MariaDB

MariaDB
💡 MariaDB는 오픈 소스의 관계형 데이터베이스(RDBMS)로 MySQL의 포크(fork)로 시작되어, MySQL과 API(Application Programming Interface) 및 ABI(Application Binary Interface) 호환성을 유지하면서도 독자적인 기능과 개선사항을 추가해 나가고 있다.
MariaDB는 웹 기반 애플리케이션, 데이터 웨어하우징, 그리고 다양한 데이터 관리 요구사항을 충족시키기 위해 널리 사용된다.
MySQL의 역사
💡 1995년 5월에 MySQL AB사에서 첫번째 버전이 발표되고 이후 1998년에 윈도우 버전(Windows 95)의 MySQL이 발표된다.
2008년에 썬 마이크로시스템즈사가 MySQL AB를 인수하고 5.1버전을 발표한다.
이후 2009년에 썬 마이크로시스템즈사가 오라클에 인수합병되어 현재는 오라클사가 권리를 가지고 있다.2018년 4월에 8.0버전이 발표 되어 전 세계적으로 널리 사용되고 있다.
- MySQL 아키텍처
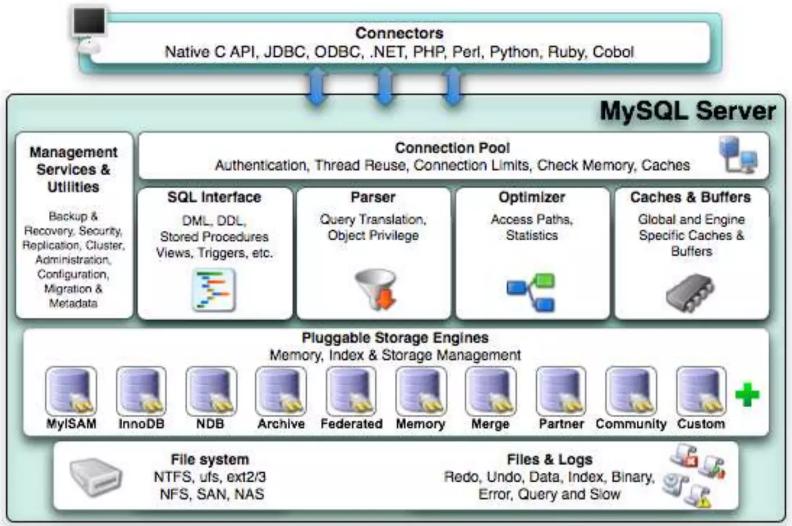
MariaDB의 역사
💡 MariaDB는 2009년 MySQL의 원 개발자 중 한 명인 미카엘 비데니우스(Michael Widenius)에 의해 창립되었다.
MySQL 커뮤니티 내에서 Oracle의 소유권과 개발 방향에 대한 우려가 커지면서 MySQL과의 완전환 호환성을 목표로 하며 MySQL 대비 여러가지 성능 개선 및 새로운 기능을 제공한다.
