Tibero Architecture
티베로 인스턴스
Tb boot라는 실행파일 > 인스턴스 실행Tb down실행파일 > 인스턴스 종료- DBMS(database manager system)
데이터단계 파일들 > 데이터베이스. 여러개의 파일들이 하나의 그룹을 이루고 있음.
여러 파일들이 모여 데이터베이스를 구성함. 그것들을 관리하기 위해 티베로 인스턴스, DB인스턴스가 필요.
- 구조에 관한 시선.
티베로 데이터베이스에 대해서. 티베로 인스턴스에 대해서. - 티베로 인스턴스의 사용자 : 고객. 클라이언트.
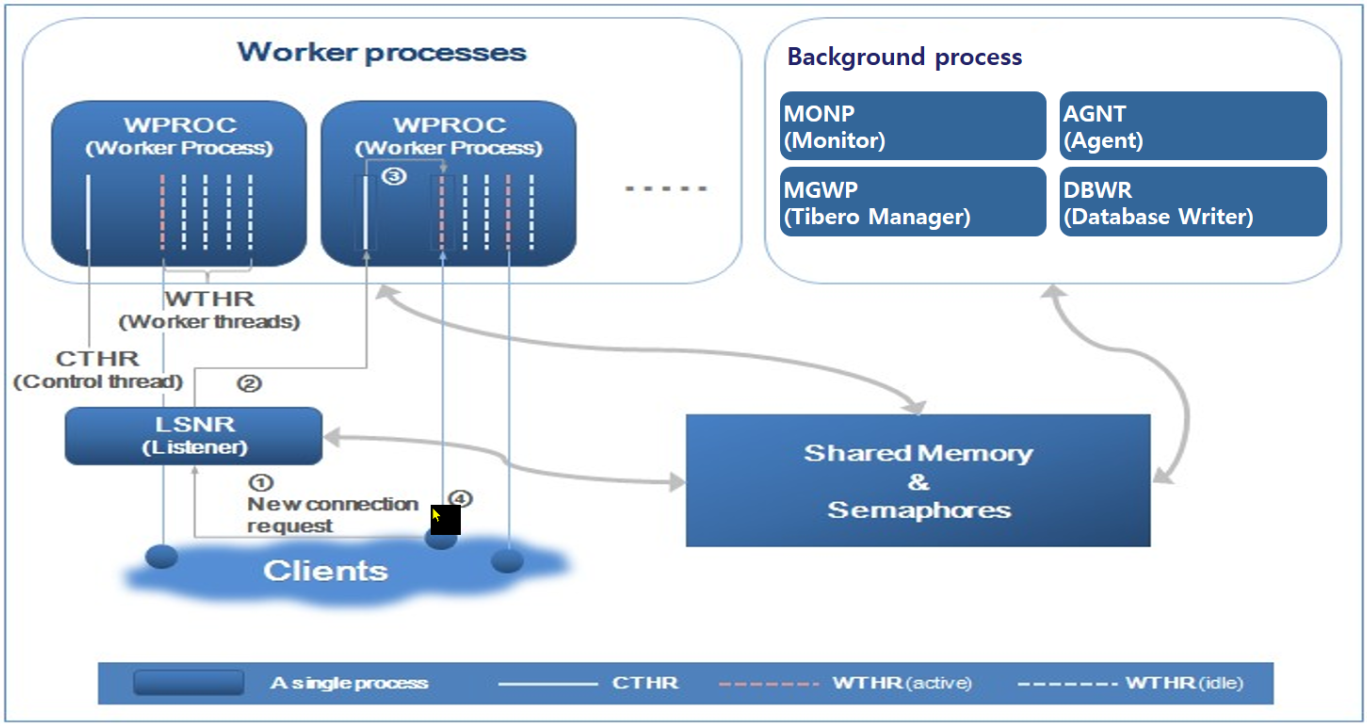
- 1~4단계를 걸쳐 문제가 없다면 사용 가능.
- 여기에서의 클라이언트는 티베로에 직접 접속하는 사용자, application이다. 예시) 제우스.
