인공지능 기술 분류
- 소프트웨어와 하드웨어 설명 모두 진행.
인공지능이란?
AI(Artificial Intelligence)
- 인지, 학습인간의 지적능력(지능) 일부 또는 전체를 '컴퓨터로 구현하는 지능'
- 4차 산업혁명의 핵심 동력 : 범용기술의 특성을 보유한다.
- 다른 분야로 급속히 확산
- 지속적 개선 가능
- 혁신을 유발하여 경제사회에 큰 파급효과
- 파괴적 기술혁신으로 산업 구조, 사회제도 변화 전망.
- 인공지능 서비스
- 데이터 획득
- 데이터 가공
- 반복학습 AI모델 생성 (알고리즘)
- 최종. 서비스 제공
- 인공지능이 이미지로 데이터를 습득시키는 경우가 많은 이유 : 인간이 정보를 습득하는 방법 중 70% 이상이 이미지 습득이기 때문에 인공지능도 유사하다.
인공지능 활용
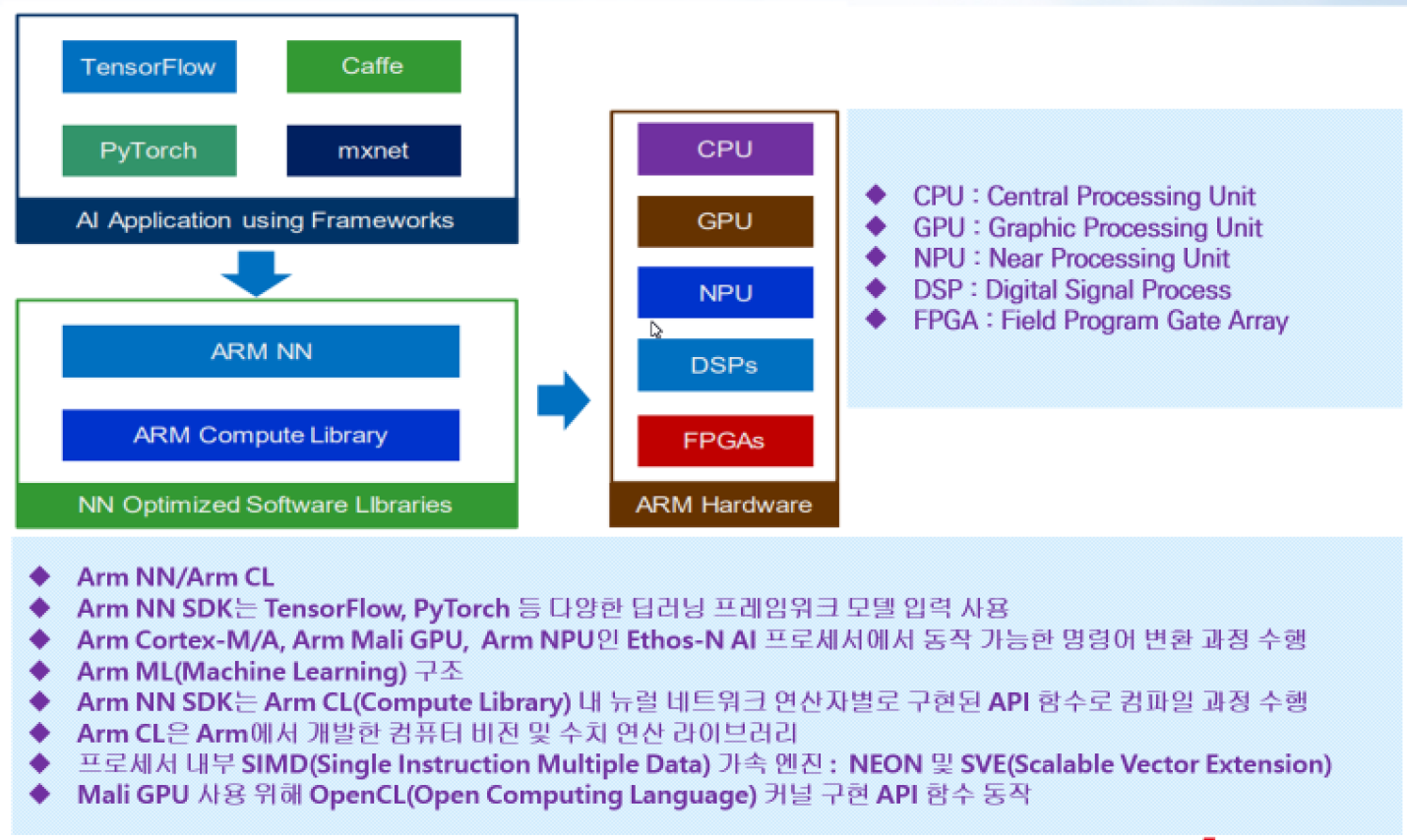
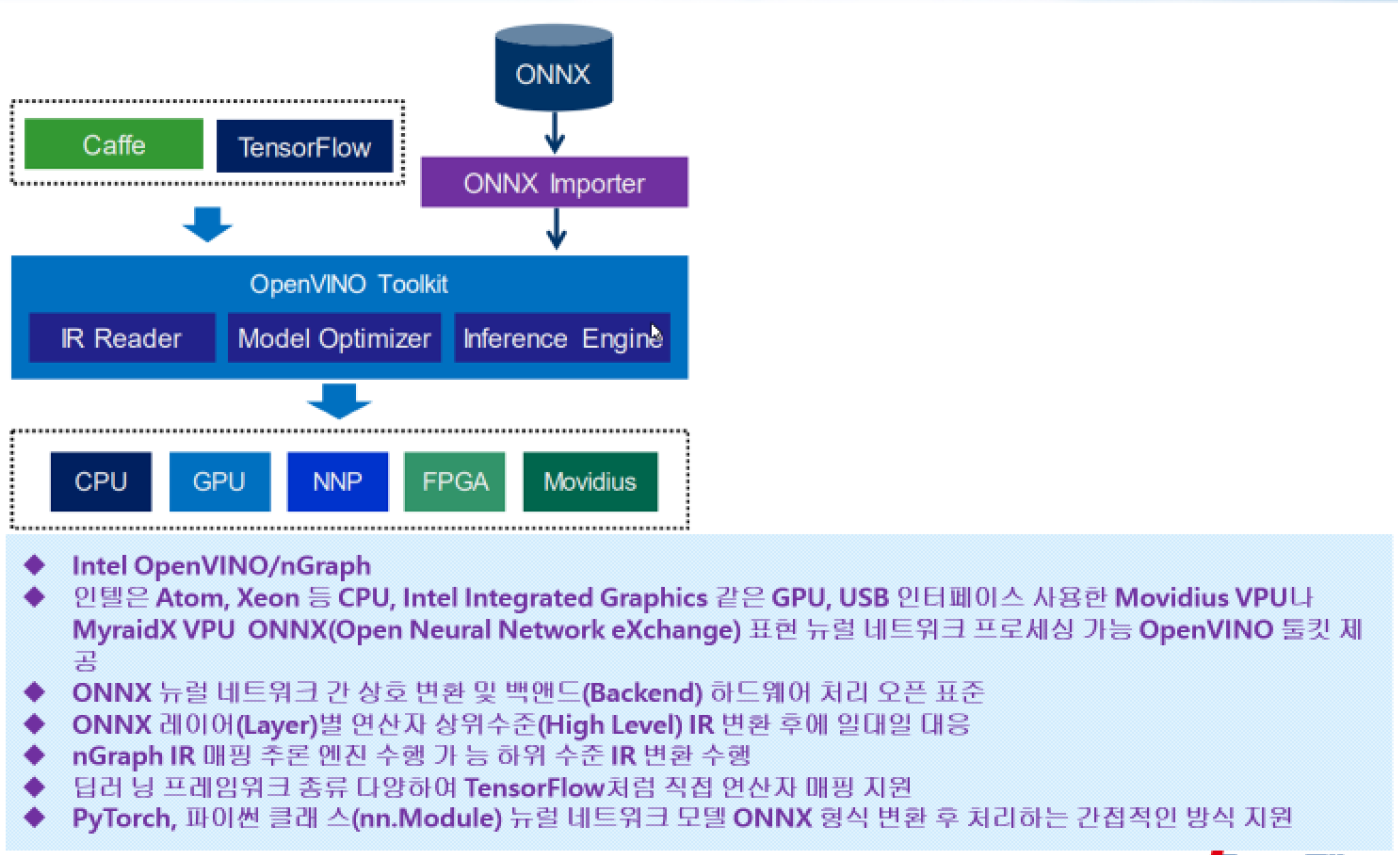