- MariaDB 아키텍처
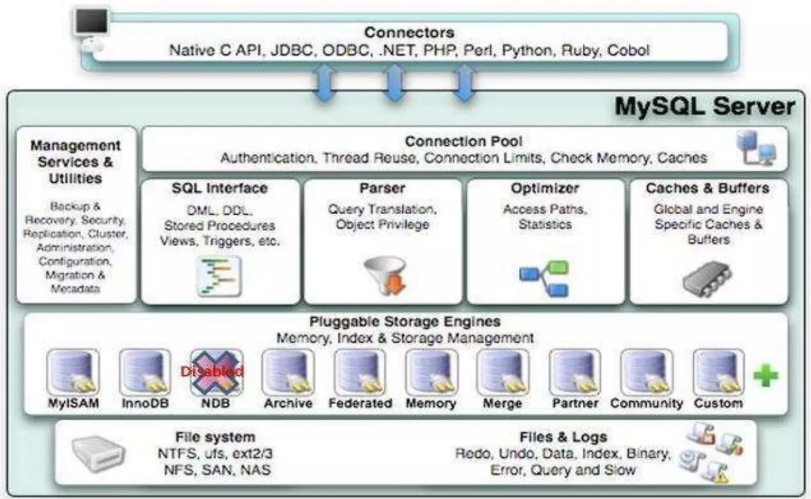
MariaDB의 특징
| 특징 | 내용 |
|---|---|
| MySQL과의 호환성 | MariaDB는 MySQL과의 높은 호환성을 유지하며 MySQL에서 MariaDB로의 전환은 매우 간단하다. |
| 개선된 성능 | MariaDB는 쿼리 최적화, 새로운 인덱스 및 스토리지 엔진, 병렬 복제 등 MySQl 대비 성능을 향상시킨 여러 기능을 제공한다. |
| 오픈 소스 | GPL v2 라이선스 하에 배포되어 누구나 자유롭게 사용, 수정, 배포할 수 있다. |
| 다양한 스토리지 엔진 지원 | MariaDB는 Aria, InnoDB, MyRocks, TokuDB등 다양한 스토리지 엔진을 지원하여, 사용자의 요구 사항에 맞게 데이터 저장 방식을 선택할 수 있다. |
| 활발한 커뮤니티 및 개발 | MariaDB는 활발한 커뮤니티와 지속적인 개발로 새로운 기능과 보안 패치를 꾸준히 제공하고 있다. |
MariaDB에서 제공하는 다양한 데이터베이스 엔진
1) Aria
: Aria는 MariaDB의 기본 스토리지 엔진 중 하나로, MyISAM의 후속작.
주로 읽기 중심의 작업에 최적화 되어 있고 향상된 캐싱 및 인덱싱 기능을 제공한다.
크래시 복구 기능이 강화되어 있어 시스템 장애 발생 시 데이터 복구가 더 용이하다.2) InnoDB
: MySQL 및 MariaDB에서 널리 사용되는 스토리지 엔진이다.
트랜잭션을 지원하며, 롤백 및 크래시 복구 기능을 제공하여 높은 신뢰성을 보장한다.
외래 키 제약 조건을 지원하여 데이터 무결성을 유지한다.
행 수준의 잠금 및 MVCC(Multi-Version Concurrency Control)를 통해 동시성을 높이고 락 경합을 최소화한다.3) MyRocks
: Facebook에서 개발한 MySQL용 스토리지 엔진으로 RocksDB에 기반을 두고있다.
SSD 환경에서 우수한 성능을 발휘하며 효율적인 디스크 사용과 빠른 데이터 압축이 가능하다.
읽기 및 쓰기 작업에 최적화되어 있으며, 특히 쓰기 작업에서 고성능을 보인다.4) TokuDB
: TokuDB는 고성능의 쓰기 집중적 애플리케이션에 적합한 스토리지 엔진이다.
고급 압축 기술을 사용하여 대용량 데이터에 대한 디스크 공간 사용을 최적화한다.
MVCC를 지원하며, 동시성과 크래시 복구 기능이 강화되어 있다.
특히 대용량 데이터 세트의 인덱싱에서 뛰어난 성능을 보인다.