- JDBC드라이버가 클라이언트와 라이브러리를 연결해준다.
- 접속요청 보내기. IP주소, 포트번호, 데이터 베이스 이름, 패스워드 등.
1) Listerner Process 에 접속요청 보내기.
2) 워커 프로세스에 요청 배정.
3) 1개의 컨트롤 쓰레드와 10개의 워커 쓰레드.
연결 안 돼있는 워커 쓰레드 할당.
4) 할당 안된 워커 쓰레드와 안 그런 쓰레드 합쳐줌.
할당된 워커 쓰레드는 다른 프로세스와 연결될 수 없음. - 연결된 회선은 끊을 때까지는 계속 연결되어 있다.
할당된 워커 쓰레드는 클라이언트에 묶여있는다. - 한 클라이언트 당 하나의 워커 쓰레드.
- 만약 리스너가 일을 하지 않는다면 새로운 접근은 차단된다.
Listener
- 클라이언트의 새로운 접속 요청을 받아 이를 일 없는 워커 프로세서에 할당.
- 클라이언트-워커 프로세스 간 중계 역할을 담당, 별도의 실행 파일인
tblistener를 사용하여 작업 - 모니터링 프로세스에 의해 생성됨. 외부에서 강제 종료하더라도 자동으로 재시작됨.
클라이언트의 새로운 접속 요청이 이루어지는 순서.
- Client가 접속 요청.
- Listener은 현재 빈 WTHR이 있는 프로세스를 찾아 이 사용자의접속 요청을 CTHR에 넘겨줌.
- 요청을 받은 CTHR은 자기 자신의 WTHR 상태를 체크해서 일하지 않은 WTHR 에게 할당.
- WTHR은 client인증 철차를 걸쳐 세션 시작.
- 한번에 가용 가능한 최대개수만큼 프로세스 시작
처음부터 다 같이 시작한다. - 너무 많은 개수로 시작하면 안된다. > 너무 많은 메모리를 소모하기 때문.
동적으로 늘리는 것은 불가능하다. 설정 후 reboot를 해주어야 한다. - 별도로 세팅하지 않다면, default값으로 지정된다.
매니저 프로세스
- 워커 프로세서와 동일한 역할을 수행하지만, 직접 리스닝을 함.
- SYS 계정만 접속이 허용, SQL을 처리한다.
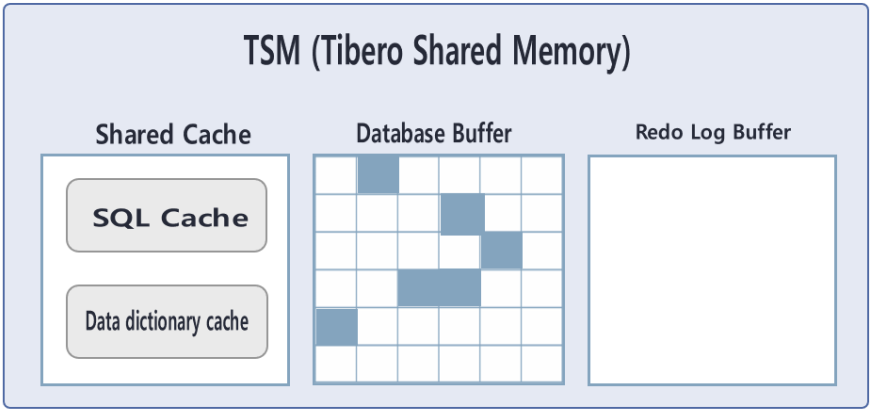
Tibero Shared Memory(TSM)
- Database Buffer 에 올려놓으면 나 뿐 아니라 다른 사람도 사용 가능하다.
- Redo Log Buffer : 한 작업을 재현하는 것.
데이터를 변경하는 작업(DO)에 대한 이력이 Redo Log.