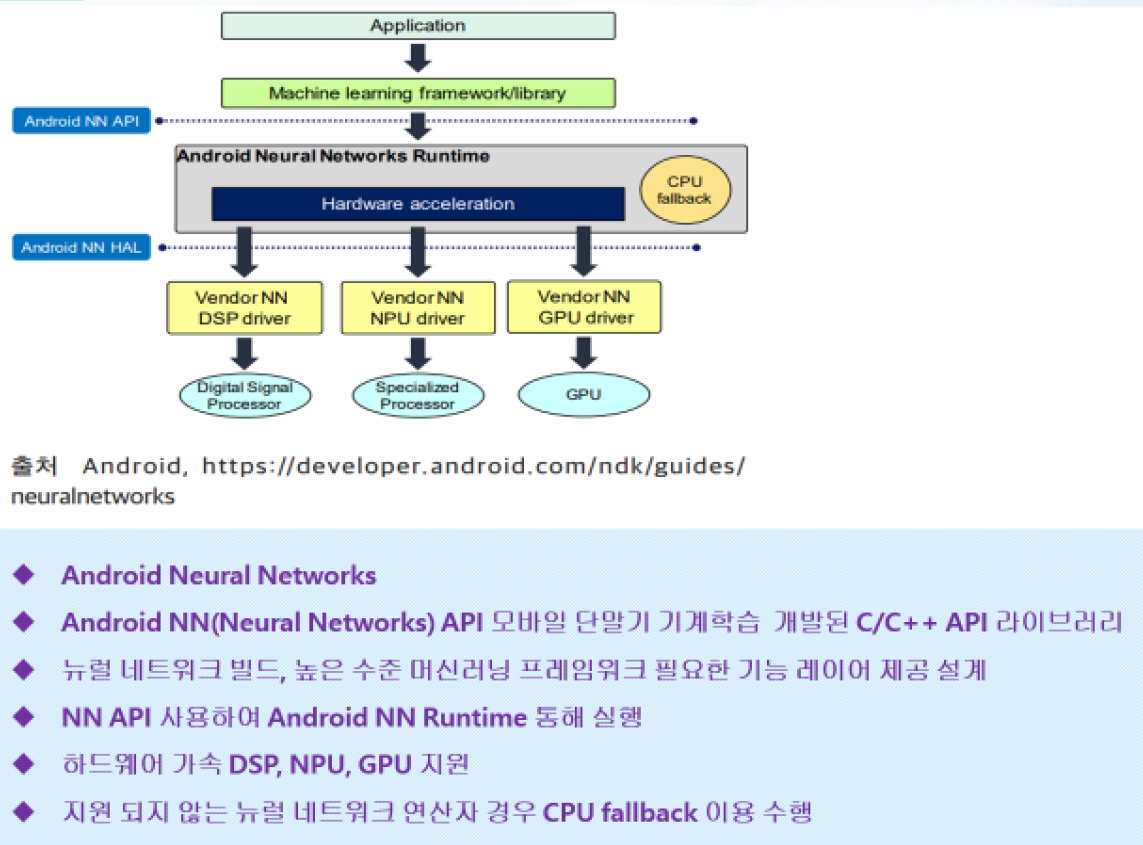
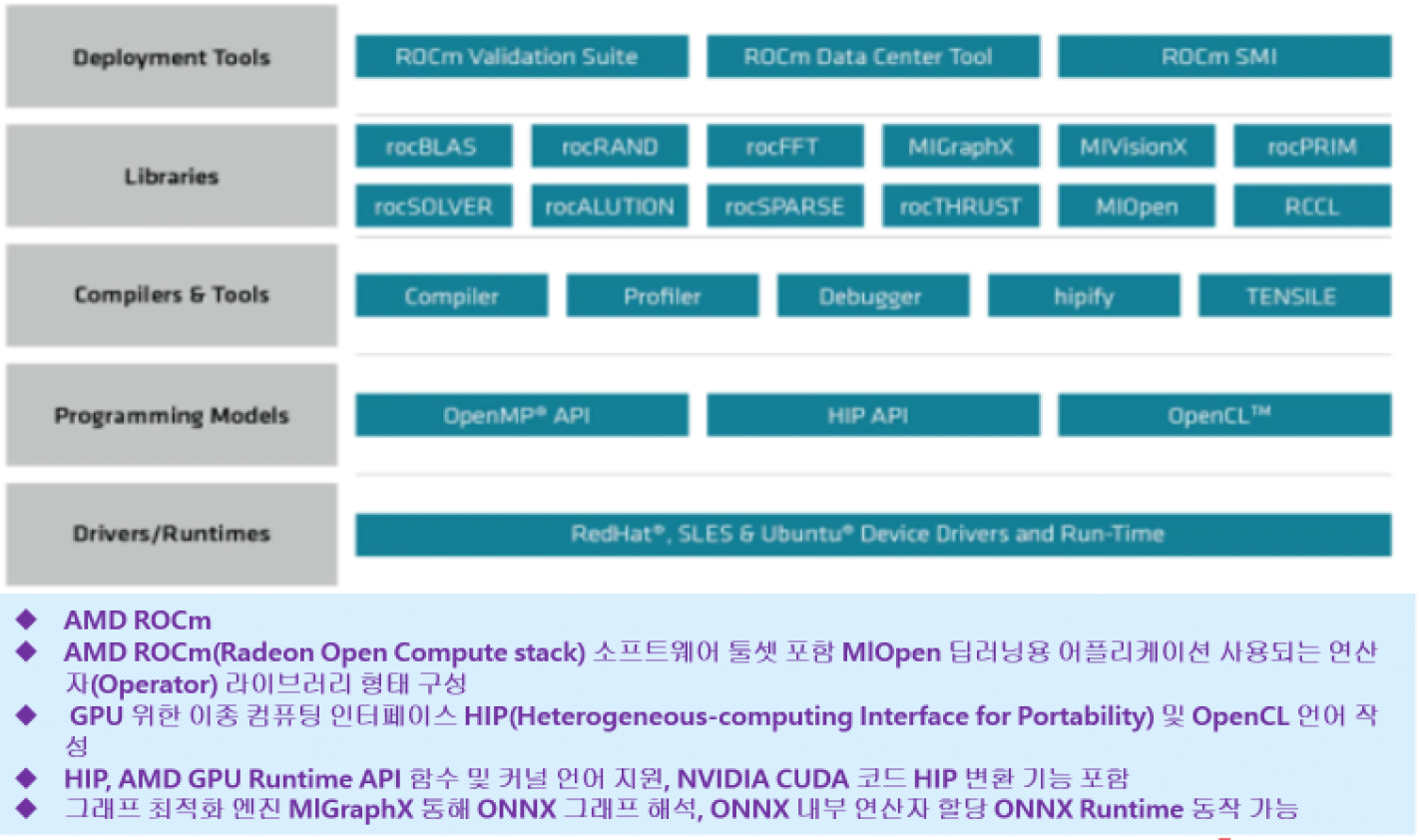


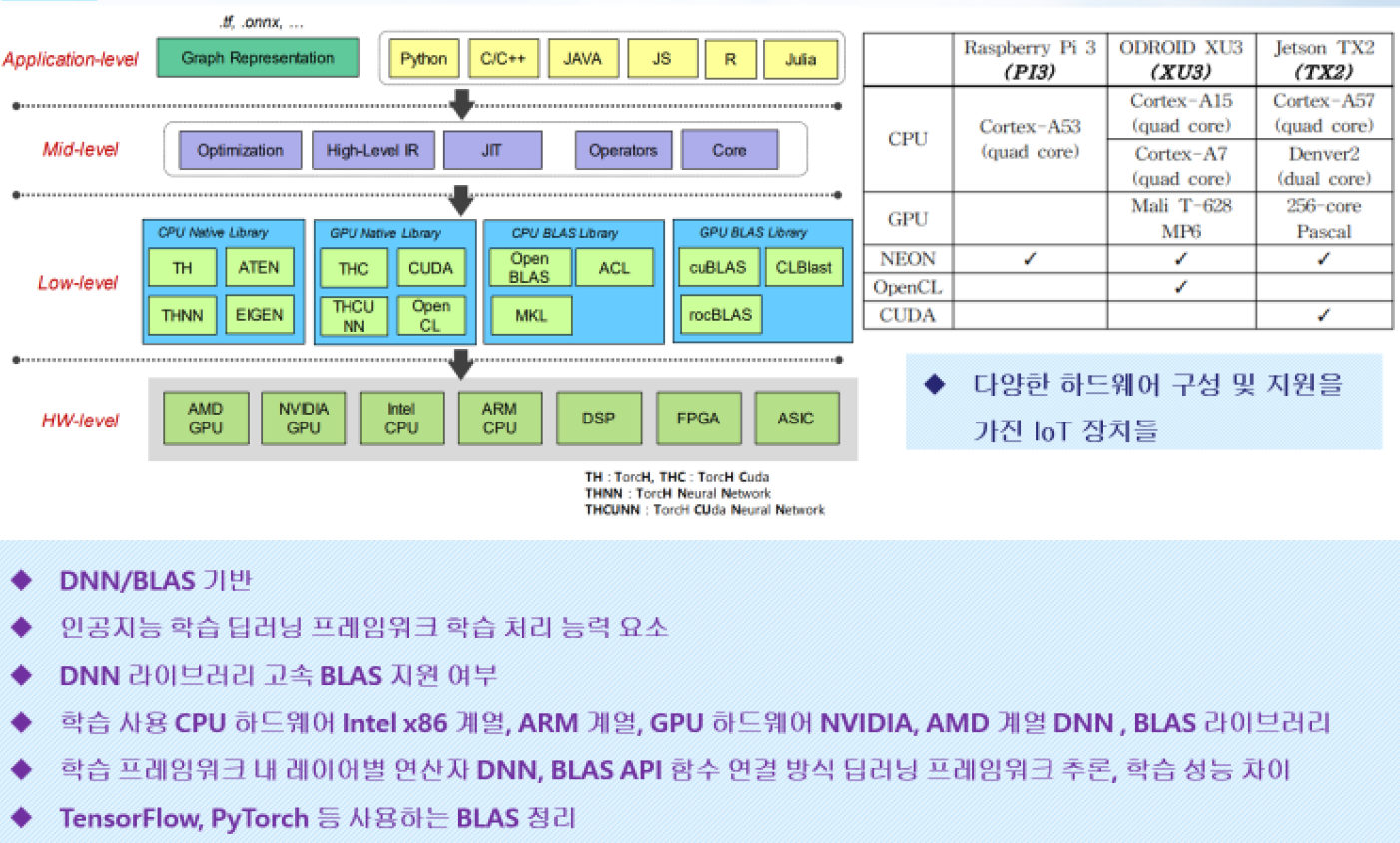
인공지능 라이브러리

- BLAS 연산
- 벡터연산과 행렬연산을 어떻게 빠르고 정확하게 할 것이냐
인공지능의 정확성과 연산속도를 빠르게 하는 핵심 기능.
