Entity
- 다른 엔티티와 구별할 수 있는 식별자를 갖고 있고, 시간의 흐름에 따라 지속적으로 변경되는 객체
- 식별자는 개별성이 있는 값을 말한다.
Value Object
- 각 속성이 개별적으로 변화하지 않고, 그 자체로 고유한 불변 객체
값의 조합으로 고유성을 갖으며, 한 번 만들어지면 내용이 변하지 않음. 불변하다. - Entity가 Value Object를 속성으로 갖는 경우가 많다.
JDBC
- DB에 SQL문을 사용하려면 별도의 툴이 필요하지만, JDBC가 그것을 대신 수행해줌.
- 자바 애플리케이션과 DB의 다리 역할을 해준다.
DB에 연결하고 작업을 할 수 있으며, 표준으로 제공되는 인터페이스. 종류에 관계없이 SQL문 사용 가능. - JDBC를 사용하려면 드라이버를 다운받아야 한다.
mysql jdbc driver maven/gradle repository를 구글에 검색하면 바로 드라이버 설치 페이지가 나오니,pom.xml혹은build.gradle에 붙여서 사용하면 된다.
Embbedded Database
- 프로그램을 실행할 때 외부 환경(DB 프로그램 등)에 좌우되면 일정한 테스트가 어려울 것이다.
- 때문에 별도의 DB를 구동하지 않더라도 프로그램 내부에서 자체적인 DB를 구성해 테스트를 실행할 수 있도록 도와주는 기능이다.
DTO
- 계층 간 데이터 교환을 하기 위해 사용되는 객체.
로직을 가지지 않은 순수한 데이터 객체(getter&setter만 가진 클래스)이다. - 예시) 유저가 입력한 데이터를 DB에 넣음.
- 유저가 자신의 브라우저에서 데이터를 입력, form에 있는 데이터를 DTO에 넣어서 전송.
- 해당 DTO를 받은 서버가 DAO를 이용해 데이터베이스로 데이터를 집어넣음.
DAO
- DB에 접근하기 위한 객체. Database에 접근하기 위한 로직&비지니스 로직을 분리하기 위해 사용.
Servlet
- 웹 서버 안에서 동작하는 자바 프로그램. 웹 클라이언트 등으로부터 요청받고 그거에 대한 응답을 처리한다. 대체로 HTTP
- 서버 역할을 하는 자바 소프트웨어 컴포넌트로, HTTP 요청에 따라 특정한 기능을 수행하고 HTML 문서를 생성하는 등 응답처리를 한다.
MVC
- Model, View, Controller
- 웹 애플리케이션을 만들 때 관심, 기능을 분리해서 각각 컴포넌트들의 관심사를 분리시킨 것.
- 하나의 자바 파일이 수천~수만 줄로 작성되는 것을 막는다. 가능한 한 곳에 몰리거나, 기준 없이 흩어놓는 것이 아닌 Model/View/Controller의 규칙을 갖는 형태로 분리시킴
- Model(java 객체) : 자바 객체 또는 Pojo로 데이터를 담고 있음.
- View(JSP) : 모델이 담고 있는 데이터를 시각적으로 보여줌.
- Controller(Servlet) : 모델과 뷰를 연결하기 위한 매개체. 클라이언트의 입력, 요청을 받아 모델의 상태 변경, 그에 따른 뷰 업데이트
- 정보 저장 - 랜더링/시각화에 필요한 로직처리 - 데이터처리
domain
- 소프트웨어로 해결하고자 하는 문제 영역
- 애플리케이션 내 로직들이 관여하는 정보와 활동의 영역.
마켓을 구현하는 경우를 생각해보면
- 회원가입, 탈퇴 기능 → 회원 영역.
- 물건 주문, 장바구니 등 → 주문/정산/결제 영역
- 결제할 때 혜택이나 쿠폰 적용 → 결제/쿠폰 영역
화살표 뒤에 있는 것들이 도메인이다.
Domain Layer
- Presentation Layer : 클라이언트의 요청을 받아 응용영역에 전달하고 처리 결과를 다시 클라이언트에게 보여주는 역할
- Controller 영역.
