선형회귀와 비선형을 여러 층으로 깊게(Deep) 쌓는 기계 학습
Deep Neural Networks 구성 방법
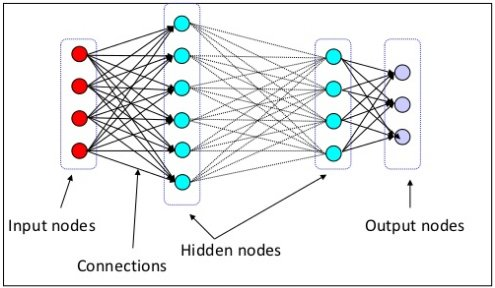
- Input layer(입력층): 네트워크의 입력 부분. 학습시키고 싶은 x 값
- Output layer(출력층): 네트워크의 출력 부분. 우리가 예측한 y 값
- Hidden layers(은닉층): 입력층과 출력층을 제외한 중간층

- 네트워크의 너비를 늘리는 방법 ☝ 네트워크의 은닉층의 개수를 그대로 두고 은닉층의 노드 개수를 늘리는 방법 예를 들어 너비를 베이스라인 모델의 2배로 늘리는 실험을 하겠다고 하면 네트워크는 아래와 같이 변경된다
- 입력층: 4
- 첫 번째 은닉층: 8 * 2 = 16
- 두 번째 은닉층: 4 * 2 = 8
- 출력층: 1
- 네트워크의 깊이를 늘리는 방법
- 입력층: 4
- 첫 번째 은닉층: 4
- 두 번째 은닉층: 8
- 세 번째 은닉층: 8
- 네 번째 은닉층: 4
- 출력층: 1
-
너비와 깊이를 전부 늘리는 방법
☝ 위에서 했던 두 가지의 방법을 모두 사용한다- 입력층: 4
- 첫 번째 은닉층: 8
- 두 번째 은닉층: 16
- 세 번째 은닉층: 16
- 네 번째 은닉층: 8
- 출력층: 1
딥러닝의 주요 개념
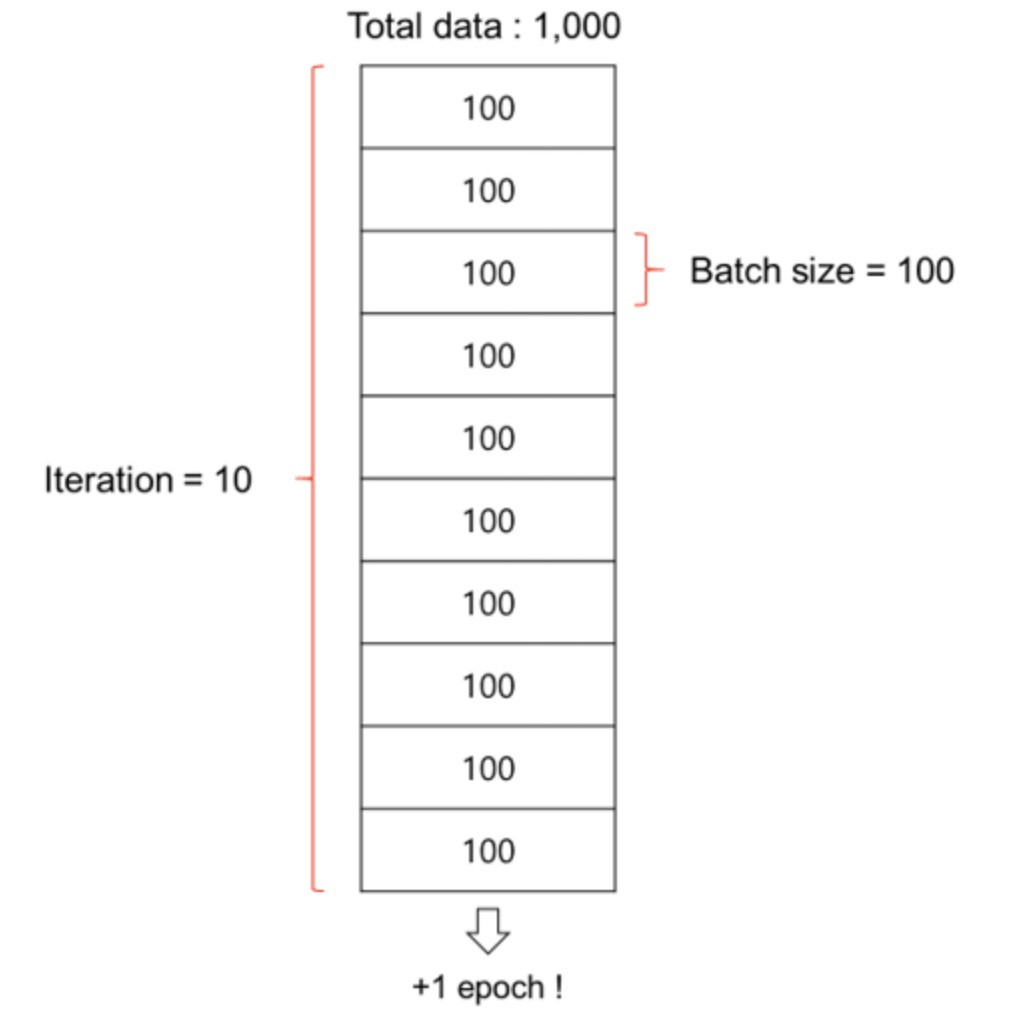
Batch size, Epoch (배치 사이즈, 에폭)
배치(Batch): 데이터셋을 작은 단위로 쪼개서 학습을 시키는데 쪼개는 단위
Iteration(이터레이션): n만 개의 데이터셋을 n개 씩으로 쪼개어 n번을 반복하는 과정
epochs(에폭): 반복 학습 수
