데이터베이스
1.SQL 각종 연산자들
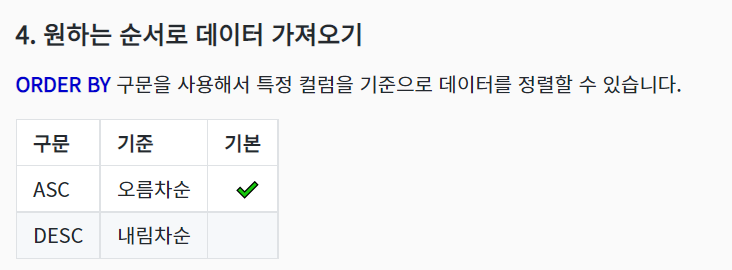
원하는 순서대로 가져오기 원하는 만큼만 데이터 가져오기 원하는 별명(alias)으로 데이터 가져오기 사칙연산(문자+숫자 = 0, 단! 문자가 숫자일때는 숫자로 인식) 
숫자 관련 함수들 그룹함수 
시간/날짜 관련 함수들 
WHERE은 그룹화 되기 전, HAVING은 그룹화 후 집계!
5.Lock
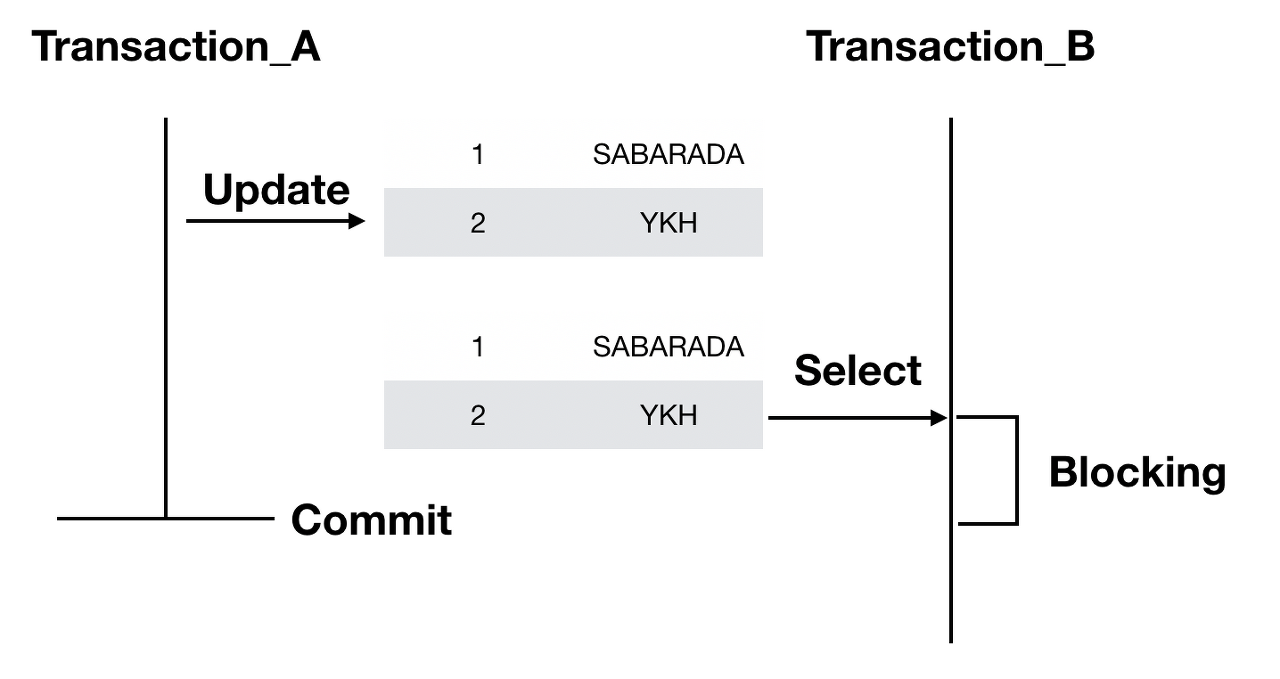