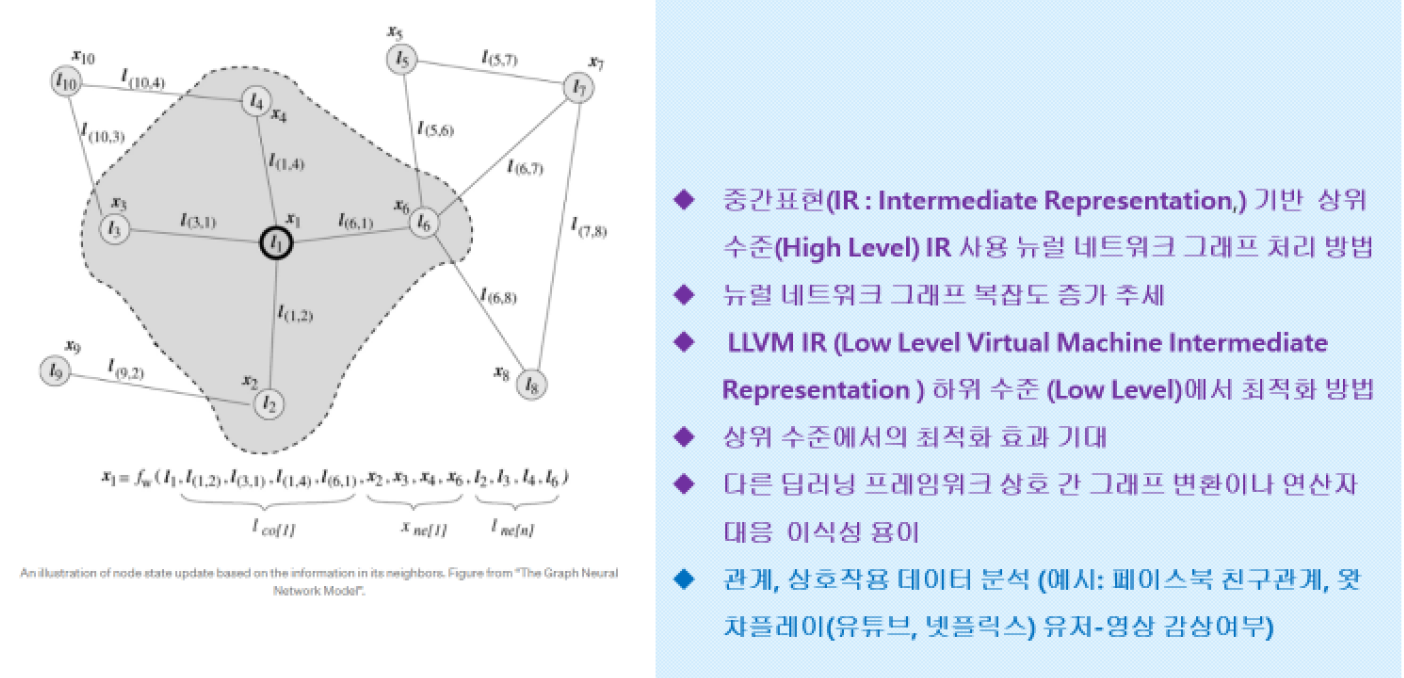
상호 간의 연산자를 그래프로 표현.
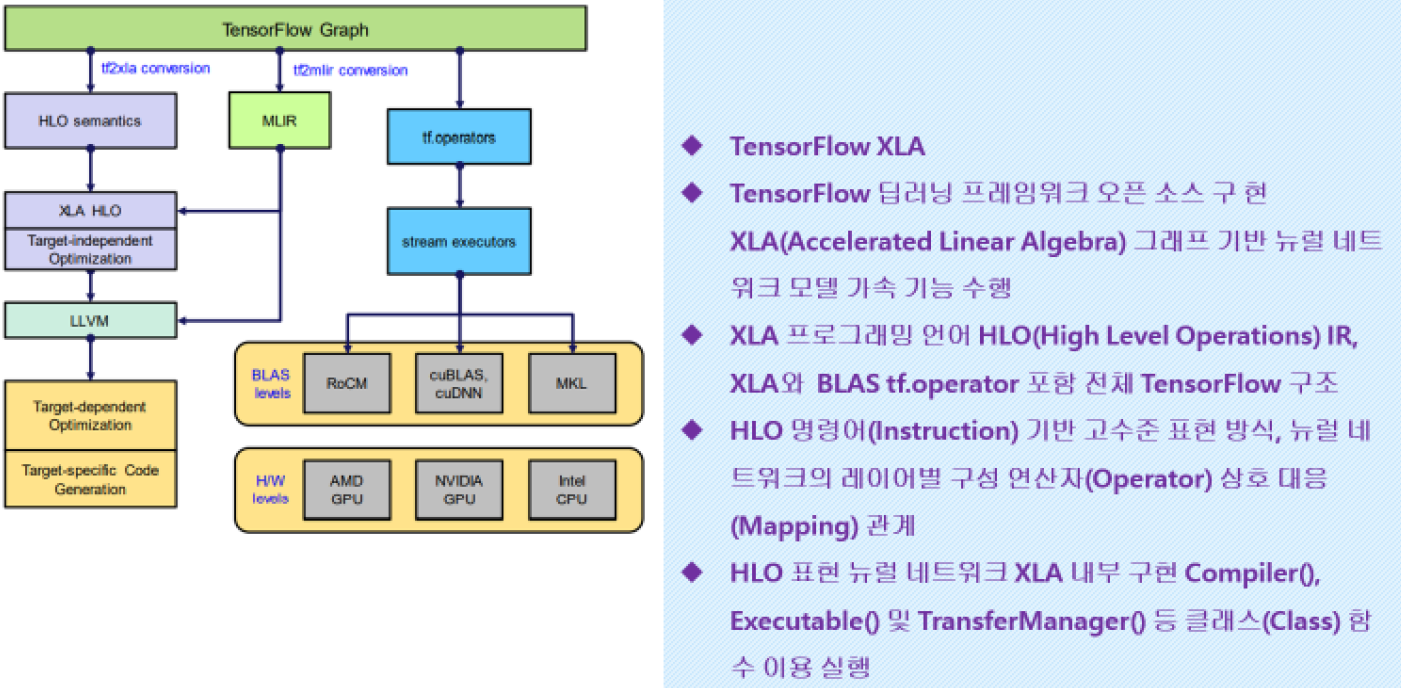
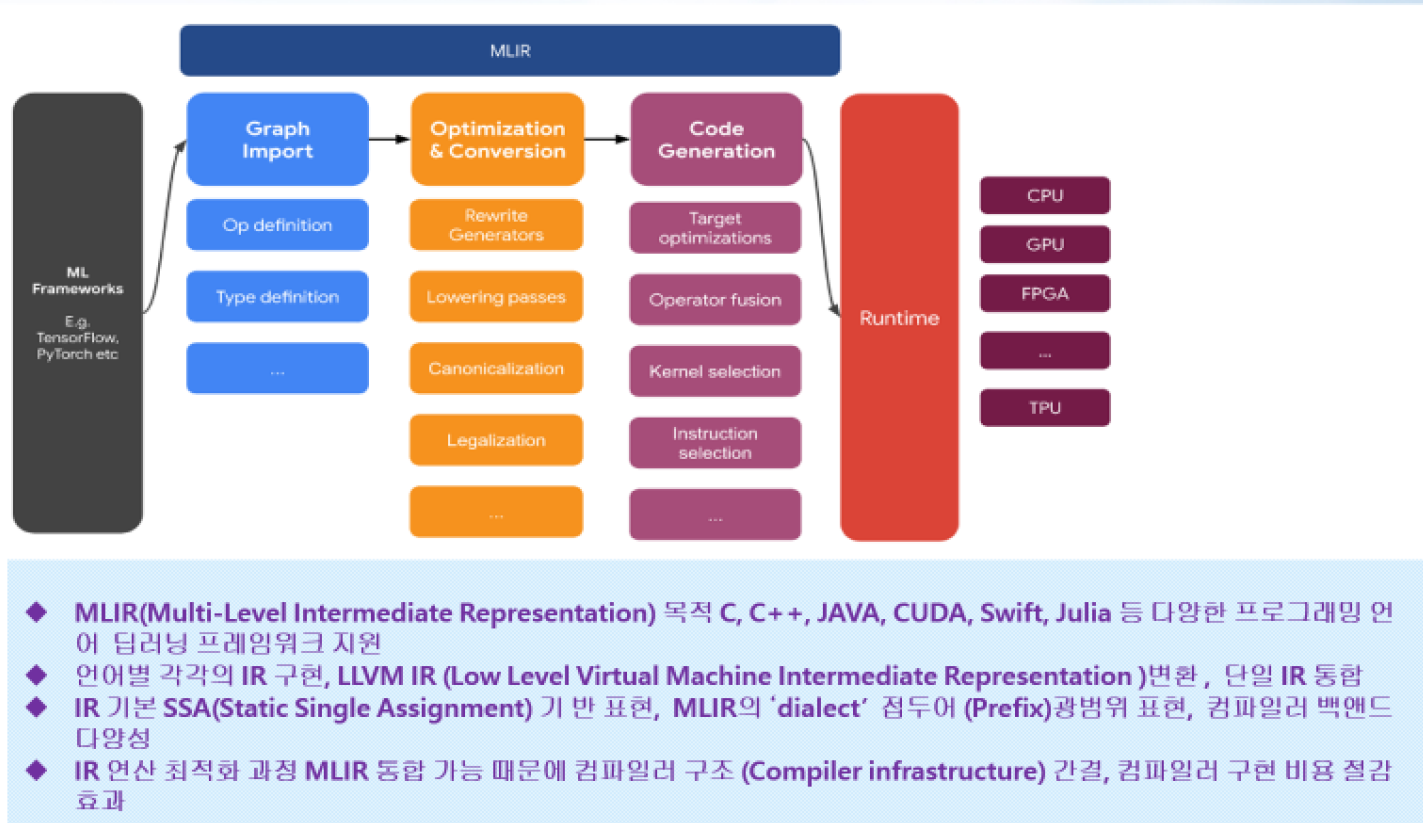
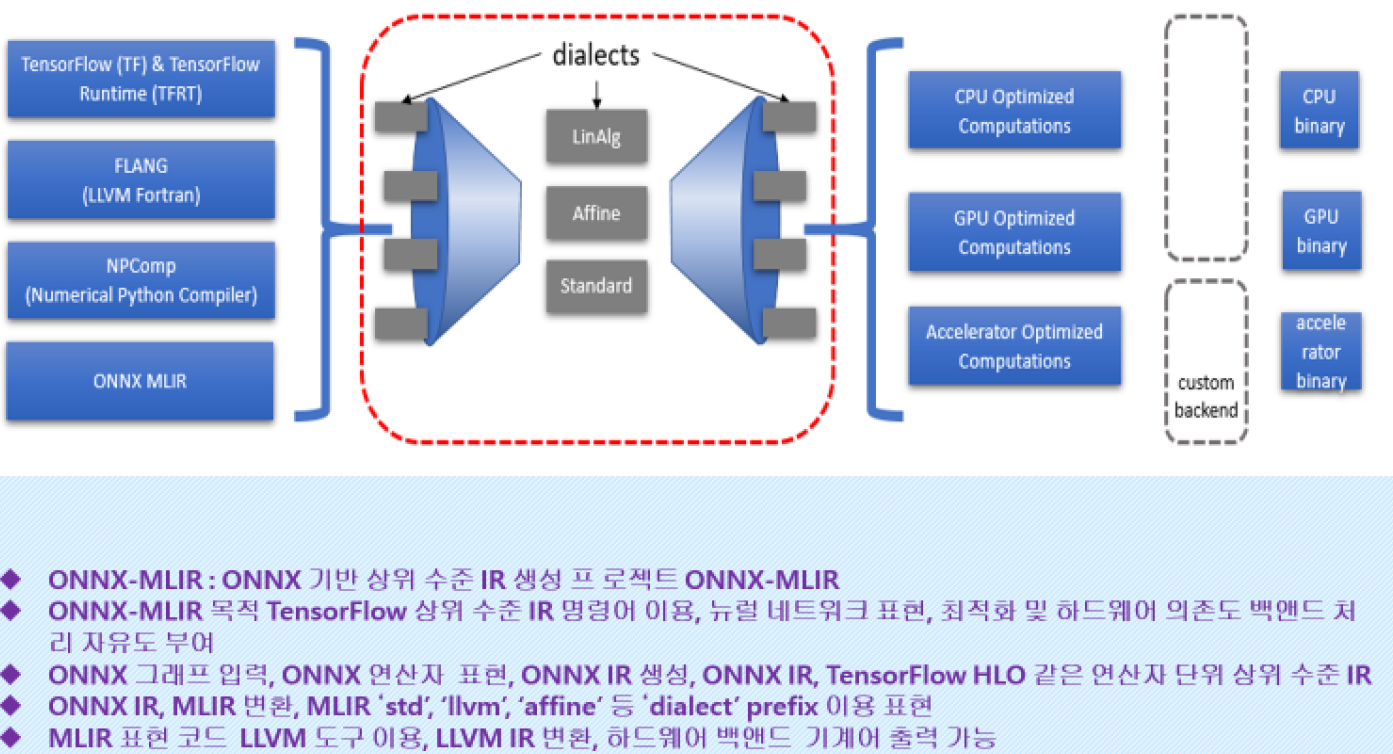
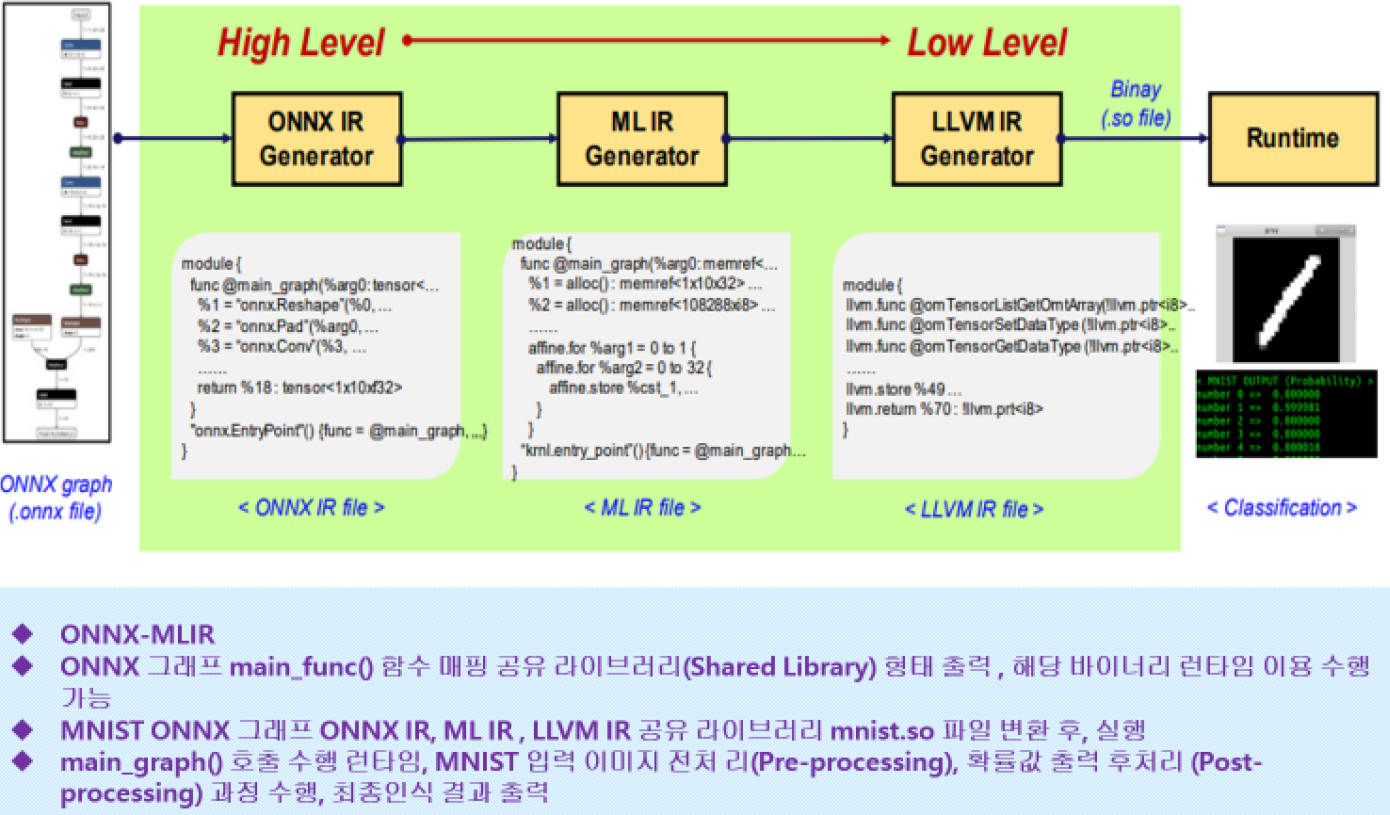
각 단계별의 인공지능 코딩.
인공지능 학습모델
- 지도학습 :
정답을 알려주며 학습시키는 방법. 이를 위해 지도학습에는 훈련 데이터에 레이블을 포함해 알고리즘을 반영함.
- 분류, 회귀(로지스틱 회귀, 선형 회귀) 신경망 등 주로 사용.
- 비지도학습 : 입력 데이터 정답을 모르는 상태에서 데이터의 새로운 특징을 찾는 방식.
비지도학습에서는 지도학습에서 필요했던 레이블이 필요 없이, 이는 시스템이 아무런 도움 없는 학습을 의미.
- 주요 알고리즘 : 시각화, 군집, 연관 규칙 학습, 차원 축소 등.
- 강화학습 :
현 상태에서 어떻게 행동하는 것이 최적인가를 외부 보상을 통해 알아내고, 보상을 최대화 방향으로 행동하는 학습 기법.
딥마인드, 알파고 등.
- 딥러닝은 머신러닝의 세부 방법론들을 통칭하는 개념으로, 이론적 딥러닝은 머신러닝의 부분집합이며, 인간의 뇌를 모사한다.
