Java의 자료구조를 공부하던 중 java.util.HashMap의 put() 메서드를 분석하게 되었습니다.
이를 분석하며 개념보다는 구체적으로 어떻게 구현되어 있는지 포스팅해보겠습니다.
이 포스팅에선 put() 메서드만 분석하겠습니다.
또한 지엽적인 변수나 본질과 조금 거리가 있는 경우엔 제외하고 설명하였습니다.
Map<String, Integer> scores = new HashMap<>();
scores.put("김철수", 95);
scores.put("이영희", 88); 위는 String을 키로, Integer을 값으로 가지는 HashMap을 생성하고, put() 메서드로 데이터를 추가합니다.
해시맵의 동작 방식은 값을 삽입하면 키 값으로 해시 함수를 통해 해시값을 가져와 버킷의 크기만큼 나머지 연산을 한다고 다들 알고 있습니다. (hash(key) % table.length)
사실 그 말은 맞는 말입니다. 하지만 제목은 나머지 연산은 하지 않는다고 왜 어그로를 끌었을까요?
사실 정확하게는 HashMap은 비트연산을 통해 나머지 연산과 동일한 연산을 수행하게 됩니다.
즉, 개념적으로는 나머지 연산이지만 실제 구현은 비트연산으로 되어있다는 것이죠.
어떻게 구현되어 있는지 알아보도록 하겠습니다.
실제 put() 메서드의 소스코드를 분석하면 다음과 같습니다.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}내부적으로 putVal()을 호출하게 됩니다.
그러면 실제로 구체적인 putVal() 메서드를 분석해보겠습니다.
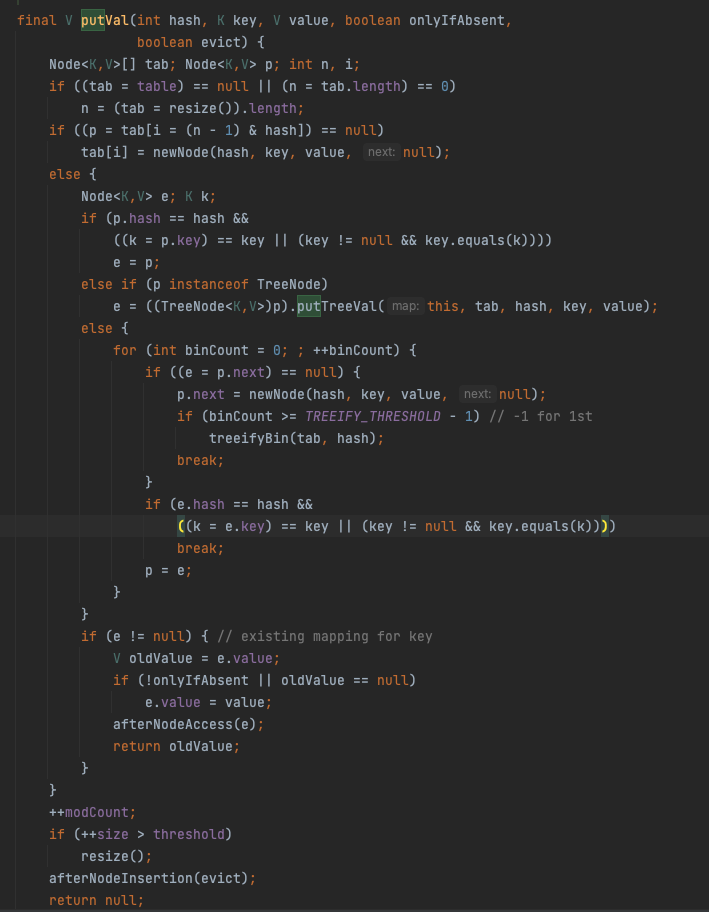
처음보면 굉장히 어려워보이지만 차근차근 들어가면 어렵지 않으니 한번 조금씩 분리해서 분석해보겠습니다!
주요 변수
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;hash : 현재 삽입할 키의 해시값
key : 현재 삽입할 키 값
value : 현재 삽입할 값
onlyIfAbsent : 키 충돌시 값을 덮어쓸지 말지 결정하는 플래그
onlyIfAbsent와 evict는 부가적인 기능을 위한 플래그인데 몰라도 본질을 이해하는데는 상관 없습니다.
tab : 해시맵 내부 테이블 변수
p : 현재 노드를 참조할 변수
n : 테이블의 길이 변수
i : 키가 저장될 인덱스 변수
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
... 중략
}보면 첫 줄에 tab = table을 이용해 해시맵 내부 테이블 변수에 값을 할당하는 것을 볼 수 있습니다.
table을 직접 사용하지 않고 tab이라는 변수에 굳이 넣어준 이유는 최적화 때문인데 이는 Hashmap 동작과 지엽적이기 때문에 따로 포스팅한 블로그 글을 확인해주세요!
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;테이블이 초기화되지 않았다면 resize()를 호출하여 테이블을 초기화합니다.
초기화 후 n에 테이블의 크기를 저장하게 됩니다.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);요거는 조금 어려워보이는데요. 사실 여기에 오늘 제목의 비밀이 있습니다.
i 변수에는 저장할 value의 버킷을 구하게 됩니다. 즉, 키가 저장될 인덱스 변수입니다.
위에서 말한 hash(key) % tab.length (n) 의 로직이 (n - 1) & hash과 동일합니다.
이게 어떻게 가능한걸까요?