- Application Layer : 응용영역 시스템이 사용자에게 제공해야 할 기능 구현
- Service 영역
- Domain 영역 : 도메인 영역. 도메인 모델 구현 (이름/주소/상품 등)
- InfraStructure Layer : 구현 기술을 다룬다. (외부 API, 데이터베이스, 외부 라이브러리 등)
Domain Model
- 특정 도메인을 개념적으로 표현. 정보를 제공하기 위한 목적을 가진 게 '모델'
- 기획, 디자인, 개발 시 의사소통의 수단으로 사용됨.
Bounded context
- 해결 영역
- 도메인 내에서 관심 영역을 분리하는 것. 과제의 범위를 나눠서 한 번에 하나의 기능에 집중할 수 있게 하는 것이다.
Aggregate
- 시스템이 기대하는 책임을 수행하면서 일관성을 유지하는 단위
- 명령을 수행하기 위해 함께 조회하고 업데이트해야 하는 최소 단위
- 실제 구현된 클래스들의 계약을 정리하는 방법. 일종의 '캡슐화'
- 예시)
- 같은 애그리거트
- [주문할 상품 개수, 배송지 정보, 주문자 정보]는 주문 시점에 함께 생성되기 때문에 하나의 애그리거트
- 주문 상품 개수-총 주문 금액 등 함께 변경되는 빈도가 높은 객체들도 한 애그리거트로 묶어주면 좋다.
- 다른 애그리거트
- Product(제품 정보)와 Review(사용자 리뷰)는 함께 생성되지도 않고, 함께 변경되지도 않기 때문에 한 애그리거트에 속하지 않는다.
- 또한 변경 주체가 다르고, 서로의 변경이 서로에게 영향을 주지 않기 때문에, 서로 다른 애그리거트에 속한다.
Aggregate Root
- 도메인 규칙을 지키려면 애그리거트에 속한 모든 객체가 정상적 상태를 가져야 함. 이 전체를 일관적 상태로 관리하는 책임을 지닌 엔티티.
애그리거트의 일관성이 깨지지 않게 하는 것이 가장 중요- 애그리거트 루트가 강제하는 도메인 규칙을 적용하려면, 애그리거트 외부에서 애그리거트에 속한 내부 객체를 직접 변경하면 안됨. → 애그리거트 루트 엔티티의 식별자를 통해서만 접근하게 해아함.
전역 식별자
- 루트 엔티티의 식별자를 에그리거트 외부에서 사용할 수 있는
전역 식별자라고 함.
전역 식별자를 통해 애그리거트를 조회할 수 있다.
ApplicationContext
- 스프링 컨테이너
BeanFactory의 하위 인터페이스로 실질적으로BeanFactory를 대신해 사용된다.- IoC Container의 스프링 버전.
- Bean : 스프링에서 제공하는 ApplicationContext에서 관리되는 객체를 말함.
IoC에서 관리되는 객체와 아닌 객체를 분리하기 위해서 만든 용어.
DI, Dependency Injection
- 의존관계 주입
A가 B를 의존한다.면 B의 변화가 A에 영향을 미치게된다.- 의존성이 높은 것은 바람직하지 않으니, 의존관계를 인터페이스로 추상화 할 수 있다.
- 의존관계를 외부에서 결정하고 주입하는 것이 DI이다.
- 클래스 모델/코드에는 런타임 시점의 의존관계가 드러나지 않는다. 그러기 위해서는 인터페이스만 의존하고 있어야한다.
- 런타임 시점의 의존관계는 컨테이너나 팩토리 같은 제 3자의 존재가 결정.
- 의존관계는 사용할 오브젝트에 대한 레퍼런스를 외부에서 제공(주입)해줌으로써 만들어진다.
- DI는 의존관계를 외부에서 결정하는 것이기 때문에, 클래스 변수를 결정하는 방법들이 곧 DI를 구현하는 방법이다.
- 런타임 시점의 의존관계를 외부에서 주입, DI 구현이 완성된다.
Component Scan
- 스프링이 직접 클래스를 검색, 빈으로 등록해주는 기능.
@Component Scan를 이용하면 설정 클래스에 직접 빈으로 등록하지 않아도 원하는 클래스를 빈으로 등록할 수 있음. @Conponent를 가진 모든 대상을 가져와 빈에 등록하기 위해 찾는 과정
Autowired
- 생성자를 통해 주입하지 않고 자동으로 의존관계 형성.
