새로운 VM 만들기
- 새 과제를 시작하기 전에 새로운 마음으로 VM을 만들어주자.
CentOS의 DVD 버전을 사용해준다.
참고
💻블록스토리지 증설 및 마운트
VM 스토리지 추가
- 최초 VM을 만들 때, 실수로 혹은 일부러 스토리지를 작게 설정할 수 있다. 이럴때는 설정을 통해 스토리지를 추가해 줄 수 있다.
참고
1. 서버에 하드 추가하기
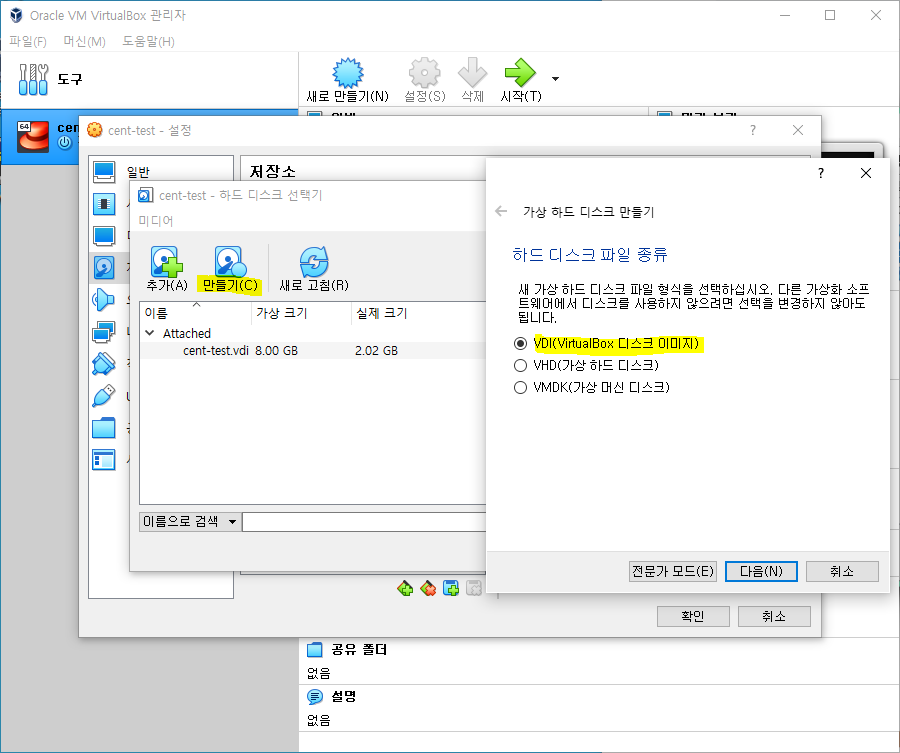
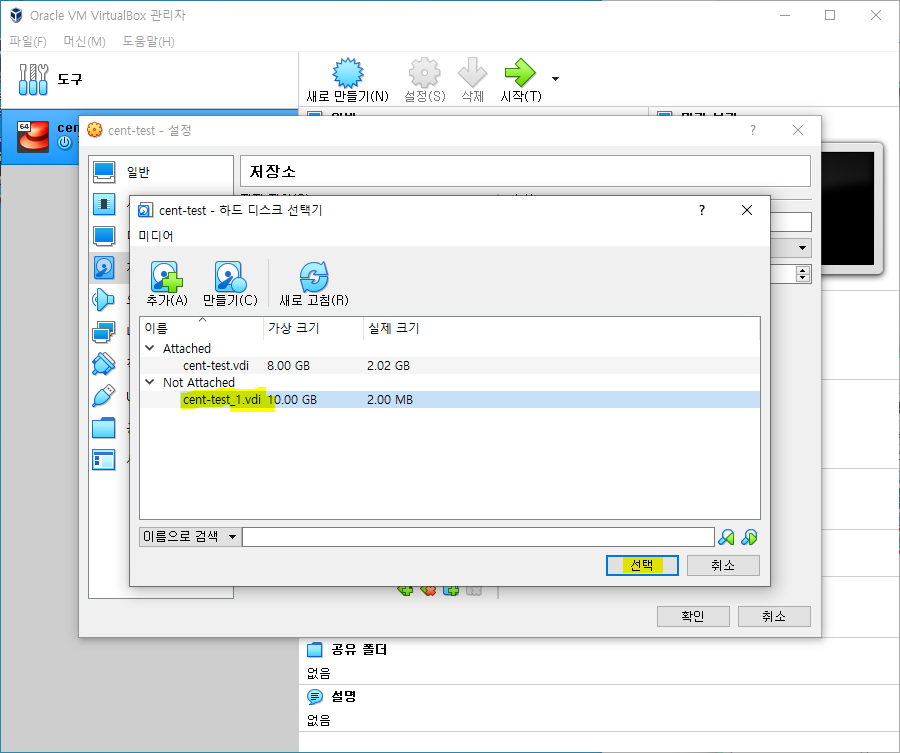
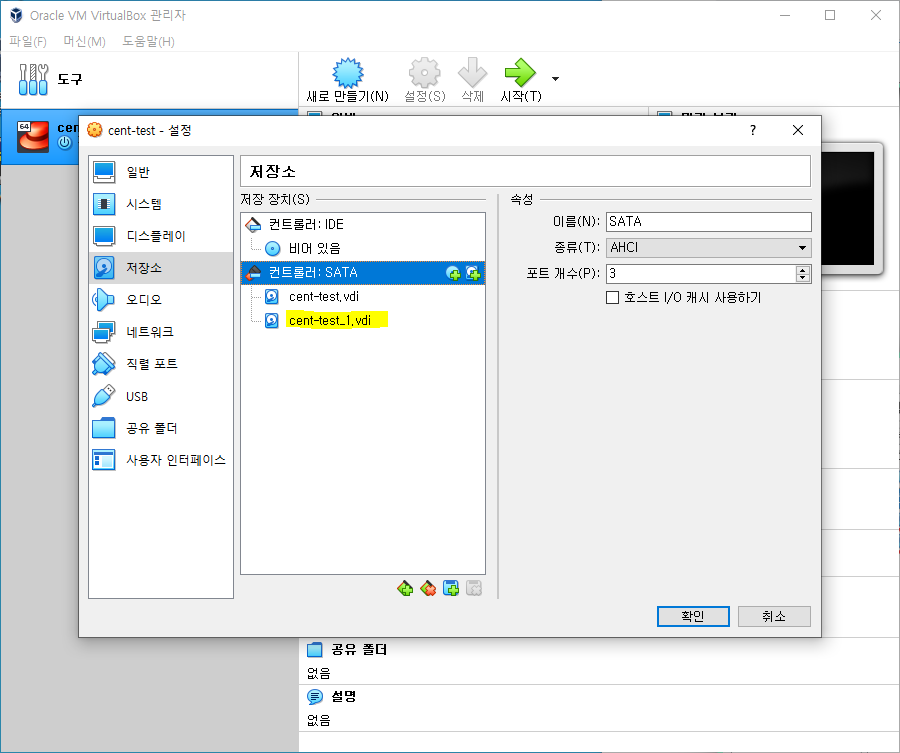
2. 디스크 추가 확인
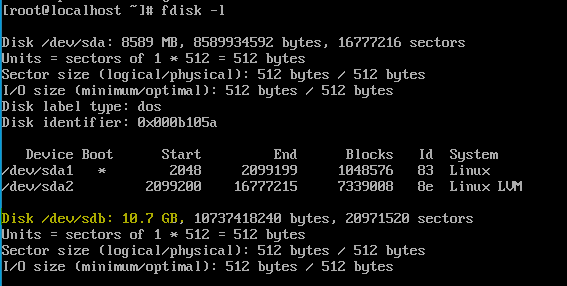
3. 파티션 생성하기
fdisk명령어를 사용해 sdb 디스크의 파티션 설정으로 들어가자.
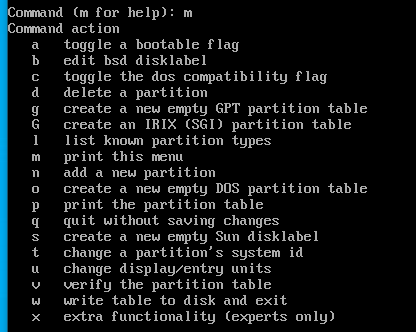
- m 을 누르면 전체 메뉴를 확인할 수 있다.
- n 을 누르면 새로운 파티션을 생성할 수 있다.
종류는 두가지 Primary와 Extended가 있다.
- 일반적으로 하드디스크 하나에는 총 4개의 파티션까지 생성이 가능하다.
근데 5개 이상의 파티션 구성이 필요하면 어떡할까?
1~3번 까지의 파티션을 Primary 타입으로 생성하고, 4번 파티션을 extended 타입으로 생성한 뒤 해당 파티션 안에서 logical 파티션을 생성하면 된다.
- 즉, Extended 파티션은 5개 이상의 파티션을 생성하기 위한 logical 파티션의 껍데기라고 생각하면 된다.
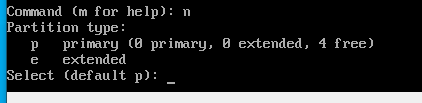
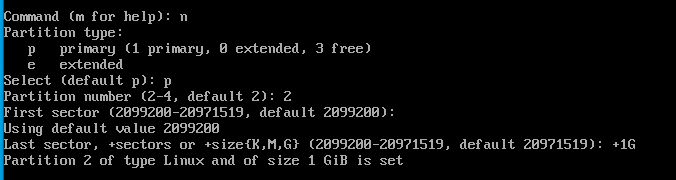
- p 를 입력해서 primary 파티션을 생성한다.
- 다음은 파티션의 용량을 정하는 부분이다.
첫 번째 섹터를 입력해준다. 그냥 엔터를 누르면 디폴트인 2048 섹터부터 시작하게 된다.
또다시 엔터를 누르면 디폴트로 마지막 섹터가 입력되고 디스크 하나가 통째로 하나의 파티션이 된다.
1기가만 추가해서 생성하자.

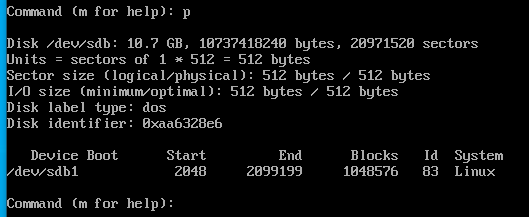
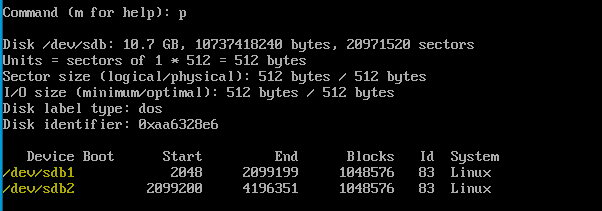
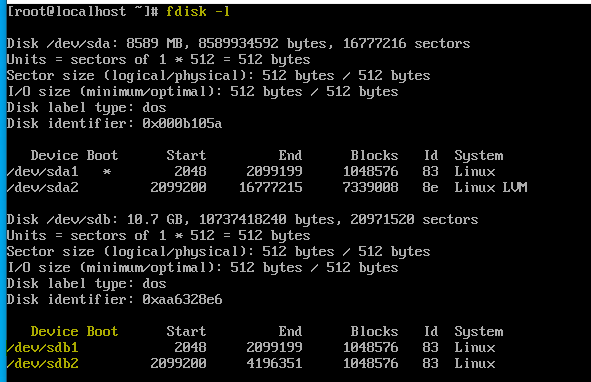
fdisk -l 명령어를 통해 확인해주자 아까와는 다르게 파티션이 나뉘어 있는 것을 확인할 수 있다.
