
📒 Amazon EBS(Amazon Elastic Block Store)
- 가용성 / 내구성 : 단일 AZ에 중복 저장
- 액세스 : 하나의 AZ에 속한 하나의 EC2 인스턴스
- 사용 케이스 : 부팅볼륨, 트랜잭션 및 NoSQL 데이터베이스, 데이터 웨어하우징 및 ETL
- 볼륨 내부에 있는 데이터, 볼륨과 인스턴스 사이에서 이동하는 모든 데이터, 볼륨에서 생성된 모든 스냅샷, 그런 스냅샷에서 생성된 모든 볼륨이 암호화된다.
- 인스턴스와 인스턴스에 연결된 EBS스토리지 간 유휴 데이터 및 전송 중 데이터의 보안을 모두 보장
- Data Lifecycle Manager로 스냅샷 생성 자동화
- 워크로드 IOPS가 많다면 SSD / 워크로드 처리량이 많다면 HDD
- 내구성이 있는 블록 수준 스토리지 디바이스이며 인스턴스를 연결하는 것이 가능
- 볼륨을 인스턴스에 연결하면 물리적 하드 드라이브처럼 사용 가능
- 연속으로 디스크 스캔을 수행하는 처리량 집약적 애플리케이션에도 해당 볼륨 사용 가능
- EBS 볼륨은 EC2 인스턴스의 실행 주기와는 독립적으로 유지
🔔 EBS 볼륨 교체 방법
- 스냅샷에서 볼륨을 생성하고 새 볼륨의 ID 기록
- 볼륨 페이지에서 교체할 볼륨의 확인란 선택
- 루트볼륨을 교체하지 않을 경우 인스턴스를 중단하지 않고 교체 가능
- 교체 / 인스턴스를 중지한 경우 인스턴스 다시 시작
💡 SSD 지원 볼륨
작은 I/O 크기의 읽기/쓰기 작업을 자주 처리하는 트랜잭션 워크로드에 최적화되어 있으며, 기준 성능 속성은 IOPS이다.
-
EBS 범용 SSD (gp2)
다양한 워크로드에 사용할 수 있으며 가격 대비 성능이 우수한 범용 SSD 볼륨
대부분의 워크로드에 추천, 시스템 부트 볼륨, 가상 데스크톱, 지연 시간이 짧은 대화형 앱, 개발 및 테스트 환경 -
EBS 프로비저닝된 IOPS SSD(io1)
지연 시간이 짧거나 처리량이 많은 미션 크리티컬 워크로드에 적합한 고성능 SSD 볼륨
지속적인 IOPS 성능이나 16,000 IOPS 또는 250Mib/s 이상의 볼륨당 처리량을 필요로 하는 중요한 비즈니스 애플리케이션
MongoDB, Cassandra, Microsoft SQL Server, MySQL, PostgreSQL, Oracle
💡 HDD 지원 볼륨
대용량 스트리밍 워크로드에 최적화되어 있으며, IOPS보다는 처리량이 더 정확한 성능 측정 기준
- 처리량에 최적화된 HDD (st1)
자주 액세스하는 처리량 집약적 워크로드에 적합한 저비용 HDD 볼륨
저비용으로 일관되고 높은 처리량을 요구하는 스트리밍 워크로드, 빅 데이터, 데이터 웨어하우스, 로그 처리, 부트 볼륨이 될 수 없음
- Cold HDD (sc1)
자주 액세스하지 않는 워크로드에 적합한 최저 비용 HDD볼륨
자주 액세스하지 않는 대용량 데이터를 위한 처리량 중심의 스토리지
스토리지 비용이 최대한 낮아야 하는 시나리오
부트 볼륨이 될 수 없음
RAID 0 : 성능은 좋지만 내결함성은 낮다
RAID 1 : 내결함성은 높지만 0보다 성능은 안좋다.
📒 Amazon EFS(Amazon Elastic File System)
- 가용성 / 내구성 : 여러 AZ에 중복 저장
- 액세스 : 1~수천개의 EC2인스턴스 / on-premise서버 / 여러 AZ에서 동시 접근
- 사용 케이스 : 웹 서비스 및 컨텐츠 관리, 엔터프라이즈 어플리케이션, 홈 디렉토리, 데이터베이스 백업, 개발자 도구, 컨테이너 스토리지 ,빅데이터 분석
- Standard 및 Infrequent Access 스토리지 클래스 제공
- EFS은 AWS에서 파일 스토리지를 쉽게 설정, 확장 및 비용 최적화할 수 있게 해주는 간단한 방식의 탄력적 서버리스 파일 시스템으로, 한 번만 설정하면 된다.