이는 해시맵 내부에서 보관하는 테이블 크기와 관계가 있는데요 HashMap의 내부 배열(테이블) 크기는 항상 2의 제곱수(2, 4, 8, 16, 32, 64...)입니다.
이렇게 설계된 이유는 & 연산을 통해 나머지 연산을 하지 않고 cpu 친화적인 비트 연산을 사용하기 위해서인데요.
이진수 체계에서 2ⁿ으로 나눈다는 것은 소수점을 왼쪽으로 n자리 옮기는 것과 같습니다.
예를 들어 42₁₀ = 101010₂를 2³(8)로 나누면(42 % 8)
101010₂ ÷ 1000₂ = 101.010₂ (101010에서 3번째 . 처리)
정수 부분: 101₂ = 5 (몫)
소수 부분: .010₂ = 2 (나머지)
즉, 마지막 n개의 자리를 구하면 된다는 것을 의미합니다.
그렇게 하기 위해 n - 1을 이진수화 시켜서 마스킹 처리를 통해 n개의 자리를 구하는 것입니다.
8 : 1000
8 - 1 : 0111 -> 2^n - 1을 하면 n개의 자리가 111 처리가 됩니다.
이 값과 해시값(42)을 & 연산(둘다 1이면 1, 아니면 0) 을 한다면 원하는 비트만 남기고 나머지는 0으로 만들 수 있습니다.
즉, 마지막 n개의 자리를 구할 수 있게 됩니다.
101010
000111
++++++
000010 -> 2 정답!
테이블의 크기가 2의 제곱수여야 하는 이유
제곱수는 n개의 자리가 모두 0이고 첫번째 값이 1인 특징이 있습니다.
2 : 10
4 : 100
8 : 1000
즉, 위 특징을 이용해 -1을 이용해 마스킹 처리를 할 수 있게 해줍니다.
다시 돌아와서...
즉, 두 번째 if문은 키가 저장될 버킷이 비어있는지 확인하는 절차입니다. 만약 비어있다면 노드를 삽입해줍니다.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); -> 노드 삽입그렇다면 else문은 그러면 뭘까요? 키가 저장될 버킷이 비어있지 않다 = 어떤 특정 노드가 들어가 있다는 것입니다.
즉, 해시 충돌이 일어났다는 것입니다. 그렇다면 separate chaining 방식으로 구성된 리스트에서 삽입할 구간을 찾아줘야합니다.
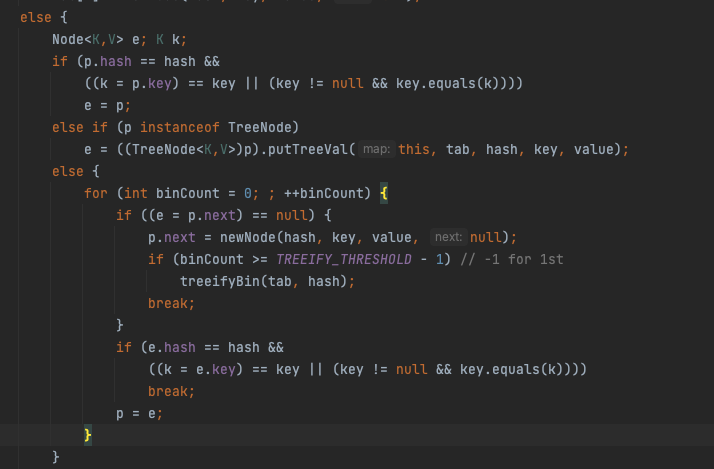
해시 충돌이 발생했을 때도 크게 3가지의 상황이 있습니다. 각 상황을 분석해보겠습니다.
1. 버킷 내부의 첫 원소에서 바로 내가 넣을 원소의 키 값과 같은 경우
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;이는 현재 참조한 버킷의 첫 번째 노드의 키가 삽입할 노드의 키와 일치하는지를 말합니다.
현재 버킷을 찾았는데 충돌한 상태라면 내부의 리스트에 여러 노드가 연결되어 있을 것입니다.
이러한 상황에서 키가 같다면 노드 변수 e에 현재 노드의 참조값을 전달합니다. (삽입은 추후에 처리합니다)
2. 버킷의 내부가 리스트가 아닌 트리로 구성되어 있는 경우
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);이 경우엔 putTreeVal()을 이용해 트리에서 작업해줍니다. 어떻게 작업하는지는 길어지는 관계로 다루지 않겠습니다.
3. 그외의 경우 즉, 리스트로 구성되어있으면서도 첫번째 노드가 아니라서 탐색이 필요한 경우
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}순회하며 일치한 키 값이 있다면 그 키를 저장하고, 일치한 키 값이 없다면 첫 if문을 통해 리스트 마지막에 노드를 생성시킨다.
만약 트리를 위한 임계점(8)에 도달한다면 트리 전환을 수행한다.
위의 단계를 거치게 되면 e변수에 현재 찾은 노드의 위치를 담고 있는데, 마지막에 값을 삽입해주게 된다.
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) // 플래그에 따라 덮어쓸지 말지
e.value = value;
afterNodeAccess(e);
return oldValue;
}이렇게 putVal() 메서드는 끝이난다!
중요한점 3줄 요약
- 해시맵은 실제로 % 연산이 아니라 테이블의 크기 - 1 & hash 연산을 통해서 나머지 연산을 구현한다.
- 내부 테이블의 크기는 항상 2의 제곱수여야 한다. 2의 제곱수여야만 나머지 연산이 잘 수행된다.
- 모두 행복한 하루 보내세요 안녕!