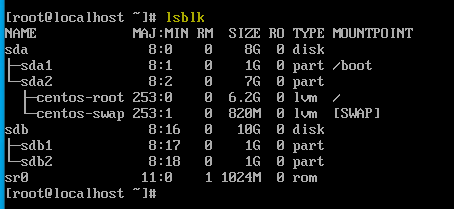
lsblk를 사용해서 트리 형태로도 볼 수 있다.
4. 파일 시스템 포맷 및 마운트
- 아직 끝이 아니다. 생성한 파티션을 사용하려면 포맷을 해야한다.
xfs 파일 시스템으로 포맷을 진행하자.
# mkfs.xfs /dev/sdb1
- 파티션을 연결할 디렉터리를 생성하고 마운트 해준다.
# mkdir /mnt/data_dir
# mount /dev/sdb1 /mnt/data_dir
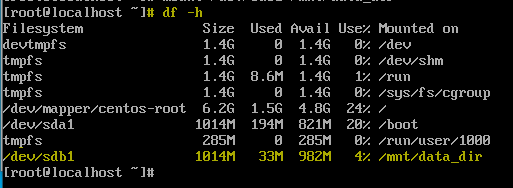
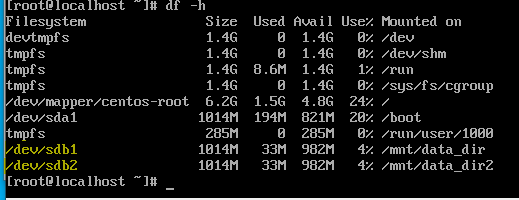
/etc/fstab에 추가하여 부팅 시 자동으로 마운트 되도록 설정할수 있다.
ncloud 환경으로 이행
- ncloud 환경으로 바꿔서 실습을 진행해보도록 하자.
1. 서버 생성
2. 스토리지 생성
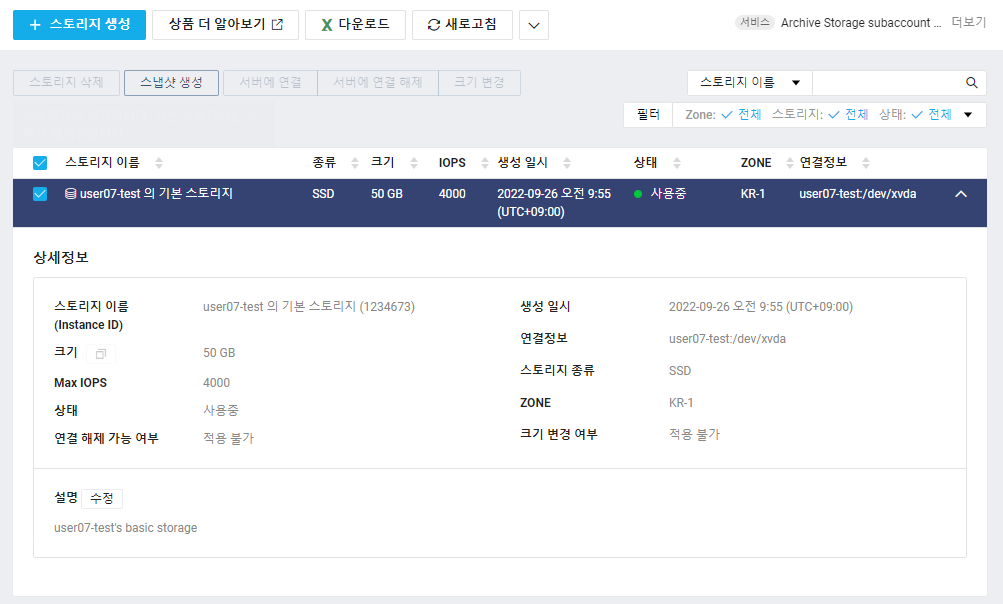
- 기본적으로 스토리지가 할당된다.
당연히, 최소한 OS가 설치될 스토리지 정도는 갖추고 있어야 하기 때문.
- 스토리지를 추가해보자.
스토리지 생성 버튼을 클릭
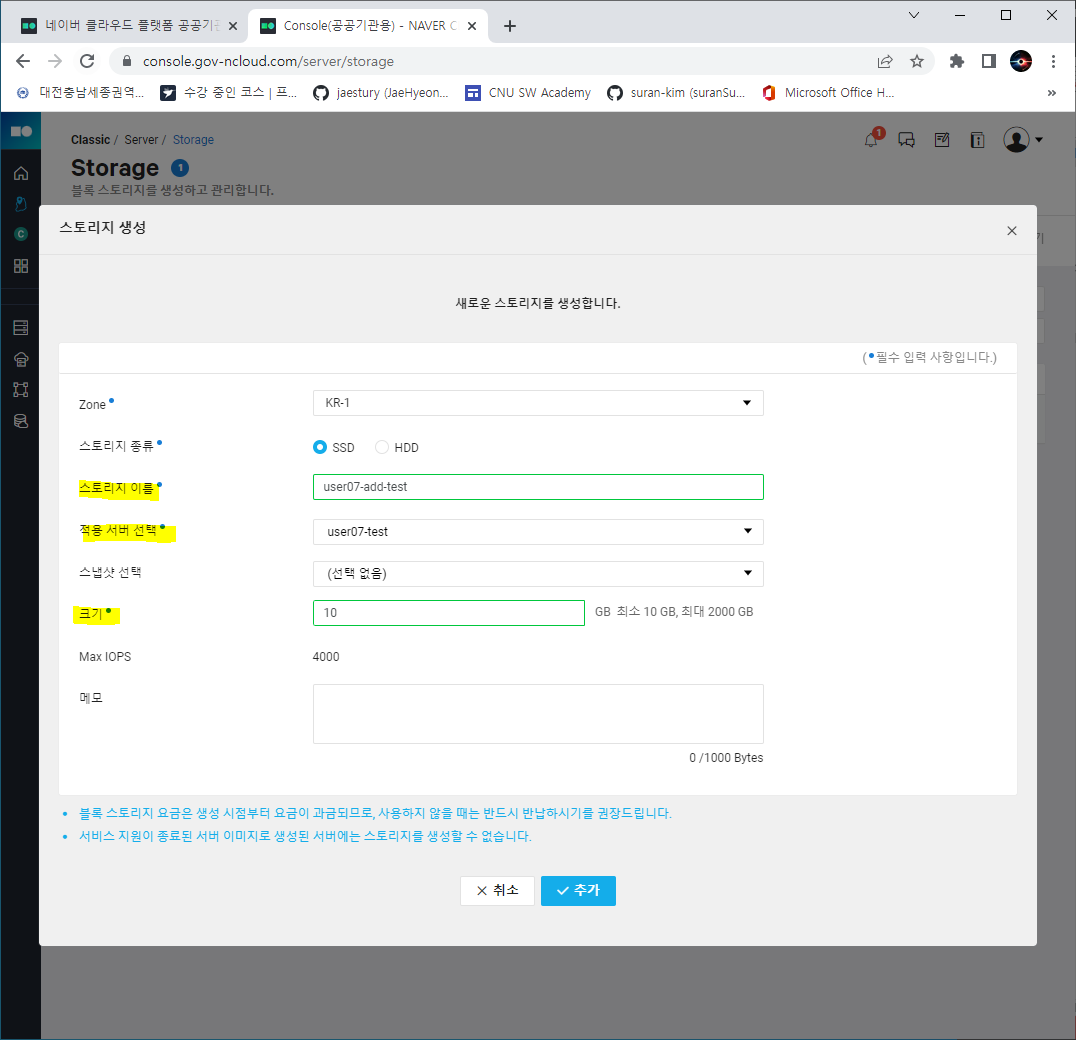
- 스토리지 이름, 적용 서버, 크기를 설정해준다.
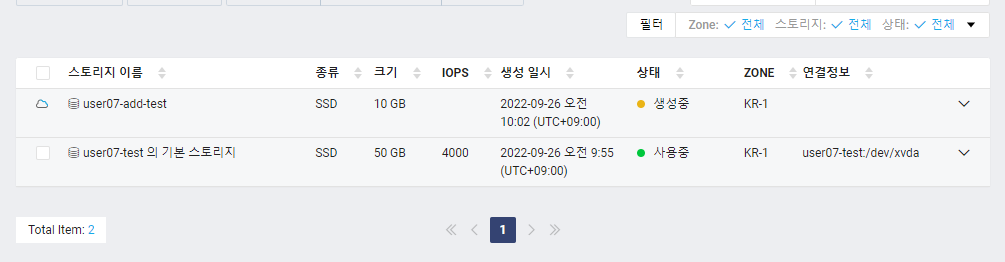
3. 스토리지와 서버 연결 확인
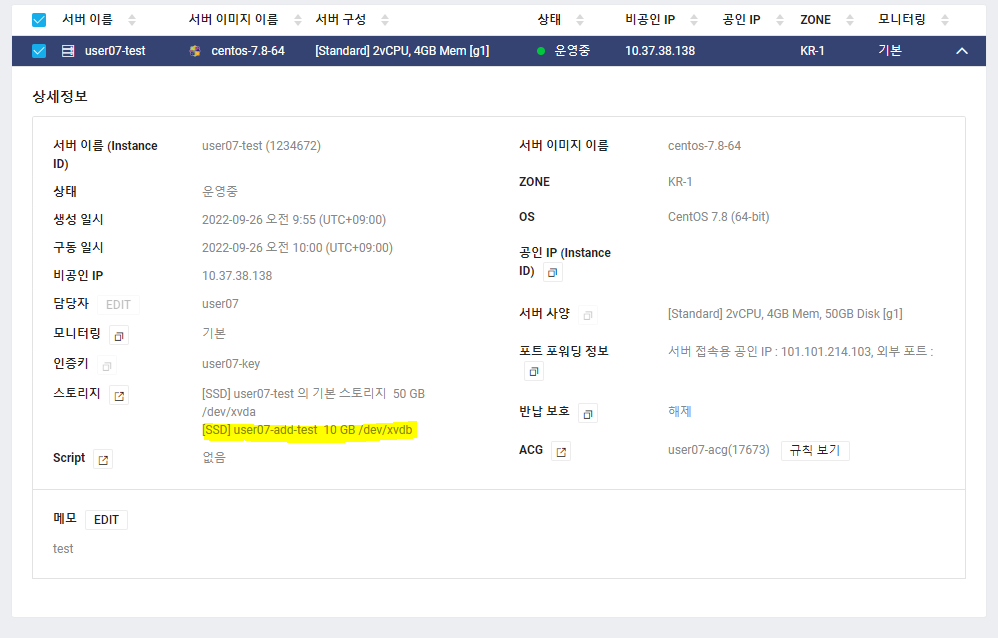
- 새로 생성된 스토리지를 확인할 수 있다.
스토리지의 경로인 dev/xvdb를 기억해두자.
- 이제 PuTTY 를 이용해서 다음 작업을 진행해야한다.
PuTTY 연결하는 과정을 알아보자.