변경작업을 한 이력을 활용해서 이 작업을 재현할 수 있음. - 이것을 하는 이유 : 데이터베이스 백업을 하기 위해. 변경되기 전 데이터베이스 상태를 저장해두기 위하여. 데이터, 데이터베이스가 망가질 가능성이 있기 때문에, 백업이 필요하다. 백업이 있다면 만약 망가지더라도 최대한 복구할 수 있다.
- 데이터는 빈번히 변경된다. 이 많은 변경 건에 대해서 Redo Log가 나옴. > Redo Log Buffer
- Redo Log를 수집하는 것은 workerThread.
RedoLog 파일에 쓰는 것은 데이터 쓰기 프로세스(DBWR)가 수행한다. - SQL만으로는 tibero가 즉시 실행할 수 없다.
실행 계획, 문법에 맞는지 확인 등등을 세워야 함. > 시간이 걸린다.
이전에 만들어 놓은 실행계획을 Shared Cache에 저장해놓는다. - 이러한 과정을 통해서 실행까지 걸리는 시간을 줄일 수 있다.
- dictionary 데이터 베이스 사전. 티베로가 만들어놓은 여러가지 테이블. SQL실행 시에 활용한다.
Data dictionary cache의 내용을 참조한다. - 데이터 공유를 잘 하면 성능을 향상시킬 수 있다.
- 공유하는 메모리(TSM)의 영역과 전체 크기를 설정해주어야한다.
데이터베이스 저장구조
저장소 구조
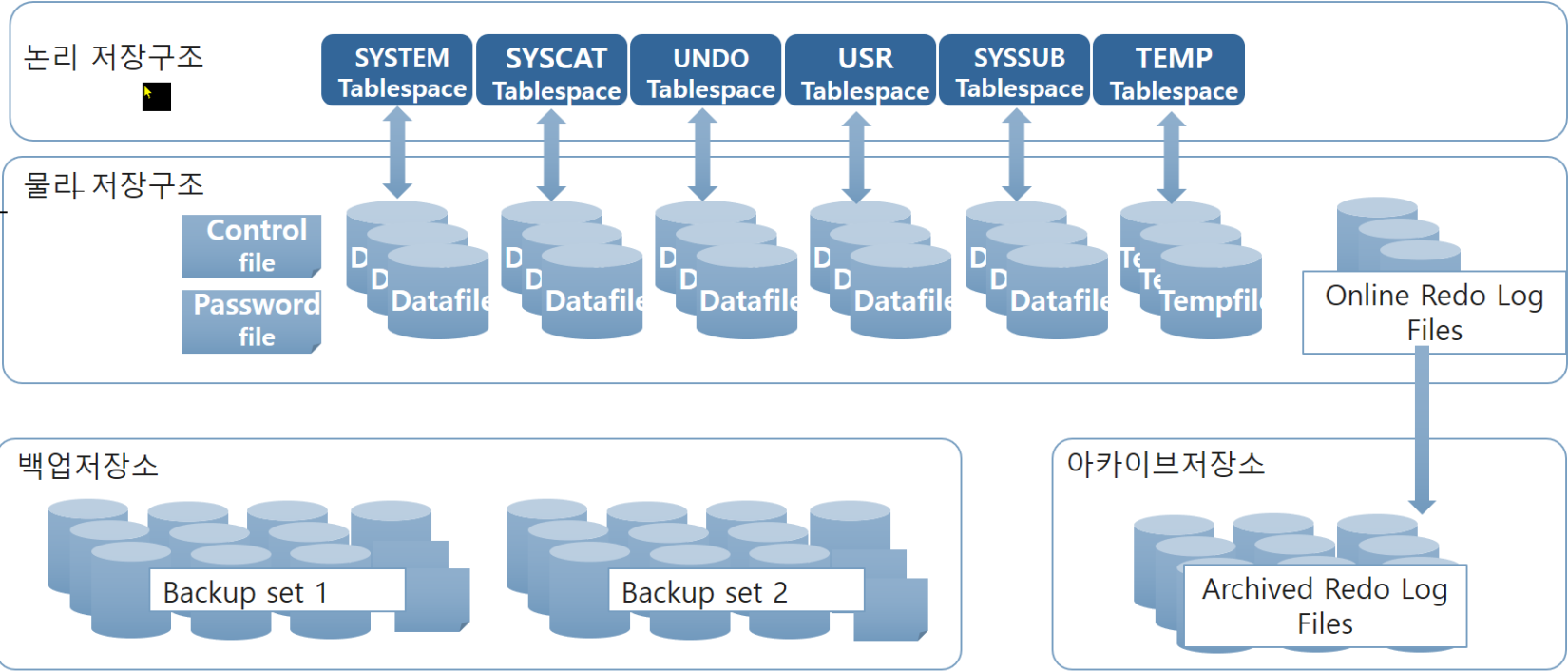
물리 저장구조 = 파일.