같은 자원(데이터)에 대해서 동시에 접근하는 경우가 생길 수 밖에 없다.이럴 경우 데이터가 오염 될 수 있는데그렇게 되지 않도록 데이터의 일관성과 무결성을 유지해야할 필요가 있다.Lock이란 트랜잭션 처리의 순차성을 보장하기 위한 방법. DBMS마다 Lock을 구현하는
6.인덱스
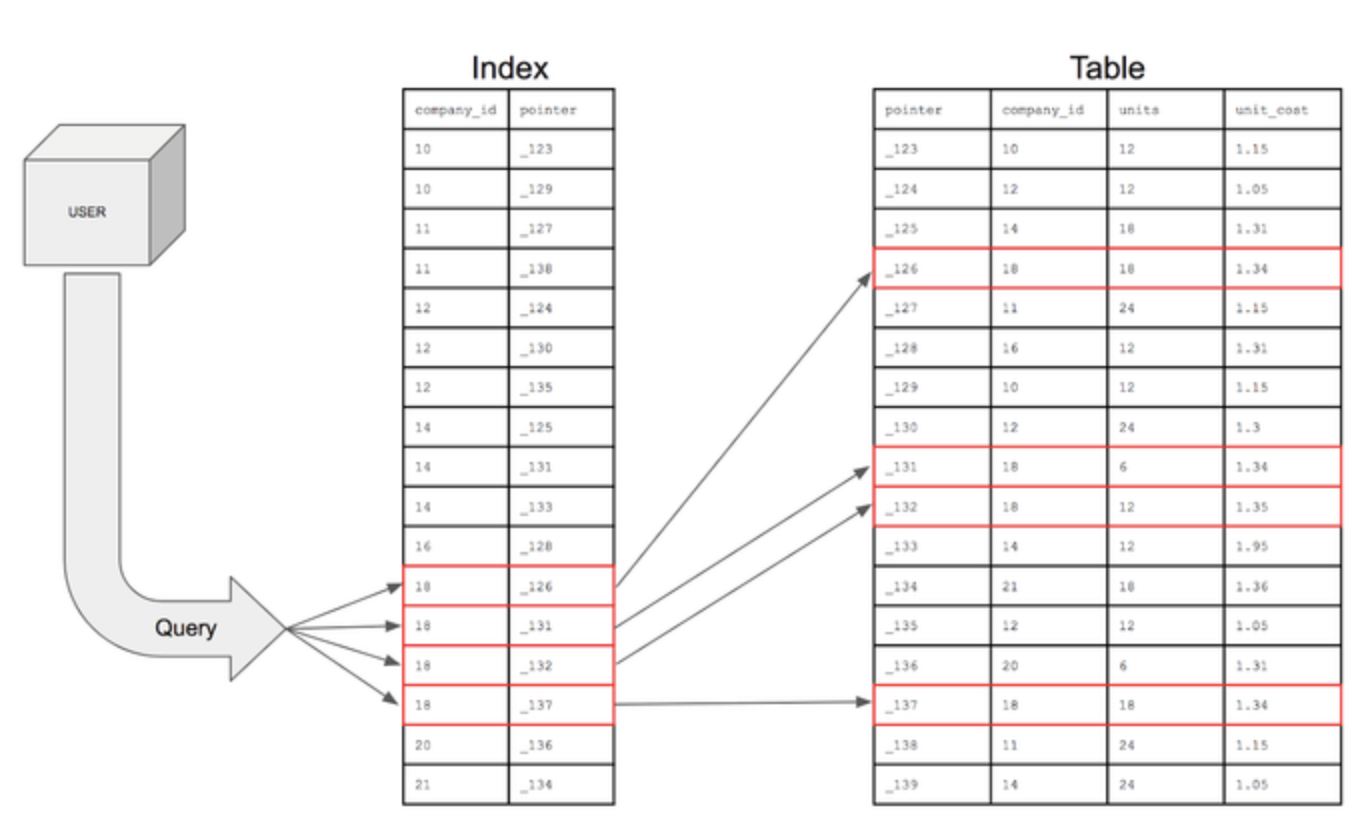
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조. 