번외 - PuTTY 서버 연결하기
- 공인 IP
- 인증키
- ACG 설정
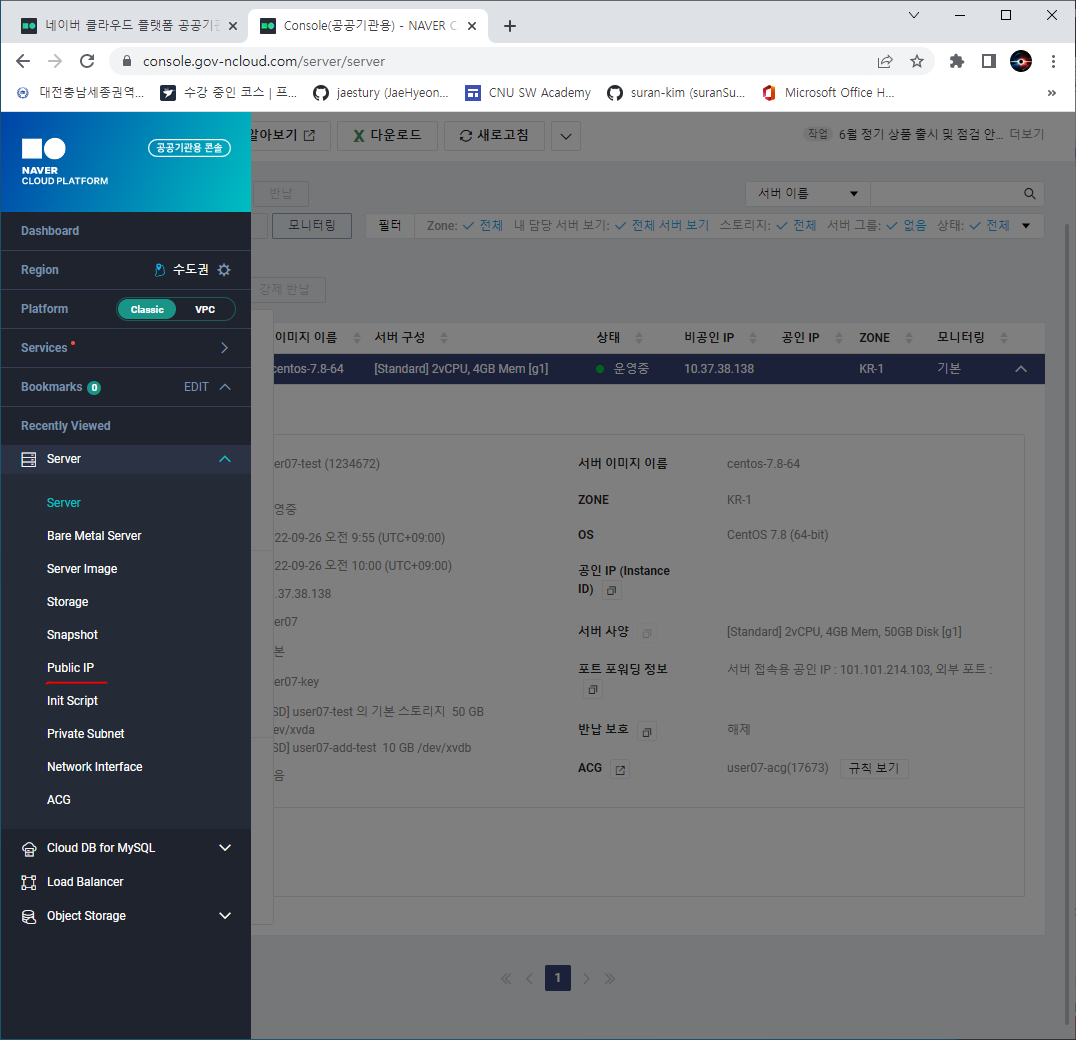
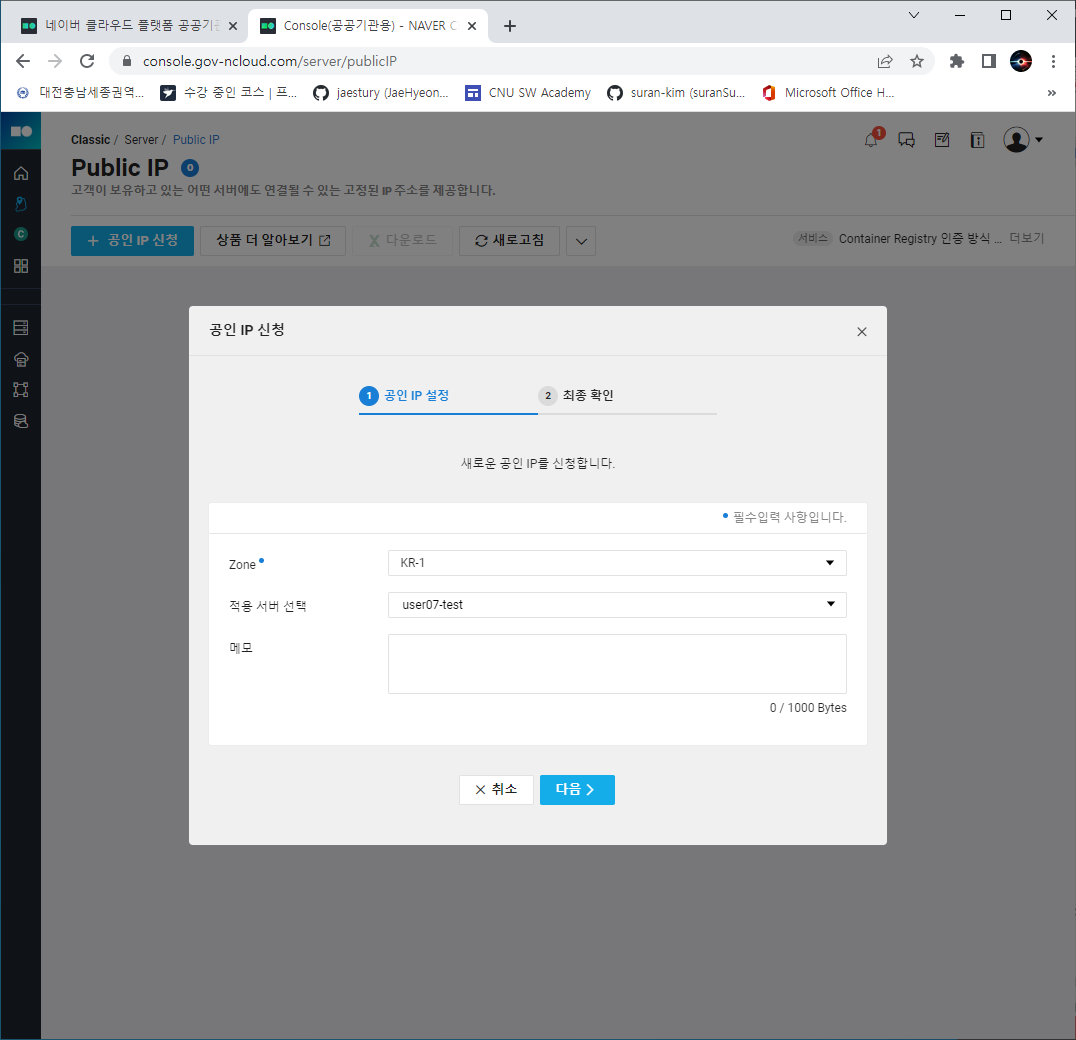
- 내가 적용할 서버에 맞춰 공인 IP신청을 해주면 끝!
- 다음은 인증키, 즉 관리자 비밀번호 확인이다.
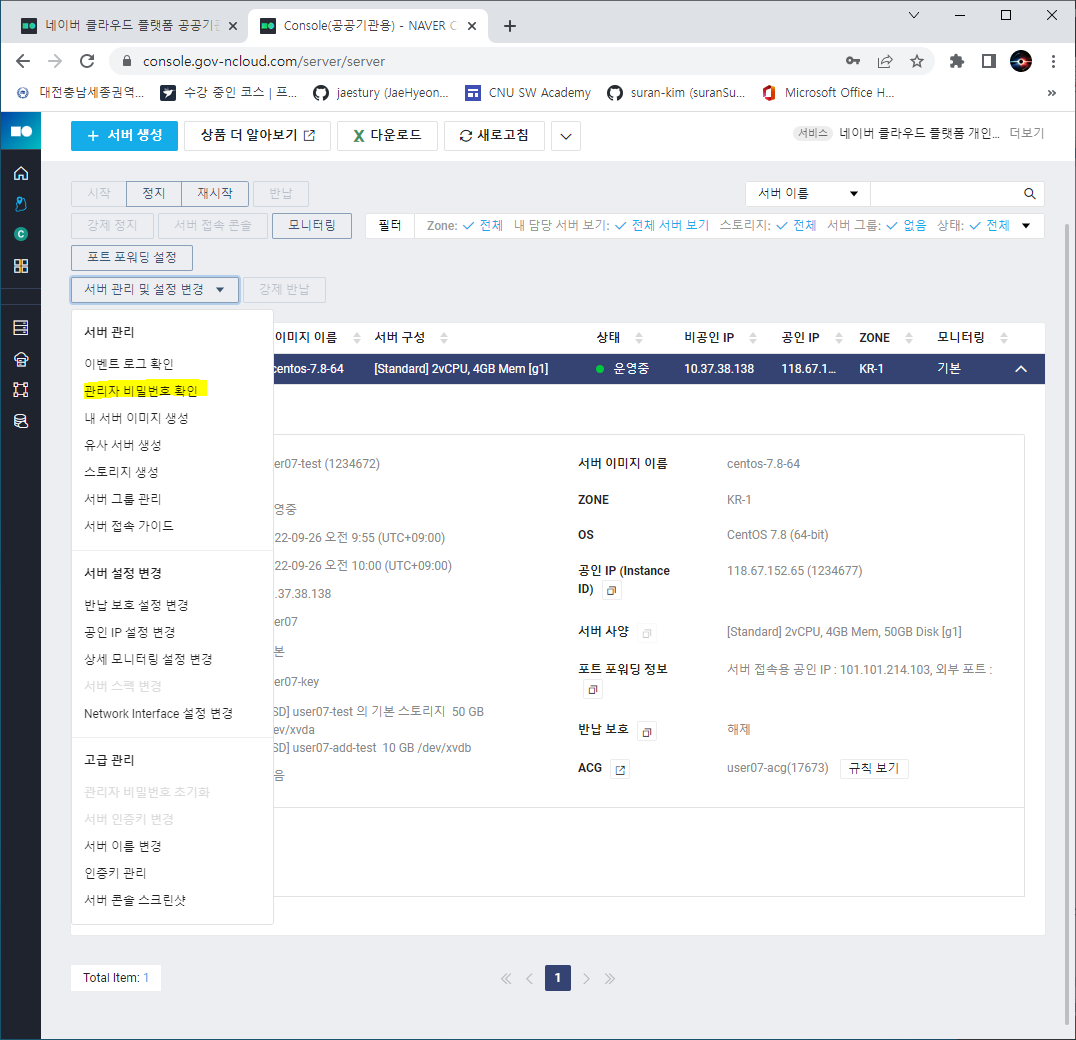
