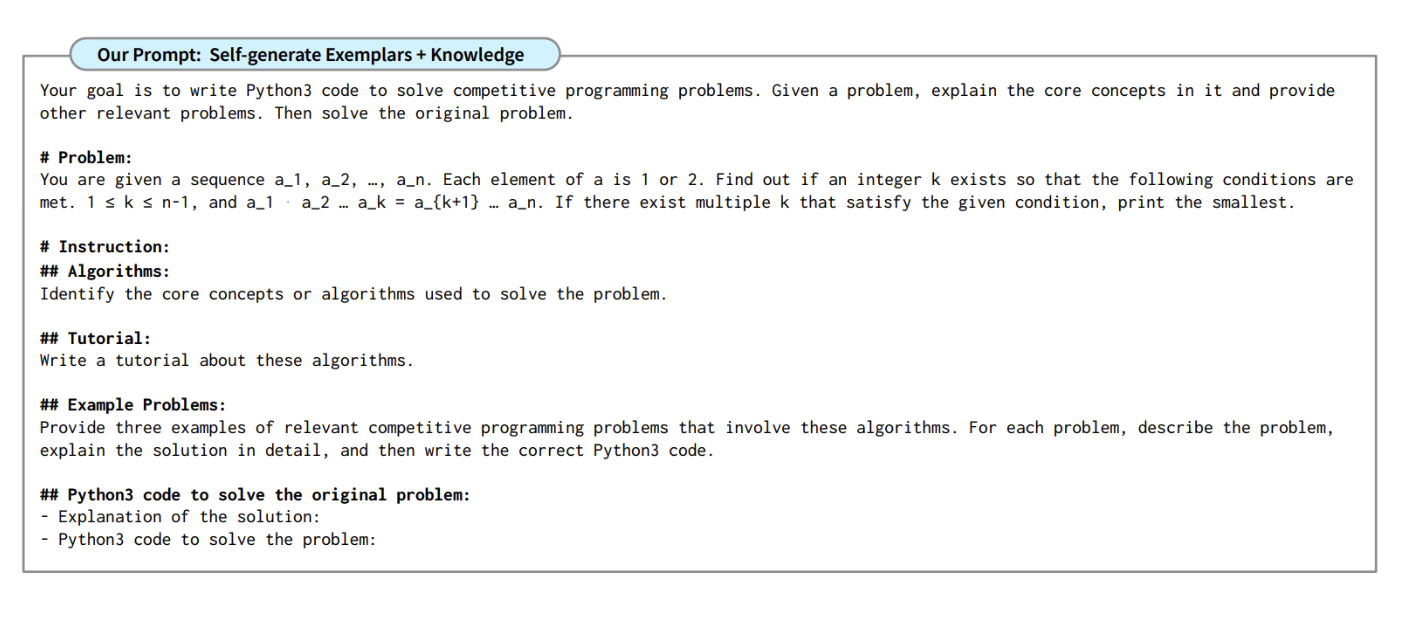
Analogical Reasoning
- 문제를 해결하기 전에 모델이 스스로 관련 예시와 지식을 생성한 후 문제를 해결하는 기법
- 문제에 맞게 지식과 예시를 맞춤형으로 생성하는 기법
- 예시를 사람이 생성하지 않고 LLM 스스로 생성하도록 하는 기법
- 응답을 만들 떄 많은 토큰을 사용해야 함
- Zero-shot CoT 방법과 Few-shot CoT 방법보다 성능이 잘 나옴
- 생성된 예시는 관련성이 잘못되었을 수 있고 해결책도 잘못 될 수 있음
- LLM이 가진 사전 지식에 크게 의존적
- 생성된 예시로는 일반화를 하지 못해서 초기 문제를 풀기 어려운 경우도 있다
Auto CoT
- CoT에 포함되어야 할 예시를 LLM 스스로 생성하고 이를 추론때 사용하는 기법
- Analogical Reasoning과는 다르게 미리 예시를 생성해두며 다양한 예시를 조합해서 사용한다
- 자동으로 예시를 생성하기 위해 Zero-shot CoT를 이용한다
- 생성된 예시의 오류를 줄이기 위해 다양한 예시를 사용한다
- 사람이 수동으로 작성한 Few-shot CoT 이상인 성능을 보임
- 다량의 데이터에 주석을 다는 작업이 필요하지 않음
- 생성된 추론 예시는 Zero-shot CoT를 이용하므로 LLM의 사전 지식에 의존적
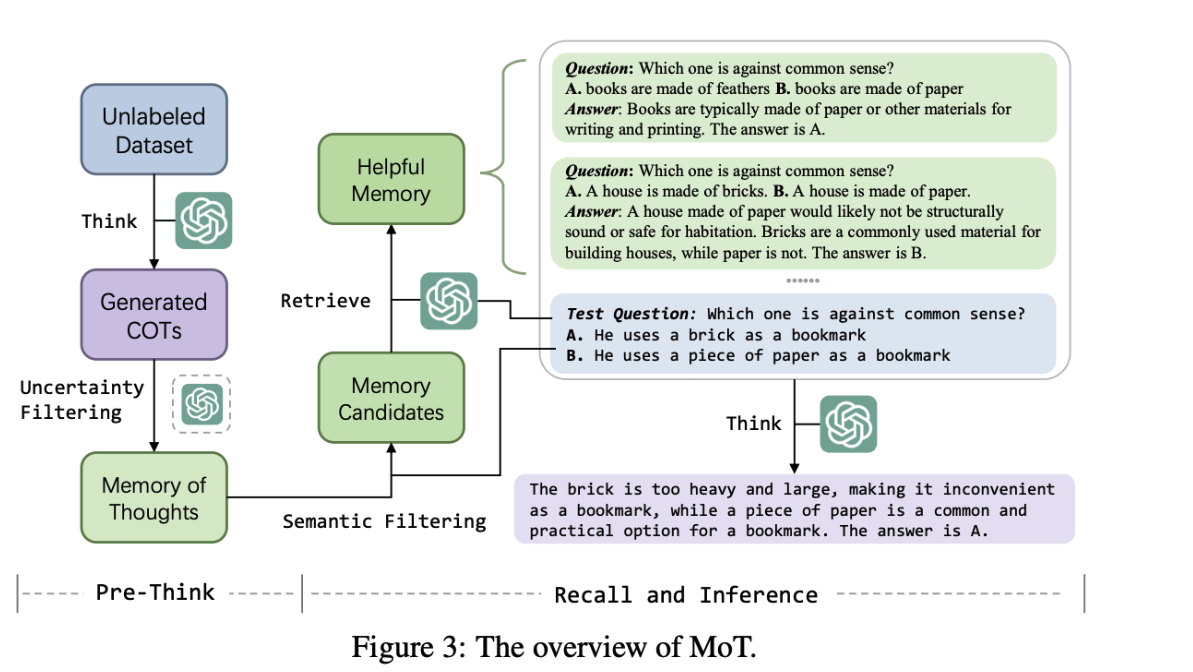
Memory-of-Thought
- LLM이 스스로 생성한 예시를 외부 메모리에 저장해두고 추론 시에 이를 활용하는 기법
- Auto-CoT와 같이 LLM을 통해 추론 과정을 생성
- Self Consistency를 사용해서 모델이 확실히 알고있는 예시를 사용
- 외부 메모리에서 예시를 검색하는건 LLM-Retrieval을 사용
- LLM이 인간 주석 비용 없이 스스로 예시를 생성해 추론하는 또 다른 기법
- 대부분의 데이터 셋에서도 Few-shot CoT를 뛰어넘는 결과를 보여줌
- LLM의 사전 지식에 의존적
- 별도의 메모리가 필요하므로 실제 적용시 메모리 확보해야함
Active Prompt
- 어떤 예시를 주석 처리할지 결정하는 방법을 다루는 기법
- 불확실설 기반의 능동 학습에서 착안
- 모델의 응답 불확실성을 측정해 가장 불확실한 질문을 우선 선택해 주석 처리하는 기법
- 주석 처리 비용을 크게 줄일 수 있다
- 불확실성 기반의 예시 선택이 랜덤적인 예시 선택보다 성능이 훨씬 잘 나온다