-> batch를 몇 개로 나눠놓았냐에 상관 없이 전체 데이터셋을 한 번 돌 때 한 epoch이 끝난다
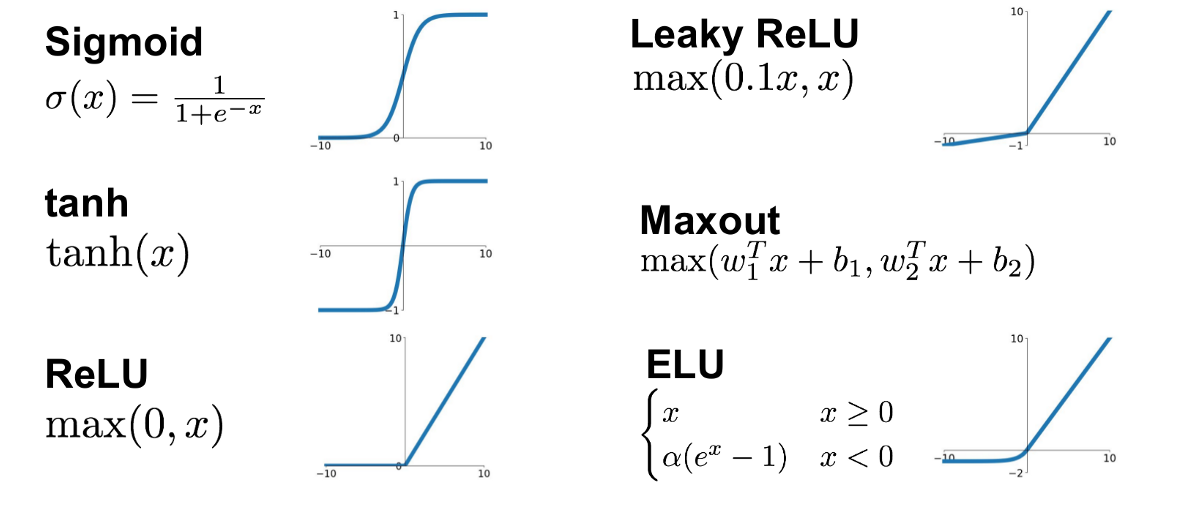
Activation functions (활성화 함수)
활성화 함수: 전기 신호의 임계치를 넘어야 다음 뉴런이 활성화 되는 함수 -> 비선형 함수여야 한다
딥러닝에서 가장 많이 보편적으로 쓰이는 활성화함수는 ReLU(렐루)는 다른 활성화 함수에 비해 학습이 빠르고 연산 비용이 적고 구현이 간단하다.
Overfitting, Underfitting (과적합, 과소적합)
딥러닝 모델을 설계/튜징하고 학습 시킬 때 Training loss는 점점 낮아지는데 Validation loss는 높아지는 시점이 나타나는 현상을 과적합 현상이라고 한다.
-> 풀어야하는 문제의 난이도에 비해 모델의 복잡도(Complexity)가 클 경우 가장 많이 발생하는 현상. 반대로 풀어야하는 문제의 난이도에 비해 모델의 복잡도가 낮을 경우 문제를 제대로 풀지 못하는 현상을 과소적합이라고 한다

과적합을 해결하는 방법에는 여러가지 방법이 있지만 대표적인 방법으로는 데이터를 더 모으기, Data augmenation, Dropout 등이 있다
딥러닝의 주요 스킬
Data augmentation (데이터 증강기법)
과적합을 해결할 가장 좋은 방법은 데이터의 개수를 늘리는 방법이다. 하지만 실무에서는 데이터가 넘쳐나기는 커녕 부족한 경우가 매우 많다. 데이터 증강기법은 부족한 데이터를 보충하기 위해 사용되는 방법이다. 이미지 처리 분야의 딥러닝에서 주로 사용한다

원본 이미지 한 장을 여러가지 방법으로 복사를 한다
사람의 눈으로 보았을 때 위의 어떤 사진을 보아도 사자인 것처럼 딥러닝 모델도 똑같이 보도록 학습시킨다
