객체지향 기술의 발전
- 기술 트랜드 :
OOP > 컴포넌트(Component) > "분산"컴포넌트(스프링) 서비스기반 아키텍쳐 (SOA : Service Oriented Architecture) > 마이크로 서비스 아키텍쳐 (MSA : Micro-Service Architecture) > 스프링 MSA - OOP > MVC (Model/View/Controller) 아키텍쳐 > DI(Dependency Injection)
객체지향
- 전체코드가 클래스 하나인 경우? > 객체지향이 맞을까? 맞다!
- 디자인패턴(경험, 베스트 프랙티스 Best Practice-최선책)
- MVC (Model/View/Controller)패턴. 3개의 클래스로 분리하자.
데이터는 Model, 화면은 View, 조율을 Controller- 모바일/PC 동시 대응할 수 있다는 장점.
View에는 로직이 최소화되어야하지만, 로직이 들어가게 됨. - MVVM(Model-View-ViewModel) 이 나오게 됨.
- 모바일/PC 동시 대응할 수 있다는 장점.
- DI(Dependency Injection) 패턴
- 전략(Strategy) 패턴
- 인터페이스 패턴
- MVC (Model/View/Controller)패턴. 3개의 클래스로 분리하자.
POJO(Plain Old Java Object)
- 자바 객체지향의 특징 및 정신을 요약
- 클래스/인터페이스로 구현할 수 있는 방법을 모두 제공.
- 클래스 아닌 인터페이스를 사용을 선호.
- 특정한 기술/규약에 의존 배격
- 클래스/인터페이스로 구현할 수 있는 방법을 모두 제공.
스프링은 유사종교(?)
- 유교/유학
- 공자
- 유(선비)
- 유교는 예법/제사다
- 맹자
- 역성혁명 / 제왕학
- 왕이 부덕하면 바꿔야한다.
- 수신제가치국평천하
- 주자
- 성리학
- "성(사람의 본성)" 과 "리(이치)"
- 우주론(태극, 주역 등등..)
객체지향 흐름
- 상속/캡슐화
- POJO(궁극적인 객체지향)
- 특정 클래스를 상속받아야 함(X. 이거 아님)
- 자바는 단일상속이라 제약이 발생한다.
- Thread 생성 > Thread 클래스 상속/Runnable 인터페이스 상속
- 객체 지향적인 원리에 충실하면서 환경과 기술에 종속되지 않고 필요에 따라 재활용될 수 있는 방식으로 설계된 오브젝트를 말한다. 그러한 POJO에 애플리케이션의 핵심로직과 기능을 담아 설계하고 개발하는 방법을 POJO 프로그래밍이라고 할 수 있다.
- 특정 클래스를 상속받아야 함(X. 이거 아님)
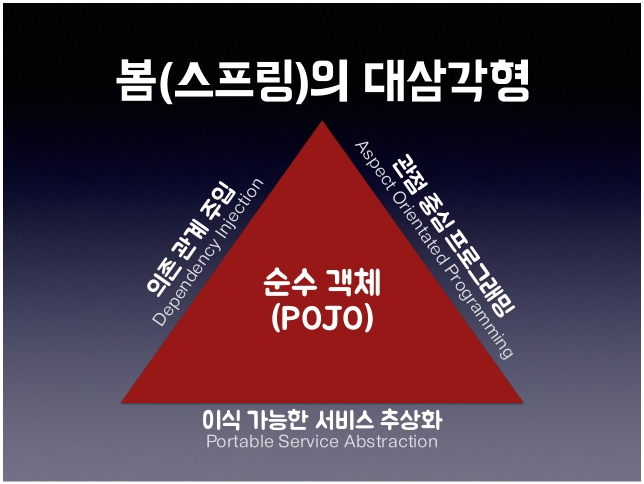
- 스프링 삼각형
- POJO = DO + AOP + PSA
객체지향 분석설계(OOAD)
- 객체지향(OO) 기술 = OOA+OOD+OOP
- 객체지향 분석설계(디자인)의 5원칙 (SOLID)
- SRP(Single Responsibility Principle) : 단일책임 원칙
클래스 하나 당 기능 하나. 메서드 하나에 기능 하나. 코드 안에 하나의 기능만 넣자. 심플하게 짜자. - OCP(Open-Close Principle) : 개방-폐쇄 원칙
기능추가에는 열려있고, 수정에는 닫혀있다.
기능추가가 쉬운 구조로, 조금의 수정으로 코드에 반영되게 설계되어야한다. - LRP
- ISP
- DIP
- SRP(Single Responsibility Principle) : 단일책임 원칙
- DO + AOP + PSA를 지키면 SOLID원칙에 맞게 코드를 구성했다 볼 수 있다.
DI스러운 코드 > OCP를 지켰다.
객체지향기술의 심화 (POJO)
- 클래스/인터페이스로 구현할 수 있는 방법을 모두 제공
- 클래스 아닌 인터페이스 사용을 선호
- POJO의 열렬한 지지자
- Spring Framework / MyBatis ...
Interface vs Abstract class
- 사이비
- 엄밀히는 다르지만, 실제로는 비슷한 것.
- 템플릿 메소드 패턴(추상클래스) vs 전략패턴(인터페이스)
- 자바의 단일상속을 고려하면 인터페이스를 사용하는 것을 선호
- 인터페이스를 사용하는 전략패턴(DI)가 주류이다.
제어의 역전(IoC)
- Inversion of Control
- 프레임워크/WAS/미들웨어 등이 주로 사용.
- 제어의 권한을 넘기고 필요한 기능(메소드/함수)만 구현하는 형태
- 프레임워크는 정해진 (콜백)메소드를 호출하면 사용자의 코드가 호출되는 구조.
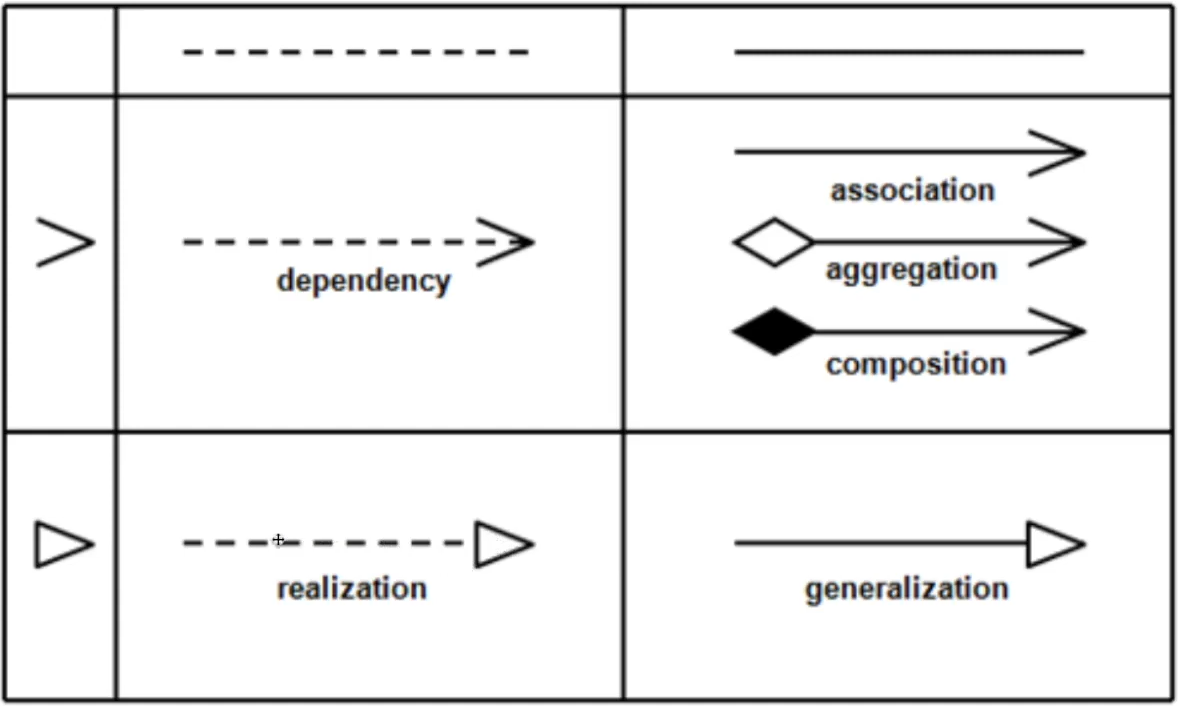
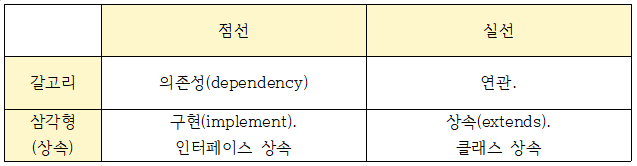
UML 기본
- 삼각형인지 갈고리인지, 실선인지 점선인지
의존성 주입(DI)
- Dependency Injection
- 디자인패턴의 전략패턴(Strategy Pattern)
- 필요한 의존성 오브젝트를 정해진 시점에 공급.
- 의존성이 없는 (최소화한) 프로그래밍을 작성하라.
- 프로그램 실행단계에서 결정.
- DI를 왜 쓰는가? 여러 환경에서 적용할 수 있게 하기 위해서.
설계할 때는 어떤 환경에서도 실행할 수 있는 코드를 짜고, 실행하는 순간 의존성이 생겨야한다.
의존성(Dependency)이란
- 어떤 프로그램이나 서비스가 수행되기 위해 필요한 것.
- 보통 리소스(자원)에 의존.
- 의존성의 종류
- 대부분 "사용(USE)"
- 의존성에 방향이 있다.
- 전체는 부분에 의존한다.
- 큰게 작은것에 의존.
- 예시) 프로그램에서 DBMS로 오라클을 사용한다. > 프로그램은 오라클에 의존한다.
객체지향기술의 심화 - 의존성 주입(IoC/DI)
- 인터페이스에만 의존
- 코드를 의존성이 없는 방식으로 구현.
- 오라클에서도, MySQL에서도 작동되는 프로그램을 만들자.
- 인터페이스를 구현한 오브젝트를 계속 만들 수 있음.
- 코드의 기능추가가 매우 쉬운 구조.
- SOLID의 OCP(개방-폐쇄) 원칙 준수
- 확장에는 열려있고(OPEN) 수정에는 닫혀(CLOSE) 있어야 한다.
- SOLID의 OCP(개방-폐쇄) 원칙 준수
- 코드를 의존성이 없는 방식으로 구현.
- 어떤 오브젝트를 생성할 때 필요한 구체적인 오브젝트를 지정하는 형태
- 주로 생성자를 사용해서 주입.
- setter/일반 메서드를 사용하는 경우도 있음.
인터페이스를 선호하는 이유 (= 상속의 문제점)
- 클래스를 상속받았는데, 재활용 되지 않는 코드가 있다면,
- 전체를 다 상속받았는데, 사용 안되는 코드가 있다. > 군살같다.
- 다중 상속은 활용되지 않는 코드가 늘어날 가능성이 높음.
- 그러니까 단일상속만 허용하자.
- 인터페이스는 코드가 없기 때문에 상속받아도 오버헤드(군살)이 없다. > 인터페이스는 오버헤드없는 상속이 가능.
- 코드의 통일성 유지 및 기능추가에 유연한 구조.
- 코드 재활용보다는 유연한 기능추가에 방점을 주자.
- DI가 유행이 됨 > 모든 코드를 DI로 만들어버리자!
- PSA : POJO, DI가 적용이 안된 코드도 껍데기는 DI스럽게 만들자.