- 전이성(Transferability)가 있음
Complexity-based Prompting
- 더 많은 추론 단계를 포함하는 예시를 프롬프트에 추가하면 추론 성능이 크게 향상됨
- 복잡한 예시를 넣는 것을 확장해서 출력 단계에서도 더 많은 단계의 추론 단계를 포함한 답을 선호하는 것으로도 확장될 수 있다
- 다른 예제 선택 방법들과 비교했을 때 성능이 뛰어났음
- 검색 기반 방법도 좋지만 항상 유사한 예시가 있다는 보장은 없으므로 복잡도 기반의 예시 선택은 CoT Prompt 성능에 도움이 될 가능성이 높다
Program of Thought
- CoT는 자연어 기반의 추론 과정이므로 계산문제에서는 약할 수 있다
- 이런 약점을 해결하기 위해 프로그래밍 코드를 생성하도록 하고 코드를 실행해서 처리하는 방법이 PoT이다
- 단계별 추론 영역으로 문제를 해결하는 코드를 생성한다는 점이 포인트
- LLM이 약한 산술 계산 오류를 해결할 수 있다
- Self-Consistency와 같이 사용하면 더 효과적
- 언어 모델의 능력 중 코드 생성 능력이 중요할 것
- PoT를 적용할 땐 여러 오류에 대해서 고려해야함(위험한 코드 생성, 값 오류, 논리 오류)
Contrastive Chain of Thought
- 올바른 추론 예시 뿐 아니라 잘못된 추론 예시까지 포함하는 방법
- 인간은 긍정적인 예시 뿐 아니라 부정적인 예시에서도 학습을 할 수 있다는 점에서 착안함
- 중간 단계의 실수가 전체 추론 과정을 탈선시킬 수도 있음
- 기존 CoT 방법보다 성능적으로 크게 향상됨
- Incogerent Objects, Irrelveant Language 유형일 경우 가장 크게 성능 향상
- 기존의 올바른 추론 과정이 있다면 잘못된 추론 과정을 만드는건 자동화 가능
Strategic Chain of Thought
- SCoT는 효과적인 추론 과정을 먼저 이끌어낸 이후에 최종적인 답변을 생성한다
- LLM이 생성한 CoT 추론 과정의 품질이 일관되지 않기 때문에 생겨남
- 기존에도 CoT Prompt의 추론 품질을 개선하는 방법도 있었음(Self-Consistency)
- 추론 과정의 품질이 일관되지 않는 문제를 해결하는 기법이다
- 다양한 문제 해결 전략을 탐색하는 방법으로 해결하는 기법이다
- 기존의 CoT, Stepback 프롬프트 기법보다 일관되게 성능이 뛰어났음
- 문제 해결 전략을 유도하고 선택하기 때문에 LLM이 가진 사전 지식에 의존적이다