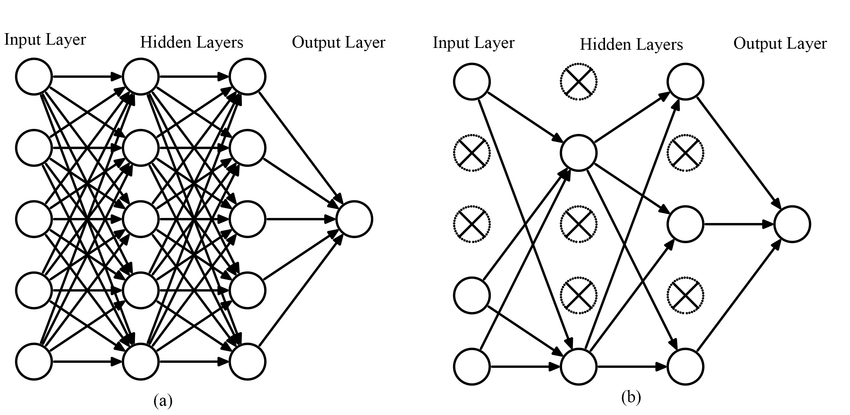
Dropout (드랍아웃)
과적합을 해결할 수 있는 가장 간단한 방법이다
각 노드들이 이어진 선을 빼서 없애버린다
Ensemble (앙상블)
여러개의 딥러닝 모델을 만들어 각각 학습시킨 후 각각의 모델에서 나온 출력을 기반으로 투표를 하는 방법. 랜덤 포레스트의 기법과 비슷하다
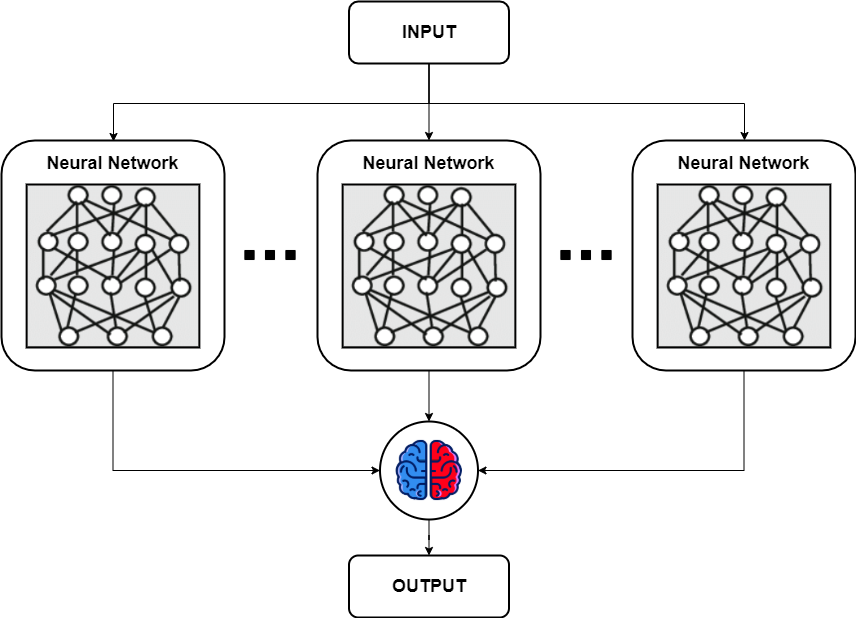
여러개의 모델에서 나온 출력에서 다수결로 투표(Majority voting)를 하는 방법도 있고, 평균값을 구하는 방법도 있고, 마지막에 결정하는 레이어를 붙이는 경우 등 다양한 방법으로 응용 가능하다
앙상블을 사용할 경우 최소 2% 이상의 성능 향상 효과를 볼 수 있다
Learning rate decay (Learning rate schedules)
Local minimum에 빠르게 도달하고 싶을 때 사용한다
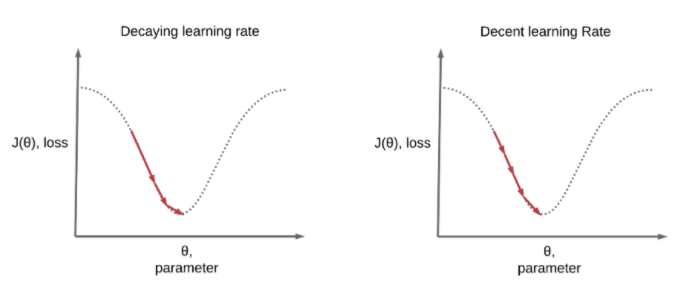
왼쪽 그림은 학습의 앞부분에서는 큰 폭으로 건너뛰고 뒷부분으로 갈 수록 점점 조금씩 움직여서 효율적으로 Local minimum을 찾는 모습이고, 오른쪽 그림은 Learning rate를 고정시켰을 때의 모습이다
Learning rate decay 기법을 사용하면 아래 그림처럼 Local minimum을 효과적으로 찾을 수 있다
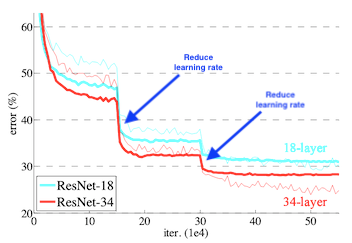
Keras에서는 f.keras.callbacks.LearningRateScheduler()와 f.keras.callbacks.ReduceLROnPlateau()를 사용하여 학습중 Learning rate를 조절한다