- control file, Redo Log 파일, Data 파일로 구성.
Data 파일 > Redo Log 파일 > Control 파일 순으로 크기가 크고, 숫자가 많음.
password 파일을 오픈할 때 필요. - 논리 저장구조 = 테이블 스페이스
데이터베이스 내의 객체. Object.
공간의 제약 없이 저장될 필요가 있음. 여러 파일들을 묶어서 논리적인 데이터 저장장소를 만듦.
테이블 스페이스는 Data파일의 제약을 넘어서 굉장히 큰 크기를 갖을 수 있다.
테이블 스페이스 : Data파일 = 1 : N - 주기적인 Backup이 필요하다. = 백업 저장소
- 추후 복구할 때 사용하기 위한 파일 = RedoLog 파일.
끊임 없이 만들어짐. 새로운 내용을 채우기 위해서 이전 파일은 덮어씌움.
하지만, 최근 내용만을 갖고 있다면 본래 취지와 맞지 않다. 이전 파일을 백업할 수 없을테니까.
때문에 Archived에다 복사본을 저장함. - 모두 온라인은 아니다. Archived 저장소나, Backup저장소의 경우 오프라인이기 때문에 끊임없이 사용되지는 않는다. 복사한 것을 쌓아놓는 구조.
- 티베로 인스턴스가 파일들을 이용하려면 위치정보나 이름, 상태정보 등이 필요하다.
- 이때 필요한 것이 파라미터 파일.
- 데이터 파일과 RedoLog파일의 파라미터는 Control파일에 있다.
때문에 Control 파일 먼저 오픈, 후에 RedoLog와 Data파일을 오픈하게 된다. - 정의된 파일들은 모두 사용된다. 만약 어느 한쪽이 없다면 모두 오픈하지 않게 된다. But, Control파일은 먼저 오픈되므로 컨트롤 파일은 항상 열리는 경우가 많다.
- mount 상태 : Control파일만 오픈되어 있는 상태.
- NoMount 상태 : Control 파일도 오픈되지 않은 상태.
- Normal 모드 : 모두 오픈된 상태
Online Redo Log File
- 저장이 순환된다.
ex. 1 저장소에 작성 > 2 저장소에 작성 > 3 저장소에 작성 > 3 저장소가 다 차면 1 저장소에 덮어씌움. - 이 과정을 Log Switch라고 부름.
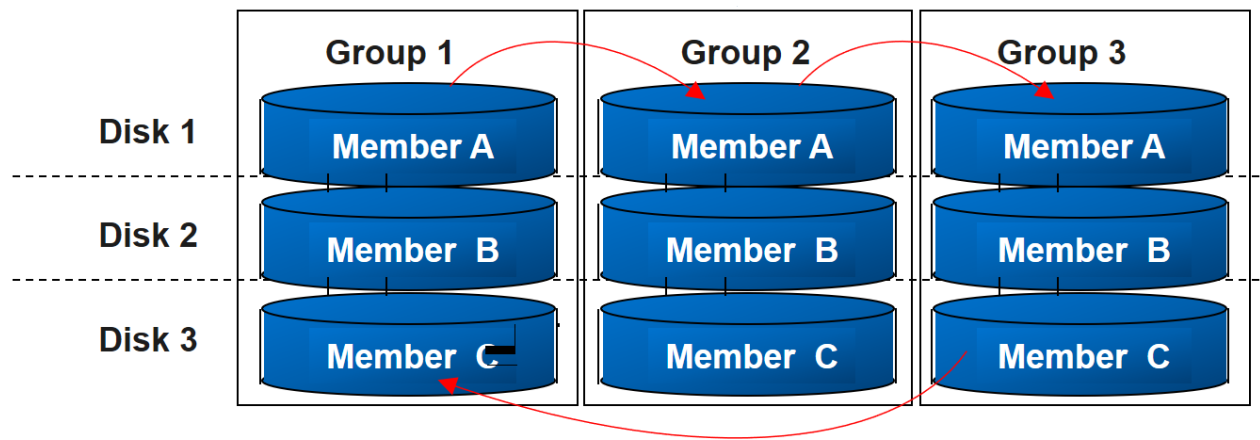
- 그룹의 멤버에 똑같이 기록한다.