- 필드에 주거나 세터에 줄 수 있음.
- 생성자가 두 개 이상일 경우 스프링은 빈을 생성할 생성자를 선택하지 못하기 때문에 스프링에 자동으로 주입되는 생성자 메서드에
@Autowired를 달아줘야한다. 하나일때는 자동으로 붙음. - 자동으로 주입 가능한 동일한 빈이 두개 있다면 오류 발생.
@Primary를 붙이면 우선 등록
@Qualifier을 사용해 용도 구분.
Profile
- 공통적인 특징을 찾아서 그룹화한 것.
- 설정, Bean 같은 것을 그룹화해 하나의 프로파일로 정의하고 그것을 이용해 어플을 구동할 수 있다.
- 개발/운영/로컬/스테이지 환경 등 여러 환경별로 프로파일을 만들고, 각 환경에서 동작하기 위해 필요한 환경설정 변수를 그룹화해 놓을 수 있음.
JUnit
- 가장 많이 사용하는 오픈소스 프레임워크.
- 테스트에 사용
기능
- 매 단위 테스트마다 테스트 클래스의 인스턴스 생성, 독립적인 테스트가 가능하다.
- 어노테이션을 제공, 테스트 라이프 사이클을 관리하게 해주고, 테스트 코드를 간결하게 작성하도록 지원함.
- 테스트 러너를 제공, 인텔리제이 등에서 테스트코드를 쉽게 실행하게 해줌.
assert로 테스트 케이스의 수행 결과를 판별하게 해준다.@BeforeAll은 테스트 코드 전체가 실행되기 전 한 번만 실행
@AfterAll은 테스트코드 전체가 실행된 후 한 번만 실행
@BeforeEach는 매 메서드 실행 전 실행.
@AfterEach는 매 메서드 실행 후 실행.- 구현 후 테스트 코드를 작성할 수도, 테스트 코드 작성 후 구현을 할수도 있다.
테스트 코드만 보고도 기능을 짐작할 수 있기 때문에, 테스트코드 작성은 중요하다.
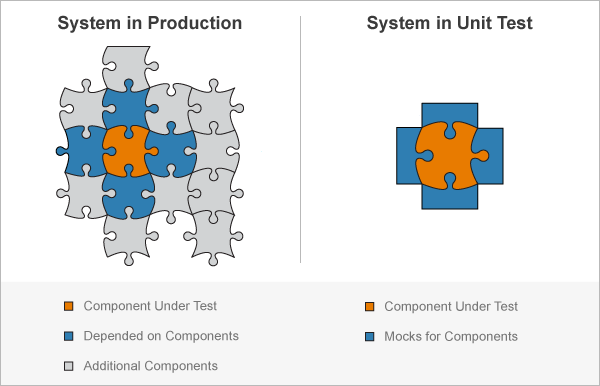
Mock Object(목 객체, 모의 객체)
- 테스트 더블
테스트하고자 하는 객체와 의존 관계에 있는 객체를 사용할 수 없을 때 테스트 하는 대상 코드.
SUT(System Under Test)와 상호작용을 하기 위해 만든 객체. target도 사용가능.
Person sut = PersonFactory.create();
Person target = PersonFactory.create();- 종류 : Mock, Stub
- Mock 객체는 호출에 대한 기대를 명시. 어떻게 동작해야하는지에 대한 내용이 기술된 객체이다.
- Mock은 행위에 집중.
- Stub은 가짜 객체 (dummy, fake)
- 실제 동작하는 것처럼 보이게 만드는 객체. 인터페이스를 구현하는 stub을 만들어 제공.
- 목 오브젝트는 행위 검증. stub을 포함한 다른 대역들은 상태검증에 집중한다.
- 행위 검증 : 목 객체가 메서드가 호출되어질 것이라는 기대하는 테스트를 짜는 것. 특정 메서드 호출, 특정 동작이 수행되는지 확인.
- 상태 검증 : 검증하고자 하는 객체, SUT에 대해 상태를 확인하며 올바르게 동작하는지 확인.