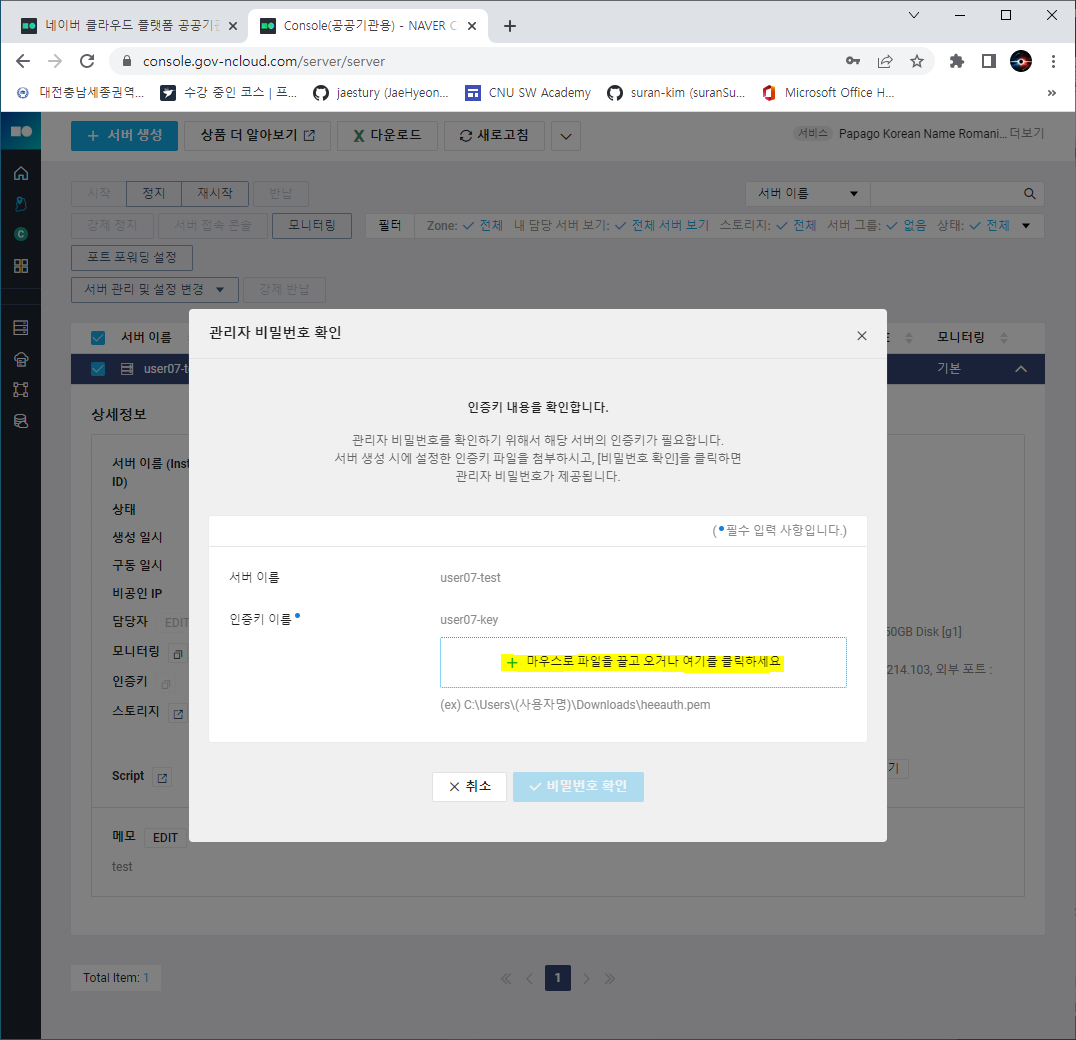
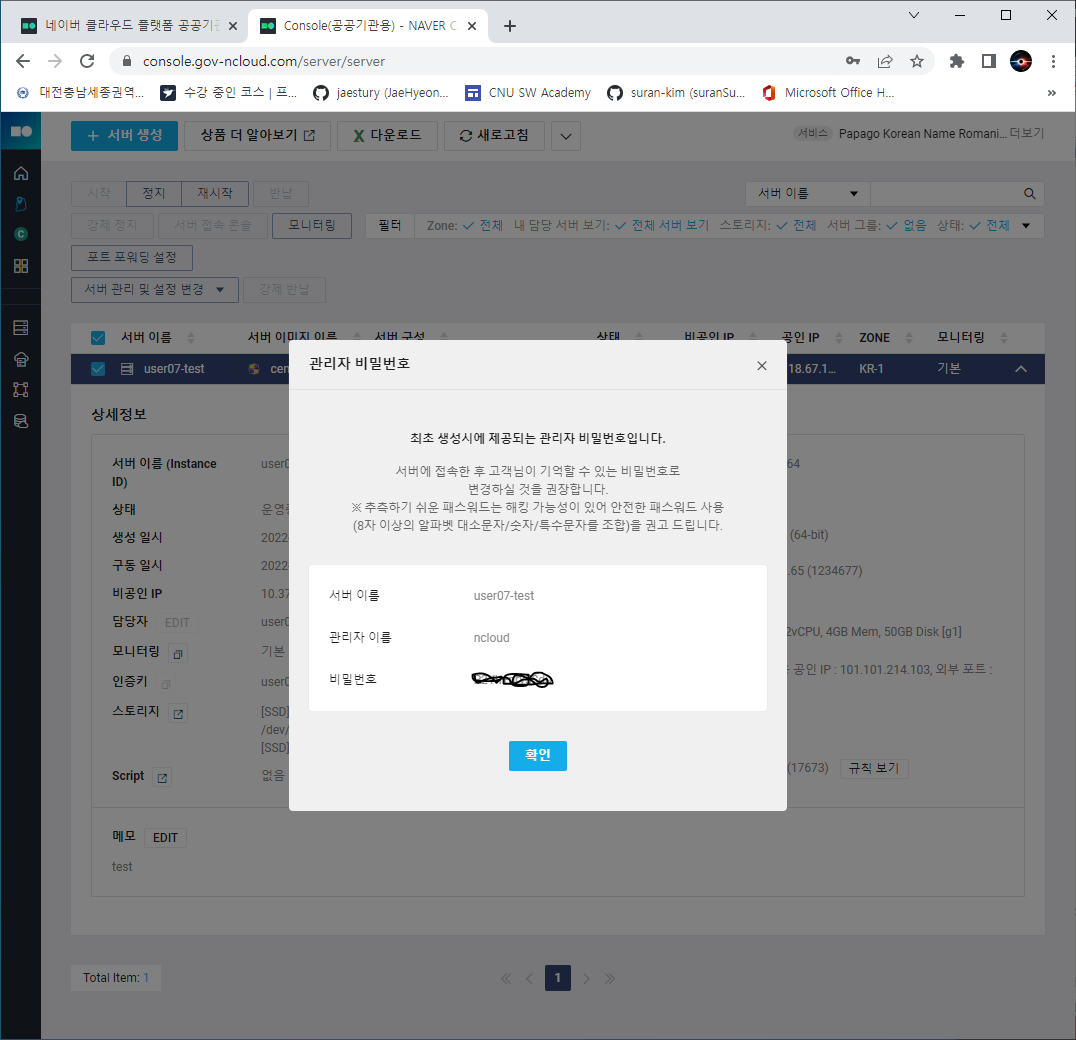
- 최초 서버를 개설할 때 생성한 인증키 파일을 이용해 관리자 비밀번호를 얻을 수 있다.
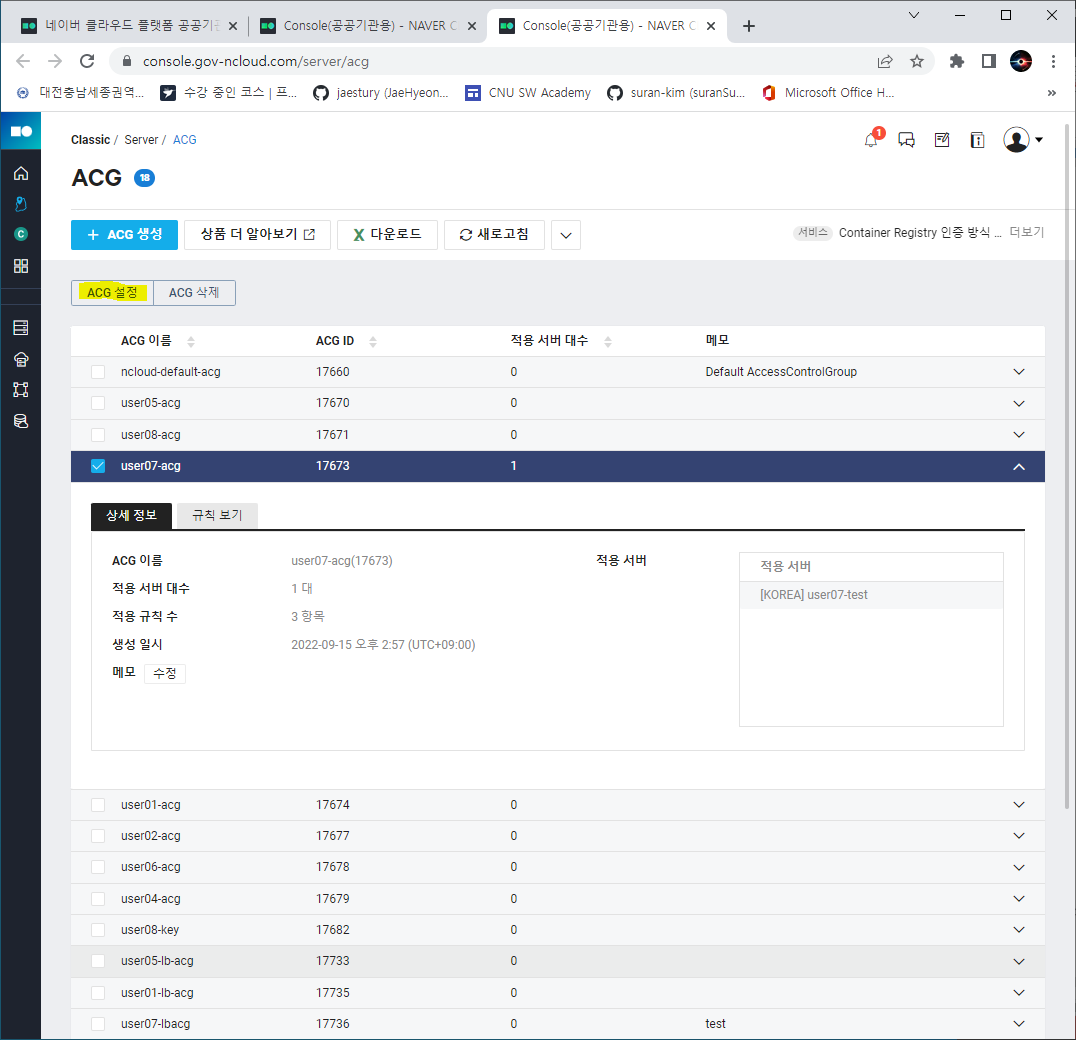
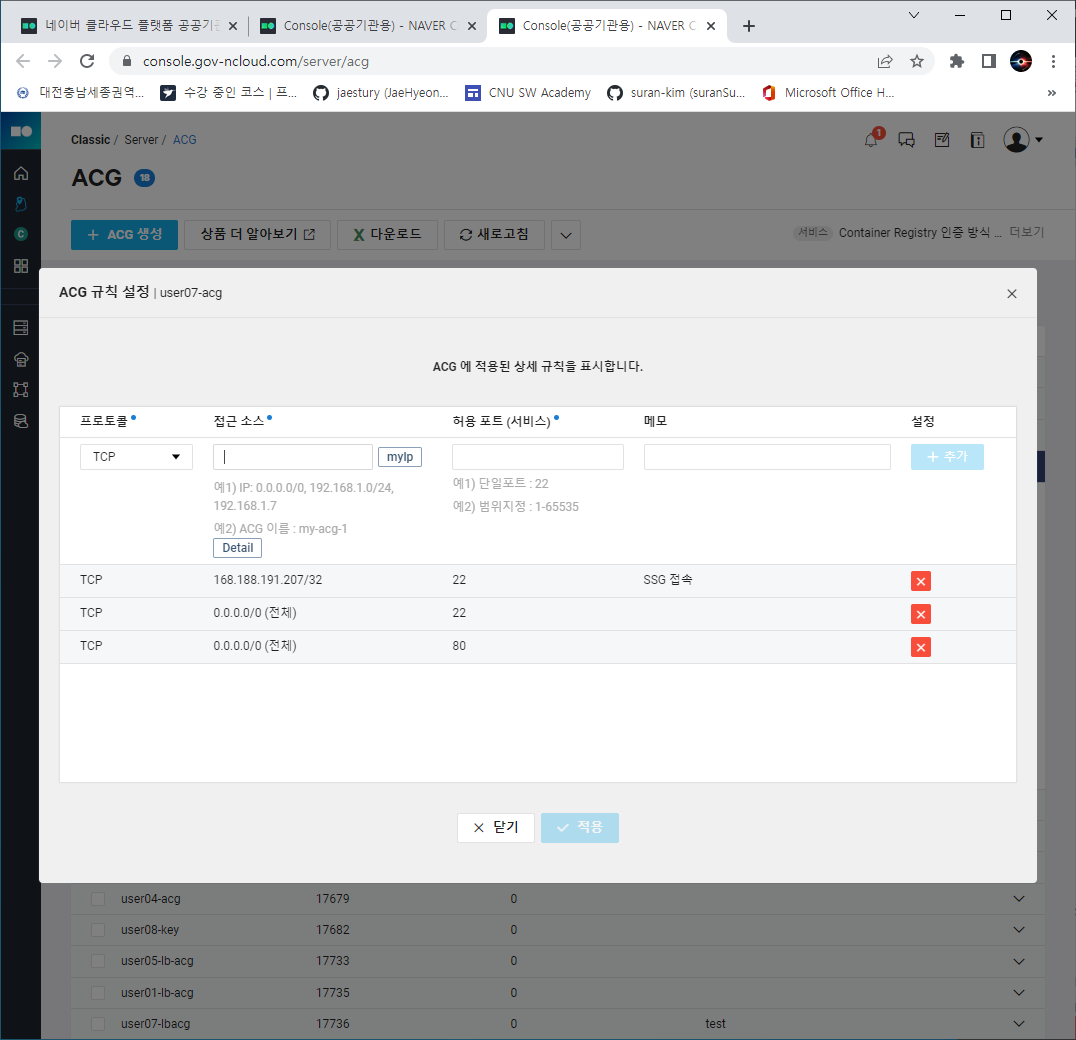
- 위와 같은 순서로 이동하여 접근 소스와 허용포트를 설정해주면 된다.