- 서버의 가용성을 극대화하기 위해서 이런식으로 다중화해서 설계한다. 만약 하나의 디스크가 망가지더라도 다른 디스크의 멤버를 사용할 수 있다.
- Data파일은 다중화 대상이 아니다. > 개수도 많고 크기도 크다.
다중화는 Control파일과 RedoLog파일. > 개수도 적고, 크기도 작다.
현실적인 이유, (개수와 용량 등의) 비용문제로 Data파일은 다중화를 할 수 없다.
- noArchived Redo Log를 사용하면 오프라인 백업만 사용 가능하다.
Control File
- 가장 먼저 오픈하는 파일.
- 다중화 대상.
논리 저장구조
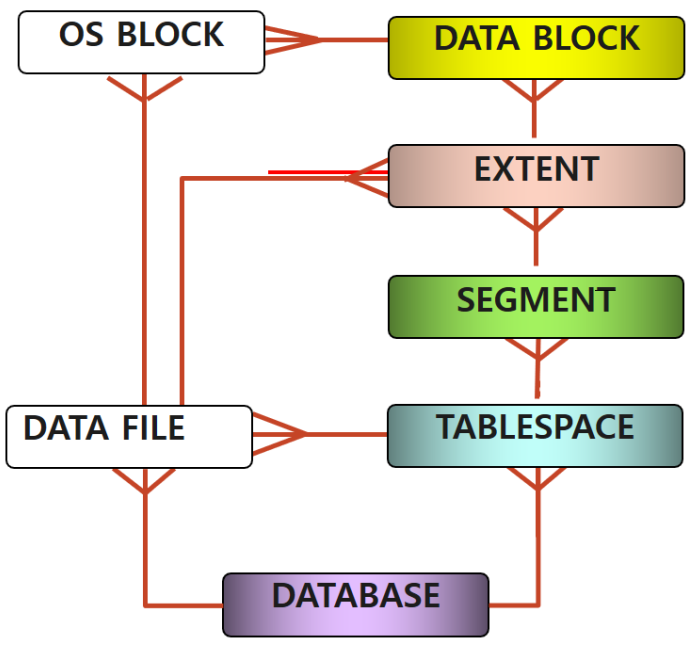
- Segment : 여러 Extent로 구성.
필요한 만큼 할당되어 데이터를 저장하게 된다.
Data File의 특정 영역을 가져다 사용한 것이 Segment. - Extent는 다시 Data Block으로 구성된다.
공간 할당 단위. - Data Block은 여러 크기를 가질 수 있지만, 크기를 설정하면 모두 똑같은 크기가 된다.
이미 데이터베이스가 만들어졌다면, 크기를 바꿀 수 없다. - Segment의 크기가 어느 Extent의 크기보다 크다면 자동으로 다른 Extent가 할당된다.
- 데이터를 지운다는 것은 Extent를 지우는 것이 아닌, Block을 지운다는 것. Extent와 Segment에는 영향이 없다.
- 세그먼트에 계속 익스텐트를 추가한다.