- JUnit : 내부적으로는 JUnit이지만, 껍데기는 인터페이스.
껍데기는 DI지만 내부는 아님.
Spring에서 DB를 연결하려면 JDBC, Spring JDBC로 포장이 되어 있어야 함.
모양 자체가 이상해짐. - POJO화는 DI가 큰 역할을 하고 있음. AOP나 DI가 적용되지 않는 것은 PSA로 포장해서 DI스럽게 보이자. >> 이것이 스프링 삼각형.
스프링 삼각형
DI(의존성 주입) 방법
- 어떠한 의존오브젝트가 들어오더라도 동작할 수 있도록 하는, 일반화 프로그래밍
- 생성자를 통한 주입
- 기본. 주로 어노테이션을 사용하여 간단히 만듬.
- setter를 통한 주입
- xml을 통한 DI
- 전용 메서드를 통한 주입
- 여러 개를 주입해야 하는 경우 전용 메서드 지정.
WAS에서 제공되는 기능
- 상용서비스를 운영하게 된다면, 서버를 하나로 할 수 없다. 서버나 DB가 죽더라도 서비스는 유지되어야 하기 때문.
- DB가 죽어버리면 어떡하지? 서버 증설해야하는 경우라면? > 카피본을 만들어서 예비를 만들어둔다. (이중화)
- DB에서 트랜잭션을 한다고 해도 DB가 트랜잭션을 보장하는 것은 완벽한가? > DB도 죽을 수 있기 때문에 완벽하지 않다.
- DB외부에 별도의 시스템이 있어서(WAS, Middleware 등), 문제가 생기면 롤백을 시키거나 우회를 시키는 등의 역할을 하는 서버/시스템이 필요함.
- WAS가 들어가면 최소 3-tier. WAS가 글로벌 트랜잭션을 수행해줌. T-max의 제우스 등이 있다.
- 트랜잭션 처리
- DBMS가 아닌 외부에서 트랜잭션 처리 보장
- 로컬(일반) 트랜잭션 vs 글로벌(분산) 트랜잭션
글로벌 트랜잭션: 서버 외부에서 여러 DB서버간의 트랜잭션을 처리해야되는 것- 2PC(Phase Commit) 프로토콜 - XA 프로토콜
2PC프로토콜 : 두개의 DB사이에 커밋을 두 단계로 둠. 두 단계 commit 프로토콜.
XA 프로토콜 : 위의 것을 구현.
- 2PC(Phase Commit) 프로토콜 - XA 프로토콜
- 로드밸런싱(L7 / L4 switch)
- 로드밸런서 : 클라이언트가 생겼을 때 어느 서버로 배치해주는지 결정. (ex 은행 번호표.)
- 동일한 여러 대의 서버로 분산처리
- 다이나믹 vs 스태틱
- 스태틱 - 모든 서버에 일을 공평하게 나눠줌.
- 다이나믹 - 일이 몰린 서버에 일을 빼주거나, 적은 서버에 일을 더 줌. 대기열이 긴 서버에는 일을 적게주고, 짧은 쪽에 집중해서 배당해줌.
- 고가용성
- 일부 서버에서 장애가 발생하더라도 전체 서비스 유지
- 장애가 나더라도(서버, DB따위 등이 죽거나 하는 일로) 전체 서비스는 잘 운영되게 하는 것.
- (오토)스케일링
- 트래픽에 대응해 서버를 늘리거나 줄이는 기술
- 로그 취합
- 여러 대의 서버에서 발생한 로그를 취합, 관리하는 기술.
- 카프카 : 로그취합 가능.
AOP(Aspect Oriented Programming)
- 관점지향 프로그래밍
- 비즈니스로직에
- 코드 + 로그, 트랜잭션 ...
- 복잡성 증가
- 메인 코드에는 로직코드만 있고
- 나머지 기능은 메서드 이름에 따라 부여
- 예)txWrite() > tx라는 단어가 있으면 트랜잭션 처리를 하도록 부여
- 바이트코드 위빙(weaving)
- 소스코드, 컴파일 시점, 바이트코드 로 변환된 시점
- 클래스 로드 시, 런타임(실행중)
- SpringAOP vs AspectJ
PSA(Portable Service Abstraction)
- DI로 안된 프로그램을 DI 포장을 입히는 작업
- ex. JUnit, JavaMail, JDBC 등의 코드를 DI화해서 제공.
- JUnit vs SpringJUnit
- 일반적인 JUnit코드와 스프링 기반의 JUnit이 다름.
- JDBC도 마찬가지. 일반적인 JDBC와 스프링 JDBC는 다르다.
스프링 프레임워크
- 분산컴포넌트 기반의 백엔드용(비즈니스 로직) 프레임워크
- 주로 WAS(Web Application Server)와 같이 운용
- 3-tier / N-tier 환경에서 주로 운용
- IoC/DI 기반
- 스프링은
VMWare이라는 회사에서 만들고 있다. - VMWare은 Dell의 스토리지서버 자회사인 EMC의 사업부문(자회사 될수도)
- 서버(DELL), 스토리지서버(EMC), 가상화/스프링 프레임워크(VMWare)
WAS/미들웨어
3계층 구조(3-tier)
- 표현계층
- 주로 웹/모바일
- 비즈니스 로직 계층
- 실제 작업처리를 담당
- 비즈니스 오브젝트(데이터)계층
- DBMS와의 연결 담당
- ORM
- JPA(Hibernate)
- SQLMapper(MyBatis)
tier (1 참조)
- WAS는 최소 3티어부터 시작된다.
- 트랜잭션/로드배런싱, 장애대응, 로그취합 등등은 3티어부터 가능성이 생긴다.
비즈니스 로직
- 업무논리(로직)을 코딩하는 부분
- 비즈니스 로직을 구현/운영할 때 필요한 많은 추가 기능 필요
- 트랜잭션 처리(로컬/글로벌), 로드밸런싱, 고가용성(장애대응), 스케일링, 로그취합 등
- WAS(예전에는 Middleware)와 같이 운용
- 높은 신뢰성이 필요함
- 높은 SW비용(수천만~수억원 대)
- 저렴한 WAS vs 비싼 WAS
- BEA Weblogic, Tmax JEUS, tcServer, IBM WebSphere
네트워크 프로그래밍과 RPC + 분산컴포넌트
네트워크(소켓) 프로그래밍
- TCP/UDP/IP
- High-lever vs Mid-level vs Low-level
- Stream vs Buffer vs Packet/Segment
- Blocking / Non-Blocking / Asynchronous
- 컴퓨터 Big3 - OS, Network, DB (AI)
RPC / RMI
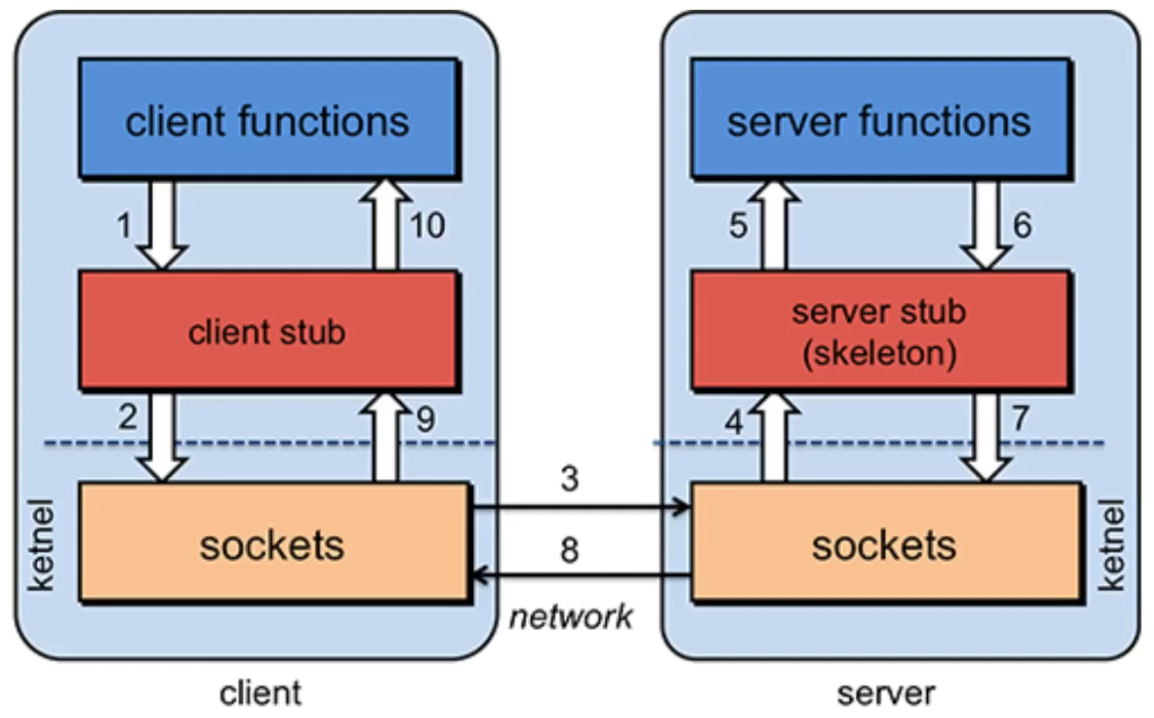
- 단점 : 속도가 떨어진다.
- Remote Procedure Call / Remote Method Invocation
- 네트워크 프로그램을 함수(메서드) 호출하는 방식으로 만들어 줌.
- 서버 /클라이언트에 일종의 프록시(Proxy)가 필요
- 스텁(Stub)/스켈리톤(Skeleton)
- 인자와 리턴값을 시스템에 맞게 조정해주어야 함.
- 마샬링/언마샬링(오리지날), 직렬화/역직결화(자바)
조정해주는 것 > 마샬링, 직렬화. 복원하는 것 > 언마샬링, 역직렬화
- 마샬링/언마샬링(오리지날), 직렬화/역직결화(자바)
- Sun(지금은 오라클에 인수)이 처음으로 제안
- Sun RPC / DCE RPC로 분화
- Java RMI는 Sun RPC 기반, MS DCOM은 DCE RPC기반
→ 자바는 자바대로, 윈도우는 윈도우대로 돌아간다는 의미.
윈도우 서버의 안드로이드(자바) 클라이언트는 어떻게 해야할까? 원격으로 RPC를 하고 싶지만, 그럴 수 없다. DCE와 Sun은 호환성이 없다. - 여러 시스템 간 연동을 위해서 xml/JSON을 사용.
- 자바직렬화 RPC vs xml RPC vs JSON RPC
xml은 느리니까 JSON으로 하자.
- 자바직렬화 RPC vs xml RPC vs JSON RPC
- 현재는 오버헤드를 더 줄인
gRPC(Google RPC)기반으로 성능 최적화- 텍스트 대신 바이너리로 RPC를 주고받음.
- HTTP/2 요구하고 프로토콜버퍼(ProtocolBuffer)라는 구글솔루션을 써야함. > 면접관이 좋아할 얘기.
디렉토리 서비스
- 여러대의 시스템에서 해당 컴포넌트 / 함수를 찾으려면 디렉토리 서비스를 통해 등록/검색
- 디렉토리 서비스(Directory Service) / 레지스트리(Registry)
- X.500 기반
- Novell Netware(IPX/SPX)
- Java JNDI(Java Naming & Directory Service)
- MS Active Directory
직렬화(Serialization) / 역직렬화(Deserialization)
마샬링/ 언마샬링
- 메모리 상의 자바 오브젝트를 네트워크나 디스크에 저장/전송하고 복원하는 개념.
