응용프로그램이 실행되면 JVM은 시스템으로부터 프로그램을 수행하는데 필요한
메모리를 할당받는다.
이 메모리를 용도에 따라 여러 영역으로 관리하는데 이 구조를 알아보자
JVM 과정을 알고 싶다면 -> 이 글을 클릭하시오
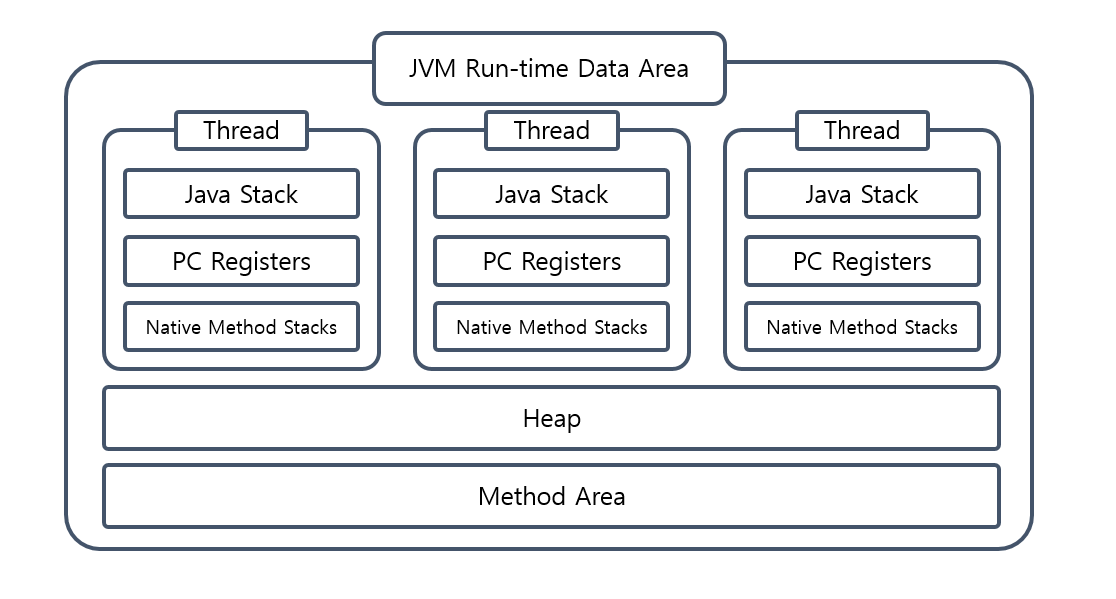
코드가 실행되고 클래스로더가 Run-time Data Area로 로딩시킨다
Run-time Data Area에서는 Heap과 Method Area는 전체 스레드가 공유하고
나머지는 스레드별로 생성되는 데이터 영역을 가지게 된다
아래 코드를 예시로 어떻게 저장되는지 확인하자
public class test {
int iv; // 인스턴스 변수
static int cv; // 클래스 변수
void method() {
int lv; // 지역 변수
}
}1. Method Area
- .class파일의 바이트코드가 저장되는 공간
- 클래스 로더가 클래스 파일을 읽어오면 클래스정보를 파싱하여 Method Area에 저장
- 클래스 변수(cv)와 클래스 정보를 가져온다
2. Heap
- 동적으로 생성된 객체가 저장되는 공간(GC의 대상)
- new연산자로 만들어진 객체와 배열을 저장한다
- 인스턴스 변수 iv가 heap영역에 저장된다
new int[5];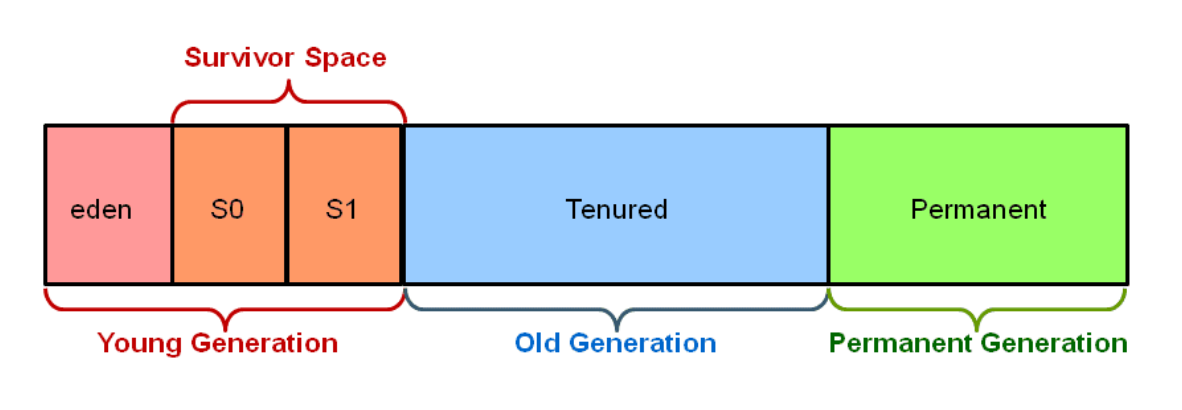
또한 효율적인 GC를 위해 위와 같이 Heap영역을 나눴다
위와 같이 나눈 이유를 알고 싶다면 GC를 공부하자 여기서 다루지는 않겠다
3. Stack
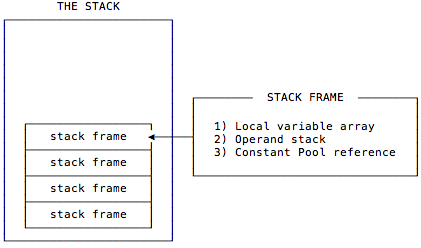
- 스레드 마다 존재
- 지역변수, 메서드의 매개변수, 임시적으로 사용되는 변수,메서드가 저장되는 공간
- JVM 스레드가 생성될 때 해당 스레드를 위한 스택이 만들어진다
->그 스택안에는 Frame이 들어가게 된다