MariaDB 동작원리
MariaDB이 쿼리를 실행하는 과정
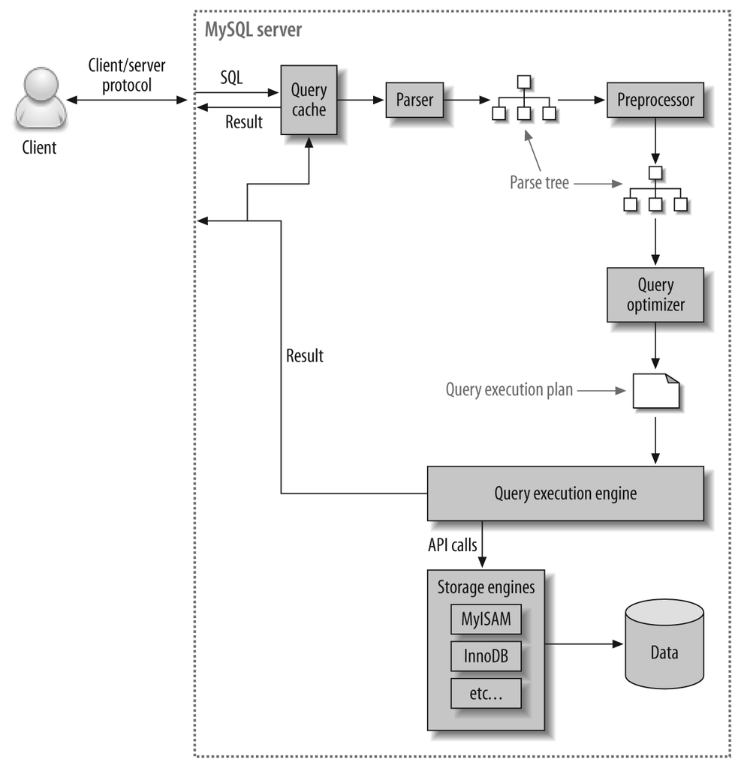
SQL쿼리가 MariaDB서버로 전달되어 결과가 반환되는 과정

-
클라이언트/서버 통신
: 클라이언트(HeidiSQL, 커맨드 라인 인터페이스, 프로그래밍 언어 API 등)에서 SQL 쿼리를 MariaDB 서버로 전송한다. -
쿼리 파싱
: MariaDB 서버가 쿼리를 받으면 먼저 쿼리를 파싱한다. 파서(parser)는 SQL문장을 이해할 수 있는 단위로 나누고 이 때 문장의 문법이 유효한지, 키워드가 올바르게 사용되었는지, 사용된 컬럼과 테이블이 실제로 존재하는지 등을 확인하고 문법에 오류가 있으면 파서는 오류 메시지를 반환하고 프로세스를 중단한다. -
최적화 및 실행 계획 생성
: 파싱이 성공적으로 완료되면, 쿼리 최적화기(optimizer)가 작동하여 파싱된 쿼리를 가능한 한 효율적으로 실행할 수 있는 방법을 결정한다. 사용할 인덱스 결정, 조인 순서, 데이터를 읽는 방법 등을 포함하여 ‘실행계획’이라는 형태로 생성된다. -
쿼리 실행
: 실행 계획에 따라, MariaDB 서버는 스토리지 엔진을 통해 필요한 데이터를 불러오거나 변경하고 이 단계에서는 실제 데이터베이스 파일 또는 인덱스에 접근한다. -
결과 반환
: 쿼리 실행이 완료되면 MariaDB 서버는 결과 세트(Result Set)를 클라이언트에게 반환한다. SELECT의 경우는 검색된 행들이 되고 INSERT, UPDATE, DELETE의 경우 영향을 받는 행의 수가 된다.- INSERT, UPDATE, DELETE은 숫자를 result set으로 반환
쿼리를 실행 과정의 중요 키워드
SQL 파싱(PARSING)
- ‘파싱’이라는 용어는 주로 컴퓨터 과학에서 사용되며, 일련의 문자열이나 데이터를 어떤 규칙에 따라 분석하고 이해하는 과정을 말한다.
- MariaDB 서버는 쿼리를 파싱하면 올바른 구문을 갖추얻는지, 참조하는 테이블과 컬럼이 실제로 존재하는지, 사용자가 그 테이블과 컬럼에 액세스할 권한이 있는지 등을 검사한다.
- 파싱 순서
-
렉시컬 분석(Lexical Analysis) 진행
: 입력된 쿼리 문자열을 키워드나 리터럴, 식별자 등의 쿼리의 최소 단위로 분리한다. 예를 들어 ‘SELECT’, ‘*’, ‘FROM’, ‘WHERE’와 같은 키워드, 리터럴, 식별자를 토큰들로 만들게 된다. -
구문 분석(Syntax Analysis) 진행
: 토큰들이 MariaDB의 문법에 맞는지 확인하고 오류가 발견되면 쿼리는 거부되고, 사용자에게 오류 메시지가 반환된다. 예를 들어, ‘WHERE’절 뒤에는 조건이 와야 하고 ‘SELECT’바로 다음에 ‘WHERE’가 오면 안되는 등의 규칙을 검사한다.