- AWS 관리 콘솔을 사용하면 클릭 몇 번 만으로 EC2 인스턴스, ECS, EKS 및 AWS Fargate에 액세스할 수 있고 파일 시스템 인터페이스(표준 운영 체제 파일 I/O API를 사용)를 통해 AWS Lambda 함수에 액세스할 수 있는 파일 시스템을 생성할 수 있다.
- 또한 강력한 데이터 일관성, 파일 잠금 등의 파일 시스템 액세스 시멘틱을 완벽하게 지원한다.
- Amazon EFS 파일 시스템은 스토리지를 프로비저닝할 필요 없이 자동으로 기가바이트에서 페타바이트 규모의 데이터로 확장될 수 있다.
- 수십 개, 수백 개 또는 수천 개의 컴퓨팅 인스턴스에서 동시에 Amazon EFS 파일 시스템에 액세스할 수 있으며, Amazon EFS는 각 컴퓨팅 인스턴스에 일관된 성능을 제공합니다.
- Amazon EFS는 높은 가용성과 뛰어난 내구성을 갖추도록 설계되었습니다. Amazon EFS에는 최소 비용이나 설정 비용이 없으며, 사용한 만큼만 비용을 지불하면 됩니다.
- EFS는 POSIX와 호환되지만 S3는 POSIX와 호환되지 않는다.
📒 Amazon FSx
- Windows 파일 서버용 Amazon FSx는 업계 표준 SMB(서비스 메시지 블록) 프로토콜을 통해 액세스할 수 있는 매우 안정적이고 확장 가능한 완전 관리형 파일 스토리지를 제공한다.
- Windows Server에 구축되어 사용자 할당량, 최종 사용자 파일 복원 및 Microsoft Active Directory(AD) 통합과 같은 광범위한 관리 기능을 제공한다.
- 광범위한 워크로드를 지원하기 위해 Amazon FSx는 높은 수준의 처리량과 IOPS, 일관된 밀리초 미만의 지연 시간을 제공한다.
- Amazon FSx는 Windows, Linux 및 MacOS 컴퓨팅 인스턴스와 디바이스에서 액세스할 수 있다.
- 수천 개의 컴퓨팅 인스턴스와 장치가 파일 시스템에 동시에 액세스할 수 있다.
- Amazon FSx 파일 게이트웨이는 클라우드에서 완전 관리형 파일 공유에 대한 짧은 온프레미스 액세스를 제공한다.
📒 FSx for Lustre
- 세계에서 가장 인기있는 고성능 파일 시스템을 쉽고 비용 효과적으로 시작 및 실행 가능
- 기계학습, HPC, 비디오 프로세싱 및 금융 모델리과 같이 속도가 중요한 워크로드
- S3와 통합된다
📒 Amazon S3
- 가용성 / 내구성 : 여러 AZ에 중복 저장
- 액세스 : 웹을 통한 수백만 개의 연결
- 사용 케이스 : 웹 서비스 및 컨텐츠 관리, 미디어 및 엔터테인먼트 백업, 빅데이터분석, 데이터 레이크
- 최대 객체 크기 5TB이고 단일 PUT 요청으로 업로드 가능한 객체의 최대 크기는 5GB입니다.
- 접두사에 대한 순차적 날짜 기반 이름 지정을 사용하여 읽기/쓰기 성능 최대화
- 더 높은 집계 처리량을 달성하기 위해 바이트 범위 가져오기를 사용한다.
서버 측 암호화
- Amazon S3 관리형 키를 사용한 서버 측 암호화(SSE-S3) = AES-256
- AWS Key Management Service에 저장된 고객 마스터 키(CMK)를 사용한 서버 측 암호화(SSE-KMS) = 감사추적기능
- 고객 제공 키를 사용한 서버 측 암호화(SSE-C) = 암호화 및 해독에 사용
SSE-S3, SSE-KMS, SSE-C
클라이언트 측 암호화
- AWS Key Management Service(AWS KMS)에 저장된 고객 마스터 키(CMK)를 사용
- 애플리케이션 내에 저장한 마스터 키를 사용
🔔 멀티파트 업로드
- 100MB 초과하는 파일에 권장되며 5GB를 초과하는 파일을 업로드하는 유일한 방법
🔔 서버측 암호화 키 관리 방법의 3가지 옵션
- 데이터 센터의 디스크에 저장하기 전에 객체를 암호화하고 객체를 다운로드할 때 이를 해독하도록 S3에 요청
Amazon S3 관리형 키를 사용한 서버 측 암호화(SSE-S3)
- Amazon S3 관리형 키를 사용한 서버 측 암호화(SSE-S3)를 사용하면 각 객체는 고유한 키로 암호화된다.