자바 → JSON / JSON → 자바 - RMI를 기반으로 스프링 BEAN이 생성되어 돌아감.
- Persitence(지속성)의 요구조건
- 오브젝트의 필드를 스트림화(streamize)해서 저장(전송)
- ObjectInputStream / ObjectOutputStream
- writeObject() / readObject
리플렉션(Reflection)
- JVM 상에서
- 오브젝트 → 클래스/부모클래스 조회
- 클래스 → 오브젝트 생성
- 메서드 인자기반으로 호출
- 생성자 호출
- ...
Java BEANs(콩, 사람 머리)
- 조건
- 직렬화(Serializable) 가능
- 기본생성자가 있어야 함.
- 모든 프로퍼티(method/field)는 private해야 한다.
- 프로퍼티는 getter/setter가 있어야 함.
- persistent 해야 한다. -저장/복원이 가능해야 함.
스프링 빈(Spring Bean)
- 옵션이 붙은 자바 빈.
스프링 RMI
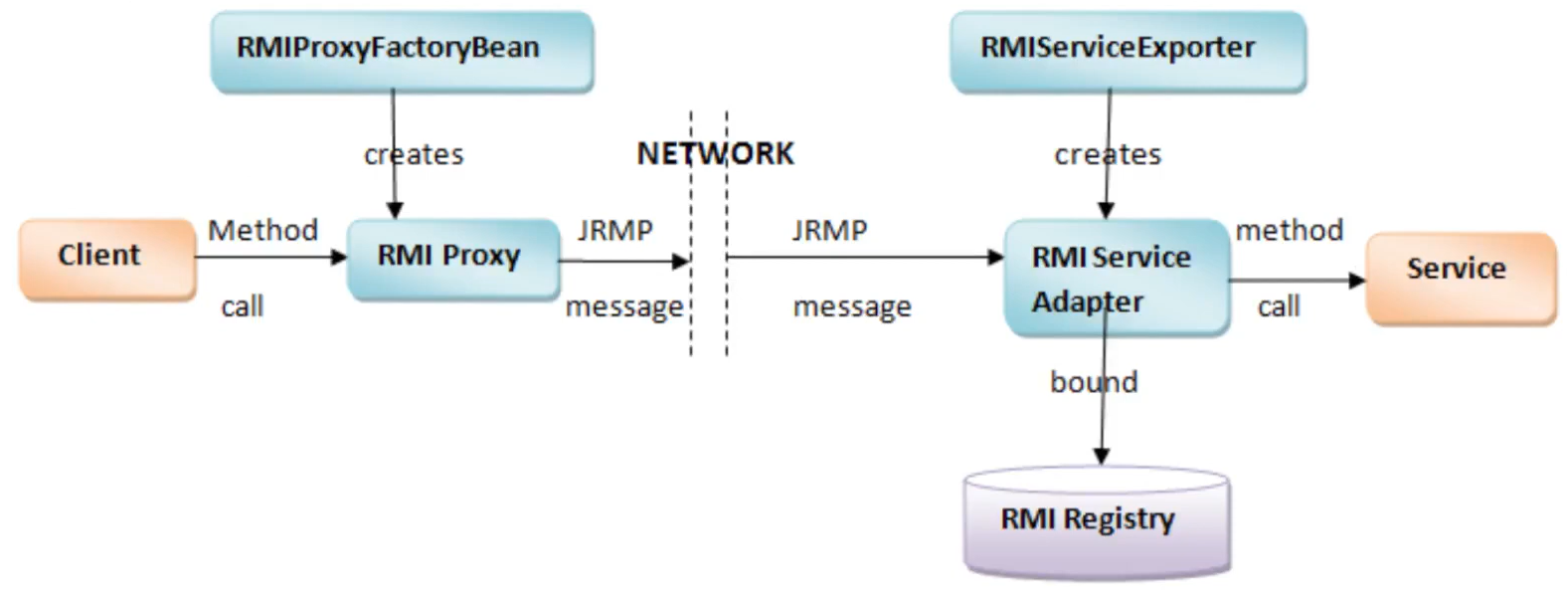
- 스프링은 스프링 빈을 만들어서 등록하고, 사용한다.
Apache Kafka
- LinkedIn에서 만든 고성능 분산메시징용 오픈소스
- MoM(Message-oriented Middleware)용
- cf. IBM MQ Series / JMS(Java Messaging Service)
- 안정적인 버퍼링(큐잉)/스트리밍용/Log Aggregation/헬스체크
- Producer / Consumer / Broker
- 트래픽이 과다되면 서버가 다운된다 → 서버를 증설하면 해결되는 문제긴 하지만, 서버 증설에는 자원이 소요된다. → 버퍼링, 큐잉 등을 도입해서 해소할 수 있다.
- 버퍼링의 장점 : 서버 스트레스를 줄여줌. 시스템 안정성이 높아진다.
단점 : 동시 최고 사용자를 제한함. - 큐잉 시스템의 최고 미덕은 서버 안정성을 높여서 서비스 다운을 막는 것.
서버 딜레이가 길어진다. - 이런 기술은
1) 큐잉, 버퍼링 등으로 서버에 과부화를 주지 않고 안정적으로 작동하게 하고,
2) 많은 write가 발생했을 때 안정적으로 작성할 수 있는 기술.
- 용도
- Messaging System
- Website Activity Checking/Monitoring
- Log Aggregation
- Stream Processing / Batch Processing
- Buffering
- Event sourcing(이벤트를 시간순으로 기록)
카프카 이전 → 이후
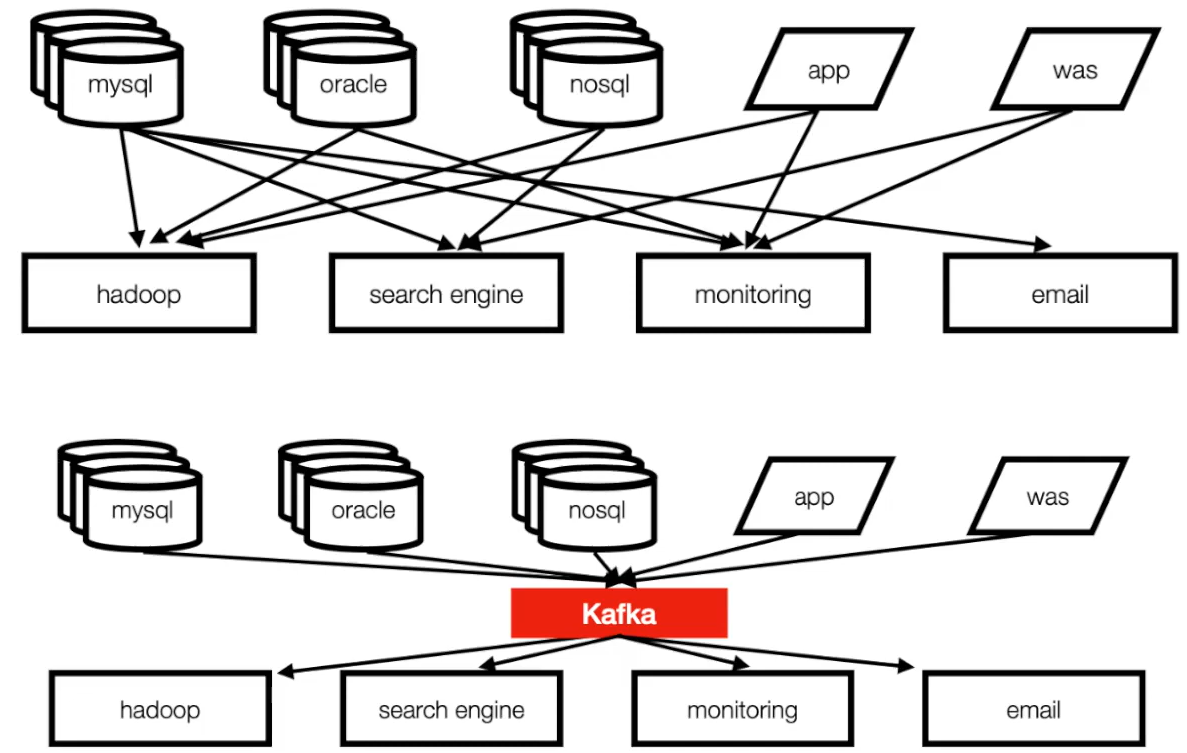
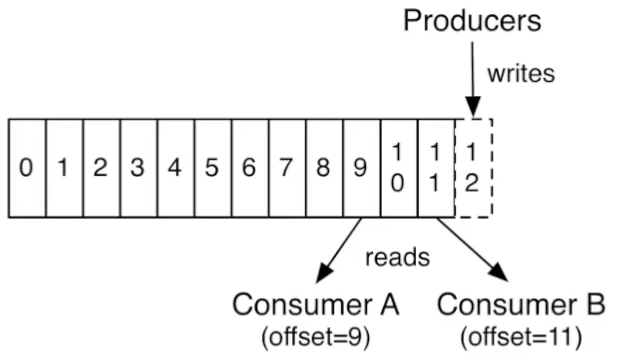
- 토픽(topic)을 기준으로 메시지 관리
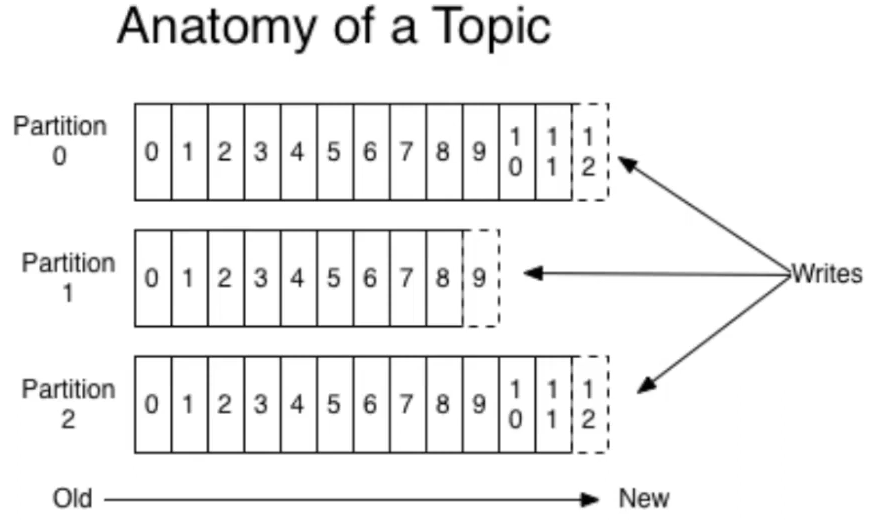
- 파티셔닝
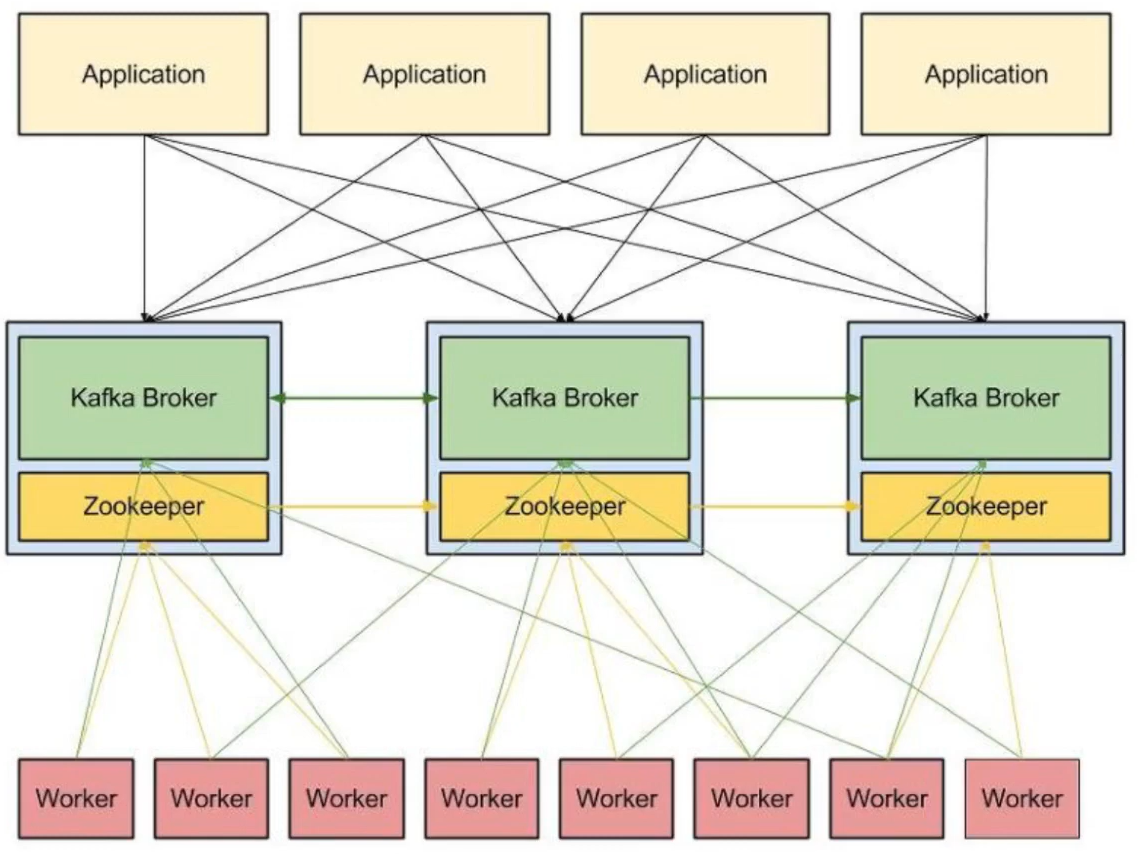
- topic들은 Broker가 보관하고, 브로커가 죽으면 안되기 때문에 Zookeeper이란 것이 지키고 있다.
