데이터 베이스는 왜 필요한가?
- 데이터 베이스를 활용하면 IT서비스를 만드는데 필요한 다양한 정보, 사용자 정보들을 기록할 수 있다.
모든 서비스는 데이터를 만들고, 이는 기록되고 저장되어야 한다.
- 이러한 정보(회원, 구매, 서비스이용, 리뷰 등)들이 기록되어야 서비스를 운영하고 발전시킬 수 있다.
- 장기적으로는 머신러닝 인공지능 등에 활용도 가능.
데이터 베이스의 종류
- 관계형 데이터베이스 :
- 프로덕션 관계형 데이터베이스
- 데이터 웨어하우스 관계형 데이터베이스
- 비관계형 데이터베이스 : 비구조화 데이터베이스라고 부르기도 함.
- 흔히 NoSQL 데이터베이스라고 부르기도 함.
- 데이터가 테이블 형태로 깔끔하게 구조화되지 않았다는 뉘앙스를 함의함.
- 보통 프로덕션용 관계형 데이터베이스를 보완하기 위한 용도로 많이 사용됨.
- 크게 4가지 종류가 존재.
: Key/Value Storage. Document Store. Wide Column Storage. Search Engine.
관계형 데이터베이스의 종류
- 관계형 데이터베이스
- 정보들을 다수의 테이블로 나눠서 저장하는 데이터베이스.
- IT 서비스 운영에 좋음.
- 프로덕션 관계형 데이터베이스 (RDBMS)
- MySQL, PostgreSQL, Oracle..
- 빠른 처리 속도에 집중.
- 데이터가 많이 쌓이거나, 서버가 좋지 않다거나, 최적화가 되지 않았다거나 하는 이유로 처리 속도가 느려질 수 있다.
속도가 느려지면 서비스 품질이 낮아져, 서비스 경험이 저하될 가능성이 높다.
- 데이터 웨어하우스 관계형 데이터베이스
- Redshift, Snowflake, BigQuery, Hive..
- OLAP(OnLine Analytical Processing)
- 회사 관련 데이터를 저장하고 분석함으로써 의사결정과 서비스 최적화에 사용.
- 데이터 분석, 모델 빌딩등을 위한 데이터 저장.
- 처리속도 보다는 구조화된 큰 데이터를 처리하는 것이 중요.
- 얼마나 많은 데이터를 저장하고 처리할 수 있는가? => Scale Ability
- 데이터 직군이라면 반드시 알아야 하는 분야.
- 데이터 엔지니어, 데이터 분석가, 데이터 과학자 등등.
이러한 관계형 데이터베이스의 프로그래밍 언어가 SQL
프런트엔드와 백엔드
웹/앱 서비스를 간단히 나누면 크게 프런트엔드와 백엔드로 구분됨.
- 프런트엔드 : 사용자와 상호작용을 하는 부분으로 보통 웹 브라우저 혹은 폰의 사용자에게 노출되는 서비스를 말함.
UI 등 디자인적 측면이 강함. - 백엔드 : 프런트엔드 뒤에 있어 사용자에게 보이지는 않지만, 실제 데이터베이스를 저장/추가하고 사용자가 요구한 일을 수행하는 부분.
서버, 데이터베이스 등의 기술이 요구됨.
추후 추가된 직군들
- 데브옵스(DevOps) : 주로 백엔드에 집중을 두고, 서비스의 운영을 책임지는 팀. 회사가 작을 때는 보통 백엔드 팀이 이 일을 담당.
- 풀스택(FullStack) : 개발 속도를 내기 위해 프런트/백엔드를 모두 할 수 있는 개발자.
- 데이터 직군.
- 데이터 엔지니어 : 사실상 소프트웨어 개발자. 데이터 웨어하우스와 관련된 일을 담당.
- MLOps : 머신러닝과 Launch 담당.
- 데이터 분석가 : 데이터 웨어하우스를 기반으로 다양한 지표설정과 분석 수행.
- 데이터 과학자 : 수집된 과거 데이터를 기반으로 미래를 예측하는 모델링 개인화 작업을 통해 서비스의 만족도를 높이고 프로세스 최적화를 수행.
- 데이터 엔지니어 : 사실상 소프트웨어 개발자. 데이터 웨어하우스와 관련된 일을 담당.
시스템 구성의 변화
- 2tier
- 보통 데스크탑 응용프로그램에서 사용되는 아키텍쳐.
- 클라이언트와 서버 두 개의 티어로 구성된다.
- 클라이언트는 사용자가 사용하는 UI가 됨.(front-end)
비즈니스 로직은 보통 클라이언트에 위치. - 서버단이 데이터베이스가 됨.(back-end)
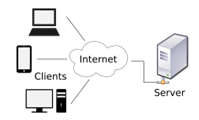
- 클라이언트는 사용자가 사용하는 UI가 됨.(front-end)
- 3tier
- 웹 서비스에서 많이 사용되는 아키텍쳐.