ssd 의 기본 포트가 22번이며, 원래라면 0.0.0.0/0 소스를 사용하는 것은 보안에 정말 취약하지만, 실습에 있어 보안이 중요한 상황은 아니니 그냥 추가해서 사용한다.
- 준비가 끝났으니 PuTTY를 실행해보자.
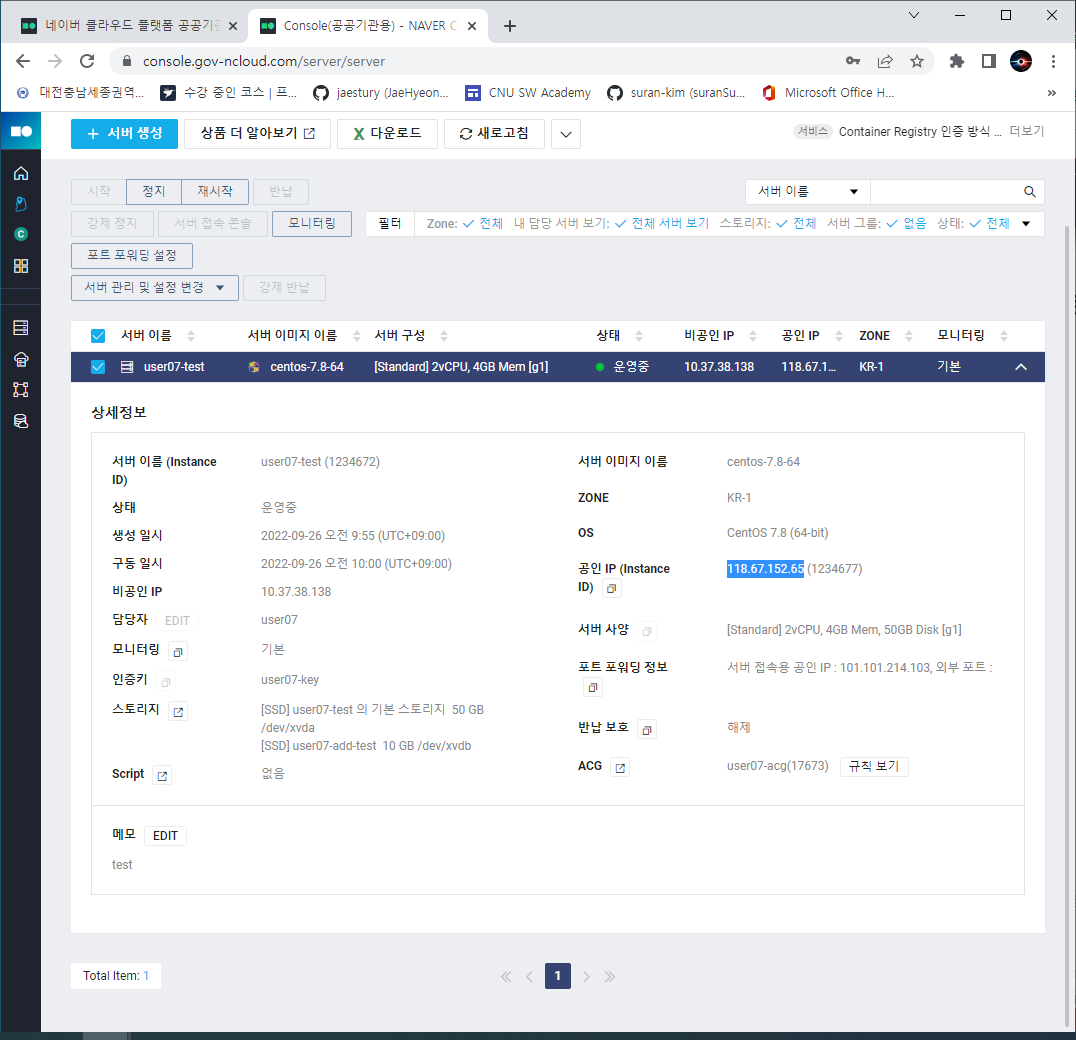
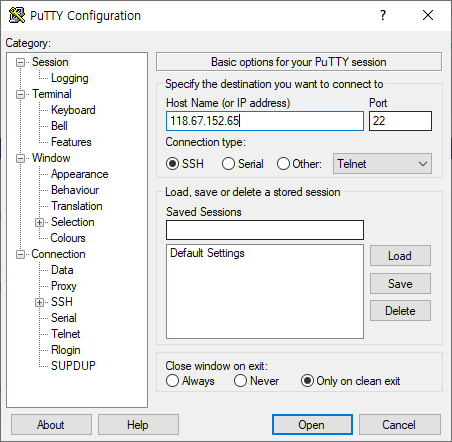
- 공인 IP를 복사해서 푸티의 Host Name에 붙여넣는다.
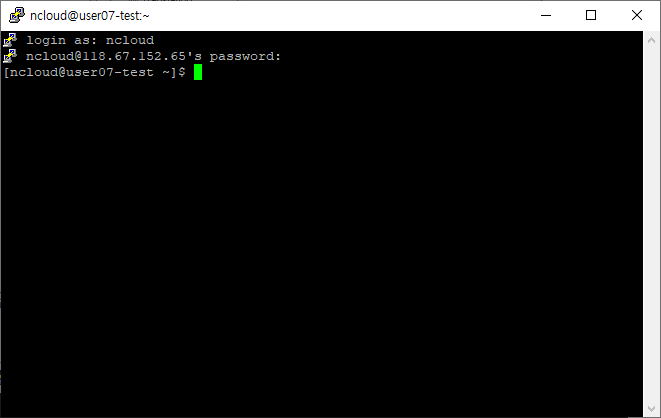
4. 추가된 스토리지 확인
- 관리자 권한이 필요하니
sudo -i를 사용해서 관리자 모드로 변경해준다.
fdisk -l을 사용해 스토리지를 확인할 수 있다.
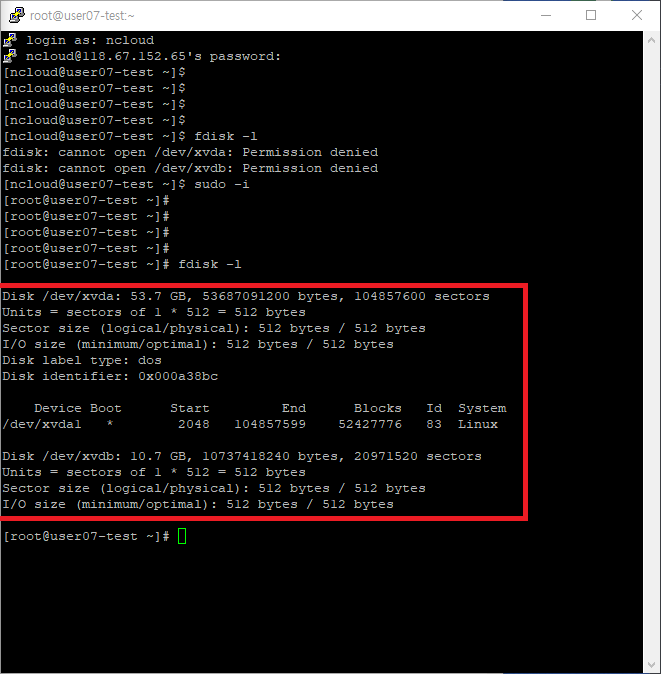
5. 디스크 파티션
fdisk /dev/xvdb를 이용해 디스크 파티션을 해주자.
위에서 한 것과 비슷하게 진행하면된다.
