💥 TODO 앱 트러블 슈팅
과제를 진행하면서 만난 문제들과 어려웠던 부분을 정리해봤습니다.
1️⃣ 클린 아키텍처 기반의 계층 분리 및 의존성 설계
🔍 상황 인지
과제 요구사항에 '클린 아키텍처'를 적용하라는 내용이 있어서 기존의 MVVM 구조로 설계한 코드들을 클린 아키텍쳐로 바꾸는 과정을 진행했습니다.
그런데 그렇게 짜여진 코드들을 Domain, Data, Presentation 폴더로 쪼개려니 "이 로직은 어느 계층에 넣어야 적절할까?"라는 고민이 생겼고 이를 분류하는데 시간을 많이 사용했습니다.
🤔 고민
일단 "어떻게 하면 앱의 핵심 로직이 Firebase 같은 외부 기술에 의존하지 않게 할 수 있을까?"를 고민해봤습니다.
그리고 개발 과정에서 실제 DB(Firestore) 대신 테스트용 가짜 데이터(Mock)를 사용해야 할 상황이 생길 때 최소한의 코드 수정만으로도 데이터 소스를 갈아끼울 수 있는 구조를 만들고 싶었습니다.
🛠️ 적용
각 계층이 유기적으로 연결되면서도 독립성을 유지하도록 객체 간의 의존성 관리 체계를 구축했습니다.
DataSource (Data 레이어): 파이어베이스와 직접 대화하는 복잡한 저수준 코드들을 별도의 클래스 DataSource 안에 넣었습니다. 이를 통해 다른 코드들이 파이어베이스의 구체적인 명령어를 몰라도 데이터를 주고받을 수 있도록 정리했습니다.
Repository 인터페이스 (Domain 레이어): 데이터가 어디서 오는지와 상관없이 동일한 기능을 수행하도록 추상 클래스 TodoRepository를 정의했습니다. 이를 통해 실제 구현체와 앱의 비즈니스 로직 사이의 결합도를 낮췄습니다.
Repository 구현체 (Data 레이어): 인터페이스를 실제로 구현한 TodoRepositoryImpl을 만들어 구체적인 데이터 처리 로직을 담당하게 했습니다.
의존성 관리 (providers.dart): todoRepositoryProvider가 todoDataSourceProvider를 관찰하도록 설계했습니다. 덕분에 코드를 조금만 수정해도 실제 DB와 Mock 데이터를 자유롭게 교체할 수 있는 구조를 완성했습니다.
✨ 결과
각 계층이 서로의 내부 사정을 모른 채 인터페이스로만 소통하게 되어 코드의 독립성이 확실해졌습니다. 특정 기능을 수정하더라도 다른 곳에 큰 영향을 주지 않는 단단한 구조가 되었으며 프로젝트 전체의 데이터 흐름을 한눈에 파악할 수 있게 되어 유지보수가 훨씬 쉬워졌습니다.
2️⃣ 인피니트 스크롤 구현
🔍 상황 인지
처음에 설계할 때는 할 일 목록을 한 번에 모두 불러오는 방법으로 구현했습니다. 하지만 데이터가 늘어날 경우 모든 목록을 한 번에 불러오는 것은 앱 속도 저하와 불필요한 서버 비용(Firestore 호출량)도 많이 들 수 있다는 점을 알게 되었습니다. 그래서 사용자가 리스트를 내릴 때마다 15개씩 데이터를 나눠서 가져오는 인피니트 스크롤을 구현하기로 했습니다. 처음에는 단순히 '페이지 번호'로 관리를 해서 몇 번째 페이지인지, 마지막 페이지인지 아닌지만 구분했는데 실제 구현 과정에서 데이터가 중복되거나 누락되는 문제가 생겼습니다.
🤔 고민
"현재 로딩 중인가?", "더 가져올 데이터가 있는가?", "다음엔 어디서부터 가져와야 하는가?"라는 세 가지 상태를 유기적으로 관리를 해야 했습니다.