- 프레젠테이션 티어(Presentation) : 사용자와 상호작용 -> 프런트 엔드
- 애플리케이션 티어(Application) : 데이터 처리와 연산 -> 백엔드
- 데이터 티어 (Data) : 데이터 저장, 제공 -> 백엔드
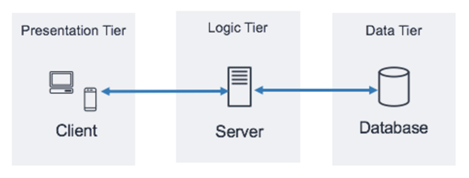
관계형 데이터베이스란?
관계형 데이터베이스 :
구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지
- 엑셀 스트레드시트 형태의 테이블로 데이터를 정의하고 저장.
- 테이블에는 컬럼(열)과 레코드(행)이 존재.
- 테이블을 어떻게 디자인하는지도 중요하다.
관계형 데이터베이스를 조작하는 프로그래밍 언어가 SQL
- 테이블 정의를 위한 DDL.
테이블의 포맷을 정의해주는 언어. - 테이블 데이터 조작/질의를 위한 DML.
DDL로 정의된 테이블에 레코드를 추가, 수정, 삭제 혹은 읽어들이기 위한 언어.
관계형 데이터베이스의 구조.
2단계로 구성됨.
- 가장 밑단에는 테이블들이 존재.
테이블은 엑셀의 시트에 해당.
- 테이블들은 데이터베이스(혹은 스키마)라는 폴더 밑으로 구성.
엑셀의 파일에 해당.
데이터베이스, 디렉토리, 스키마 등등은 폴더를 이르는 다른 이름.
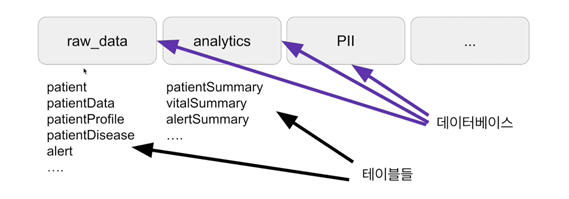
- 테이블의 성질, 특성 등에 따라 특별한 폴더를 만들어서 데이터의 관리를 조금 쉽게 할 수 있다.
예시) 개인정보 등 접근을 제한하고 보호해햐 하는 정보의 경우, 비밀 폴더를 만들고 거기에 넣어 접근을 제한할 수 있다.
- 테이블의 구조(테이블 스키마)
* 테이블은 레코드들도 구성(행)
- 레코드는 하나 이상의 필드(컬럼)로 구성(열)
- 필드(컬럼)는 이름과 타입과 속성으로 구성됨.
(primary key, 식별자(공통되지 않는 정보)로 사용 가능)

SQL
SQL : Structure Query Language
- 관계형 데이터베이스에 있는 데이터(테이블)을 질의하거나 조작해주는 언어.
- SQL은 1970년대 초반에 IBM이 개발한 구조화된 데이터 질의 언어.
- 두 종류의 언어로 구성.
- DDL(Data Definition Language) : 테이블의 구조를 정의하는 언어.
- DML(Data Manipulation Language) : 테이블에서 원하는 레코드들을 읽어오거나, 레코드를 추가/삭제/갱신하는데 사용하는 언어.
SQL의 단점
- 구조화된 데이터를 다루는데 최적화.
정규 표현식을 통해 비구조화된 데이터를 어느 정도 다루는 것은 가능하지만, 제약이 심하다. - 많은 관계형 데이터베이스들이 플랫한 구조를 지원함. (no nested)
- 비구조화된 데이터를 다루는데 Spark, Hadoop과 같은 분산 컴퓨팅 환경이 필요해짐.
즉 SQL만으로는 비구조화 데이터를 처리하지 못함. - 관계형 데이터베이스마다 SQL 문법이 조금씩 상이.
하지만 하나를 잘 배워두면 다른 것을 배우는 것은 그렇게 어렵지 않다(고 한다.)
스키마 형태의 종류
- Star schema
Production DB용 관계형 데이터베이스에서는 보통 스타 스키마를 사용해 데이터를 저장.
데이터를 논리적 단위로 나눠 저장하고 필요 시 Join.
스토리지 낭비가 덜하고 업데이트 쉬움.
단점 : Join을 하는 과정에서 시간과 리소스를 할애할 수 있음. - Denormalized schema
NoSQL이나 데이터 웨어하우스에서 사용하는 방식.
단위 테이블로 나눠 저장하지 않음으로 별도의 조인이 필요 없는 형태.
이는 스토리지를 더 사용하지만, 조인이 필요 없기에 빠른 계산이 가능.
단점 : 수정하는 것이 어려움.