- 또한 추가 보안 조치로 주기적으로 교체되는 루트 키를 사용하여 키 자체를 암호화한다.
- Amazon S3 서버 측 암호화는 가장 강력한 블록 암호 중 하나인 256비트 Advanced Encryption Standard(AES-256) GCM을 사용하여 데이터를 암호화한다.
- AES-GCM 이전에 암호화된 객체의 경우 AES-CBC는 여전히 해당 객체의 암호를 해독하도록 지원된다.
AWS Key Management Service에 저장된 KMS 키를 사용한 서버 측 암호화(SSE-KMS)
- AWS KMS keys를 사용한 서버 측 암호화(SSE-KMS)는 SSE-S3와 유사하지만 이 서비스 사용 시 몇 가지 추가적인 이점이 있고 비용이 발생한다.
- Amazon S3의 객체에 대한 무단 액세스에 대응하여 추가적인 보호를 제공하는 -KMS 키를 사용하려면 별도의 권한이 필요하다.
- SSE-KMS도 KMS 키가 사용된 때와 사용 주체를 표시하는 감사 추적 기능을 제공한다.
- 또한 고객 관리형 키를 생성하고 관리하거나 사용자, 서비스 및 리전에 고유한 AWS 관리형 CMK를 사용할 수 있다.
고객 제공 키를 사용한 서버 측 암호화(SSE-C)
- 고객 제공 키를 사용한 서버 측 암호화(SSE-C)를 사용하면 사용자는 암호화 키를 관리하고 Amazon S3는 암호화(디스크에 쓸 때) 및 해독(객체에 액세스할 때)을 관리한다.
🔔 클라이언트측 암호화
- 클라이언트 측 데이터를 암호화하여 암호화된 데이터를 S3에 업로드
- KMS에 지정된 고객 마스터 키 (CMK)를 사용한다. / 객체를 업로드 할 때 임의로 생성된 데이터 키의 다음 두 가지 버전을 반환한다.
- 클라이언트가 객체 데이터를 암호화는 데 사용하는 일반 텍스트 버전의 데이터 키
- 클라이언트가 S3에 객체 메타데이터로 업로드하는 동일한 데이터 키의 암호 BLOB
- 애플리케이션 내에 저장한 마스터 키를 사용한다.
- 클라이언트 측 마스터 키와 암호화되지 않은 데이터는 AWS로 전송되지 않는다.
- 따라서 암호화 키를 안전하게 관리하는 것이 중요하다. 해당 키를 잃어버리면 데이터와 암호를 해독할 수 없다.
🔔 S3 웹 사이트 엔드 포인트 형식
S3-website 대시(-)리전 = http://bucket-name.s3-website-Region.amazonaws.com
- . - - . # URL 기호 순서S3-website 점(.)리전 = http://bucket-name.s3-website.Region.amazoneaws.com
- . - . . # URL 기호 순서🔔 AWS S3 알림
s3:TestEvent
- 알림이 사용 설정되면 Amazon S3는 테스트 알림을 게시합니다.
이는 주제가 존재하고 버킷 소유자에게 지정된 주제를 게시할 권한이 있는지 확인하기 위한 것입니다. - 알림 사용 설정가 실패하면 테스트 알림이 수신되지 않습니다.
s3:ObjectCreated:*, Put, Post, Copy, CompleteMultipartUpload
- PUT, POST 및 COPY와 같은 Amazon S3 API 작업은 객체를 생성할 수 있다.
- 이 이벤트 유형을 사용하면 특정 API 작업을 사용하여 객체가 생성될 때 알림을 사용 설정할 수 있다.
- 또는 s3:ObjectCreated:* 이벤트 유형을 사용하여 객체를 생성하는 데 사용된 API와 관계없이 알림을 요청할 수 있다.
- 실패한 작업에서는 이벤트 알림이 수신되지 않는다.