Kafka의 특징
- Publisher/Subscriber 모델
- High Availability / Scalability
- Sequential Sore and Process in Disk
- 장애 대응
- I/O 최적화
- Distributed Processing
Kafka 아키텍쳐
- Pub/Sub 구조
- 브로커(Broker)
- 주키퍼(Zookeeper) : 브로커가 죽는 상황을 방지.
- 토픽(Topic)
- 파티션(Partition)
- 리더(Leader)/팔로워(Follower)
- 컨슈머 그룹(Consumer Group)
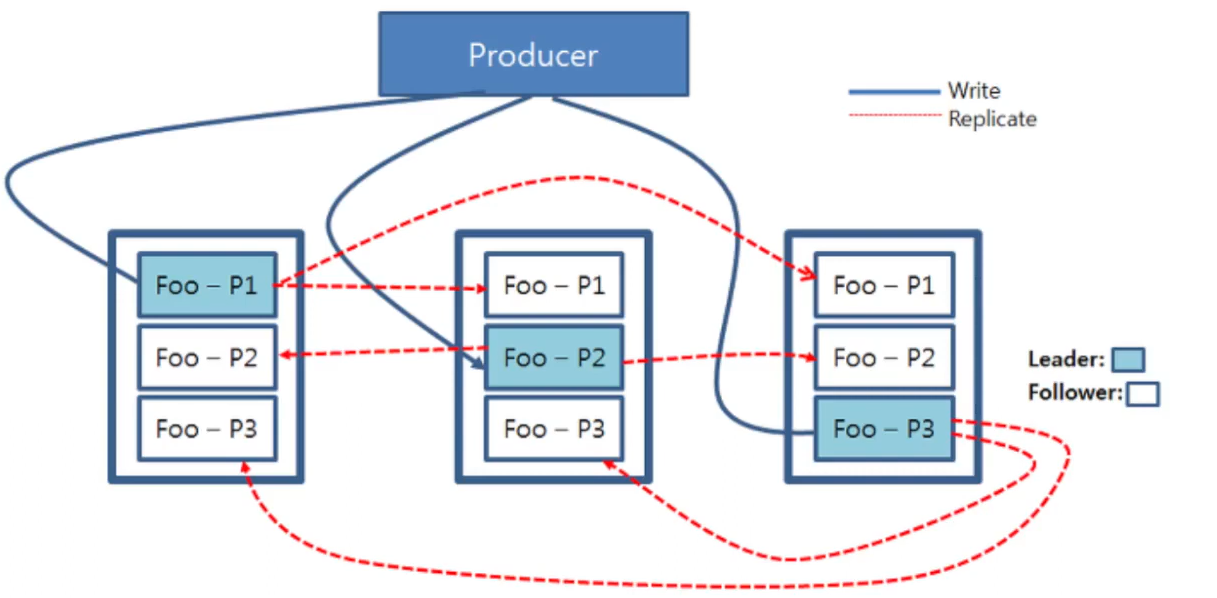
Kafka leader/follower
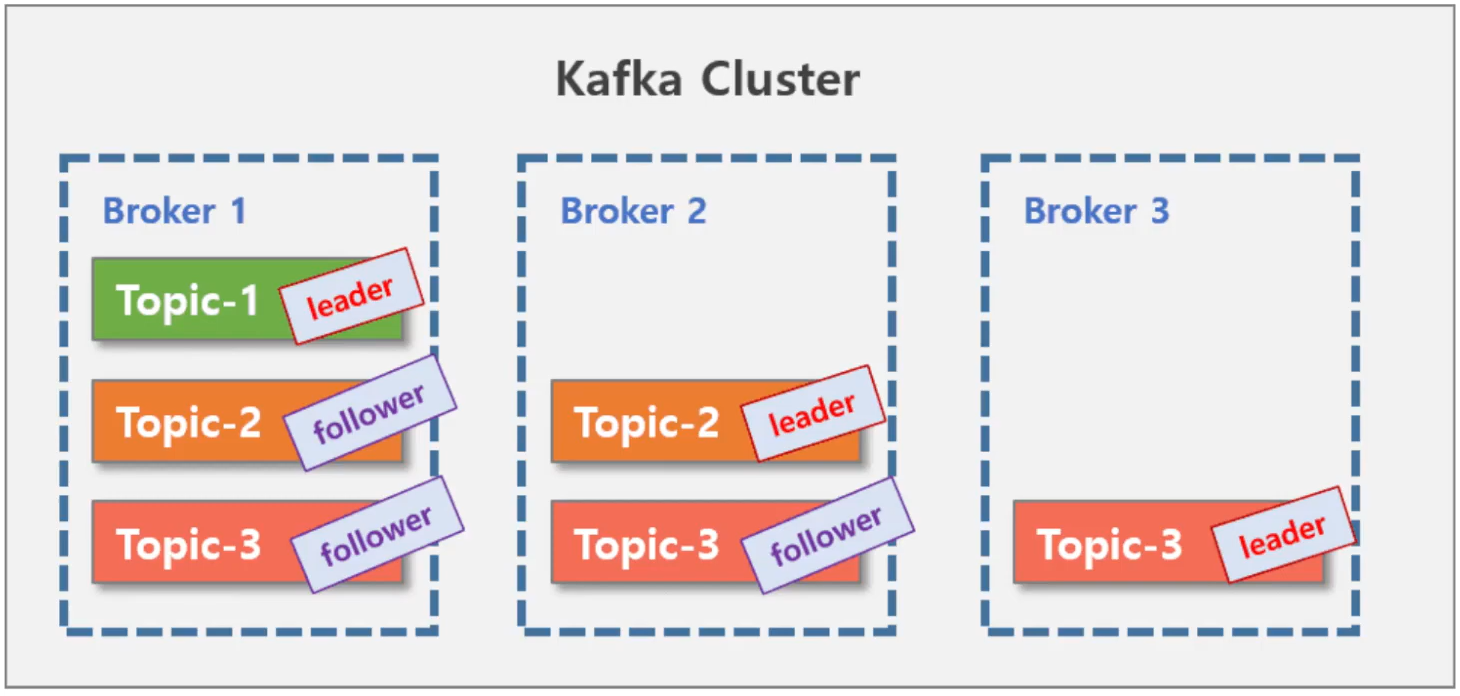
- Broker이 세개. 각 토픽이 들어가 있음.
- 토픽 리더를 입력하면 팔로워가 업데이트 됨.
- ack
- 0 : ack를 기다리지 않음. 빠르다.
- 1 : leader는 데이터를 기록.
- all(-1) : 모든 ISR확인. 느리고 손실가능성 없음.
- DBMS의 마스터-슬레이브 복제와 유사.
- 동기복제/반동기/비동기 복제와 유사
파티션과 컨슈머 그룹
- 컨슈머 하나가 파티션 하나에 대응한다.