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장인덱스 생성 컬럼을 Where 조건으로
7.Clustered Index VS Non-Clustered Index
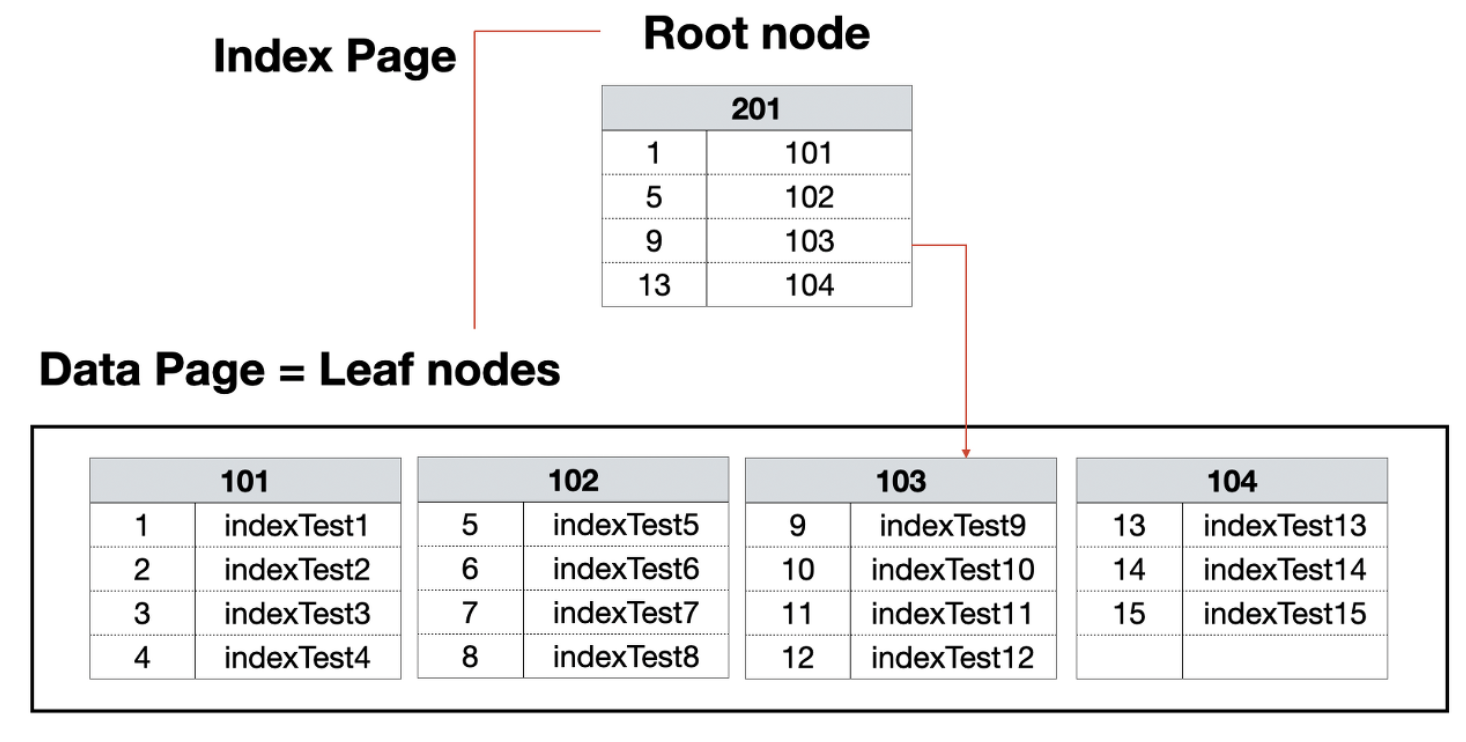
테이블당 1개씩만 허용된다.물리적으로 행을 재배열한다.PK설정 시 그 칼럼은 자동으로 클러스터드 인덱스가 만들어진다.인덱스 자체의 리프 페이지가 곧 데이터이다. 즉 테이블 자체가 인덱스이다. (따로 인덱스 페이지를 만들지 않는다.)데이터 입력, 수정, 삭제 시 항상 정