- s3:ObjectCreated:CompleteMultipartUpload에는 복사 작업을 위해 UploadPartCopy를 사용하여 생성된 객체가 포함되어 있다.
s3:ObjectRemoved:*, Delete, DeleteMarkerCreated
- ObjectRemoved 이벤트 유형을 사용하여 객체나 객체 그룹이 버킷에서 삭제될 경우 알림을 사용 설정할 수 있습니다.
- s3:ObjectRemoved:Delete 이벤트 유형을 사용하여 객체가 삭제되거나 버전이 지정된 객체가 영구적으로 삭제될 경우 알림을 요청할 수 있다.
- 또한 s3:ObjectRemoved:DeleteMarkerCreated를 사용하여 버전이 지정된 객체에 대해 삭제 마커가 생성될 경우 알림을 요청할 수 있다.
- 버전이 지정된 객체를 삭제하는 방법에 대한 지침은 버전 관리가 사용 설정된 버킷에서 객체 버전 삭제 섹션을 참조
- s3:ObjectRemoved:* 와일드카드를 사용하여 객체가 삭제되는 모든 경우에 알림을 요청할 수도 있다.
- 이러한 이벤트 알림은 수명 주기 정책 또는 실패한 작업의 자동 삭제에 대해 경고하지 않는다.
s3:ObjectRestore:*, Post, Completed, Delete
- ObjectRestore 이벤트 유형을 사용하여 S3 Glacier Flexible Retrieval 스토리지 클래스및 S3 Glacier Deep Archive 스토리지 클래스에서 객체를 복원할 때 초기화 및 완료 알림을 받을 수 있다.
- 객체의 복원된 복사본이 만료될 때 알림을 받을 수도 있다.
- s3:ObjectRestore:Post 이벤트 유형은 객체 복원 시작을 알린다.
- s3:ObjectRestore:Completed 이벤트 유형은 복원 완료를 알린다.
- s3:ObjectRestore:Delete 이벤트 유형은 복원된 객체의 임시 복사본이 만료될 때 알려준다.
s3:ReducedRedundancyLostObject
- Amazon S3가 RRS 스토리지 클래스의 객체가 손실되었음을 감지하면 이 알림 이벤트를 수신합니다.
s3:Replication:*, OperationFailedReplication, OperationMissedThreshold, OperationReplicatedAfterThreshold, OperationNotTracked
- 복제 이벤트 유형을 사용하여 S3 복제 지표 또는 S3 복제 시간 제어(S3 RTC)가 사용 설정된 복제 구성에 대해 이벤트 알림을 받을 수 있다.
- 보류 중인 바이트, 보류 중인 작업, 복제 대기 시간을 추적하여 복제 이벤트의 진행률을 분 단위로 모니터링할 수 있다.
- s3:Replication:OperationFailedReplication 이벤트 유형은 복제에 적합한 객체가 복제에 실패할 때 알려준다.
- s3:Replication:OperationMissedThreshold 이벤트 유형은 복제에 적합한 객체가 복제에 대한 15분 임계값을 초과할 때 알려준다.
- s3:Replication:OperationReplicatedAfterThreshold 이벤트 유형은 S3 복제 시간 제어를 사용하는 복제에 적합한 객체가 15분 임계값 이후에 복제될 때 알려준다.
- s3:Replication:OperationNotTracked 이벤트 유형은 객체가 S3 복제 시간 제어를 사용하지만 복제 지표에 의해 더 이상 추적되지 않는 복제에 적합할 때 알려준다.
🔔 S3 수명 주기
- 수명 주기 동안 객체가 비용 효율적으로 저장되도록 관리하려면 해당 Amazon S3 수명 주기를 구성한다.
- S3 수명 주기 구성은 Amazon S3이 객체 그룹에 적용하는 작업을 정의하는 일련의 규칙이다.
- 다음과 같은 두 가지 유형의 작업이 있다.
전환 작업
이 작업은 객체가 다른 스토리지 클래스로 전환되는 시기를 정의한다.
예를 들어, 생성 후 30일이 지나면 객체를 S3 STANDARD-IA 스토리지 클래스로 전환하거나 생성 후 1년이 지나면 객체를 S3 Glacier Flexible Retrieval 스토리지 클래스에 아카이브하도록 선택할 수 있다.
수명 주기 전환 요청과 관련된 비용이 있다.
만료 작업
이 작업은 객체가 만료되는 시기를 정의한다.
Amazon S3에서 만료된 객체를 자동으로 삭제합니다.
수명 주기 만료 비용은 선택한 객체 만료 시점에 따라 달라진다.