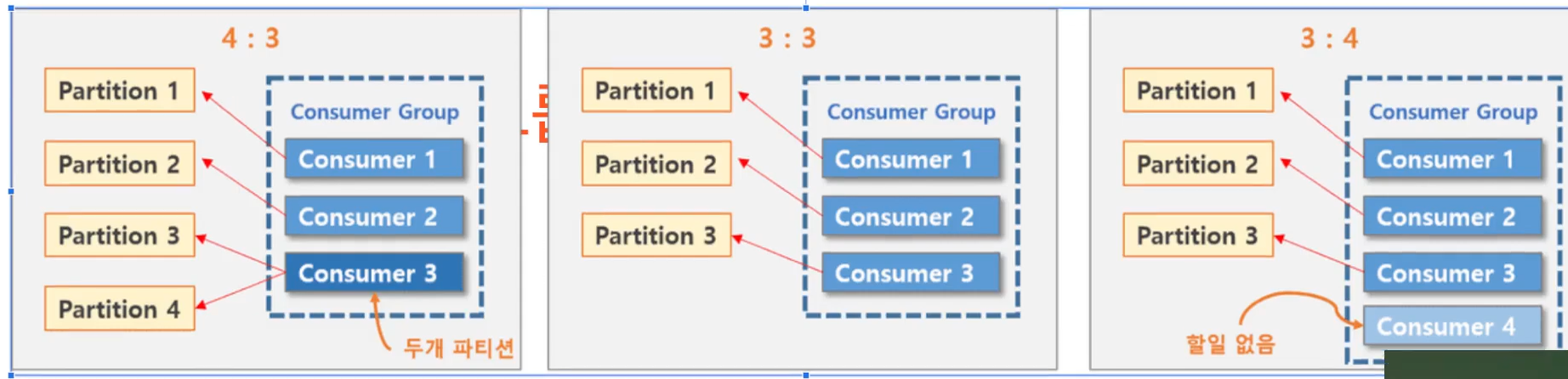
Kafka Broker 구성예
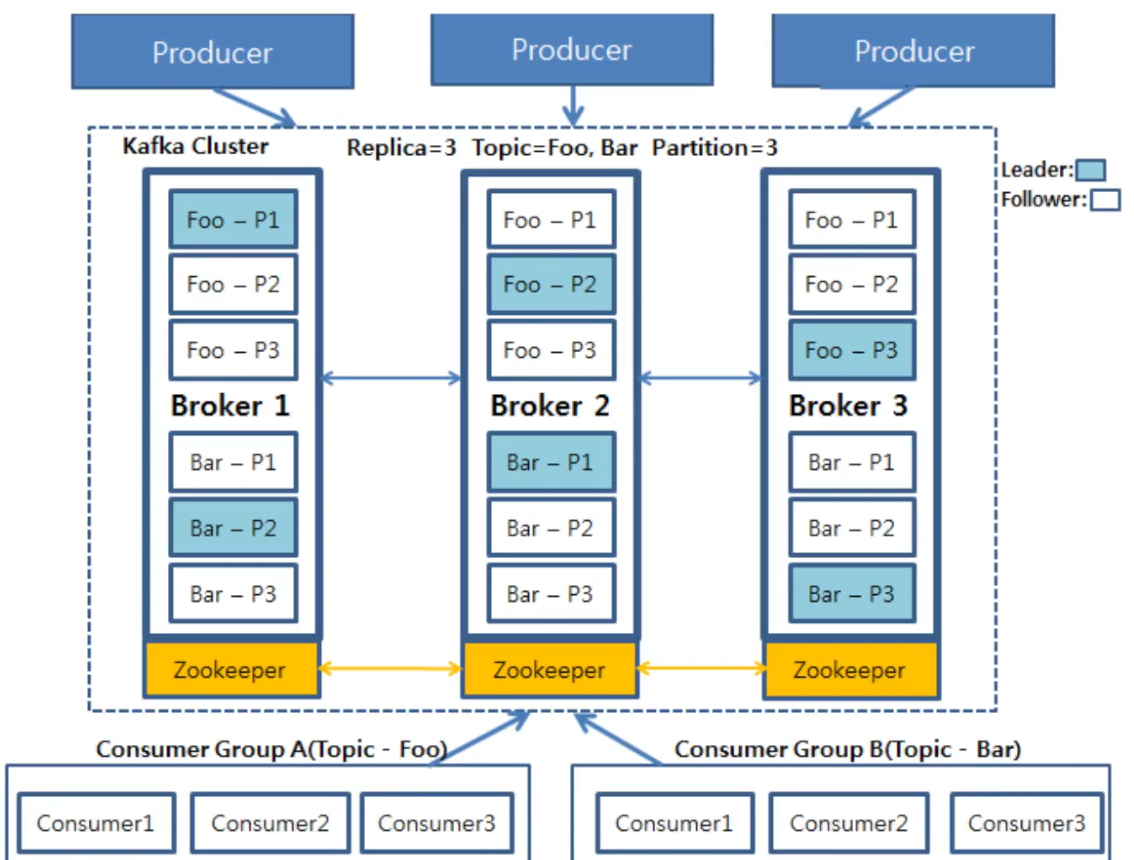
- 삼중화를 했으니, 2개가 고장나는 최악의 경우에도 사용 가능.
- write 파티션을 세개로 나눴으니 동시에 3개를 작성 가능.
Consumer Group
- Consumer들을 묶는 개념
- Consumer 수 만큼 파티션의 데이터 분산처리함(읽을 때의 단위)
- 파티션이 3개면 3개의 Consumer가 필요하다.
- 복제본에는 Leader를 선정(하늘색), 읽기 쓰기를 관장하는 구조.
카프카 성능 (vs RabbitMQ)
- 카프카가 성능이 좋다.
- 제로 카피(Zero Copy)
- 큐의 복사가 실제 일어나지 않고, 주소의 복사만 일어나게 된다.
- 많은 수의 큐/버퍼를 관리해야하는 상황에서 큰 성능차가 발생.
- 큐 (mbuf:BSD)를 복사하지 않고 포인터를 넘기면 성능이 향상된다. (3번→0번)
실제 메모리 카피를 하지 않는다. - 리눅스/BSD 네트워크 커널
- Encapsulation
- OSI 7계층 (응용→물리)
- Encapsulation
Apache zookeeper
- 카프카는 주키퍼가 필수.
- 브로커가 죽으면 모든 프로그램이 죽음. 그리고 이 주키퍼는 브로커가 죽지 않도록 방지한다.
- 고가용성 기술 : 일부 서버가 죽어도 서비스를 계속 사용할 수 있게하는 기술.
같은 브로커가 최소 두개 이상은 있어야 고가용성을 유지할 수 있다.
- Master / Slaves
- 하나의 마스터와 여러 개의 슬레이브 구성
마스터가 죽어도 슬레이브로 연결해서 서비스 유지. - 수동으로 한다는 특징.
- 근데 수동으로 하는 거 별로 원하지 않음.
- 하나의 마스터와 여러 개의 슬레이브 구성
- Active / Stand-by
- 장애가 발생하면 Fail-over
- Active 브로커가 우선 작동을 하다 죽을 경우, Stand-by브로커가 대체하게 된다.
최초 Active는 하나. 동작하는 Active가 죽을 경우 Stand-by 브로커가 Active 브로커로 자동 전환됨. - Active 브로커는 항상 하나이다.
- 전환에 시간이 걸리면 문제가 생길 가능성이 있음.
- Active / Active
- 동시에 여러 개의 Active를 구성
- 어떤 상황에도 Active가 하나 이상 존재함.
따라서 Active가 죽어도 큰 문제가 없음. - 의견이 다를 때는 합의(다수결. 3,5,7,9개의 Active)
결정에 시간이 걸린다는 단점이 있음.
zookeeper에 대한 입장
- 필수
- 꼭 해야함.
- Required / mandatory / compulsory
- 권장
- 안해되 되지만, 안하면 좀 힘들걸
- recommended
- 옵션
- 하면 좋음.
- optional
- 하둡2 부터는 주키퍼는 recommended, 카프카의 주키퍼가 required
클라우드
클라우드 현황
- IT 공룡들의 경쟁
- 실리콘 밸리 핵심기업 FAANG
- Facebook, Amazon, Apple, Netflix, Google
- 클라우드 4인방 AMIG
- Amazon AWS
- Microsoft Azure
- IBM Bluemix(Watson, Hyperledger Fabric, ...)
- Google Cloud
- 얼마나 돈이 될까?
- 모든 IT 기업들이 클라우드에 투자.
- 오라클 ...
- 한국은 규제나 기술격차가 심하다.
클라우드는 싸지 않다.
- 절대비용은 작게 잡아도 50%이상 비쌈.
- 하지만 총 비용(TCO, Totla Cost of Ownership. 총 소유비용) 감소
- 인건비, 수리비 등 여러 부대비용을 모두 계산해보면 클라우드가 더 저렴하다.
클라우드의 장점
- 비용 절약! / 시간 절약 / 부가가치
- 첨단 하청.
- 클라우드로 옮기면 기존의 서비스가 모두 지원되는가?
- 클라우드 갑질? 헤게모니 문제
클라우드 서비스의 종류
- 클라우드는 public과 private로 나뉨
- 대상이 일반인가 기업인가
AWS 등은 public 계열. 카카오 등 기업 자체적으로 구축한 클라우드는 private
- 대상이 일반인가 기업인가
- 클라우드 자체 구축(On-premise) vs 클라우드 서버 사용
- 서버 호스팅과의 차이점은?
- 비용 / 보안 / 성능 문제 등등..
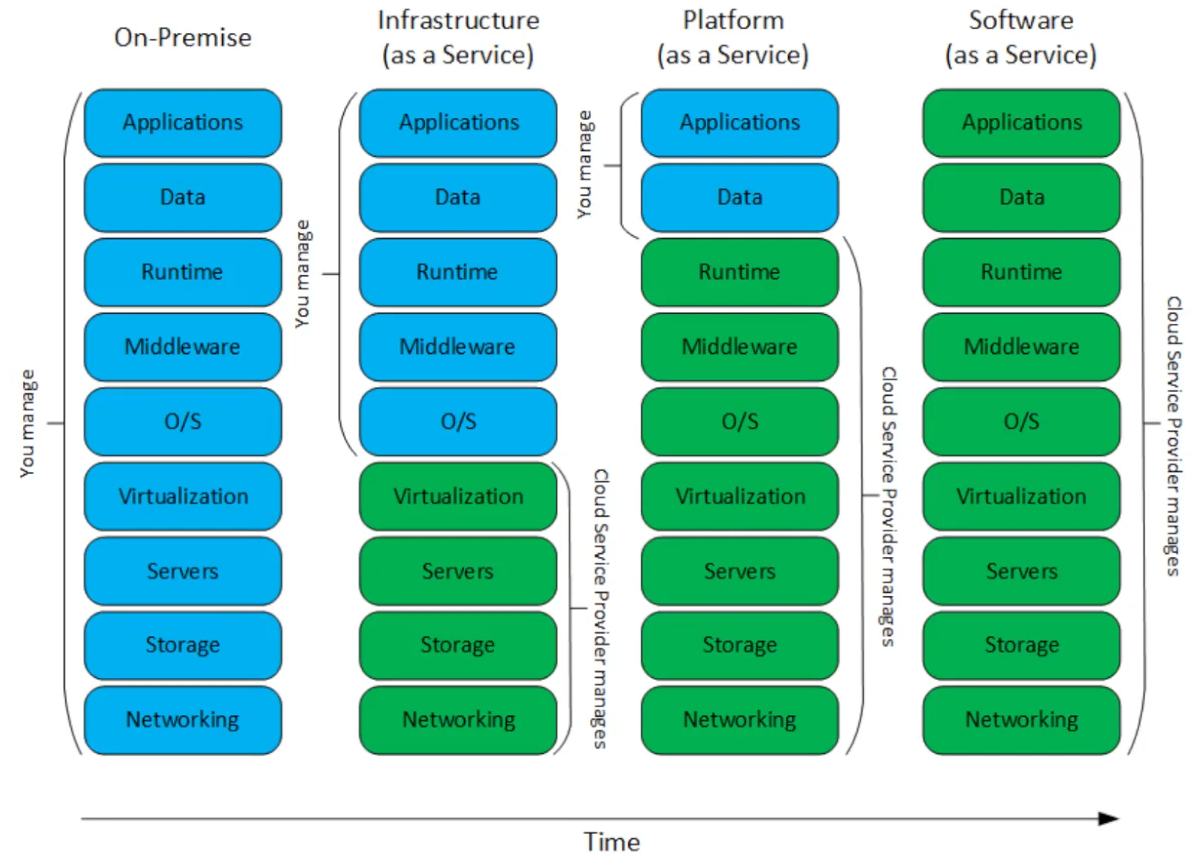
SPI 모델
- 가장 일반적인 클라우드 구부넙
IaaS(Infrastructure as a Service)
- 서버 자원(CPU/메모리/디스크/네트워크), ...
- 아마존 AWS EC2
- 요새는 OS설치까지는 해서 제공되는 경우가 많다.
PaaS(Platform as a Service)
- OS + Runtime(Java)+Platform(Spring, Hadoop, DBMS, ...)
- 아마존 AWS EMR
- 풀옵션 원룸과 비슷함.
- 프로그램을 실행하기 위한 여러 기반 프로그램이 갖춰져 있는 경우.
SaaS(Software as a Service_
- Google Drive, MSOffice.com, ...
- BaaS(Backend as a Service)
- 네트워크를 사용하는 앱을 만들 때 서버단을 서비스형태로 제공.
- CaaS(Container as a Service)
- MaaS(Monitoring as a Service)
- CaaS(Communication as a Service)
- DaaS(Database as a Service)
- XaaS(Anything as a Service)
- BaaS(Blockchain as a Service)
- IaaS와 SaaS 사용이 많다. IaaS의 점유가 50% 이상.
