이진트리란?
1. 기본 개념
이진 트리는 데이터 구조의 하나로, 각 노드가 최대 2개의 자식 노드를 가질 수 있는 트리 구조입니다. Binary Search Tree로 이분화된 탐색을 위한 트리 자료구조라는 뜻이다.
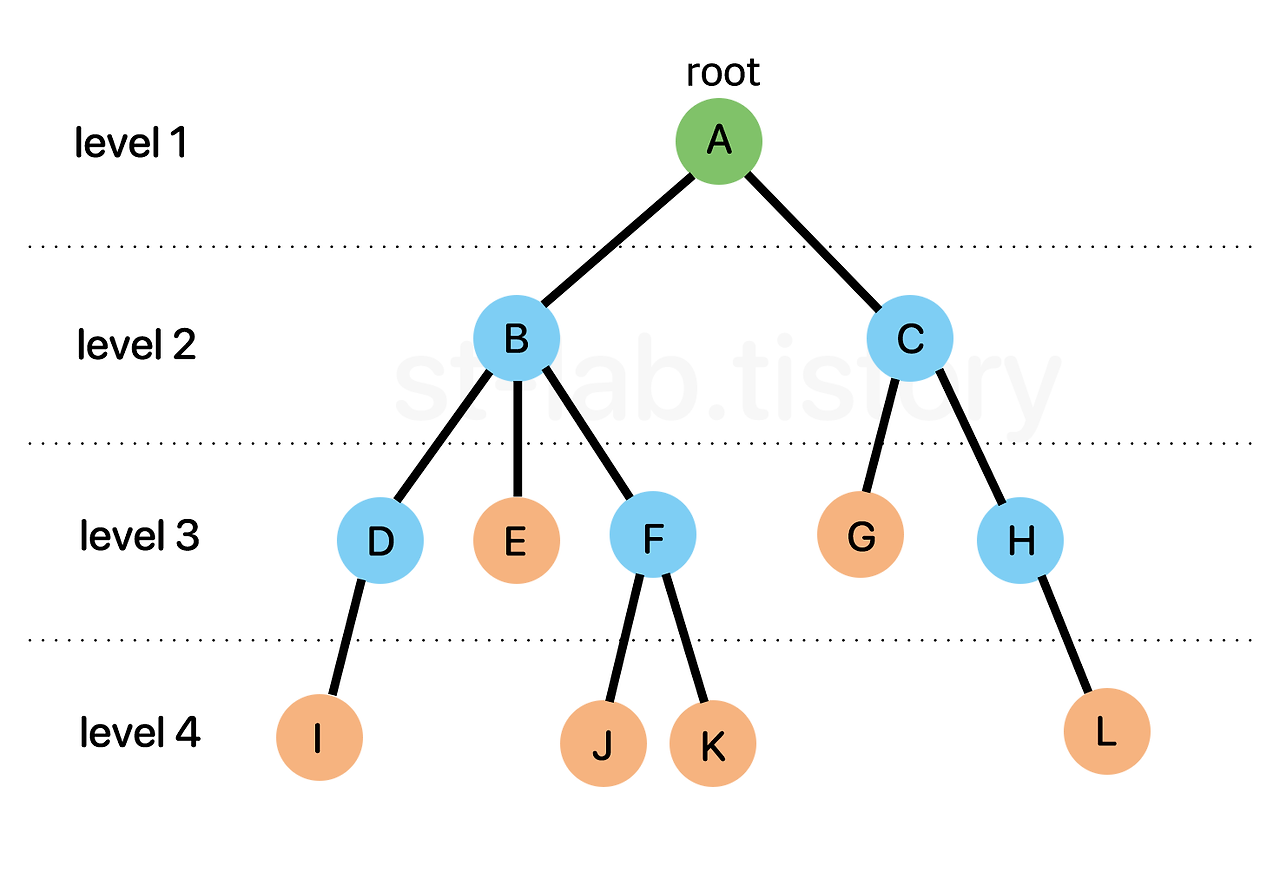
- 루트 노드: 트리의 최상위 노드 (A)
- 부모 노드: 자식 노드를 가진 노드
- 자식 노드: 부모 노드의 하위 노드
- 리프 노드: 자식이 없는 노드 (I, J, K, L)
- 깊이 : 특정 노드에 도달하기 위해 거쳐가야하는 간선의 개수
- 레벨 : 특정 깊이에 있는 노드들의 집합
2. 이진 트리의 종류
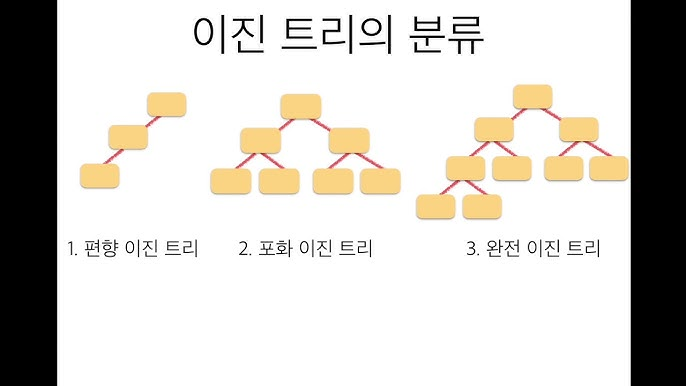
1) 완전 이진 트리 (Complete Binary Tree)
- 마지막 레벨을 제외한 모든 레벨이 완전히 채워져 있음
마지막 레벨은 왼쪽부터 순차적으로 채워짐
2) 포화 이진 트리 (Perfect Binary Tree)
- 모든 레벨이 완전히 채워진 이진 트리
모든 리프 노드가 같은 레벨에 있음
3) 편향 이진 트리 (Skewed Binary Tree)
- 한쪽 방향으로만 자식 노드를 가진 트리
일반적으로 코딩 테스트에서 데이터를 트리에 담으면 완전 이진 트리 형태를 떠올리자
3. 이진 트리의 순차 표현
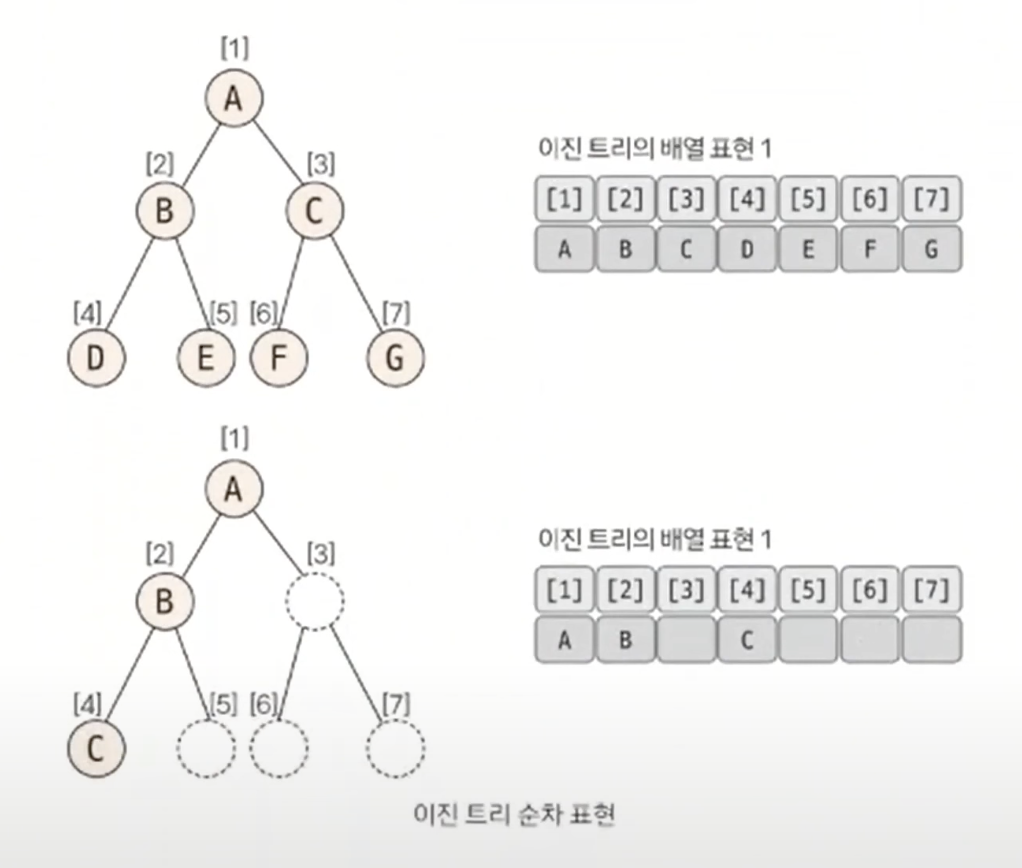
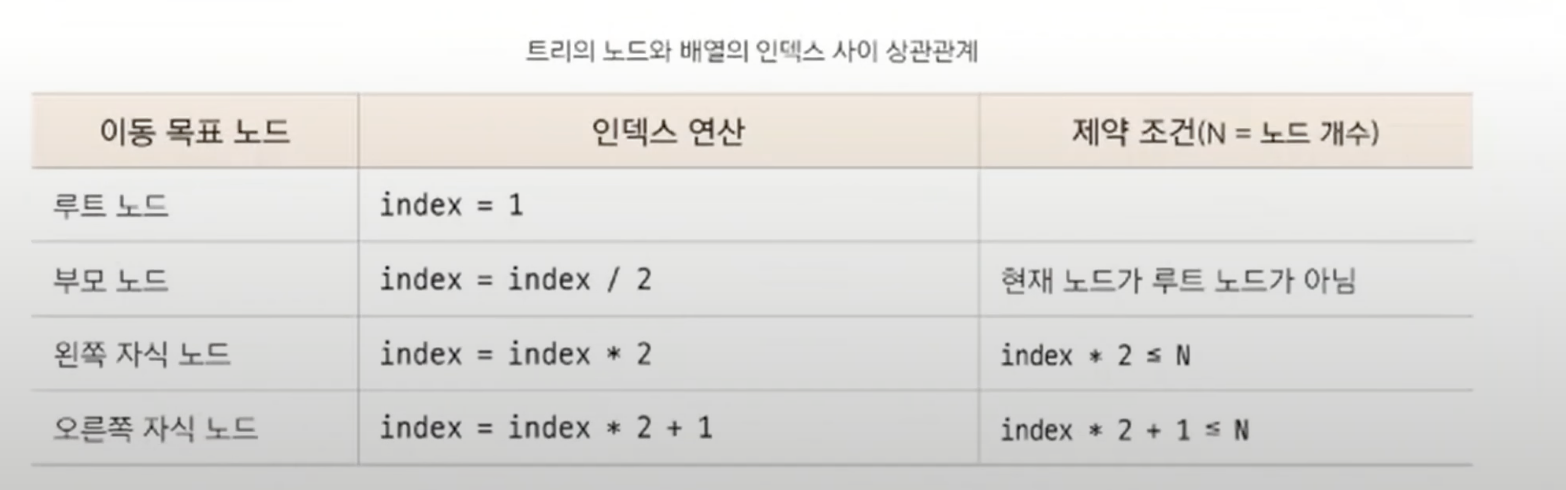
이진 트리는 1차원 배열의 형태로 표현할 수 있다. 이럴 경우 트리의 노드와 배열의 인덱스 간의 상관 관계는 어떻게 될까?
문제
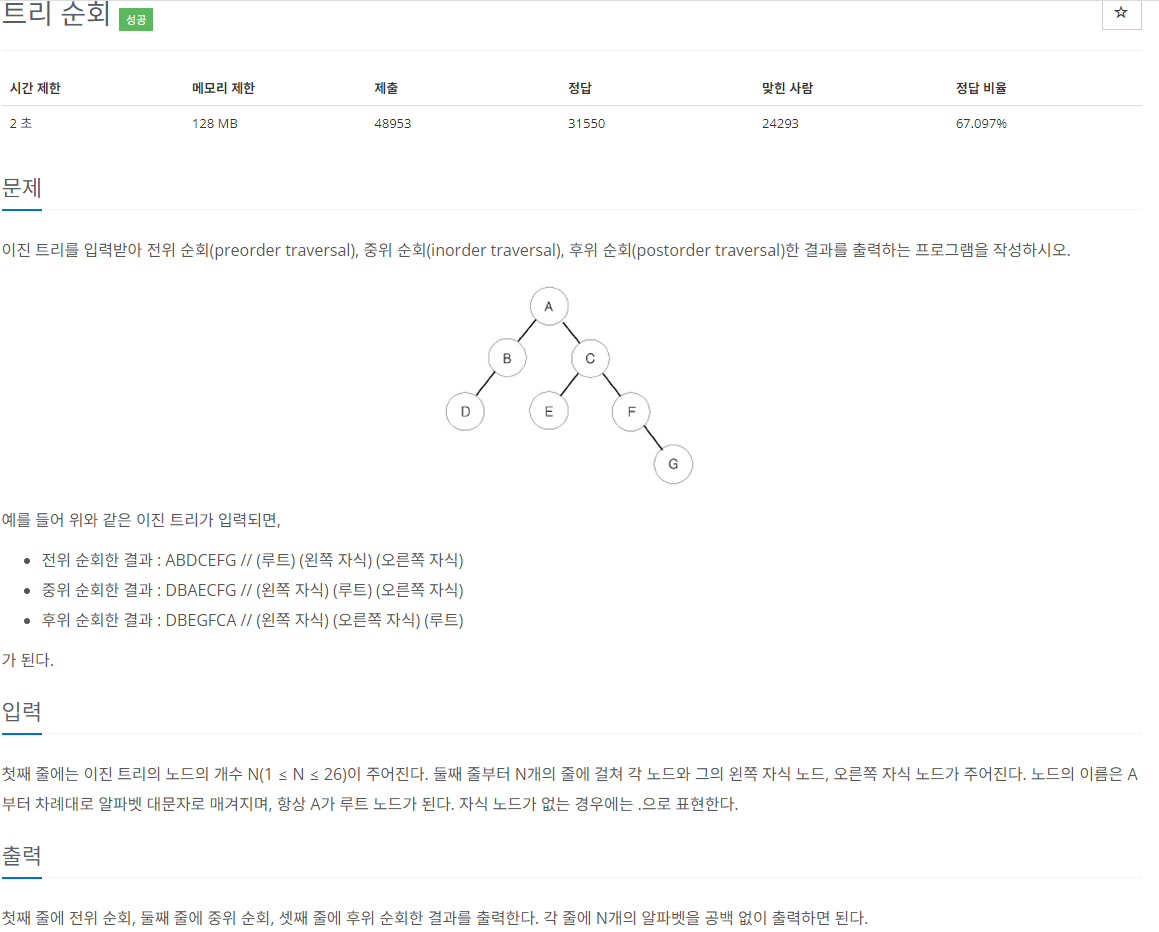
알고리즘 [접근 방법]
문제에서 이진 트리를 입력받아 각각 순회한 결과를 출력하라고 했으므로 이진 트리 알고리즘을 사용한다.
풀이방법
2차원 배열에 트리 데이터를 저장한다.
앞서 설명했던 트리의 노드와 배열의 인덱스 사이 상관관계를 파악하여 전위 순회, 중위 순회, 후위 순회 메서드를 구현한다.