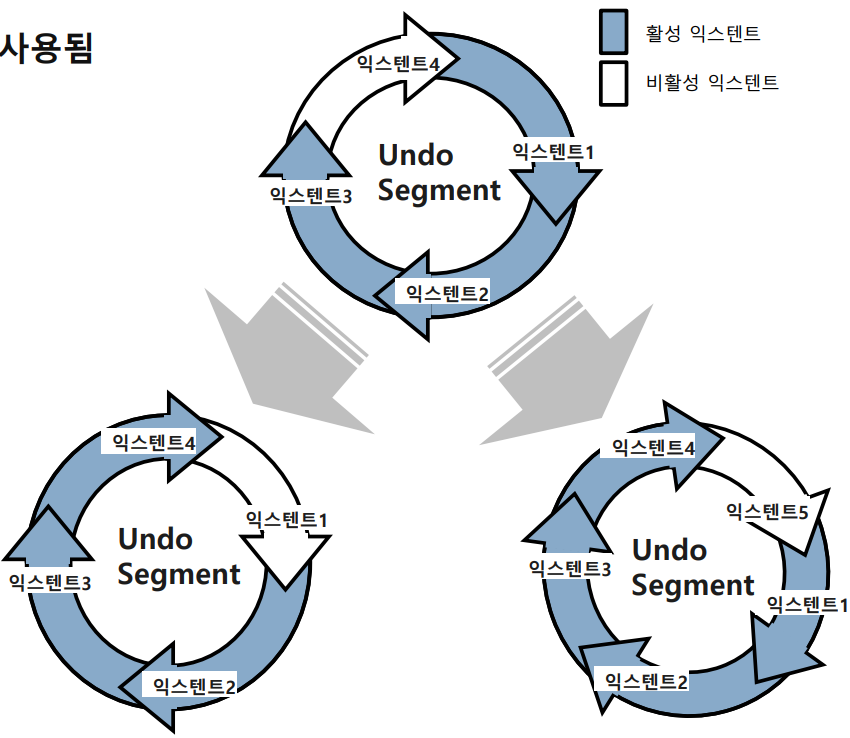
UNDO 세그먼트
- 모든 데이터 변경 시, 이곳에 기록하게 되어있음 > 어마어마하게 많이 나옴.
- 순환구조이기 때문에 기존 저장소를 씌울수도, 새로 추가할 수도 있다.
왼쪽과 같이 재활용하는 것이 우선순위가 높다.
- 트랜잭션 롤백 :
- 트랜잭션 복구 :
- 읽기 일관성 작업 : 데이터에 접근해서 데이터를 읽을 때 시차가 발생하고, 나중에 읽는 데이터가 변경될 수 있음(다른 사람이 변경하는 등의 이유로). 그래도 처음에 읽는 시점의 데이터로 읽어 오는 것.
- 플래시백 작업 : 플래시백 쿼리라고 불리는 특수한 문법. 손쉽게 복구를 진행할 수 있다.
세그먼트 공간관리와 HWM(High Water Mark)
- 빈 공간에 데이터를 집어넣는다.
데이터 저장 속도의 측면에서 장점이 많음.
하지만, 데이터가 어디에 저장되어 있는지 찾기가 너무 어렵다. - 세그먼트의 처음부터 끝까지 다 보아야한다. > Table Full Scan
데이터가 적을때는 부담이 적지만, 많아지면 많아질수록 어려워진다. - 공간관리 작업이 권장됨. Reorganization.
데이터 블록
- 행 단위로 데이터가 저장됨.