오픈소스 기반 IaaS 서비스
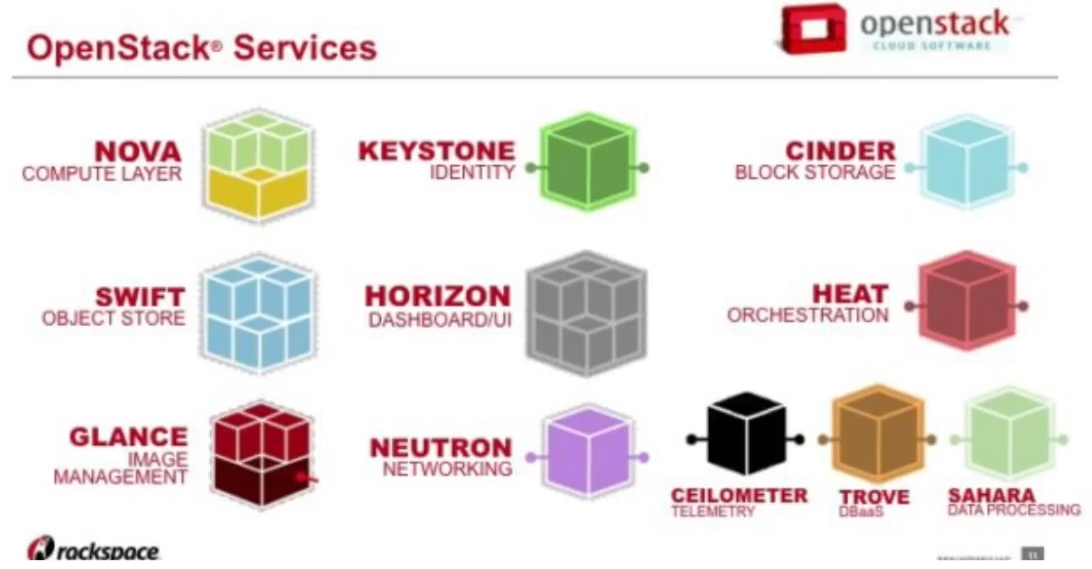
- 오픈스택(OpenStack)
- Open IaaS
- IaaS 스타일의 오픈소스 클라우드 구축 플랫폼
- "KVM"을 기본 하이퍼바이저로 사용
- 직접 IaaS를 구축할 수 있다.
- 오픈스택 재단(OpenStack Foundation)
- 2010년부터 시작.
오픈소스 기반 PaaS 서비스
- VMWare의 CloudFoundry와 Redgat의 Openshift가 경쟁
- PaaS에서 기본으로 제공되는 "서비스"의 종류
- 장애 복구, 스케쥴링, 로드밸런싱, 확장성(Scalability), 고가용성(High Availability), 미터링(Metering), 모니터링(Monitoring)
클라우드 구현 기술
- 클라우드를 구축하기 위한 가능 기술(Enabling Technology)
- 가상화 vs 컨테이너 기반 가상화
- 가상화
- 하이퍼바이저(Hypervisor)로 통칭
- VMWare, Hyper-V, ...
- 컨테이너 기반 가상화
- 도커(Docker), 쿠버네티스(Kubernetes)
가상화
- 가상화는 얼마나 사용하나?
- 클라이언트
- 서버
- 서버에서는 가상화를 사용하지 않는 경우가 거의 없다.
- Utilization(70~80%)
100%에 근접하게 할 경우 불안해질 수 있다. - 하지만 개별 VM은 느려짐
- Utilization(70~80%)
- 가상머신 예시
- 리소스가 놀고 있다면 가상머신을 추가해서 성능을 끌어올린다.
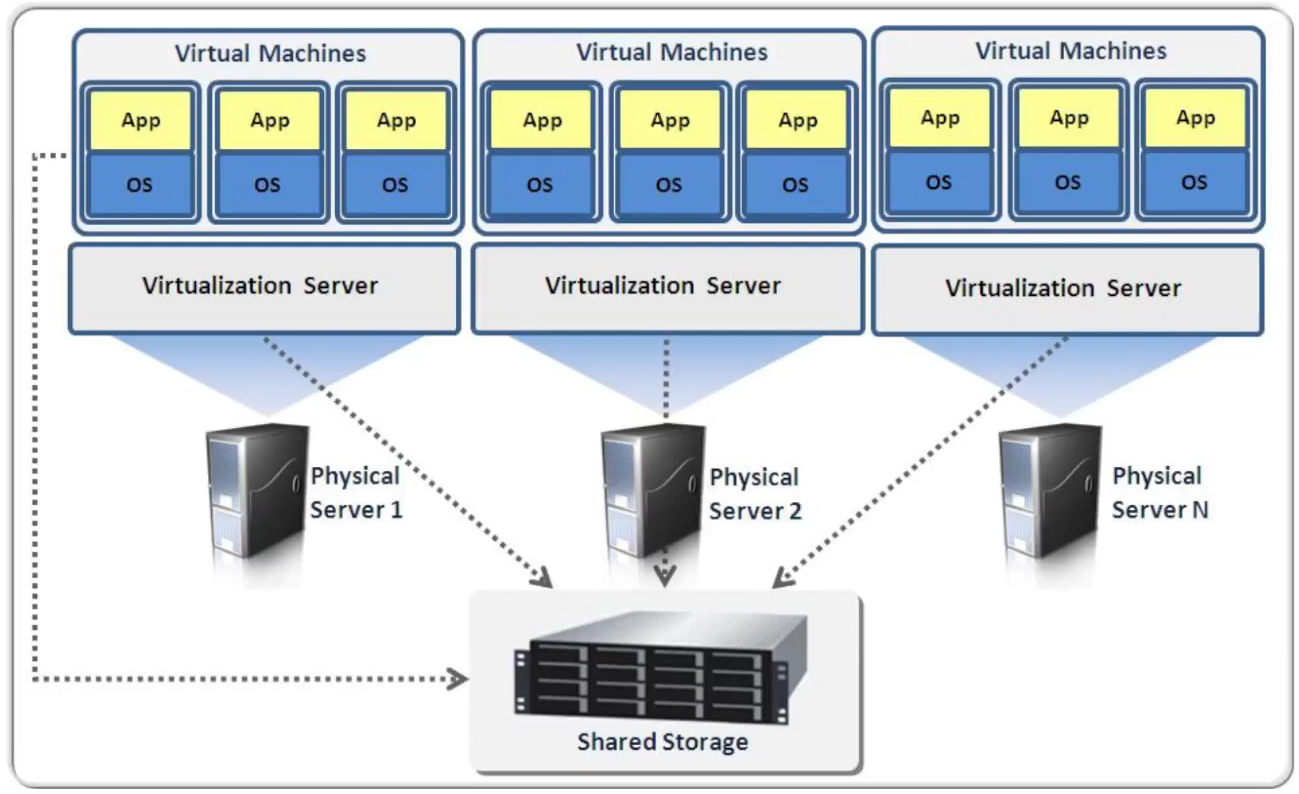
- 가상화(Virtualization)는 서버의 리소스 가상화를 통해 하나의 서버에 여러대의 OS를 동작시킬 수 있는 기술
- 서버의 사용 효율 (Utilization)을 높일 수 있다.
- 컴퓨터 자원 (CPU, 메모리, 저장장치 등)의 추상화/프로비저닝(Provisioning)
- CPU의 기능 지원 필요
- vt-x(인텔)/AMD-V(AMD)
- 인텔 셀러론/펜티엄 계열 CPU는 지원하지 않음.
- 가상머신을 사용하면 낭비되는 리소스를 활용해 성능을 개선할 수 있다. 하지만 개별 VM의 성능은 저하된다.
→ 개별 VM의 성능을 덜 저하시키는 기술이 나오게 된다. - 가상화 2세대 기술
- 도커(컨테이너기반 가상화)
- 가벼우면서도 스마트한 기술
- 쿠버네티스(오케스트레이션 기술)
- 여러 대를 관리하는데 필요한 기술 제공
- 도커(컨테이너기반 가상화)
도커 & 쿠버네티스
가상화
- 가상화(Virtualization)는 서버의 리소스 가상화를 통해 하나의 서버에 여러대의 OS를 동작시킬 수 있는 기술
가상화의 레벨
- API(Application Programming Interface)
- 응용프로그램 레벨의 함수/메서드, 언어독립적인 경우도
- 윈도우→리눅스, 리눅스→윈도우 처럼 가상화 없이 프로그램이 돌릴 수 있도록 API를 제공.
- WSL(Windows Subsystem for Linux)
- ABI(Application Binary Interface)
- Windows RT(AMD) vs Windows(Intel)
- 플랫폼과 소프트웨어 사이의 인터페이스 정의
- API보다 낮은 레벨
- API는 유지되면서 ABI는 변경되는 경우
- 코드는 유지하면서 재컴파일. 크로스 컴파일.
- 안드로이드 프로그램이 윈도우에서 동작하게 해주는 것도 일종의 VM. ABI기술에 속한다.
- ISA(Instruction Set Architecture)
- 하드웨어와 소프트웨어 사이의 인터페이스 정의
- VMWare등의 기술. 애뮬레이션처럼 동작함.
일반적인 부팅방식을 따름.
- 하이퍼바이저
- 호스트시스템에서 다수의 게스트 OS를 돌리기 위한 플랫폼
- 호스트 OS
- 물리시스템(컴퓨터)에 설치된 OS
- 게스트 OS
- 가상머신/컨테이너 위에 설치된 OS
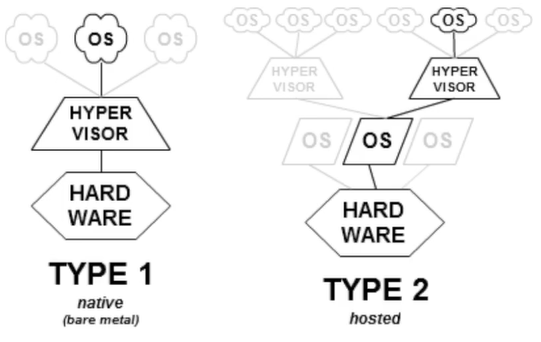
- 타입 1
- 하이퍼바이저가 하드웨어 위에서 바로 실행
- 타입 2
- 호스트OS위에 하이퍼바이저를 실행시키는 방식
가상화의 장단점
- 장점
- 서버의 사용효율(Utilization)을 높일 수 있음.
- 20년 가까이 성숙된 기술/시장의 주류
- 단점
- 네이티브보다 느림.
- 상대적으로 무거움(컨테이너 기반 가상화)
- 오버헤드 (15~20%) 정도
- 불필요한 기능의 중복
- 호스트OS와 게스트OS 간의 기능 중복
- 프로세스 스케줄링
- 호스트OS와 게스트OS 간의 기능 중복
- 배치(Deployment)의 어려움
- 대형 서비스에서 구축 방법이 복잡.
전가상화와 반가상화
전가상화(Full Virtualization)
- 하드웨어를 완전히 가상화
- OS를 제약없이 사용할 수 있음
- 게스트 OS는 자신이 가상머신 위에서 동작하고 있다는 것을 인식하지 못함.
- 시스템에서 물리적인 가상화 지원기능이 필요. vt-x(인텔)/AMD-V(AMD)
- 게스트 OS에서 물리자원에 직접 접근 불가
- 반드시 하이퍼바이저를 통해 접근해야 함 → 성능 저하로 이어짐.
반가상화(Para Virtualization)
- 게스트 OS가 자신이 가상머신 위에서 동작하고 있다는 것을 인식
- OS 제약이 있다.