🔔 S3 수명 주기
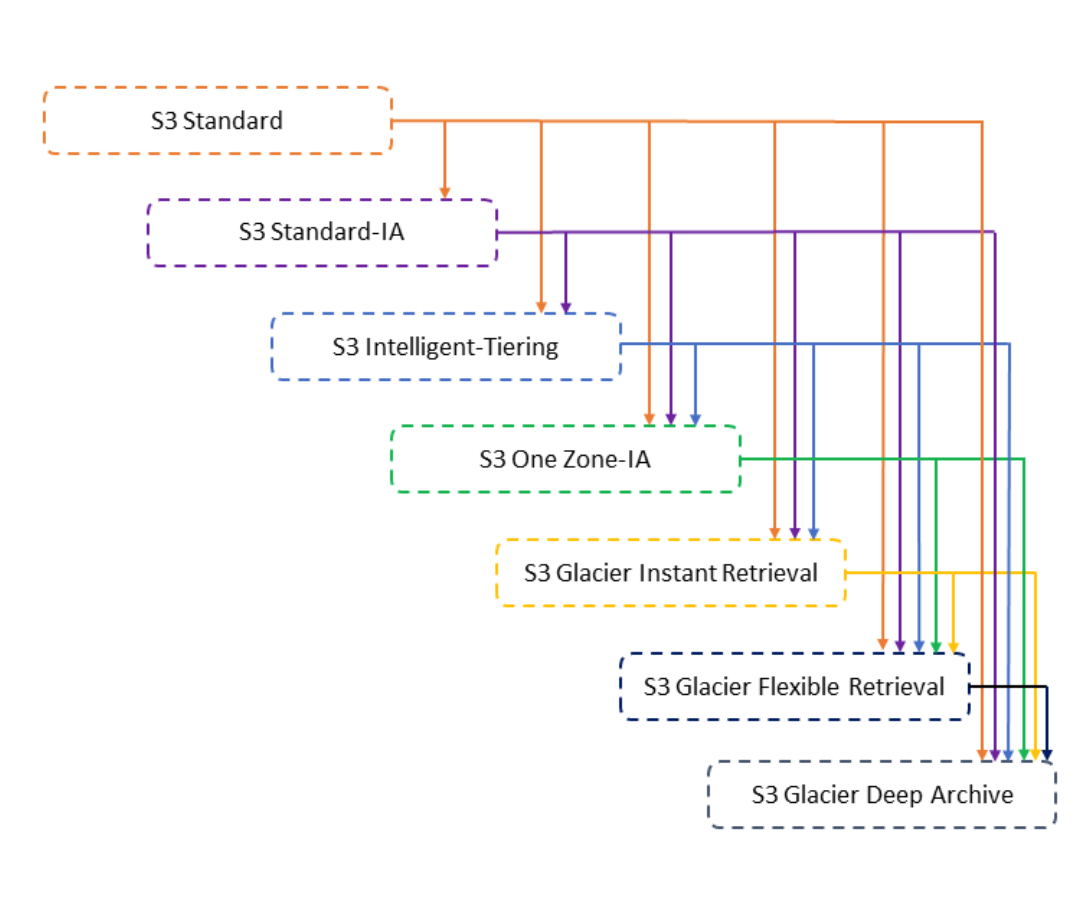
💡 S3 Standard
- 범용
- 여러 AZ에 걸쳐 높은 객체 내구성을 제공하고 전체 가용 영역에 영향을 미치는 이벤트에 대한 복원력이 있다.
- S3 Standard는 자주 액세스하는 데이터를 위해 높은 내구성, 가용성 및 성능을 갖춘 객체 스토리지를 제공한다.
- S3 Standard는 짧은 지연 시간과 많은 처리량을 제공하므로 클라우드 애플리케이션, 동적 웹 사이트, 콘텐츠 배포, 모바일 및 게임 애플리케이션, 빅 데이터 분석 등의 다양한 사용 사례에 적합하다.
- S3 스토리지 클래스를 객체 수준에서 구성할 수 있으며 S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, S3 One Zone-IA 전반에 걸쳐 저장된 여러 객체가 단일 버킷에 포함될 수 있다.
- 또한 S3 수명 주기 정책을 사용하여 애플리케이션 변경 없이 자동으로 스토리지 클래스 간에 객체를 전환할 수 있다.