사용자가 투두 리스트 맨 끝에 완전히 닿은 후에야 로딩이 시작되면 데이터가 나타날 때까지 흐름이 끊기게 됩니다. "사용자가 바닥에 닿기 전, 미리 다음 데이터를 가져올 수 없을까?"라는 고민도 했습니다.
🛠️ 적용
1) TodoListState 상태 재설계
로딩 상태와 데이터의 끝을 판별하기 위해 기존 상태 모델TodoListState를 확장했습니다.
class TodoListState {
final List<ToDoEntity> todos;
final Object? lastCursor; // 다음 데이터를 가져올 기준점 (마지막 데이터 위치)
final bool isLastPage; // 더 가져올 데이터가 없는지 확인
final bool isLoading; // 중복 호출 방지를 위한 로딩 상태 확인
TodoListState({
this.todos = const [],
this.lastCursor,
this.isLastPage = false,
this.isLoading = false,
});
}2) 중복 요청 차단 및 데이터 병합 로직
fetch 함수 내에 로딩 중이거나 이미 데이터를 다 가져온 상태에서는 불필요한 추가 요청을 방지하고 다음 데이터를 가져오게 구현했습니다.
Future<void> fetch({bool isRefresh = false}) async {
// 중복 호출 및 불필요한 요청 방지
if (!isRefresh && (state.isLastPage || state.isLoading)) return;
state = state.copyWith(
isLoading: true,
isLastPage: isRefresh ? false : state.isLastPage,
);
try {
// Repository로부터 페이징 결과(데이터, 다음 커서, 추가 여부) 수신
final result = await _repo.getToDos(
limit: _limit,
lastCursor: isRefresh ? null : state.lastCursor,
);
state = state.copyWith(
// 새로고침이면 교체, 아니면 기존 리스트에 추가(병합)
todos: isRefresh ? result.todos : [...state.todos, ...result.todos],
lastCursor: result.lastCursor,
isLastPage: result.todos.length < _limit, // 가져온 데이터가 limit보다 적으면 끝으로 판단
isLoading: false,
);
_refreshStatistics();
} catch (e) {
state = state.copyWith(isLoading: false);
}
}3) UI 선제적 로딩 (Pre-fetching)
사용자가 로딩을 체감하지 못하도록 바닥에 닿기 200px 전에 미리 다음 데이터를 호출하는 로직을 적용했습니다.
NotificationListener(
onNotification: (notification) {
if (notification is ScrollUpdateNotification) {
final metrics = notification.metrics;
// 바닥까지 200px 남았을 때 미리 다음 페이지 호출
if (metrics.pixels >= metrics.maxScrollExtent - 200) {
ref.read(homeViewModel.notifier).onEvent(HomeFetchRequested());
}
}
return false;
},
child: ListView.builder(),
)✨ 결과
데이터 중복 호출 문제를 해결하여 서버 리소스 낭비를 최소화했습니다. 특히 200px 여유를 둔 선제적 로딩 기법을 통해 사용자는 대량의 리스트를 탐색할 때도 멈춤이나 버벅임 없이 쾌적하게 서비스를 이용할 수 있게 되었습니다. 또한 RefreshIndicator와 페이징 로직을 유기적으로 연결하여 데이터의 최신성과 사용성을 동시에 확보했습니다.