- OS의 제약, 커널을 수정해야한다.(주로 리눅스만 됨)
- 게스트OS에서 물리자원 직접 접근 가능(Passthrough) → 성능개선
- 바이너리 변환(Binary Translation)
- HVM(Hardware Virtual Machine)
베어메탈(Bare-metal)
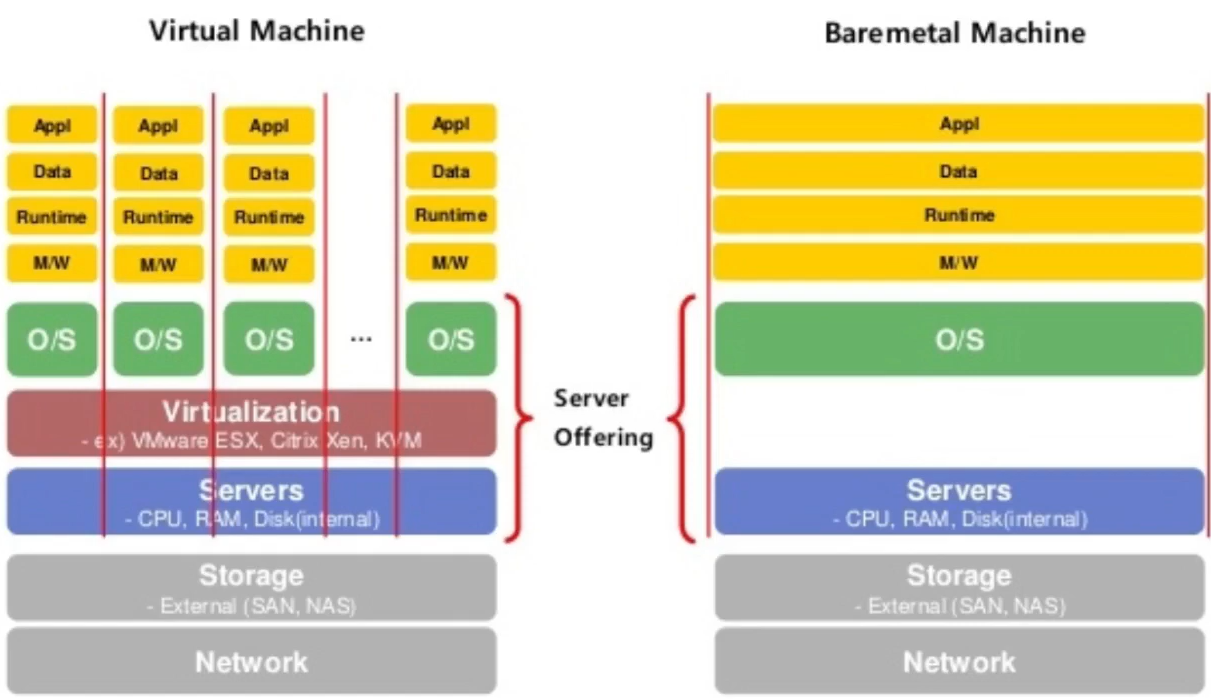
- 서버는 거의 100% 가상머신을 사용하지만, 사용하지 않는 경우도 있다.
그것을 베어메탈이라고 부른다. - Bare : 거의 없는. Bare-metal은 위에 덮인 프로그램 없이 생 쇠와 같다는 뜻으로 이해하면 된다.
하이퍼바이저 종류
- VMWare
- 대표적인 상용 하이퍼바이저
- ESXi/Workstation/WorkStation Player
- ESXi : 하이퍼바이저
- vSphere(ESXi+vCenter)
- vCenter : 중앙제어
- 가상머신과 중앙제어 소프트웨어
- MS Hyper-V
- 윈도우 서버에 통합
- Ctrix Xen(오픈소스)
- 최초의 반가상화 하이퍼바이저
- 오픈소스
- KVM(오픈소스)
- 하이퍼바이저를 커널의 '서브모듈'로 제공(.ko)
- 메모리관리자/파일시스템/하이퍼바이저
- 오픈스택의 기본 하이퍼바이저
- 패러렐즈(Parallels)
- MacOS기반의 하이퍼바이저
- 오라클 버츄얼박스(Oracle VirtualBox)
- 오라클에서 만든 GPL기반의 하이퍼바이저
컨테이너기반 가상화
- 기존의 가상화와 다른 개념
- 하드웨어 가상화가 아닌 실행환경의 분리(isolation)
- 각 컨테이너 간 영향을 분리
- 기존의 경우 : 호스트OS > 하이퍼바이저 > 게스트OS > ...
- 도커 : 호스트OS > 도커 > ...
- 사용하는 입장에서는 일반적인 가상머신과 다를 것이 없으나, 아키텍쳐 관점에서는 게스트 OS와 다르다.
호스트OS의 커널을 컨테이너가 모두 공유. - 도커는 리눅스 전용 기술. (윈도우 X)
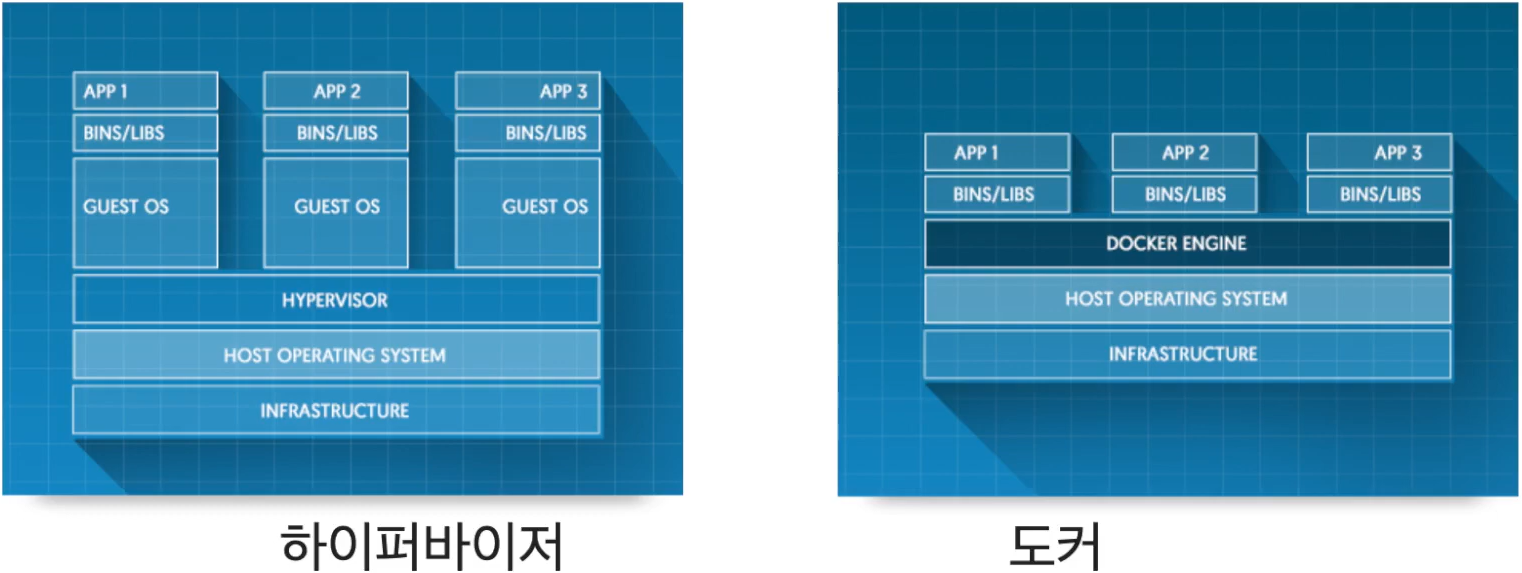
- 구축 및 실행 단순화
Build-Ship-Run

도커의 특징
- 가볍다
- 똑똑하다
- 많은 사람들이 자기가 구축한 이미지를 공유(도커허브)
- 거의 천만개 이상의 이미지가 공유되고 있음.
- 구글, 오라클과 같은 회사에서 자사의 SW 배포 방법으로 채택
- 텐서플로우, 오라클/MySQL, ...
- 에코시스템(Ecosystem)
- 도커의 단점을 보완하는 기술들.
- 도커기반/활용 기술의 활성화
- 도커 컴포즈, 스웜, 쿠버네티스, ...
- 하이퍼레저 패브릭, ...
- 가상머신을 쓰는 것보다 도커를 사용하는 것이 장점이 더 많다.
- 오버헤드가 3~5% 이내
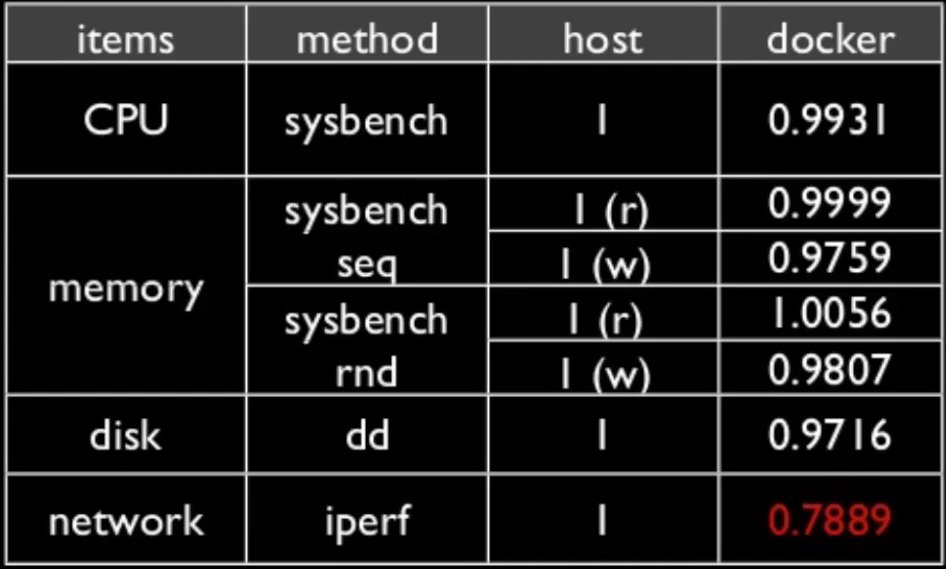
- 도커를 쓰면 네이티브(베어메탈)에 비해 큰 성능저하를 보이지 않는다.
기술적 특징
- 시스템의 분리에는 Linux Containers(LXC)
- 파일 시스템은 Advanced multi layered unification filesystem(Aufs)
- 그리고 Git과 같은 이미지 버전컨트롤 시스템 도입
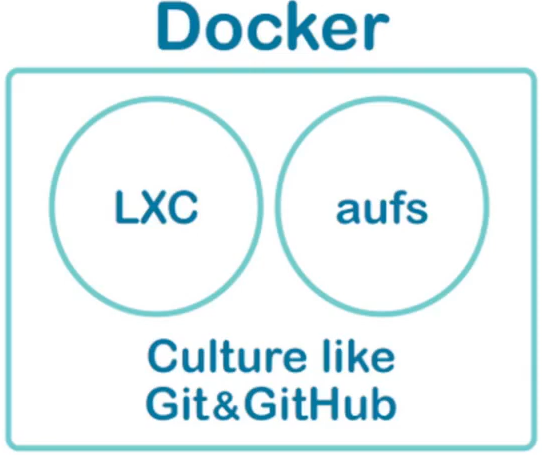
- 모든 컨테이너들이 동일 OS 커널 공유
- 독립적인 스케줄링이나 CPU/메모리/디스크/네트워크를 가상화하지 않음
- 리눅스의 특수 기능(LXC)을 사용한 실행환경 격리를 응용
- 리눅스에서만 사용 가능
- 다른 OS(윈도우/OSX)에서 사용하려면
- 일반 하이퍼바이저(경량)가 있어야 함
- Windows Container 지원 (MS)
- 구글에서 만든 Go언어로 작성
- PaaS 공급업체 DotCloud가 PaaS의 백엔드로 사용하는 컨테이너 기반의 가상화 소프트웨를 오픈소스로 공개.