💡 S3 Standard-IA
- 빈번하지 않은 액세스
- S3 Standard-IA는 자주 액세스하지 않지만 필요할 때 빠르게 액세스해야 하는 데이터에 적합하다.
- 여러 가용 영역에 걸쳐 99.999999999%의 객체 내구성과 99.9%의 연중 가용성을 제공하도록 설계
- 하나의 가용 영역 전체가 파괴되더라도 데이터 복원력 유지
- S3 Standard-IA는 S3 Standard의 뛰어난 내구성, 높은 처리량 및 짧은 대기 시간을 저렴한 GB당 스토리지 요금과 GB당 검색 요금으로 제공한다.
- 저렴한 비용과 높은 성능의 조합을 제공하는 S3 Standard-IA는 장기 스토리지, 백업 및 재해 복구 파일용 데이터 스토어에 이상적이다.
- S3 스토리지 클래스를 객체 수준에서 구성할 수 있으며 S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, S3 One Zone-IA 전반에 걸쳐 저장된 여러 객체가 단일 버킷에 포함될 수 있다.
- 또한 S3 수명 주기 정책을 사용하여 애플리케이션 변경 없이 자동으로 스토리지 클래스 간에 객체를 전환할 수 있다.
💡 S3 Intelligent-Tiering
- 알 수 없거나 변화하는 액세스
- Infrequent Access 티어는 스토리지 비용을 최대 40% 줄인다.
- 성능에 대한 영향, 검색 요금 또는 운영 부담 없이 액세스 빈도에 따라 가장 비용 효율적인 액세스 티어로 데이터를 자동으로 이동하여 세분화된 객체 수준에서 스토리지 비용을 자동으로 절감해주는 최초의 클라우드 스토리지
- S3 Intelligent-Tiering은 Frequent, Infrequent Access 및 Archive Instant Access 티어에서 자주 액세스하는 데이터, 자주 액세스하지 않는 데이터, 그리고 거의 액세스하지 않는 데이터에 대해 밀리초 단위의 대기 시간과 높은 처리량을 제공한다.
- 거의 모든 워크로드, 특히 데이터 레이크, 데이터 분석, 새로운 애플리케이션 및 사용자 생성 콘텐츠에 대한 기본 스토리지 클래스로 S3 Intelligent-Tiering을 사용할 수 있다.
I
💡 S3 One Zone-IA
- 자주 액세스하지 않지만 필요할 때 빠르게 액세스해야 하는 데이터에 적합
- 최소 3개의 가용 영역(AZ)에 데이터를 저장하는 다른 S3 스토리지 클래스와는 달리, S3 One Zone-IA는 단일 AZ에 데이터를 저장하며 비용이 S3 Standard-IA보다 20% 적게 든다.
- S3 One Zone-IA는 자주 액세스하지 않는 데이터에 대한 저렴한 옵션을 원하지만 S3 Standard 또는 S3 Standard-IA 스토리지와 같은 가용성 및 복원력이 필요 없는 고객에게 적합하다.
- 이 서비스는 온프레미스 데이터 또는 쉽게 다시 생성할 수 있는 데이터의 보조 백업 복사본을 저장하는 경우 좋은 선택이다.
- 또한, S3 교차 리전 복제를 사용하여 다른 AWS 리전에서 복제한 데이터를 위한 비용 효과적인 스토리지로 사용할 수 있다.
💡 Amazon S3 Glacier
- 데이터 아카이브를 위해 구축된 제품으로, 클라우드에서 가장 뛰어난 성능, 가장 뛰어난 검색 유연성, 그리고 가장 저렴한 비용의 아카이브 스토리지를 제공하도록 설계
- 다양한 액세스 패턴과 스토리지 기간에 최적화된 세 가지 아카이브 스토리지 클래스 중에서 선택할 수 있다.
- 밀리초 단위 : S3 Glacier Instant Retrieval
- 5~12시간의 무료 대량 검색 또는 몇 분 내 검색을 지원 : S3 Glacier Flexible Retrieval
- 12~48시간의 데이터 검색 시간을 지원하며 클라우드에서 가장 저렴한 스토리지 비용을 제공 : S3 Glacier Deep Archive
🔔 S3 Transfer Acceleration
- 거리가 먼 클라이언트와 S3 버킷 간에 파일을 빠르고, 쉽고, 안전하게 전송할 수 있게 해준다.
- Transfer Acceleration은 전 세계적으로 분산되어 있는 Amazon CloudFront의 엣지 로케이션을 활용한다.