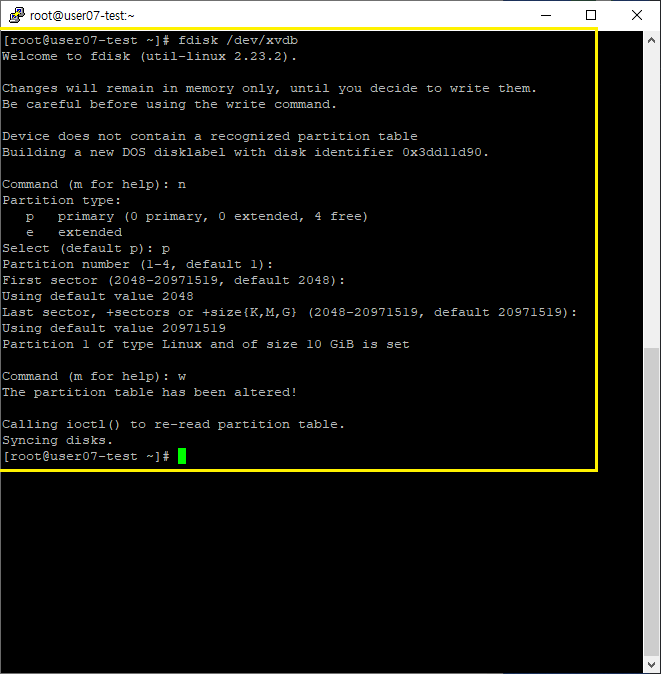
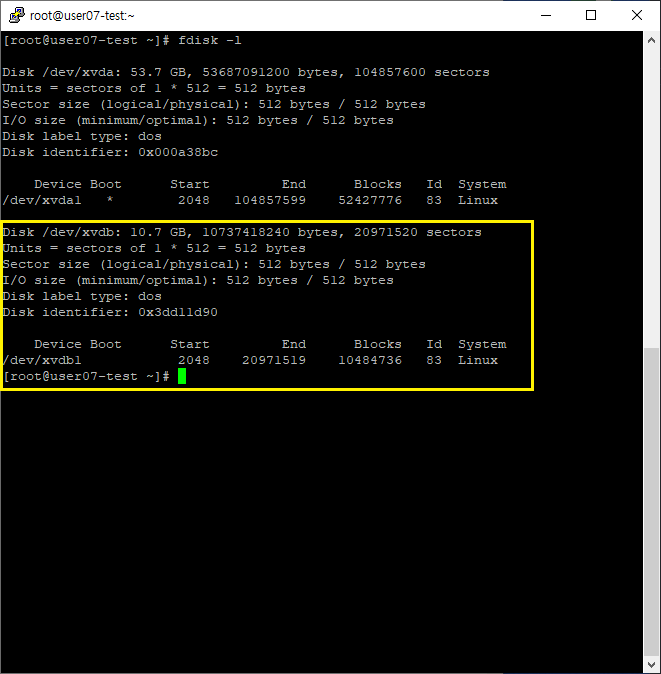
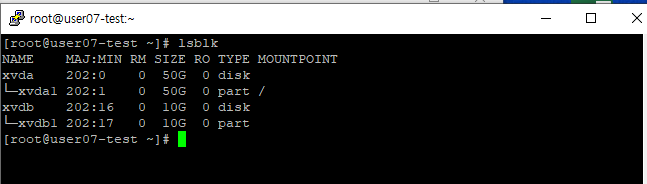
lsblk명령어를 사용하여 트리 형태로 볼 수 있다.
아까와는 다르게 파티션이 형성된 것을 볼 수 있다.
6. 스토리지 포맷 및 마운트
# mkfs.xfs /dev/xvdb1를 이용해서 스토리지 포맷.
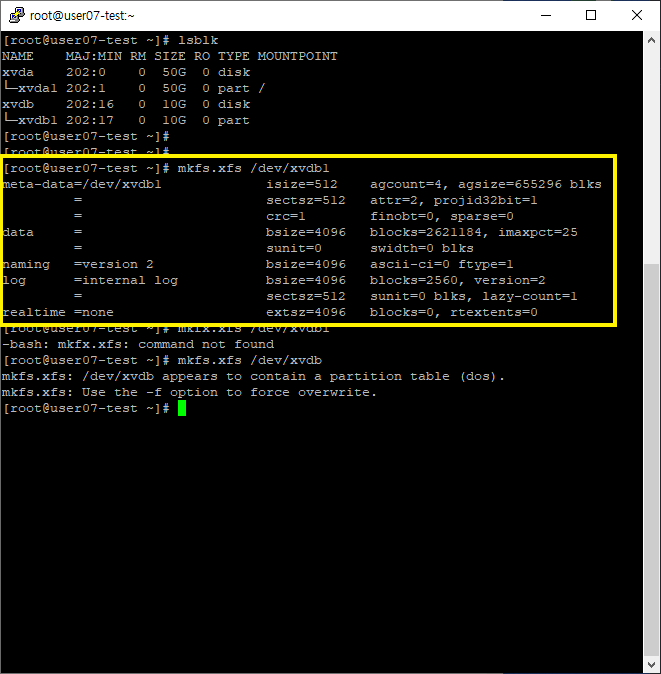
# mkdir /data 명령어로 디렉토리 설정
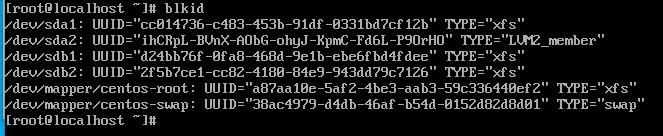
# mount /dev/xvdb1 /data 명령어로 마운트blkid 명령어로 UUID 를 확인 가능하다.
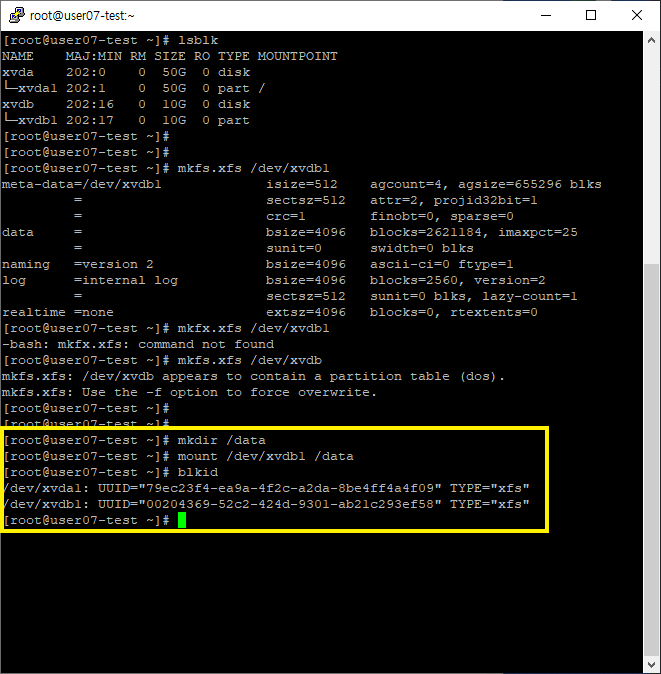
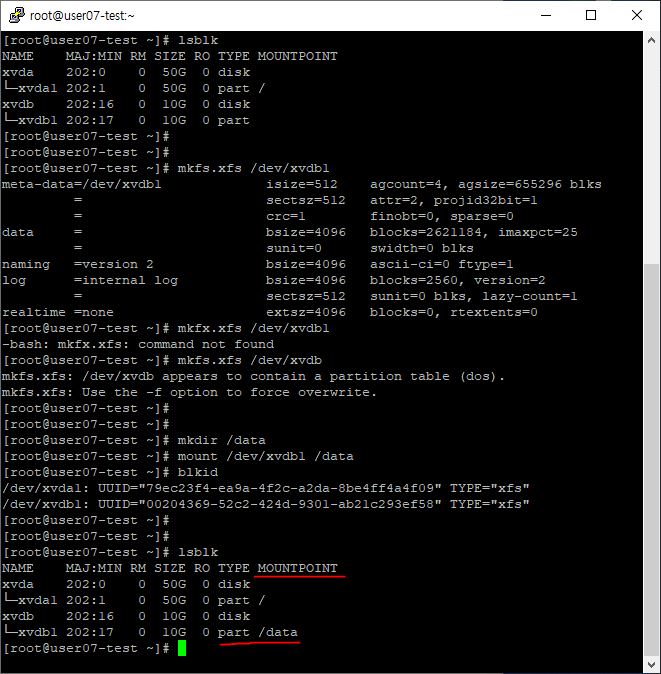
7. 정보 유지 설정
/etc/fstab에 UUID를 추가하여 재부팅시에도 마운트 정보를 유지하게 할 수 있다.
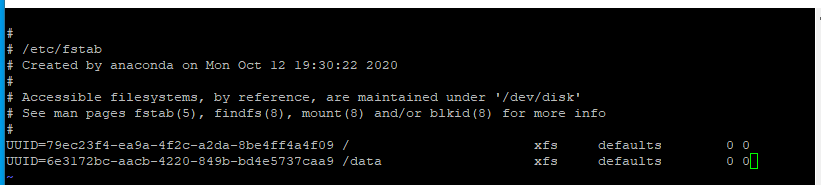
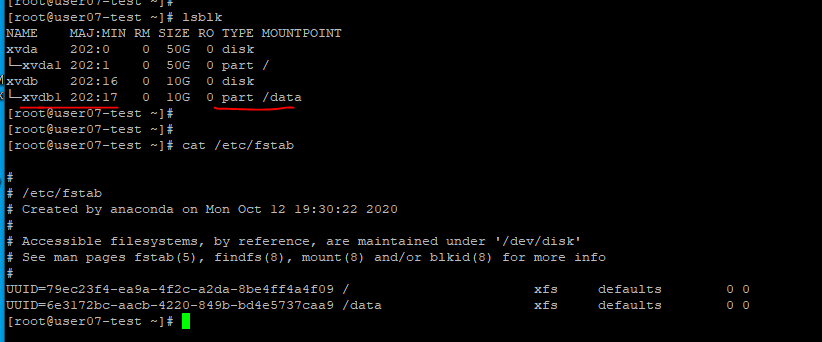
- 재부팅 후에도 상태가 유지되는 것을 확인할 수 있다.
확장구성 (LVM) 실습
1. 새로운 스토리지 추가
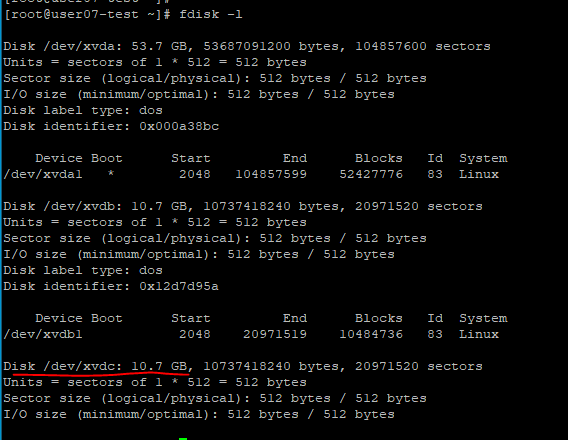
fdisk -l로 확인해보자.
문제 없이 추가 완료되었다.