3️⃣ 인피니트 스크롤과 실시간 통계의 모순
🔍 상황 인지
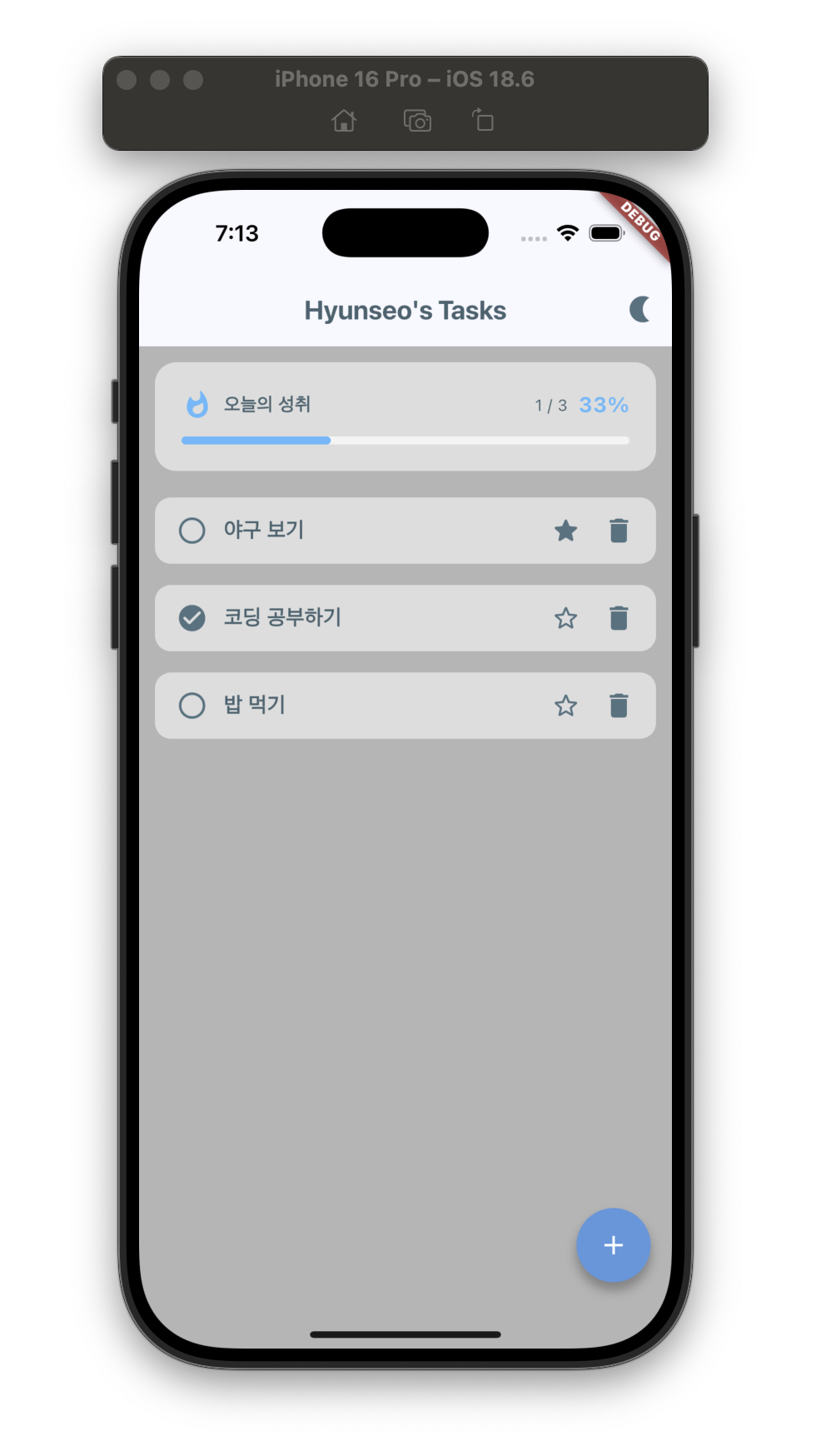
이번 프로젝트에서 나만의 기능으로 할 일 완료 현황 대시보드 를 리스트 상단에 추가했습니다. 하지만 인피니트 스크롤을 적용하자 예상치 못한 문제가 발생했습니다. 상단 대시보드가 데이터베이스 전체 기준이 아닌 현재 화면에 로드된 데이터(15개씩)만 계산하여 보여주는 것이었습니다. 이로 인해 사용자가 스크롤을 내릴 때마다 전체 할일 현황이 15, 30, 45로 늘어나며 통계 수치가 계속 변하는 버그가 나타났습니다.