풀이
public class Main {
// 트리를 표현할 이차원 배열
static int[][] tree;
static StringBuilder preorder = new StringBuilder();
static StringBuilder inorder = new StringBuilder();
static StringBuilder postorder = new StringBuilder();
static void preorder(int node) {
if(node == -1) return;
preorder.append((char)(node + 'A')); // 루트
preorder(tree[node][0]); // 왼쪽
preorder(tree[node][1]); // 오른쪽
}
static void inorder(int node) {
if(node == -1) return;
inorder(tree[node][0]); // 왼쪽
inorder.append((char)(node + 'A')); // 루트
inorder(tree[node][1]); // 오른쪽
}
static void postorder(int node) {
if(node == -1) return;
postorder(tree[node][0]); // 왼쪽
postorder(tree[node][1]); // 오른쪽
postorder.append((char)(node + 'A')); // 루트
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
// 트리 배열 초기화 (0: 왼쪽 자식, 1: 오른쪽 자식)
tree = new int[26][2]; // A-Z를 0-25로 표현
// 트리 구성
for(int i = 0; i < N; i++) {
String[] input = br.readLine().split(" ");
int parent = input[0].charAt(0) - 'A'; // 문자를 인덱스로 변환
char left = input[1].charAt(0);
char right = input[2].charAt(0);
// 왼쪽 자식 설정
tree[parent][0] = left == '.' ? -1 : left - 'A';
// 오른쪽 자식 설정
tree[parent][1] = right == '.' ? -1 : right - 'A';
}
// 순회 시작 (루트 노드 A는 인덱스 0)
preorder(0);
inorder(0);
postorder(0);
// 결과 출력
System.out.println(preorder);
System.out.println(inorder);
System.out.println(postorder);
}
}정리
- 트리 배열 선언
static int[][] tree = new int[26][2]; // [노드 번호][0: 왼쪽 자식, 1: 오른쪽 자식]- 트리 구성 부분
int parent = input[0].charAt(0) - 'A'; // 문자를 0-25 인덱스로 변환
char left = input[1].charAt(0);
char right = input[2].charAt(0);
// 왼쪽, 오른쪽 자식 설정 ('.'인 경우 -1로 표시)
tree[parent][0] = left == '.' ? -1 : left - 'A';
tree[parent][1] = right == '.' ? -1 : right - 'A';- 순회 메소드
static void preorder(int node) {
if(node == -1) return;
preorder.append((char)(node + 'A')); // 루트
preorder(tree[node][0]); // 왼쪽
preorder(tree[node][1]); // 오른쪽
}
static void inorder(int node) {
if(node == -1) return;
inorder(tree[node][0]); // 왼쪽
inorder.append((char)(node + 'A')); // 루트