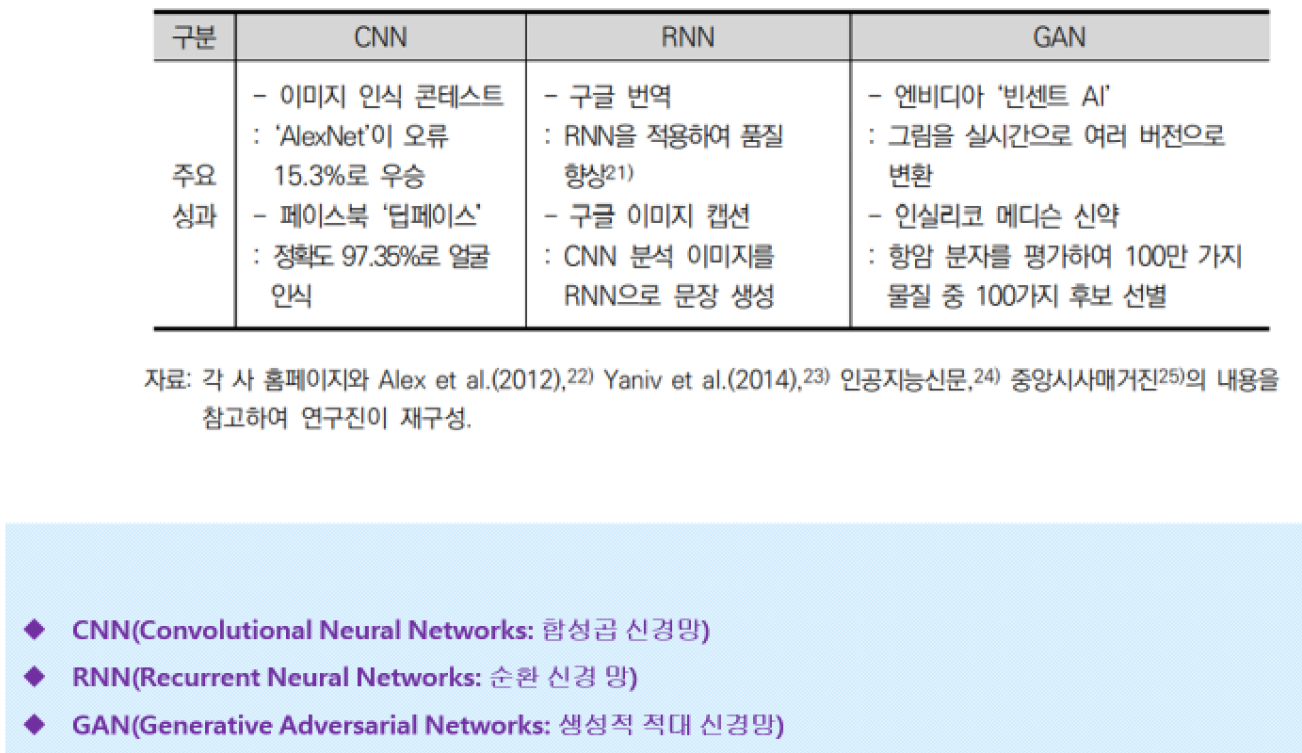
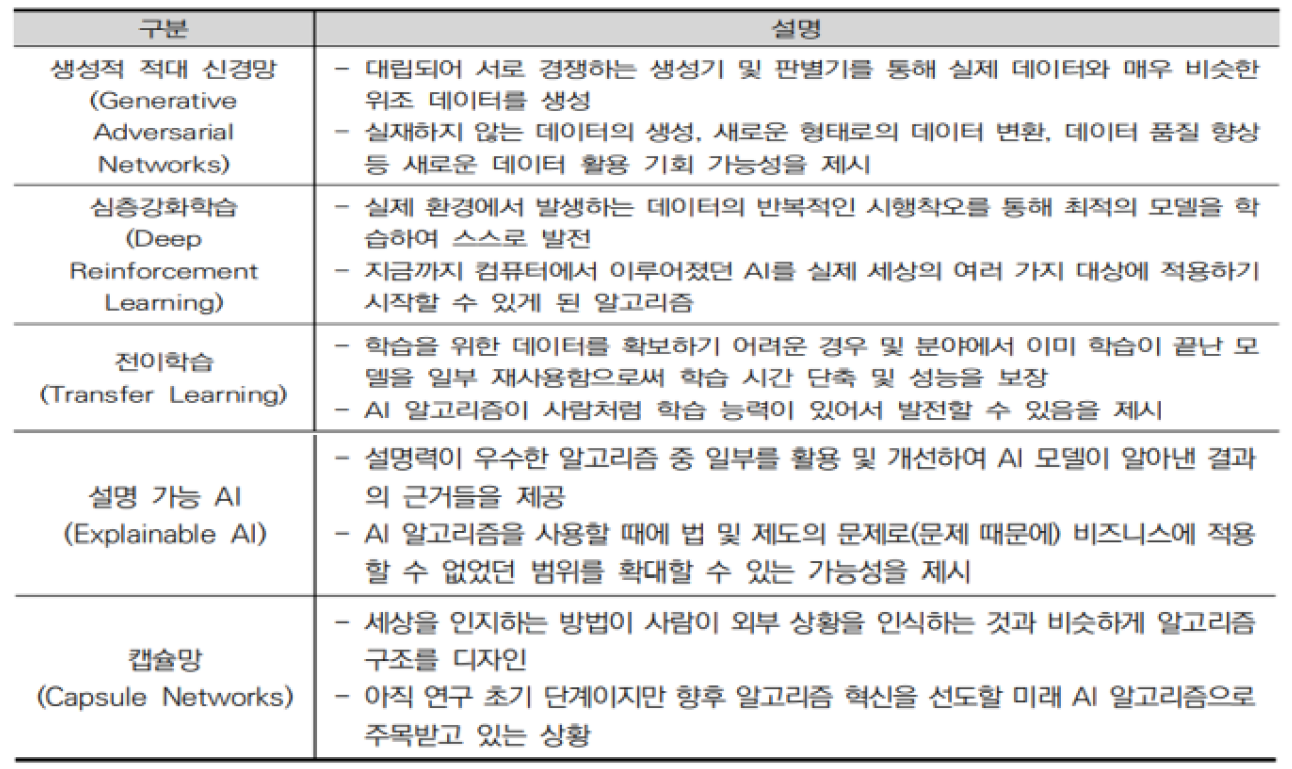
- 생성적 적대 신경망
대립되고 상반되는 데이터를 기준으로 원 데이터와 가상 데이터, 유사 데이터를 생성하는 것.
실제 데이터와 가상데이터를 비교하는 상태에서 얼마나 근접한지, 유사성이 나타나는지 비교하는 것.
원래 있는 데이터하고 얼마만큼 유사한가? 예측하지 못했던 특성이 나타나는가? - 심층 강화학습
몇 번을 반복했을 때 정확도와 신뢰성이 보장되는가?
무작정 많이 반복하는 것이 좋은 방법은 아니다. 리소스를 사용하기 때문. - 전이학습
데이터가 없는 상태에서 유사한 환경의 학습 예시가 있다면, 그 예시를 사용하는 것.
기존 장비가 같고 있던 데이터를 신규 장비에 대입해서 신규 장비의 데이터를 예측해보는 것이 예시. - 설명 가능 AI
유형의 결과값을 갖고 있다고 보기 어려운 분야에 적용할 수 있음. - 캡슐망
연속적인 사회 현상중에서 특정범위를 제한적으로 상황을 한정시켜 예측.