2. 패키지 설치
3. 디스크 파티션
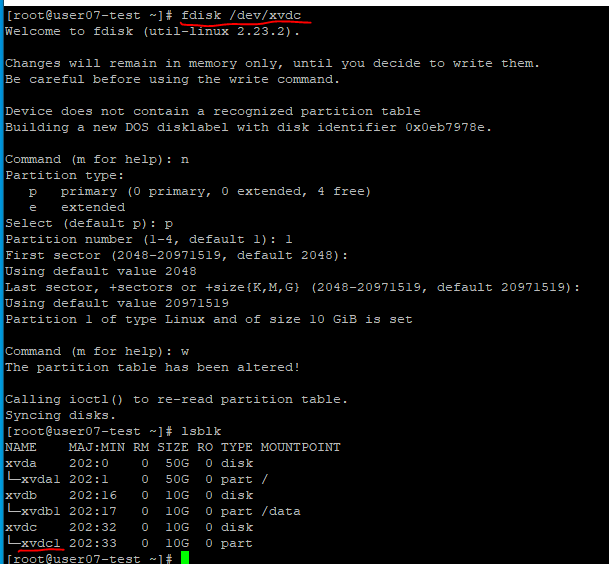
# fdisk /dev/xvdc로 디스크 파티션 진행.
xvdc1이 파티션 됐다는 것을 확인할 수 있다.- 다시 한 번 파티션을 해주어야한다.
마찬가지로 # fdisk /dev/xvdc 사용.
이번에는 t를 눌러준다. t는 파티션의 시스템 id를 바꾸는 명령어이다.
- 다음은
L을 눌러준다. L은 t 명령어의 선택가능한 목록을 열람하는 명령어이다.
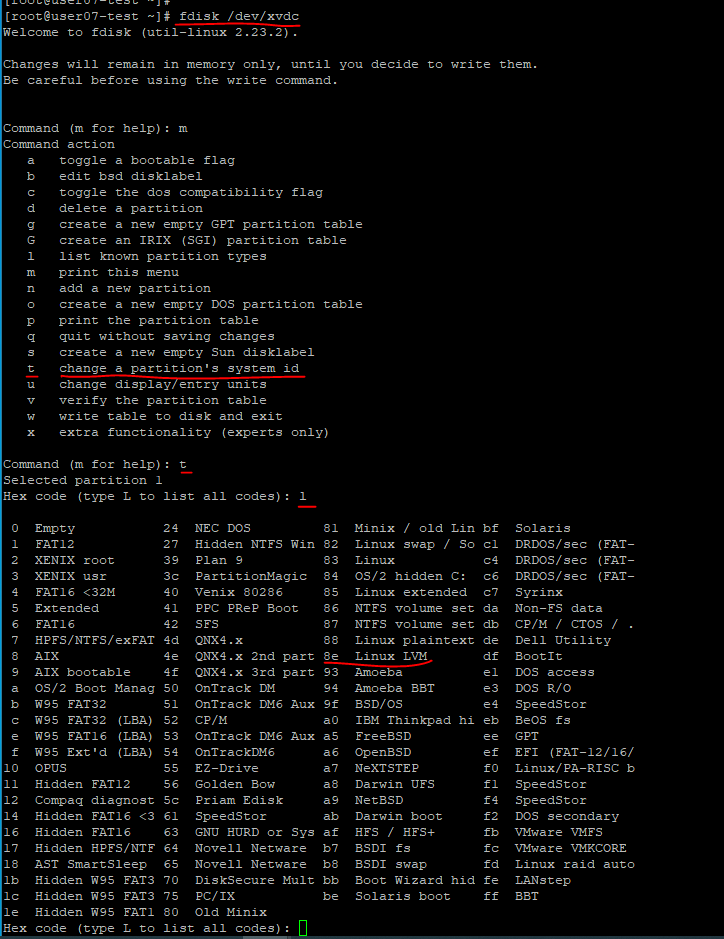
- 이번에 해볼 것은
8e명령어를 사용하는 Linux LVM이다.
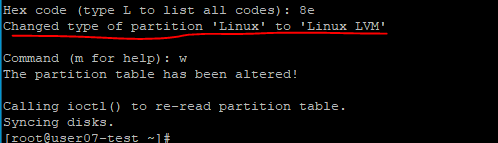
- 파티션의 타입이 Linux 에서 Linux LVM 으로 변경됐다.
w(write)를 사용해서 마무리.
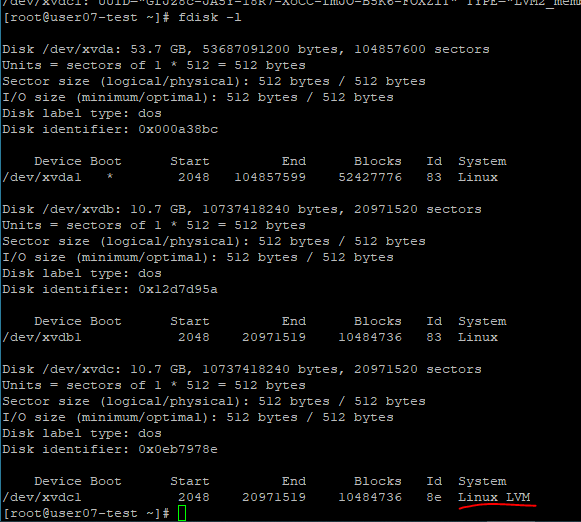
4. Physical Volume 생성

pvcreate /dev/xvdb1 명령어를 사용해서 물리적인 디스크가 LVM 데이터 구조를 사용할 수 있도록 생성해준다.
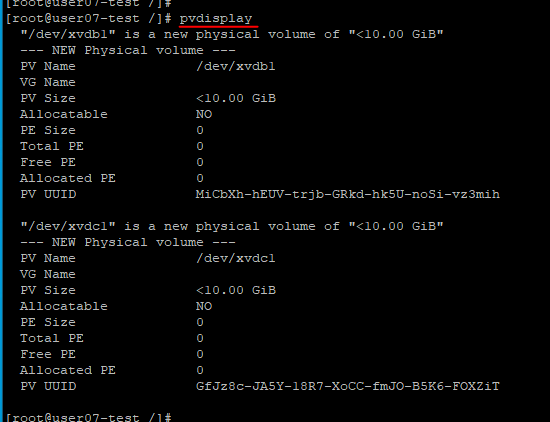
pvdispaly를 사용해서 제대로 생성되었는지 확인할 수 있다.
5. Volume Group 생성
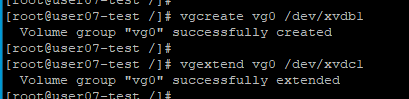
- 한 개 이상의 PV가 속해 있는 그룹을 말한다.
vgcreate vg0 /dev/xvdb1을 사용해서 생성할 수 있고
vgextend vg0 /dev/xvdc1을 사용해 확장할 수 있다.
- 물론 처음부터 두개의 Volume으로 하나의 VG를 구성할 수도 있다.
vgcreate vg0 /dev/xvdb1 /dev/xvdc1
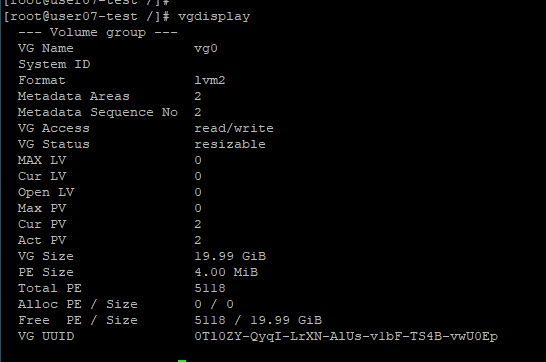
vgdisplay로 생성된 VG를 확인할 수 있다.
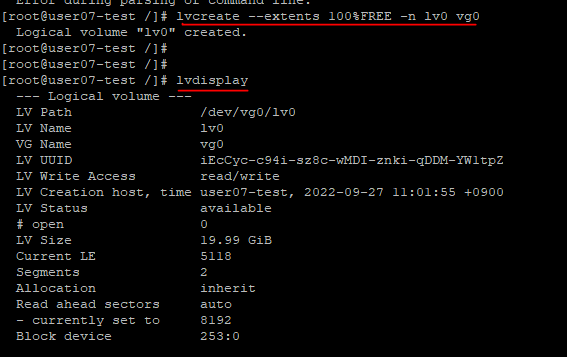
6. Logical Volume 생성
- PV, VG로 구성되어 있는 공간을 전체, 또는 분할하여 사용할 수 있도록 논리적으로 할당한 공간.
볼륨 그룹처럼 논리 볼륨에 사용하는 이름은 관리자가 결정할 수 있다.
lvcreate --extents 100%FREE -n {(만들어지는)LV 이름} {(사용되는)VG 이름}
7. 포맷 후 마운트
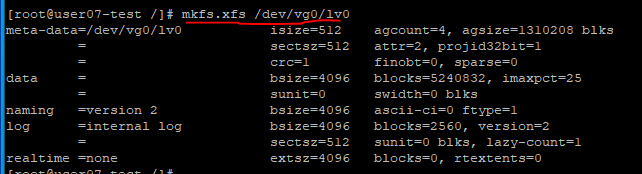
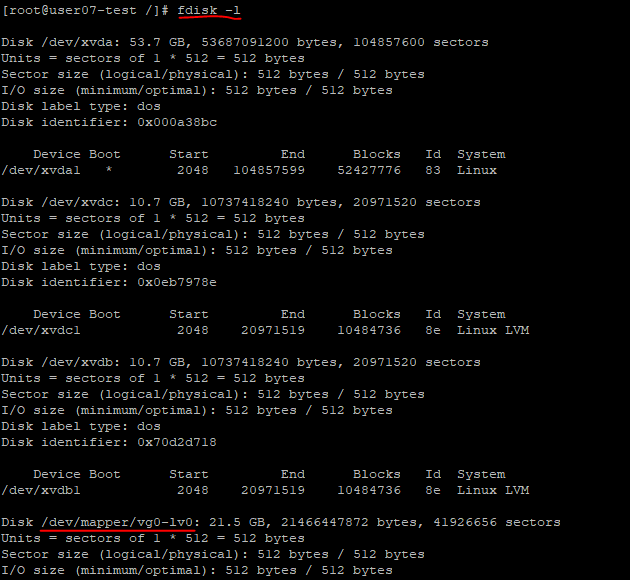
- 장치명을 확인한다.
- 이후 마운트 포인트, 즉 디렉토리를 생성하고 마운트해준다.
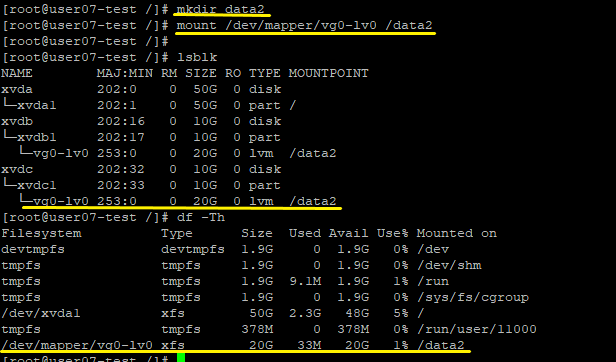
8. 정보 유지 설정
/etc/fstab에 UUID를 추가하여 재부팅시에도 마운트 정보를 유지하게 할 수 있다.
LVM
LVM이란?
- Logical Volume Manager
리눅스의 저장 공간을 효율적이고 유연하게 관리하기 위한 커널의 한 부분.
LVM vs 일반 disk partitioning
- 기존 방식의 경우, 하드디스크를 파티셔닝 한 후 OS 영역에 마운트하여 읽기와 쓰기 작업을 수행했다.
이 경우 저장 공간의 크기가 고정되어 증설/축소가 어려웠기에 이를 보완하기 위한 방법으로 LVM을 사용할 수 있다.
- LVM은 파티션 대신에 Volume이라는 단위로 저장장치를 다룬다.