Mock 상세
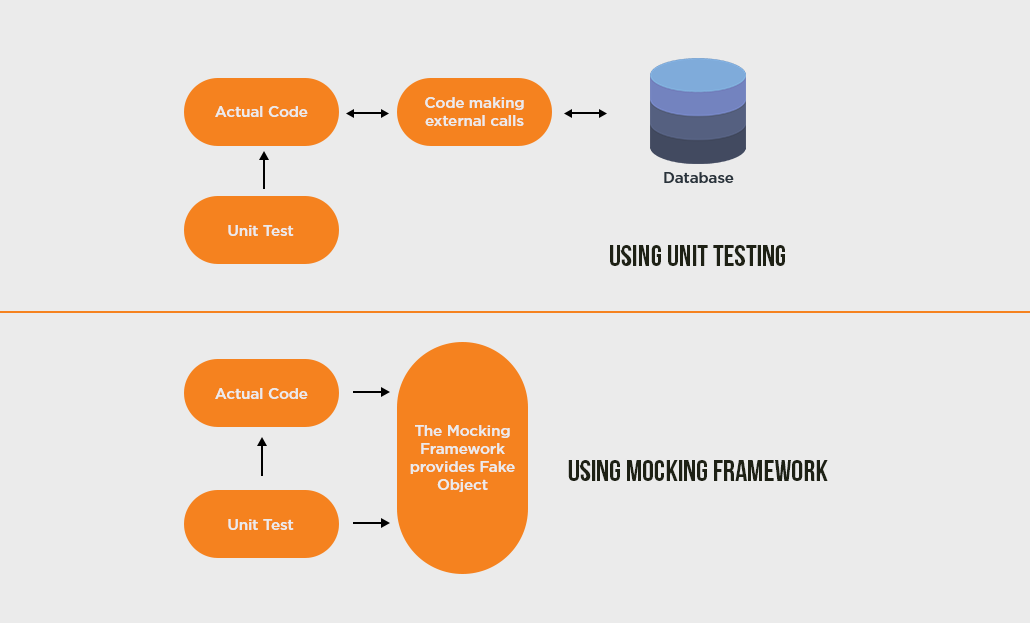
- 단위 테스트를 하기 위해 메서드를 실행할 때 메서드가 다른 네트워크, DB 등 제어하기 어려운 것들에 의존하고 있다면, 코드가 해당하는 Flow가 아닌 시스템의 다른 부분에 많이 얽히고 의존해있다면 단위 테스트가 어려워질 것이다.
- 이럴 때 Mock을 사용한다.
- Mock : 실제 객체를 만들어 사용하기에는 시간, 비용 등 cost가 높거나, 혹은 객체 서로 간 의존성이 강해 구현하기 힘들 경우 가짜 객체를 만들어 사용함.
- Mock 객체는
- 테스트 작성을 위한 환경 구축이 어려움
- 테스트가 특정 경우나 순간에 의존적
- 테스트 시간이 오래 걸림
- 개인 PC의 성능, 서버의 성능문제로 오래 걸릴 수 있는 경우 시간을 단축하기 위해 사용한다.
- Mock에 대한 기본적인 분류 개념, 테스트 더블
- 테스트 더블 (test double)
- 테스트 진행이 어려운 경우, 이를 대신해 테스트를 진행할 수 있도록 만들어주는 객체
- Mock 객체와 유사하나, 테스트 더블이 좀 더 상위의 의미로 사용됨.
- 더미 객체 (dummy object)
- 단순히 인스턴스화될 수 있는 수준으로만 객체 구현.
- 인스터스화된 객체가 필요할 뿐 해당 객체의 기능까지는 필요하지 않은 경우에 사용.
- 테스트 스텁 (test stub)
- 더미 객체보다 좀 더 구현된 객체.
더미 객체가 마치 실제로 동작하는 것처럼 보이게 만든 객체. - 객체의 특정 상태를 가정해서 만들어 특정 값을 리턴해주는 등의 작업 수행.
- 특정 상태를 가정해 하드코딩된 형태이기 때문에 로직에 따른 값 변경은 테스트할 수 없음.
- 어떤 행위가 호출됐을 때 특정 값으로 리턴해주는 형태가
Stub
- 더미 객체보다 좀 더 구현된 객체.
- 페이크 객체 (fake object)
- 여러 상태를 대표할 수 있도록 구현된 객체로 실제 로직이 구현된 것처럼 보이게 한다.