- 엣지 로케이션에 도착한 데이터는 최적화된 네트워크 경로를 통해 Amazon S3로 라우팅된다.
- 전 세계 각지에서 중앙의 버킷으로 업로드하는 고객이 있을 경우
- 전 세계에 정기적으로 수 기가 바이트에서 수 테라바이트의 데이터를 전송할 경우
- 대역폭을 충분히 활용하지 못할 때
🔔 S3 Select
- 간단한 SQL 식을 사용하여 애플리케이션이 객체에서 일부 데이터만 가져올 수 있도록 하는 서비스
- 애플리케이션에 필요한 데이터만 가져옴으로써, 상당한 성능 향상 (최대 400%) 을 이룰 수 있다.
🔔 S3 Glacier Select
- 간단한 구조화 쿼리 언어(SQL) 문을 S3 Glacier의 데이터에서 직접 사용하여 필터링 작업 수행
- S3 Glacier 아카이브 객체에 대해 SQL 쿼리를 제공하면 S3 Glacier Select가 쿼리를 실행하고 출력 결과를 S3에 작성
- 더 자주 사용하는 계층으로 데이터를 복원할 필요 없이 Glacier에 저장된 데이터에서 쿼리 및 사용자 지정 분석을 실행
다음 중 한 가지를 지정해서 액세스 시간과 비용 요건을 기준으로 아카이브를 가져온다.
아카이브 검색 옵션
- Expedited 신속 (1분~5분)
- Standard 표준 (3~5시간)
- Bulk 벌크(보통 5~12시간
🔔 Glacier Vault Lock
- 한 번 쓰고 여러 번 읽는 WORM 모델을 적용하기 위함
- 규정 준수와 데이터 보존을 위해 사용, 객체가 Glacier 볼트로 가면 그 후에 볼트 잠금 정책을 추가하여 객체가 지워지거나 또는 정책 자체가 지워지는 것을 방지
🔔 S3 Object Lock
- 특정 시간 동안의 객체 버전 삭제를 막는다.
📒 AWS Storage Gateway
3가지 유형 : File Gateway / Volume Gateway / Tape Gateway
🔔 File Gateway
💡 S3 File Gateway
Amazon S3 파일 게이트웨이는 다음과 같은 파일 인터페이스를 지원한다.
Amazon S3 서비스와 가상 소프트웨어 어플라이언스를 결합한다.
이 조합을 사용하면 NFS 및 SMB 같은 업계 표준 파일 프로토콜을 사용하여 Amazon S3 S3에 객체를 저장하고 검색할 수 있다.
소프트웨어 어플라이언스 또는 게이트웨이는 VMware ESXi 또는 Microsoft Hyper-V 또는 Linux 커널 기반 가상 머신(KVM) 하이퍼바이저에서 실행 중인 가상 머신(VM)으로 온프레미스 환경에 배포된다.
이 게이트웨이를 통해 파일 또는 파일 공유 탑재 지점으로 S3 내 객체에 액세스할 수 있습니다. S3 파일 게이트웨이를 통해 다음 작업을 할 수 있다.
💡Amazon FSx File Gateway
Storage Gateway 파일 게이트웨이, 볼륨 게이트웨이 및 테이프 게이트웨이 스토리지 솔루션을 제공한다.
Amazon FSx 파일 게이트웨이 (FSx 파일) 는 온프레미스 시설에서 Windows 파일 서버용 클라우드 인 FSx 파일 공유에 대한 지연 시간이 짧고 효율적인 액세스를 제공하는 새로운 파일 게이트웨이 유형이다.
대기 시간이나 대역폭 요구 사항으로 인해 온-프레미스 파일 스토리지를 유지 관리하는 경우 FSx File을 사용하여 완전히 관리되고 안정적이며 사실상 무제한의 Windows 파일 공유에 원활하게 액세스할 수 있다.
이점
- 온프레미스 파일 서버를 제거하고 모든 데이터를 통합AWS클라우드 스토리지의 규모와 경제성을 활용한다.
- 클라우드 데이터에 대한 온프레미스 액세스가 필요한 작업을 포함하여 모든 파일 워크로드에 사용할 수 있는 옵션을 제공한다.
- 온프레미스를 유지해야 하는 애플리케이션은 이제 동일한 짧은 지연 시간과 높은 성능을 경험할 수 있다.
- AWS네트워크에 부담을 주지 않고 가장 까다로운 애플리케이션이 겪는 지연 시간에 영향을 주지 않습니다.