🤔 고민
사용자에게 정확한 전체 달성률을 보여주려면 데이터베이스의 모든 할 일을 알아야 합니다. 하지만 통계 하나를 위해 수백 개의 데이터를 한꺼번에 불러온다면 성능 최적화를 위해 도입한 인피니트 스크롤의 의미가 사라지게 됩니다. "데이터 로딩은 최소화하면서, 어떻게 전체 데이터의 상태를 실시간으로 파악할 것인가?"가 핵심 고민이었습니다.
그냥 이 상태로 냅둘까.. 하고 잠시 생각도 했지만, 스크롤 위치에 따라 통계 숫자가 자꾸 바뀌는 것은 사용자 경험을 떨어뜨리는 치명적인 UX 문제라고 판단했습니다. 또한 전체 개수와 완료된 개수를 각각 따로 불러오면 응답 시간이 길어질 수 있는데 이를 어떻게 효율적으로 처리할지도 함께 고민했습니다.
🛠️ 적용
1) [Data] Firestore 집계 쿼리(count)와 병렬 처리
모든 할 일을 가져오는 대신 서버 측에서 숫자만 빠르게 세어 반환하는 집계 쿼리를 사용했습니다. 응답 속도를 높이기 위해 Future.wait로 두 가지 데이터를 동시에 요청했습니다.
// TodoDataSourceImpl: 서버에서 숫자만 빠르게 가져오기
Future<TodoStatisticsDto> getTodoStatistics() async {
final todosCollection = _firestore.collection('todos');
// 전체 개수와 완료된 개수 집계 쿼리를 병렬로 실행하여 시간 단축
final results = await Future.wait([
todosCollection.count().get(),
todosCollection.where('isDone', isEqualTo: true).count().get(),
]);
return TodoStatisticsDto(
total: results[0].count ?? 0,
completed: results[1].count ?? 0,
);
}2) [Domain] 유스케이스를 통한 로직 분리
통계 데이터가 리스트 로딩과 섞이지 않도록 독립적인 유스케이스를 만들어 관리했습니다.
// GetTodoStatisticsUseCase: 통계 데이터만 전문적으로 가져오는 역할
class GetTodoStatisticsUseCase {
final TodoRepository repository;
GetTodoStatisticsUseCase(this.repository);
Future<TodoStatistics> execute() async {
return await repository.getTodoStatistics();
}
}3) [Presentation] 실시간 상태 업데이트 트리거
데이터를 새로 불러오거나 수정, 삭제 등의 변화가 생길 때마다 통계를 다시 갱신하도록 설계하여 화면에 로드된 개수와 상관없이 항상 최신 수치를 유지했습니다.
// TodoListNotifier: 데이터 변화가 있을 때마다 호출
Future<void> _refreshStatistics() async {
try {
// 유스케이스를 통해 DB 전체 기준의 정확한 통계 획득
final statistics = await _getStatisticsUseCase.execute();
state = state.copyWith(statistics: statistics);
} catch (e) {
print('통계 갱신 실패: $e');
}
}✨ 결과
인피니트 스크롤을 통해 기기 메모리와 네트워크 비용은 아끼면서도, 상단 대시보드에는 항상 실제 데이터베이스 전체 기준의 정확한 달성률을 보여줄 수 있게 되었습니다. 특히 count() 쿼리를 통해 데이터 읽기 비용을 줄였고 Future.wait를 통한 병렬 처리로 빠른 UX를 구현했습니다.
과제를 마무리하며
처음에는 과제이니 일단 동작하게 만드는 것이 목표였지만
구현을 거듭할수록 “이 구조면 사용하기 불편하지 않을까?”라는 생각이 들며
자연스럽게 더 나은 방향을 고민하게 되었습니다.
특히 인피니트 스크롤과 통계 기능이 충돌했을 때
기능을 제거하고 마무리할까 고민하기도 했지만
문제를 분리해 하나씩 접근해보니 생각보다 충분히 해결 가능한 문제였습니다.
앞으로도 단순히 요구사항을 만족시키는 구현에 그치지 않고
사용자 경험과 유지보수를 함께 고려하는 기준으로 프로젝트를 진행하고 싶습니다.