- 실제 DB에 접속해 비교할 때와 동일한 모양이 보이도록 객체 내부에 구현하는 것.
- 테스트케이스 작성을 위해 다른 객체들과 의존성 제거를 위해 사용.
- 페이크 객체를 만들 때 복잡도로 인해 노력이 많이 들어갈 경우 적절한 수준에서 구현하거나 Mock 프레임워크를 사용한다.
- 테스트 스파이 (test spy)
- 테스트에 사용되는 객체, 메서드의 사용 여부 및 정상 호출여부를 기록, 요청시 알려줌.
- 테스트 더블로 구현된 객체에 자기 자신이 호출되었을 때 확인이 필요한 부분을 기록하도록 구현.
- 목 객체 (Mock Object)
- 행위 검증을 위해 사용되는 객체를 지칭. 수동으로 만들수도, 프레임워크를 통해 만들수도 있다.
- 행위 기반 테스트는 복잡도, 정확성 등 작성하기 어려운 부분이 많아 상태 기반 테스트가 가능하다면 만들지 않는 것이 좋음.
- Mock 유의사항
- 정말 필요한가?
- 테스트 케이스 유지에 복잡성이 더해지기 때문에 없는게 나을수도.
- 목 객체는 목 객체일 뿐이므로 실 객체로 작동해보았을 때 테스트 결과와 다른 결과가 나올수도 있다.
AOP (Aspect Orient Programming, 관점 지향 프로그래밍)
- 프로그램 패러다임.
Aspect는 '관점'보다는기능, 관심으로 생각하는 것이 더 맞는 해석일 듯.- 어떤 로직을 기준으로 핵심적인 기능, 부가적인 기능으로 나누어서 보고 그 기능을 기준으로 각각 모듈화하겠다는 것.
핵심기능은 비즈니스 로직에 집중, 부가기능은 별도로 분리하여 부가기능을 담당하는 모듈에서 자체적으로 관리하고 발전시키자. - 레이어를 분리시켜서 기능을 집중시킨다.
Presentation/Business/DataAccess Layer - Logging/Transaction/Security 등과 같이 공통으로 고민해야하는 부분에 대해서는 횡단으로 각각에 레이어를 걸쳐 적용시켜주는 부가기능을 이용하며,
Cross Cutting Concerns라고 한다. - AOP는 각 레이어의 핵심 기능, 로직과 부가기능을 분리해서 프로그램을 만들 수 있게 해주는 방식.
핵심 비즈니스로직과 부가기능을 분리하되, 쉽게 부가기능을 추가할 수 있게 해주는 것이 핵심이다.
JPA(Java Persistence API)
- Java 애플리케이션에서는 JDBC API를 이용해 데이터 저장 계층에 접근하게 되어 있다.
JDBC API 인터페이스는 JDBC 드라이버라는 각각의 구현체를 통해 동일한 인터페이스로 구현된다.
JDBC Template
- JDBC Template을 이용해 데이터 계층에 접근이 가능.
기존 JDBC 이용시의 반복적인 작업을 JDBC Template이 대신 수행해준다. - JDBC Template이 제고아는 여러 메서드를 이용해 손쉽게 결과 조작이 가능하다.
Mybatis
- JDBC의 반복적인 쿼리 작업을 수행해주는 QueryMapper
- 자바 코드와 쿼리를 분리해줘, 쿼리 수정으로 자바 코드 수정이나 컴파일하는 작업을 하지 않아도 된다.
사용 이유
- 생산성 증진
- SQL에 의존적인 개발에서 벗어나, 객체 중심의 생산적인 개발이 가능하게 됨.
- 객체와 관계형 테이블의 패러다임 불일치
- 객체지향 프로그래밍은 추상화/캡슐화/상속/다형성 등을 지원하지만,
RDB는 데이터 중심으로 구조화되어 있으며, OOP의 특성을 지원하지 않음.
- 객체지향 프로그래밍은 추상화/캡슐화/상속/다형성 등을 지원하지만,
Entity라는 객체가 RDB의 테이브로가 맵핑이 되며 추상화/캡슐화/상속/다형성 등 객체지향 프로그래밍의 특징을 사용할 수 있게 되었다.