스토리지 확장, 변경에 유연하면 크기를 변경할 때 기존 데이터의 이전이 필요 없다.
장점
- 크기 조절이 가능한 storage pool
- 실시간 용량 조절이 가능.
관련 용어
- 물리적 볼륨 / PV (Physical Volume)
- 실제 디스크 장치를 분할한 파티션된 상태를 의미.
- PV는 일정한 크기의 PE로 구성.
- 물리적 확장 / PE (Physical Extent)
- PV를 구성하는 일정한 크기의 Block
- 보통 1PE는 4MB에 해당한다.
- PE와 LE는 1:1로 대응
- 볼륨 그룹 / VG (Volume Group)
- PV들이 모여서 생성되는 단위. (모든 걸 합쳐놓은 거대한 덩어리 같은 느낌)
- 사용자는 VG를 원하는대로 쪼개서 LV를 만들게 됨.
- 논리적 볼륨 / LV (Logical Volume)
- 사용자가 최종적으로 사용하는 단위. VG에서 필요한 크기로 할당받아 LV를 생성.
- 논리적 확장 / LE (Logical Extent)
- LV를 구성하는 일정한 크기의 블록.
- 기본크기는 PE와 같은 4MB.
- 리눅스 뿐 아니라 유닉스에서도 가능하다.
유닉스는 증가와 축소가 매우 안정적으로 작동하지만, 리눅스의 경우 아직 축소는 불안정하다. 위험할 수 있다.
📗스토리지
종류
블록 스토리지
- 쉬운 색인 및 검색을 위해 각 데이터 블록이 구조화된 고정 블록으로 배열. '고도로 구조화됨'
- 데이터를 일정한 크기의 덩어리(블록)으로 나누어 저장하는 방식.
- 블록은 파일보다 작은 단위로, 조각으로 나누어 저장된다. 이는 스토리지 시스템이 더 작은 데이터 조각을 원하는 곳에 배치할 수 있도록 해줌.
- 일부는 Linux 환경에, 일부는 Windows 장치에 저장하는 방식을 취할수도 있음.
- 이렇게 나누어진 각각의 블록은 고유의 주소를 갖고 있고, 이 주소를 통해 블록을 재굿성하여 데이터를 불러올 수 있다.
- 블록들은 연속적으로 저장될 필요가 없으며 사용자가 데이터를 요청할 때마다, 기본 스토리지 시스템이 데이터 블록을 다시 병합, 사용자의 요청을 처리한다.
- SAN(Storage Area Network) 또는 클라우드 기반 스토리지 환경에 데이터 파일을 저장하는데 사용.
- 블록 스토리지는 보통 저장 영역 네트워크(SAN) 저장소에 배치된다. 대부분의 애플리케이션에서 오브제트 또는 파일 스토리지는 기본 블록 스토리지의 맨 위에 있는 계층이며, 블록 스토리지는 파일 스토리지 시스템이 구축되는 기반으로 생각할 수 있다.
- 정형화된 데이터를 빠르게 처리하거나, 효율적이며 안정적인 데이터 전송이 요구되는 컴퓨팅 상황의 경우 많이 사용됨.
장점
- 고유 주소가 있어 파일 스토리지와 달리 계층 구조도 필요 없고, 경로도 하나만 있는 것이 아니라 다양함. → 데이터의 신속한 검색
- 파티션으로 분할될 수 있어 서로 다른 운영 체제에서 액세스할 수 있다. 자유롭고 효율적이며 안정적이기 때문에 대규모 DB에 잘 맞음.
- 더 많은 데이터를 저장해야 할수록 블록 스토리지를 사용하는 것이 유리.
단점
- 비용이 많이 든다.
- 메타데이터(오브젝트나 파일 수준 개념) 처리가 제한적이기 때문에 데이터 단위가 아닌 애플리케이션 또는 데이터베이스 수준에서 작업을 진행하여 관리자(개발자, 시스템 관리자)의 부담이 있음.
오브젝트 스토리지
- 데이터 저장소의 형식이나 구조 없이, 오브젝트의 평면적인 목록을 취하고 있어 '비구조화'된 상태.
- 데이터 일관성 : 최근 작성한 오브젝트를 즉시 다시 읽어낼 수 있는지 여부와 같이 스토리지 시스템이 보장하는 읽기, 쓰기 및 업데이트 능력.
- 접근 수준 : 사용자가 데이터에 접근하고 처리할 수 있는 권한 수준.
- 오브젝트라는 개별 데이터 단위로 데이터를 저장. 모든 데이터를 포괄하는 유형이라고 할 수 있다.
- 계층구조 없이 평면(flat) 구조로 데이터를 저장. 접근이 쉽고 빠르며 확장성이 높다.
- 메타 데이터가 포함되지만, 파일 스토리지의 제한적인 메타데이터와 달리 사용자가 원하는 상세한 정보를 추가할 수 있다. 데이터 검색이 용이.
- 증가세가 가파른 대량의 데이터를 저장하고 관리하기 좋은 스토리지 방식.
- 복잡하고 대용량인 비정형 데이터의 처리를 효율적으로 할 수 있어, 대부분의 서비스 백엔드 스토리지로 사용되고 있음.
- 메타데이터 처리의 측면에서 오브젝트/블록 스토리지의 차이
: 오브젝트 스토리지에서는 오브젝트에 저장된 데이터 파일에 관한 추가적인 상세 정보를 포함하도록 메타데이터를 사용자 정의할 수 있다.
: 블록 스토리지에서는 메타데이터가 기본 파일 속성으로 제한됨.
- 파일을 변경하면 새로운 오브젝트가 생성되므로, 오브젝트 스토리지는 자주 변경되지 않는 정적 파일에 가장 적합.
장점
- 데이터 구조가 평면구조로 데이터 접근이 빠르고 확장성이 좋음.
- 메타데이터가 오브젝트 자체로 저장, 접근과 검색이 빠르다.
- 사용한 만큼만 비용을 지불하면 되므로 비용 효율적. 확장하기도 쉬우므로 퍼블릭 클라우드 스토리지에 매우 적합.
단점
- 오브젝트를 수정할 수 없기 때문에 덮어쓰는 방식으로 수정해야 함.
때문에 자주 변경되는 데이터는 맞지 않고, 수정이 잘 일어나지 않는 데이터에 적합.
- 전통적인 데이터베이스와 잘 연동되지 않음. 오브젝트 작성이 느리게 진행되는데다가, 오브젝트 스토리지 API를 사용하기 위해 애플리케이션을 작성하는 일이 파일 스토리지를 사용할 때만큼 간단하지 않기 때문.
파일 스토리지
- 계층 방식으로 색인되고 구조화
- 파일과 폴더의 계층구조로 이루어진 방식.
윈도우 탐색기와 같이, 상위 폴더 - 하위 폴더 - 파일같은 가장 일반적인 방식.
- 파일을 찾기 위해서는 경로를 알아야함. 파일들은 이름, 위치, 생성일 등 제한적인 메타데이터를 갖고 있다. 파일이 늘어나면 데이터도 늘어나고 파일을 찾는 것도 그만큼 힘들어지기 때문.
- 일반적으로 NAS(Network Attached Storage)에 사용된다.
- 구성하기 매우 쉽지만, 데이터에 대한 액세스가 데이터에 대한 단일 경로로 제한됨으로, 성능이 떨어질 수 있다.
- Windows용 NTFS(New Technology File System) 또는 Linux용 NFS(Network File System) 등의 공통 파일 레벨 프로토콜에서만 작동된다. 서로 다른 시스템 간에 가용성이 제한될 수 있는 것이다.
장점
- 오래전부터 사용된 전통적인 데이터 스토리지 시스템.
사용이 친숙하고 표준화가 잘 되어있다.
단점
- 데이터가 많아지면 파일과 폴더를 찾기 위해 리소스가 많이 들기 때문에 성능이 저하된다.
- 시스템을 추가하는 스케일 아웃을 통해 해결할 수 있다.
스토리지 종류
DAS
- Direct Attachted Storage
- PC나 서버에 다이렉트로 꽂아서 사용하는 스토리지
서버와 하드웨어를 1:1로 연결한다.
- 각 서버는 자신이 직접 파일 시스템을 관리한다.
- 서버에 직접 외장저장장치를 연결하므로 속도는 빠르고 확장은 쉽지만, 연결 수에 한계가 있다.
NAS
- Network Attached Storage
- 서버와 저장장치가 이더넷 등의 LAN 방식의 네트워크에 연결된 방식
LAN은 TCP/IP 프로토콜 기반이고 저장장치는 SCSI를 사용하므로 이들간 통신을 위해 중계역할을 하는 파일서버가 필요하다.
- 스토리지 내에서 직접 파일을 읽기/쓰기/공유 한다.
- LAN : Local Area Network. 근거리 통신망.
광대역 통신망과는 달리 학교, 회사, 연구소 등 한 건물이나 일정 지역 내에서 컴퓨터나 단말기들을 고속 전송 회선으로 연결한 네트워크 형태
- SCSI : Small Computer System Interface
컴퓨터 주변기기 접속을 위한 직렬 표준 인터페이스
- 장점
- DAS와 달리 port수 제한이 없어 확장성과 유연성이 뛰어남.
- 경제적으로 유리하고 설치와 유지보수가 용이함.
- 단점
- 트래픽 증가 시 성능이 저하되고, DAS에 비해 성능이 떨어짐.
- 파일시스템을 공유하기 때문에 비교적 보안에 취약함. 백업이 어렵다.
SAN
- Storage Area Network
- 데이터 스토리지에 대한 액세스를 제공하는 컴퓨터 네트워크. 블록 레벨 스토리지에 접근할 수 있다.
스토리지 트래픽을 LAN의 나머지 트래픽에서 분리해 애플리케이션 가용성과 성능을 개선함.
- 스토리지 리소스를 더 쉽게 할당하고 관리해 더 높은 효율성을 달성할 수 있다.
- 구성
- 상호 연결된 호스트, 스위치, 스토리지 기기로 구성.
- 각 구성 요소는 다양한 프로토콜로 연결할 수 있다.
- 본래 SAN 전송 프로토콜은 파이버 채널이며, 또 다른 옵션인 파이버 채널 오버 이더넷(FCoE)은 파이버 채널 트래픽을 기존 고속 이더넷으로 옮겨 스토리지와 IP 프로토콜을 하나의 인프라로 통합함.
- 두 계층으로 구성되며, 첫 계층인 스토리지 연결 계층은 네트워크의 노드 사이에 연결을 제공하고 기기로 가는 명령과 상태를 전송한다. 최소 하나의 스토리지 노드가 이 네트워크에 연결되야 한다.
두 번째 계층은 소프트웨어 계층. 소프트웨어를 사용해 첫 계층 위에서 동작하는 부가 서비스를 제공한다.
NAS 와 SAN의 차이
- SAN과 네트워크 연결 스토리지(NAS)는 모두 네트워크 기반 스토리지 솔루션.
- SAN은 일반적으로 파이버 채널 연결을 사용. NAS는 보통 표준 이더넷을 통해 네트워크에 연결한다.
- SAN은 블록 레벨에 데이터를 저장. NSA는 파일로 데이터 액세스.
- 클라이언트 OS관점에서 SAN은 일반적으로 디스크로 인식되며 별도의 자체 스토리지 디바이스 네트워크로 존재
NAS는 파일 서버로 인식됨.