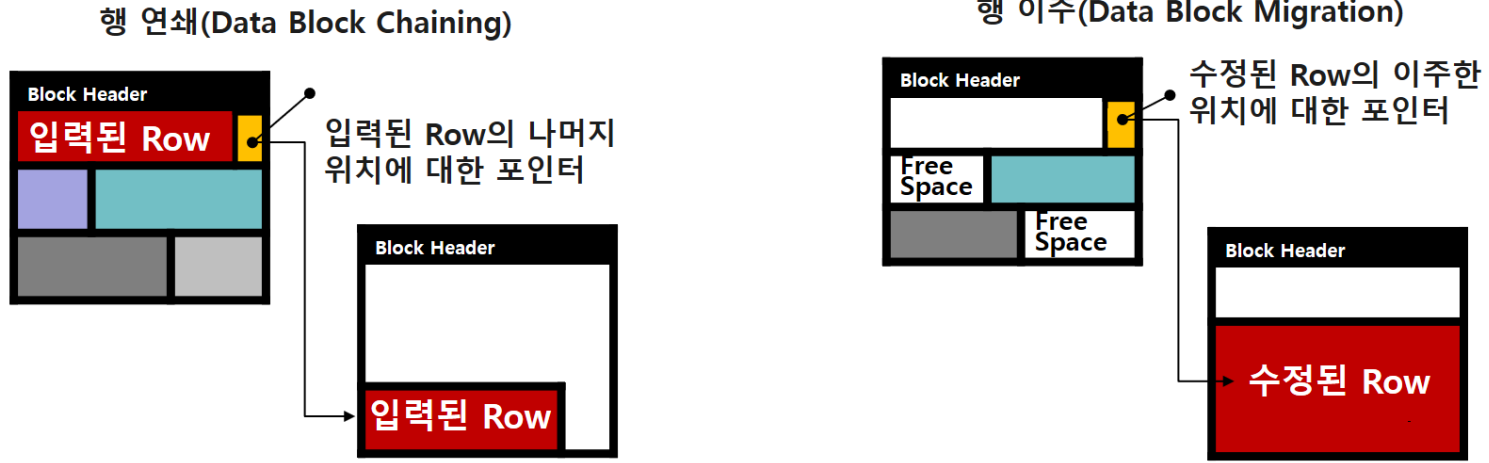
행 연쇄, 행 이주
- 끊어지는 부분이 발생하면 성능저하가 발생할 수 있다. (Insert 도중에 크기가 모자라면 다른 블럭에 적는 경우가 발생한다.
ROWID
인덱스에서 ROWID를 사용하여 위치정보를 관리함.
Parameter File
- 파라미터 파일이 없다면 티베로가 시작할 수 없다.
- 처음 시작할 때 모든 정보를 제공.
- 하지만 이미 시작된 이후라면 파라미터 파일을 세팅한 것이 영향을 주지 못한다.
동적 파라미터(Dynamic parameter)
- 시작한 이후라도 파라미터값을 변경할 수 있다.
slog(system log)
- 중요한 일은 Tb시스템에 log를 남긴다.
혹은 특정 에러 발생 시 log를 남긴다. - 파라미터를 사용해서 저장 위치를 바꿀 수 있다.
기능
- 대용량 데이터 처리를 위한 아키텍처를 기반으로 고성능 처리를 지원.
- 비용 기반(cost Base) Optimizer
실행계획이 굉장히 중요하다. 엄청난 성능차이를 발생시킬수도 있다.
통계가 중요하다. 현황정보 데이터 양, 블럭 사용 등등. Hint가 제공됨. - 다양한 Index/Partition 기술
데이터가 많을 때 성능을 향상시킬 수 있다.
데이터가 많아질수록 성능은 떨어진다. > 테이블 하나에 세그먼트 여러개를 두자. - 고성능 병렬 처리 및 압축
데이터가 많을 때 병렬 처리를 해서 성능을 향상시킬 수 있다. 여러 워커 쓰레드를 추가적으로 할당시켜서 일을 빠르게 할 수 있다.
다만, 병렬처리가 항상 일을 빠르게 하는 것은 아니다. 적합한 경로, 환경, 장비 등이 있다.
압축 역시 적합한 경로가 있다.
TAC(Tb Active Cluster)
- 티베로 인스턴스가 여러 개 모여있다.
- 고가용성이 핵심. 1번 서버 장비에 문제가 생기더라도 2번 서버를 통해서 서비스를 유지할 수 있다.
- 확장성도 중요.
TSC (Tb Standby Cluster)
- 서버 1의 RedoLog를 복제해서 서버 2를 만든다. 같은 내용의 서버가 둘 > 가용성 상승.