-
의미 분석(Semantic Analysis) 진행
: 쿼리가 의미적으로 올바른지 확인한다. 예를 들어, 참조하는 테이블과 컬럼이 존재하는지, 데이터 형식이 맞는지 등을 검사한다. -
SQL과 실행 계획 시 라이브러리캐시에 캐싱 되어 있는지 확인
-
캐싱되어 있을 시 소프트 파싱, 캐싱 되어 있지 않다면 하드 파싱
파싱의 종류와 캐시
1) 소프트 파싱
: SQL과 실행 계획을 캐시에서 찾아 곧바로 쿼리 실행 단계로 넘어가는 경우2) 하드 파싱
: SQL과 실행 계획을 캐시에서 찾지 못해 최적화 과정을 거치고 나서 실행 단계로 넘어가는 경우3) 라이브러리 캐시
: 해시구조로 엔진에서 관리되며 SQL마다 해시 값에 따라 여러 해시 버킷으로 나뉘어 저장되고 SQL을 찾을 때는 SQL 문장을 해시 함수에 적용하여 반환되는 해시 값을 이용해서 해시 버킷을 탐색한다.
-
옵티마이저(Optimizer)
- 옵티마이저는 쿼리를 실행하는 데 필요한 가장 효율적인 방법을 결정하기 위해 사용된다.
- MariaDB에서는 기본적으로 CBO를 사용하며 RBO를 제공하지 않는다.
옵티마이저의 종류
1) 비용기반 옵티마이저(Cost-Based Optimizer, CBO)
: 쿼리를 실행하는 데 필요한 비용을 추정하여 쿼리 실행 계획을 선택한다. 이 비용은 디스크
I/O, CPU 사용량 등의 자원 사용을 고려하고 데이터베이스의 통계 정보(테이블의 행 수,
인덱스의 유니크한 값 등)를 사용하여 비용을 추정한다.데이터베이스의 실제 상황을 더 잘 반영하는 쿼리 실행 계획을 선택할 수 있다.2) 규칙기반 옵티마이저(Rule-Based Optimizer, RBO)
: 고정된 세트의 규칙을 기반으로 쿼리 실행 계획을 결정한다. 규칙은 개발자나 DBA(Database
Administrator)가 설정할 수 있으며 특정 상황에서 특정 유형이 연산이 더 효과적이라는 경험
적인 지식에 기반해 정해진다.실제 데이터 분포나 통계를 고려하지 않으므로 때때로 비효율적인 쿼리 실행 계획을 선택할 수 있다.
실행 계획
-
실행계획은 SQL을 어떤 순서로 어떻게 진행할 지에 대한 단계별 계획을 결정하는 것이다.
-
MariaDB에서는 ‘EXPLAIN’ 명령어를 사용해 실행 계획을 확인할 수 있다.
-
예제 코드
CREATE TABLE products ( fruit_code INT PRIMARY KEY, fruit_name VARCHAR(100), fruit_price DECIMAL(10, 2) ); INSERT INTO products (fruit_code , fruit_name , fruit_price ) VALUES (1, 'Apple', 2000), (2, 'Orange', 2500), (3, 'Banana', 1700); EXPLAIN SELECT * FROM products WHERE fruit_name = 'Orange'; -
실행결과

각 열의 의미
id:EXPLAIN의 결과 내에서 쿼리의 순서를 식별하는 데 사용되는 값이다. 같은 id값을 가진 행은 하나의 ‘스텝’ 내에서 실행되며, id값이 다른 행은 다른 ‘스텝’을 나타낸다. id값이 작을수록 먼저 실행되는 쿼리이다.select_type: SELECT 쿼리의 유형을 나타낸다.- SIMPLE: 하위 쿼리나 'UNION'이 없는 단순 SELECT 쿼리를 나타낸다.
- PRIMARY: 가장 바깥쪽에 있는 SELECT 쿼리를 나타낸다.