Frame := 메소드가 호출될 때마다 만들어지고, 메소드의 상태 정보 저장 - 스레드가 쓸 수 있는 스택의 사이즈를 넘기게 되면 StackOverflowError가 발생한다.
- 스택 프레임은 메소드가 호출될 때 마다 생성되고 실행이 끝나면 Pop되어 삭제
ex) main() -> method1() -> method2() -> 각각의 스택 프레임생성 (3개) - 위 코드의 지역변수 lv가 메소드가 호출되면 스택에 저장됨
Frame의 구성요소
- Local Variables Array(지역 변수 배열)
- Operand Stack (메소드 내의 계산 공간)
- Constant Pool Reference(상수 풀 참조 - 상수를 담는 테이블)
아래의 영상을 보면 각 구성요소가 어떻게 저장되고 어떻게 관리되는지 볼 수 있다
유의사항
Car c = new Car("아반떼");위와 같은 코드가 있으면 new Car("아반떼") 객체가 Heap영역에 들어가고
인스턴스 c는 Stack 영역에 들어간다
4. PC Register
- 스레드 마다 존재
- 스레드가 시작될 때 생성되며 수행중인 JVM의 명령어를 저장하는 공간
- 스레드가 어떤 부분을 어떤 명령어로 실행할지 저장하는 공간
5. Native Method Stack
- 스레드 마다 존재
- Java가 아닌 다른 언어의 코드를 위한 공간
참고 매체
https://hongsii.github.io/2018/12/20/jvm-memory-structure/
https://johngrib.github.io/wiki/jvm-stack/
https://www.youtube.com/watch?v=GU254H0N93Y
후기
단순히 이론적으로 어딘가에 저장된다는 것은 알았지만 그 어딘가의 구조를 세세하게 알게되고 실제로 어느 코드를 적용하여 흐름도를 파악하니까 더욱 이해하기 좋았다
이 글이 흐름을 읽기엔 쉽지 않아 이해가 어렵다면 위의 유튜브 영상을 봐보면
훨씬 이해가 쉬울 것이다.
