목적
초보자가 봐도 이해할 수 있도록 문자열을 비교하는 알고리즘에 대한 설명
단순 구현이 아닌 성능 최적화에 포커스를 둔 설명
목차
- 문자열의 구조 및 고려사항을 설명
- 두 문자열의 사전순 비교 알고리즘 설명 및 구현(최적화)
- 두 문자열이 동일한지 비교 알고리즘 설명 및 구현(최적화)
- 최종 소스코드
문자열의 구조 / 고려사항
문자열은 문자값(char)의 배열이다
String str = "Hi"; // char arr["H","i"];배열은 한번에 비교하기 쉽지 않은 구조(원소가 많은만큼 시간이 걸림)
그렇기에 두 배열의 비교는 배열의 길이 만큼의 시간 소모
배열 혹은 문자열을 다루는 내장기능이나 함수들은
길이에 비례한 시간을 소모하기에 대략적인 시간복잡도를 알아두자!!
1. 문자열의 사전순 비교
두 단어 algorithm과 allergy를 생각해봤을 때
일반적으로 어떤 단어가 더 앞에 있을까?
-> 세번째 알파벳 g가 l보다 사전순으로 더 빠르니 algorithm일 것
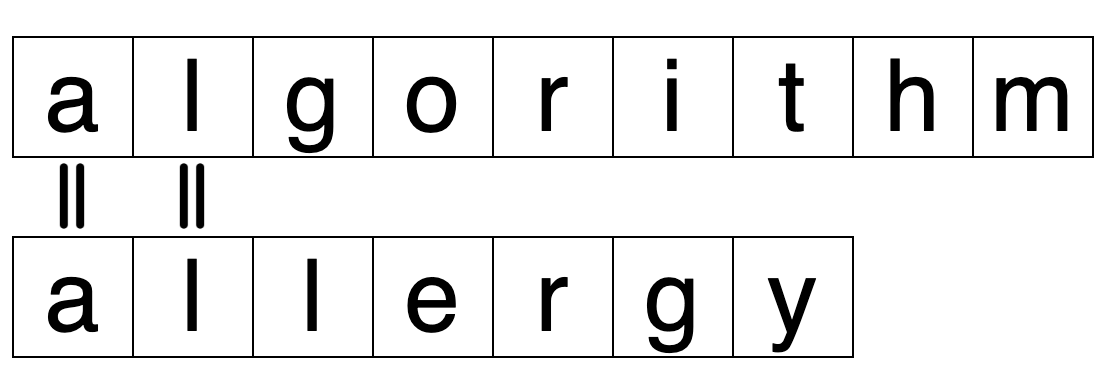
case1 : 서로 다른 문자가 등장하는 위치가 존재하는 경우
서로 다른 문자가 등장하는 첫위치에서의 두 문자의 사전 순 관계
문자데이터에 대한 공부를 했다면 실제로는 문자 데이터들이
내부적으로는 바이트 단위의 숫자데이터인 것을 알것이다(유니코드, 아스키코드..)
문자데이터들도 숫자 데이터기에 대소 비교가 가능
// algorithm : s1[] / allergy : s2[]
if (s1[2] < s2[2]){
// ok
}case2 : 서로 다른 문자가 등장하지 않는 경우
예시로 app vs apple이 있다
app까진 같다가 비교 대상이 없으면 비교대상이 없는얘가 사전순으로 앞서게 된다
사전순 비교 구현
문자열의 사전순 대소관계 비교를 위한 함수 compare(s1,s2)를 완성하세요.
s1이 s2보다 사전순으로 빠른 단어라면 음수를 반환한다.
s1과 s2가 정확히 동일한 문자열이라면 0을 반환한다
s2가 s1보다 사전순으로 빠르다면 양수를 반환한다.