- SUBQUERY: SELECT나 WHERE 절에 있는 하위 쿼리를 나타낸다.
- DERIVED: FROM 절에서 사용되는 하위 쿼리를 나타낸다.
- UNION: UNION 쿼리의 첫 번째 SELECT를 제외한 나머지 SELECT를 나타낸다.
- UNION RESULT: UNION 쿼리의 결과를 나타낸다.
table: 접근하고 있는 테이블의 이름이다.type: 접근된 테이블의 행들이 어떻게 스캔되었는지를 나타낸다.- system: 테이블에 하나의 행만 존재할 경우이다.
- const: 테이블에 하나의 매칭된 행만 존재할 경우이다.
- eq_ref: 조인 시, 다른 테이블에서 하나의 행만을 참조하는 경우이다.
- ref: 인덱스를 통해 하나 이상의 행을 참조하는 경우이다.
- range: 인덱스를 통해 특정 범위의 행을 스캔하는 경우이다.
- index: 인덱스 전체를 스캔하는 경우이다.
- ALL: 테이블 전체를 스캔하는 경우이다.
key: 실제로 쿼리에서 사용하는 인덱스이다.key_len: 사용된 키의 길이이다.ref: 인덱스의 키 값이 사용되는 컬럼을 나타낸 상수이다.rows: 쿼리가 처리할 행의 예상 수이다.Extra: 쿼리를 실행하는 방법에 대한 추가 정보를 제공한다.- Using where: WHERE 절을 사용하여 행을 필터링했음을 나타낸다.
- Using temporary: 쿼리를 처리하기 위해 임시 테이블을 사용했음을 나타낸다. 이는 종종 정렬을 위해 발생한다.
- Using filesort: 결과를 정렬하기 위해 디스크 기반의 정렬 알고리즘을 사용했음을 나타낸다.
- Using index: 컬럼 데이터를 읽지 않고 인덱스를 통해 정보를 얻었음을 나타낸다. 이를 '커버링 인덱스'라고도 한다.
- Using join buffer: 조인 버퍼를 사용했음을 나타낸다. 이는 일반적으로 블록 중첩 루프 조인이 발생할 때 나타난다.
-
-
옵티마이저가 제대로 동작하려면 데이터베이스의 통계 정보가 정확해야 한다. 이를 위해 MariaDB는 테이블과 인덱스의 통계 정보를 주기적으로 업데이트 해야 하는데 데이터의 분포가 크게 바뀌었거나, 테이블의 크기가 크게 변했다면 ‘ANALYZE TABLE’ 명령어를 사용해 통계 정보를 직접 업데이트 해서 더 정확한 실행계획을 만들 수 있다.
-
예제 코드
ANALYZE TABLE products; -
실행 결과
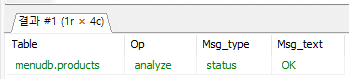
각 열의 의미
Table: 이 열은 분석되는 테이블의 이름을 표시한다.Op: 이 열은 수행된 작업을 표시한다.- analyze: ANALIZE TABLE 명령을 실행했음을 나타낸다.
Msg_type: 이 열은 메시지의 유형을 나타낸다.- status: 작업의 상태에 대한 메시지이다.
- error: 오류가 발생했음을 나타내는 메시지이다.
- info: 일반 정보에 대한 메시지이다.
- warning: 경고 또는 주의해야 할 사항에 대한 메시지이다.
- note: 보조적인 정보 또는 참고사항에 대한 메시지이다.
Msg_text: 이 열은 메시지의 내용을 나타낸다.Msg_type열에 따라 해당 메시지에 대한 세부 정보를 제공한다.- "Table is already up to date": 이미 최신 상태인 테이블에 ANAYLIZE가 실행되었음을 의미한다.
- "OK": ANAYLIZE 작업이 성공적으로 완료되었음을 나타낸다.
- "Table does not support optimize, doing recreate + analyze instead": 최적화를 지원하지 않는 테이블에 대해 다시 생성하고 분석하는 작업이 수행되었음을 나타낸다.