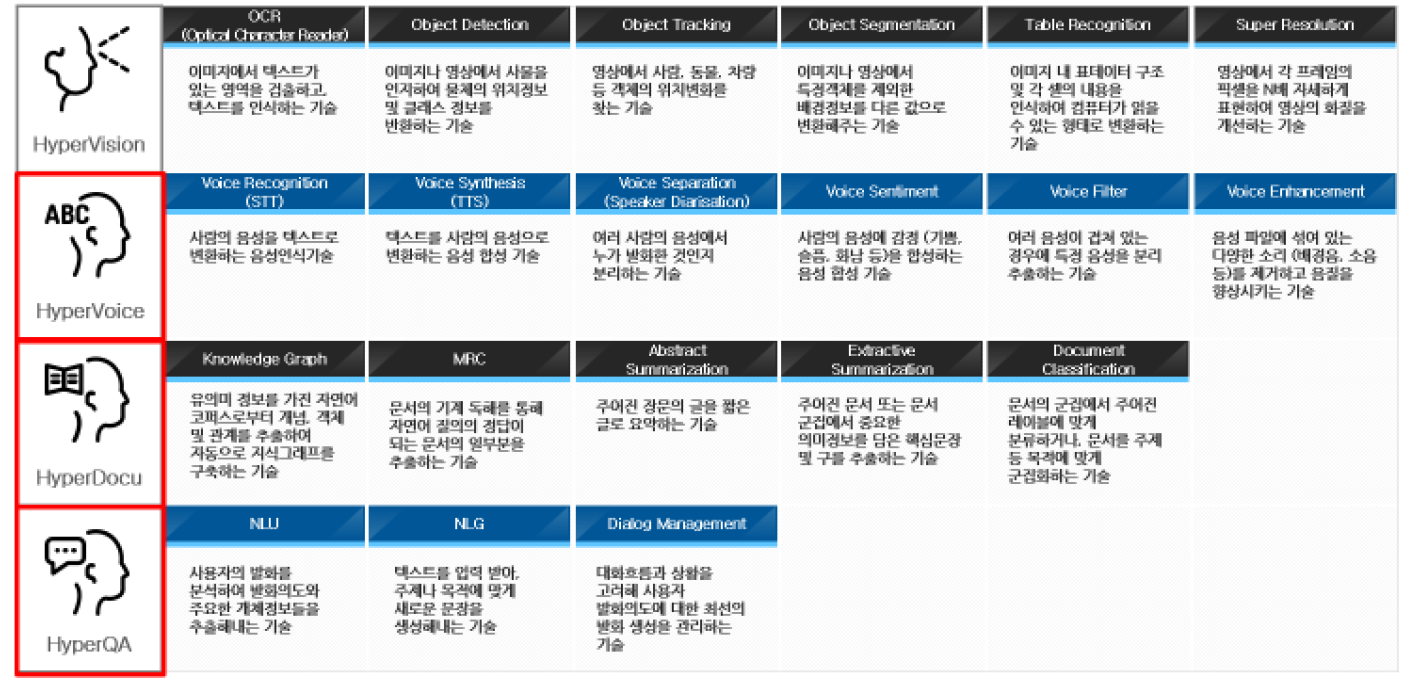
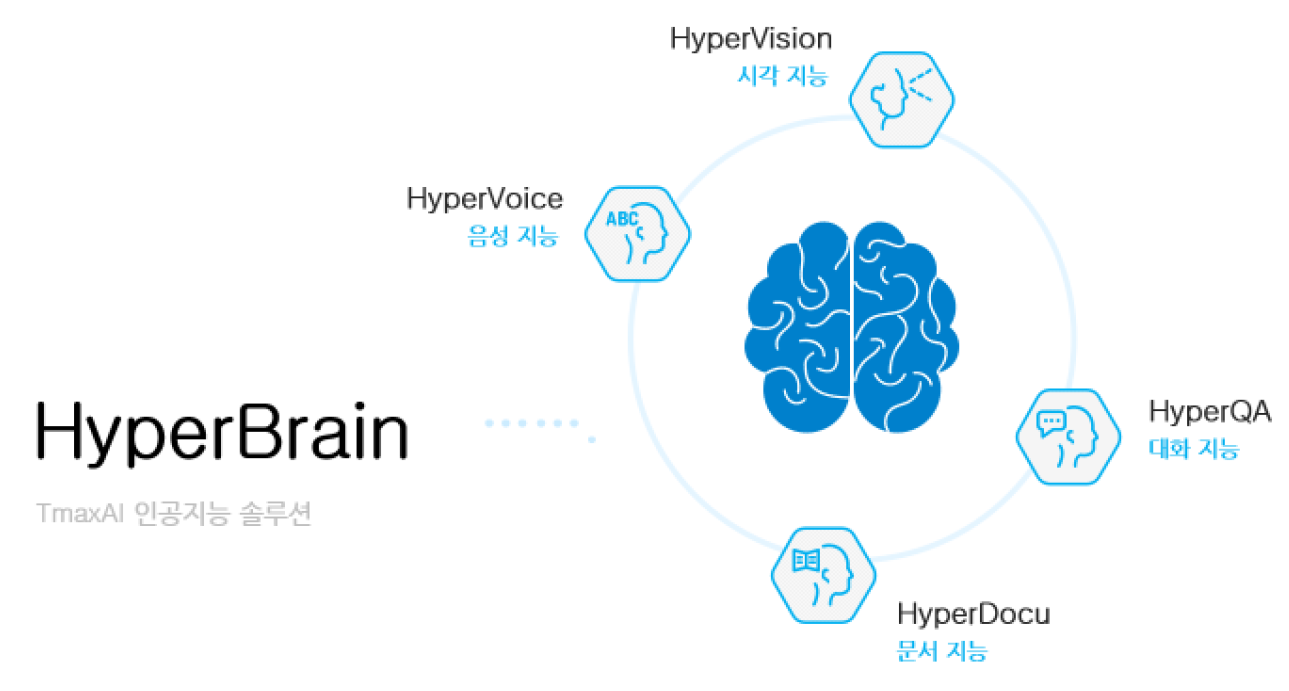
TmaxAI HyperBrain
-
시각 지능, 음성지능, 대화지능, 문서 지능 등 다양한 분야의 서비스를 제공하는 TmaxAI만의 인공지능 솔류션.
-
자체개발한 AI 핵심기술을 기반으로 적용, 비즈니스 모델에 최적화된 서비스를 제공.