🔔 Volume Gateway
볼륨 게이트웨이볼륨 게이트웨이는 온프레미스 애플리케이션 서버에서 iSCSI(Internet Small Computer System Interface) 장치로 탑재할 수 있도록 클라우드 기반 스토리지 볼륨을 제공한다.
볼륨 게이트웨이는 VMware ESXi, KVM 또는 Microsoft Hyper-V 하이퍼바이저에서 실행되는 VM으로 온프레미스 환경에 배포된다.
이 게이트웨이가 지원하는 볼륨 구성은 아래와 같다.
💡 캐싱 볼륨
데이터는 S3에 저장하고 자주 액세스하는 데이터 하위 집합의 사본은 로컬에 저장한다.
캐싱 볼륨을 통해 기본 스토리지 비용이 상당 부분 절감되고 온프레미스 스토리지를 확장할 필요성이 최소화한다.
자주 액세스하는 데이터에 액세스할 때는 지연 시간이 짧아지는 효과도 있다.
💡 저장 볼륨
전체 데이터 세트에 대한 지연 시간이 낮은 액세스가 필요한 경우 먼저 모든 데이터를 로컬로 저장하도록 온프레미스 게이트웨이를 구성한다.
그런 다음 이 데이터의 특정 시점 스냅샷을 Amazon S3에 비동기식으로 백업한다.
이렇게 구성하면 내구성과 경제성이 좋은 오프사이트 백업 방식으로 로컬 데이터 센터나 Amazon Elastic Compute Cloud(Amazon EC2)로 복구할 수 있다.
예를 들어 재해 복구를 위해 교체 용량이 필요한 경우, 백업을 Amazon EC2로 복구할 수 있다.
🔔 Tape Gateway
테이프 게이트웨이는 클라우드 지원 가상 테이프 스토리지를 제공한다.
테이프 게이트웨이를 사용하면 S3 Glacier Flexible Retrieval 또는 S3 Glacier Deep Archive에 백업 데이터를 비용 효율적이고 안정적으로 보관할 수 있다.
테이프 게이트웨이는 비즈니스 요구 사항에 따라 원활하게 확장되고 물리적 테이프 인프라를 프로비저닝, 확장 및 유지 관리하는 운영상의 부담을 없애주는 가상 테이프 인프라를 제공한다.
Storage Gateway는 VMware ESXi, KVM 또는 Microsoft Hyper-V 하이퍼바이저에서 실행되는 VM 어플라이언스로 온프레미스, 하드웨어 어플라이언스로 또는 AWS에서 Amazon EC2 인스턴스로 배포할 수 있다.
게이트웨이를 EC2 인스턴스에 배포하여 AWS에서 iSCSI 스토리지 볼륨을 프로비저닝한다.
재해 복구, 데이터 미러링 및 Amazon EC2에서 호스팅되는 애플리케이션용 스토리지 제공을 위해 EC2 인스턴스에서 호스팅되는 게이트웨이를 사용할 수 있다.
- AWS Storage Gateway는 사실상 무제한의 클라우드 스토리지에 대한 온프레미스 액세스 권한을 제공하는 하이브리드 클라우드 스토리지 서비스이다.
- Storage Gateway는 iSCSI, SMB 및 NFS와 같은 표준 스토리지 프로토콜 세트를 제공하므로 기존 애플리케이션을 다시 작성하지 않고 AWS 스토리지를 사용할 수 있다.
- Amazon 클라우드 스토리지 서비스에 데이터를 안전하고 안정적으로 저장하면서 자주 액세스하는 데이터는 온프레미스에 캐싱하여 지연 시간이 짧은 성능을 제공한다.
- Storage Gateway는 변경된 데이터만 전송하고 데이터를 압축하여 AWS로의 데이터 전송을 최적화한다.
- Storage Gateway는 Amazon S3 및 Amazon FSx for Windows File Server 클라우드 스토리지와 기본적으로 통합하여 데이터를 클라우드 내에서 처리할 수 있고, AWS Identity and Access Management(IAM)와 통합하여 서비스 및 리소스에 대한 액세스 관리를 안전하게 보호할 수 있으며, AWS Key Management Service(KMS)와 통합하여 클라우드에 저장된 데이터를 암호화하고, Amazon CloudWatch와 통합하여 모니터링 기능을 제공하고, AWS CloudTrail과 통합하여 계정 활동을 로깅할 수 있다.