inorder(tree[node][1]); // 오른쪽
}
static void postorder(int node) {
if(node == -1) return;
postorder(tree[node][0]); // 왼쪽
postorder(tree[node][1]); // 오른쪽
postorder.append((char)(node + 'A')); // 루트
} - 트리 전개 과정
- preorder(0) 전개 과정
- node = 0 (A)
- append('A')
- preorder(tree[0][0]) // B로 이동
- node = 1 (B)
- append('B')
- preorder(tree[1][0]) // D로 이동
- node = 3 (D)
- append('D')
- preorder(-1) // 왼쪽 자식 없음, return
- preorder(-1) // 오른쪽 자식 없음, return
- 다시 B로 돌아와서
- preorder(tree[1][1]) // 오른쪽 자식 없음, return
- 다시 A로 돌아와서
- preorder(tree[0][1]) // C로 이동
- node = 2 (C)
- append('C')
- preorder(tree[2][0]) // E로 이동
... (계속)
최종 결과: ABDCEFG
- inorder(0) 전개 과정
- node = 0 (A)
- inorder(tree[0][0]) // 먼저 B로 이동
- node = 1 (B)
- inorder(tree[1][0]) // 먼저 D로 이동
- node = 3 (D)
- inorder(-1) // 왼쪽 자식 없음, return
- append('D')
- inorder(-1) // 오른쪽 자식 없음, return
- 다시 B로 돌아와서
- append('B')
- inorder(tree[1][1]) // 오른쪽 자식 없음
- 다시 A로 돌아와서
- append('A')
- inorder(tree[0][1]) // C로 이동