public class Q2D {
// 문자열의 사전 순 대소관계 비교를 위한 함수 compare(s1, s2)만들기
// s1이 s2보다 빠르면 음수, 동일하면 0, 느리다면 양수 반환
// 문자열의 일치여부 확인을 위한 equals(s1, s2)만들기
// 일치하면 true, 일치하지 않으면 false 반환
// 사전 순 대소관계 비교 함수
public static int compare(char[] s1, char[] s2) {
// case1 서로 다른 문자가 등장하는 위치가 존재하는 경우
// ex) algorithm vs allergy
int n = Math.min(s1.length, s2.length); // n = 두 문자열 중 작은값
for(int i = 0; i < n; i++) { // 두 문자열 중 작은값까지만 비교
if(s1[i] != s2[i]) { // 최초로 다른 문자라면
if(s1[i] < s2[i]) { // s1이 s2보다 빠르다면
return -1; // 리턴을 넣어 성능 개선(리턴하면 더 반복하지 않음)
}else {
return 1;
}
}
}
return 0; // 위 조건이 실행되지 않으면 동일하다
// case2 서로 다른 문자가 등장하지 않은 경우 (길이가 같은 경우와 다른 경우)
// ex) app vs app, app vs apple
// 둘이 길이가 같다면 n값이 같을 것 -> 이 경우는 문자열이 일치
if(s1.length == s2.length){ // app vs app
return 0;
}else if(s1.length < s2.length){ // app vs apple
return -1;
}else{ // apple vs app
// s1.length > s2.length
return 1;
}
}
}위에서 배운 개념을 적용하여 알고리즘을 구현한다면 위와 같이 구현할 수 있다
그러나 위의 로직은 중첩if문의 사용으로 가독성도 좋지 않고 성능적으로도 개선할 수 있다
어떻게 성능 개선을 할 수 있는지 알아보자
case1 최적화
음수 양수로만 판별하면 되기 때문에 굳이 if문 연산이 아닌
아스키코드 연산을 한다면 아래와 같이 코드를 짤 수 있다
s1[i] - s2[i]를 한다면 s1이 빠른단어면 음수가 나올 것
public static int compare(char[] s1, char[] s2) {
// 1. 서로 다른 문자가 등장하는 위치가 존재하는 경우
// ex) algorithm vs allergy
int n = Math.min(s1.length, s2.length);
for(int i = 0; i < n; i++) {
if(s1[i] != s2[i]) {
return (int)s1[i] - s2[i]; // int 계산이 됨(우선순위)
// (int)'g' = 103
// (int)'l' = 108
}
}위와 같이 최적화 할 수 있다
case2 최적화
case2의 경우 그냥 조건문을 모두 없애고 크기를 연산해 최적화 할 수 있다
// 2. 서로 다른 문자가 등장하지 않은 경우 (길이가 같은 경우와 다른 경우) ex) app vs app, app vs apple
return s1.length - s2.length;사전 순 비교 함수(최적화 완료)
public static int compare(char[] s1, char[] s2) {
int n = Math.min(s1.length, s2.length);
for(int i = 0; i < n; i++) {
if(s1[i] != s2[i]) {
return (int)s1[i] - s2[i];
}
}
return s1.length - s2.length;
}짠! 위의 복잡한 코드가 엄청 간결해진 것을 볼 수 있다
2. 문자열 동일 판별 알고리즘(equals())
그냥 위 코드에서
return compare(s1, s2) == 0
하면 안되나요?? 라고 물어본다면 가능하다
하지만 시간적 개선(성능 개선)을 목표로 된 설명이기에 이에 대해 설명하겠다
얼마나 일치할까?
완전 임의로 선택된 두 변수 A, B에 대해서 두 값이 일치할 확률은 상당히 적다
무슨말이냐면
int a = ?
int b = ?
if(a == b){
}위 조건문이 실행될 확률은 int는 4바이트 즉 32비트 이기에
2의 32제곱 중 한번 실행될 확률이다(매우 적은 확률)
변수만 해도 이렇게 적은 확률인데 배열은 훨씬 적을 것이다
Question
두 문자열이 같은가의 질문에서 사전순의 대소관계는 꼭 필요한 질문인가?
우리는 일치한 확률에 접근할 것이 아닌 그의 반대
일치의 여집합인 불일치에 접근할 것(불일치 제외의 상황은 모두 일치로 작성하면된다)
불일치에 접근한다고 가정해보자
app vs apple -> 길이가 다르면 애초에 비교할 필요가 없다
앞에서 비교를 한 이유는 공통부분까지를 통해 다르다는걸 검증하고
어떤 문자가 사전순으로 앞서는지에 대한 정보가 필요했기 때문이지 이번엔 필요없음
equals() 구현(최적화)
public static boolean equals(char[]s1, char[] s2){
// 길이가 일치하지않는 경우
if(s1.length != s2.length){ // 이 조건만 해도 엄청많은 데이터가 스킵
return false;
}
// 길이가 일치하는 경우
for(int i = 0; i < s1.length; i++){
if(s1[i] != s2[i]){
return false; // 가지치기
}
}
return true;
}이렇게 성능 개선을 할 수 있다
알고리즘 최종 코드
package algorithm.comon;
public class Q2D {
// 문자열의 사전 순 대소관계 비교를 위한 함수 compare(s1, s2)만들기
// s1이 s2보다 빠르면 음수, 동일하면 0, 느리다면 양수 반환
// 문자열의 일치여부 확인을 위한 equals(s1, s2)만들기
// 일치하면 true, 일치하지 않으면 false 반환
// 사전 순 대소관계 비교 함수
public static int compare(char[] s1, char[] s2) {
int n = Math.min(s1.length, s2.length);
for(int i = 0; i < n; i++) {
if(s1[i] != s2[i]) {
return (int)s1[i] - s2[i];
}
}
return s1.length - s2.length;
}
// 문자열 일치 함수
public static boolean equals(char[]s1, char[] s2){
// 길이가 일치하지않는 경우
if(s1.length != s2.length){ // 이 조건만 해도 엄청많은 데이터가 스킵
return false;
}
// 길이가 일치하는 경우
for(int i = 0; i < s1.length; i++){
if(s1[i] != s2[i]){
return false; // 가지치기
}
}
return true;
}
public static void main(String[] args) {
// toCharArray() = 문자열을 char배열로 변경하는 함수
char[] s1 = "algorithm".toCharArray();
char[] s2 = "allergy".toCharArray();
System.out.printf("compare() Result : %d\n", compare(s1,s2) );
System.out.printf("equals() Result : %b\n", equals(s1,s2) );
}
}
후기
이 글을 통해 문자열 비교 알고리즘에 대해 다들 이해하면 좋겠고
단순 구현이 아닌 최적화에 대해 고민하고 생각하는 모두가 되길 바랍니다