-
-
실행 계획의 구성요소
- 조인 순서(Join Order): 여러 테이블이 참여하는 쿼리에서 각 테이블이 어떤 순서로 처리될 것인지를 정한다.. 조인 순서는 쿼리의 성능에 큰 영향을 미치며, 일반적으로 조인 조건에서 가장 많은 데이터를 줄일 수 있는 테이블을 먼저 처리한다.
- 조인 기법(Join Method): 조인 기법은 두 테이블을 조인하는 방법을 나타낸다. MariaDB는 Nested Loops, Hash Join 등 여러 가지 조인 기법을 사용한다. 각기 다른 조인 기법은 데이터의 분포, 인덱스의 유무, 조인 조건 등에 따라 서로 다른 성능을 보인다.
- 액세스 기법(Access Method): 액세스 기법은 테이블의 데이터에 어떻게 접근할 것인지를 결정한다. 이는 테이블 스캔(Full Table Scan), 인덱스 스캔(Index Scan), 인덱스 범위 스캔(Index Range Scan), 인덱스 탐색(Index Seek) 등의 방식이 있다. 액세스 기법은 테이블의 크기, 데이터 분포, 인덱스의 유무, 쿼리 조건 등에 따라 달라진다.
- 최적화 정보(Optimization Information): 쿼리를 실행하는 데 필요한 기타 정보를 포함한다. 예를 들어, 어떤 인덱스를 사용할 것인지, 테이블의 통계 정보는 어떤지, 쿼리에서 사용하는 상수 값은 무엇인지 등이 이에 포함된다.
- 연산(Operation): 쿼리에 포함된 각 연산을 실행하는 방법을 결정한다. 이는 WHERE 조건에서 사용하는 비교 연산, SELECT 절에서 수행하는 집계 연산, 그리고 ORDER BY 절에서 수행하는 정렬 연산 등을 포함한다. 연산 방법은 사용하는 함수, 연산자, 데이터 타입, 데이터의 분포 등에 따라 달라진다.
MariaDB 계정 생성 및 권한 부여
-- 계정 생성 후 데이터베이스 활용
-- 1) 새로운 swcamp 계정 만들기
CREATE USER 'swcamp'@'%' IDENTIFIED BY 'swcamp'; -- 'localhost' 대신 '%'를 쓰면 외부 ip로 접속 가능하다.
-- 현재 존재하는 데이터베이스 확인
SHOW databases;
-- mysql 데이터베이스로 계정 정보 확인하기
USE mysql; -- 기본 적으로 제공되는 mysql database
SELECT * FROM user; -- mysql database에서 user를 확인해 계정이 추가된 것을 확인한다.
-- 2) 데이터베이스 생성 후 계정에 권한 부여
-- 데이터베이스(스키마) 생성
CREATE DATABASE menudb;
-- CREATE SCHEMA menudb;
-- swcamp 계정의 권한 확인하기
SHOW GRANTS FOR 'swcamp'@'%';
-- 왼쪽 Navigator를 새로고침해서 menudb database(schema)가 추가된 것을 확인한다.
-- MySQL 또는 MariaDB는 개념적으로 database와 schema를 구분하지 않는다.
-- (CREATE DATABASE와 CREATE SCHEMA가 같은 개념이다.)
GRANT ALL PRIVILEGES ON menudb.* TO 'swcamp'@'%'; -- menu에 대한 모든 권한 부여
-- swcamp 계정의 바뀐 권한 확인하기
SHOW GRANTS FOR 'swcamp'@'%';
-- 3) 새로운 접속기 생성 후 접속하고 데이터베이스 활용하기
-- 좌측 상단의 '파일' 버튼을 눌러 '세션 관리자'에서 '신규'로 swcamp 계정 접속기를 만들어
-- 접속하고 database(schema)를 사용한다.
-- 접속기의 Connection Name은 'SWCAMP'로 지정
-- Parameters의 Username은 'swcamp'로 지정(계정명)
-- Default Schema(기본 데이터베이스(스키마) 설정)는 'menudb'로 지정
USE menudb;스키마(SCHEMA)
: 데이터베이스의 구조와 제약조건을 정의한 것