... (계속)
최종 결과: DBAECFG
- postorder(0) 전개 과정
- node = 0 (A)
- postorder(tree[0][0]) // 먼저 B로 이동
- node = 1 (B)
- postorder(tree[1][0]) // 먼저 D로 이동
- node = 3 (D)
- postorder(-1) // 왼쪽 자식 없음, return
- postorder(-1) // 오른쪽 자식 없음, return
- append('D')
- 다시 B로 돌아와서
- postorder(tree[1][1]) // 오른쪽 자식 없음
- append('B')
- 다시 A로 돌아와서
- postorder(tree[0][1]) // C로 이동
... (계속)
최종 결과: DBEGFCA
여러가지 풀이 방법이 있지만 이차원 배열을 사용하여 트리 구조 표현하여 문제를 풀었다.
이차원 배열로 트리를 구현할 때는 tree[i][0]과 tree[i][1]을 사용하여 각 노드의 자식들을 표현한다. 여기서 i는 부모 노드의 인덱스를 나타내며, 0은 왼쪽 자식, 1은 오른쪽 자식을 의미한다.
또한 알파벳을 배열의 인덱스로 변환하는 과정을 거쳤다. 'A'를 0으로, 'B'를 1로, ... 'Z'를 25로 매핑하는 방식을 사용했다. 이는 문자를 배열 인덱스로 쉽게 변환 가능 (char - 'A') 하며
인덱스를 다시 문자로 변환하기 쉽다. (index + 'A')
시간 복잡도
- 트리 구성: 각 노드를 한 번씩만 처리하므로 O(N)
- 트리 순회: 모든 노드를 정확히 한 번씩 방문하므로 O(N)
- 노드 접근: 배열의 인덱스로 직접 접근하므로 O(1)
- 전체적인 연산: O(N)의 선형 시간 복잡도
이차원 배열 구현의 장단점
- 구현이 단순하고 직관적
- 노드 접근이 빠름 (인덱스 기반)
- 트리의 크기가 고정됨
따라서 이러한 구현 방식은 다음과 같은 경우에 특히 유용하다.
- 트리의 크기가 고정된 경우
- 노드의 삽입/삭제가 빈번하지 않은 경우
- 빠른 노드 접근이 필요한 경우