8.트랜잭션의 격리수준
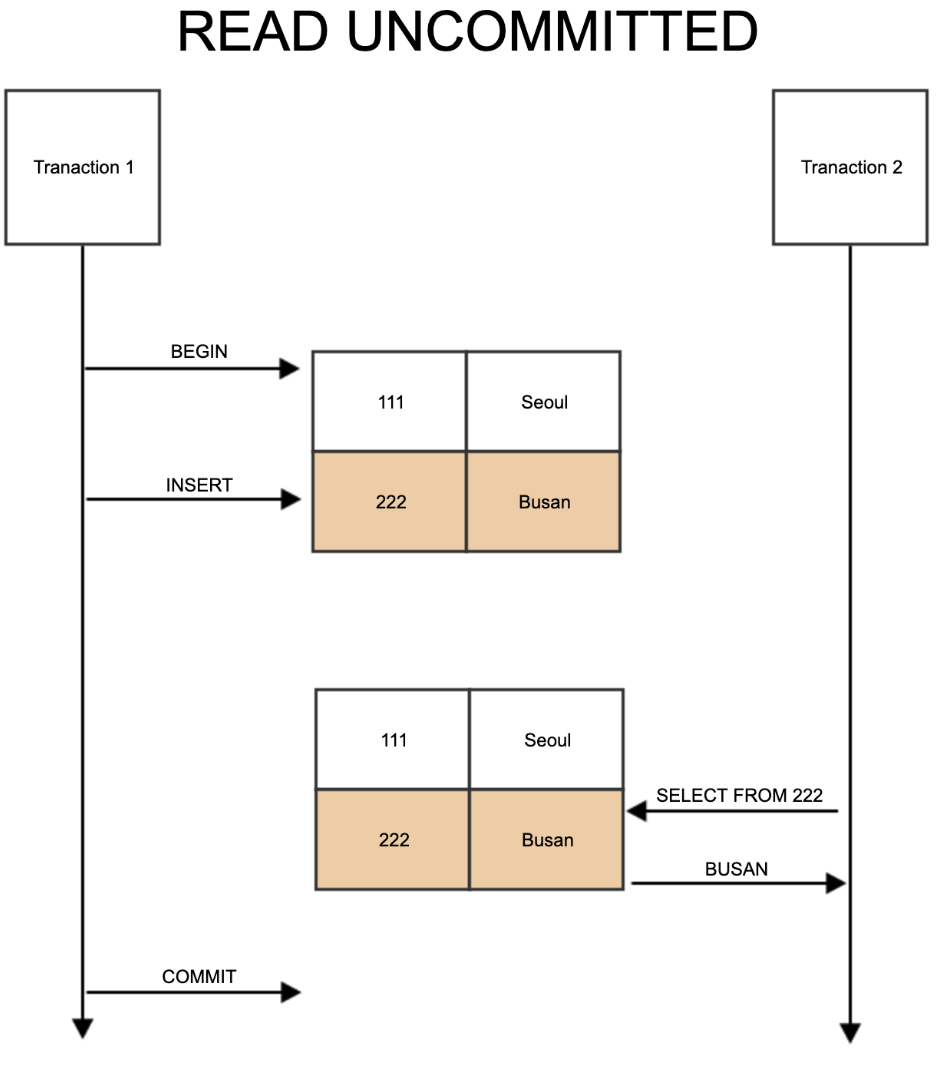
트랜잭션간에 격리성을 완벽히 보장하려면 동시에 처리되는 트랜잭션을 거의 차례대로 실행 해야 함. 하지만 이렇게 처리를 하면 처리 성능이 매우 나빠지게 된다. 이러한 문제로 인해 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의.트랜잭션 수준 읽기 일관성을 지