- 현재 도커로 회사명 변경
- 14년 6월 출시
- 구글과 같은 메이저 벤더들에 빠른 속도로 채택
- 현재 사실상의 표준(de facto standard)이 됨
- 리눅스 시스템설정방식과 도커기반 리눅스 설정방식이 다름.
- 환경변수 설정, 서비스 수행방식, ...
LXC
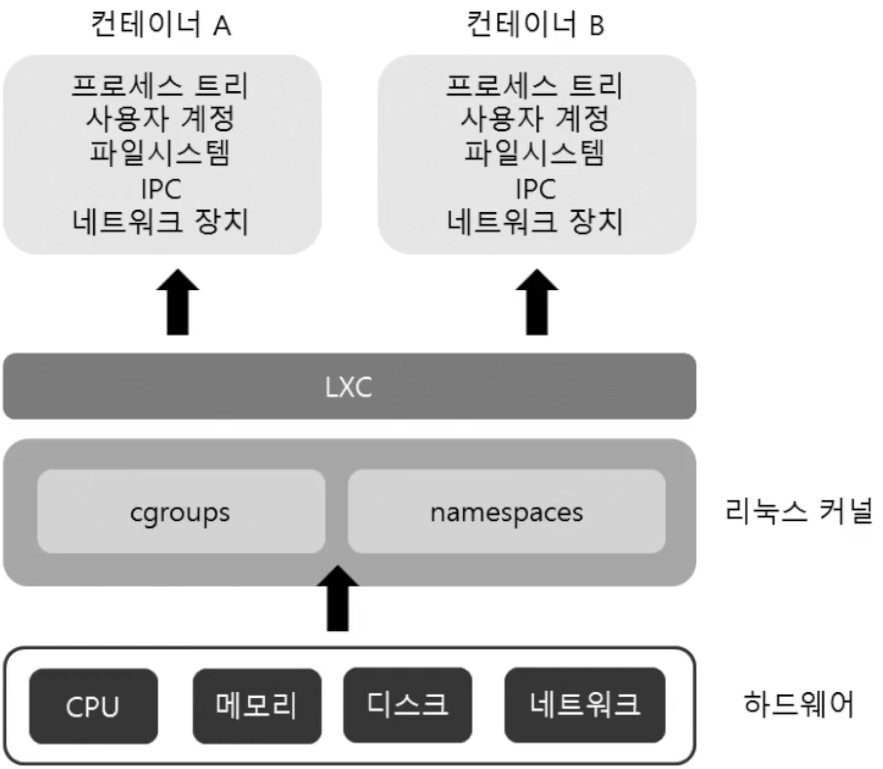
- 커널에 있는 기능만 사용해도 가상화를 할 수 있음.
- Linux Container
- 시스템레벨 가상화
- cgroups(control groups)
- CPU, 메모리, 디스크, 네트워크
- Namespaces(Namespace Isolation)
- 프로세스트리, 사용자계정, 파일시스템, IPC, ...
- 호스트와 별개의 공간 설정
- chroot(change root) 명령어에서 발전
- chroot jail
- chroot 상의 폴더에서 외부 디렉토리 접근 안됨.
- 하지만 우분투의 특허기술.
Libcontainer
- 우분투의 의존성을 해결하기 위해 LXC 외에 libcontainer 제작
- 실행 드라이버(exec driver)라고 부름.
- native(libcontainer), lxc(LXC)
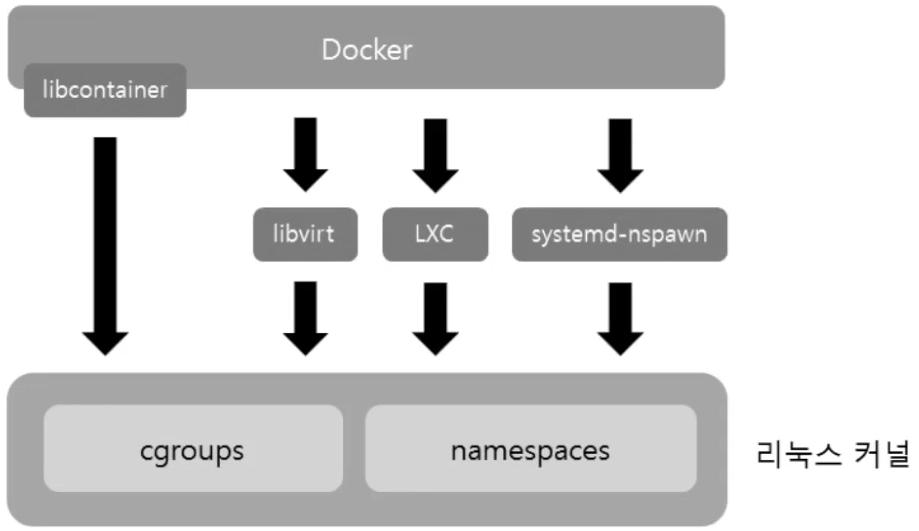
- 이 기술을 도입하고 나서 우분투 외에서도 기능하기 시작함.
containerd/runC
- 표준화 진행한 도커.
- 기존방식과 최신방식의 차이점
- containerd/runC 기반의 도커
- 도커 1.11 이후
- containerd
- 컨테이너를 실행하고 노드에서 이미지를 관리하는데 필요한 최소한의 기능세트를 저장하고 OCI(Open Container Initiative) 호환 코어 컨테이너 런타임 중 하나
- CNCF에 공식적으로 포함됨(쿠버네티스 표준화 담당)
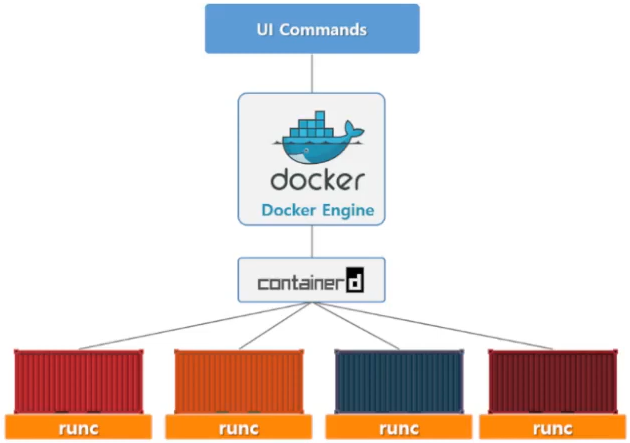
- 도커는 root권한을 요구하는데, 이것이 보안취약점을 만들 수 있음.
LXD
- 우분투를 만든 캐노니컬(canonical)에서 만든 컨테이너 솔류션
- 기존의 LXC에 보안 개념 추가
- Secure by default
- Unprivileged container
- root가 아니어도 컨테이너 생성가능
- 도커는 Application Container, LXD는 Machine Container
- LXD는 Container "Hypervisor"
- 경쟁기술이라기 보다는 보완관(도커와 병행 가능)
- KVM(Kernel Virtual Machine)을 경쟁 기술로 간주
- Docker on RunC vs Docker on LXD
- 단점 : 캐노니컬의 특허 기술이기 때문에 우분투에서만 기동함.
때문에 LXD는 반쪽짜리 해결책이라 부를 수 있음.
rkt, 로켓
- root권한을 요구하지 않는 다른 컨테이너 프로그램을 이용한다면? 보안문제를 해결할 수 있지 않을까?
- 단점 : 도커를 사용하지 않으면 도커 이미지를 활용할 수 없다.
Container Orchestration(컨테이너 지휘)
오케스트레이션
- 여러 대의 서버/서비스를 편리하게 관리해주는 작업
- Logging, Monitoring
- 여러 대의 서버를 관리하는 경우 로그와 서버 상태를 한 곳에서 관리
- Service Discovery
- 서버나 컨테이너가 추가되었을 때 자동으로 발견하는 작업
- Clustering
- Scheduling(핵심기능)
- 어떤 서버에 컨테이너를 할당할 것인가.
- Load Balancer
- 여러 개의 서버/컨테이너에 작업을 고르게 분배.
- High Avilability(고가용성)
- 클러스터 내의 서버가 다운됐을 때 대응
cf. DB 이중화
- 클러스터 내의 서버가 다운됐을 때 대응
- (Auto) Scalability
- 성능을 지속적으로 향상시키는 기능
트래픽 양에 따라 서버 수를 조절함. 완전자동으로 할수도 있고, 명령어를 통한 수동제어도 가능.
- 성능을 지속적으로 향상시키는 기능
- Rolling Update
- 여러개의 컨테이너의 이미지 업그레이드
일부는 업데이트 / 일부는 운영. 모든 서버가 동시에 업데이트하면 위험하다.
- 여러개의 컨테이너의 이미지 업그레이드
→ 일종의 분산 WAS/미들웨어의 역할
툴 선택기준
- Swarm vs Kuvernetes
- 쿠버네티스
- 강력한 기능/ 복잡한 설정
- 500대의 서버에 50,000컨테이너를 서비스 가능
- 스웜
- 비교적 간단한 설정
- 50대 미만의 경우 스웜을 사용하는 것이 유리
- Kakao Cloud > 20000VM > 2~3명이 관리.
- 도커는 스웜을 좋아하지만, 시장은 쿠버네티스를 선택하는 것 같다.
서비스가 시작될 때는 규모가 작겠지만, 시간이 지나면 지날수록 더 많은 서버가 필요하게 됨. > 결국 스웜으로는 부족해진다. - 공부할때는 스웜이 좋지만 운영할 때는 결국 쿠버네티스를 사용하게 된다.
스웜
- 여러대의 도커 서버를 하나의 클러스터로 구성
- 분산코디네이터(Distributed Coordinator)
- 각종 정보를 저장하고 동기화
- 일종의 분산 DB
- 서버 상태, 각 노드의 상태를 파악할 수 있음
- 매니저(Manager)
- 클러스터 내의 서버를 관리하고 제어함.
- 각 서버의 상태를 보고 명령을 내림.
- 에이전트
- 각 서버의 제어를 담당.
- 매니저에게 명령을 받고, 명령을 수행.
분산 코디네이터
- 기능
- 클러스터에서 새로운 서버의 발견
- 클러스터의 각종 설정 저장
- 데이터 저장
- 보통 고가용성(HA:High Availability)를 위해 사용하는 경우가 많음
- 분산 코디네이터가 다운되면 전체 클러스터가 동작하지 않음.
- etcd(kubernaetes), zookeeper(swarm, hadoop, spark, ...), consul등이 있다.
스웜 모드
- (정적) 로드밸런싱
- 라운드 로빈(round-robin)방식으로 컨테이너 접근
- 이중화를 하면 내부적으로 로드
- 스케일링
- 인스턴스를 4개로 변경
- 장애 복구
- 롤링 업데이트
- 업데이트를 나눠서 하게 한다.
- 로그(도커)
- 로그 취합(스웜)
Kubernetes
- 상용 수준의 컨테스트 오케스트레이션 수준.
