개념 모델
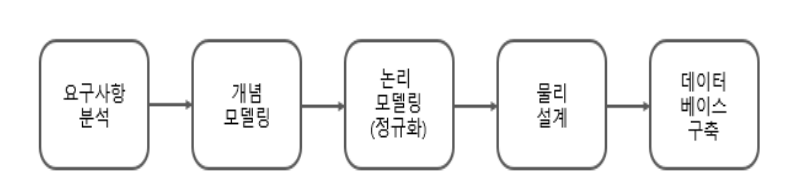
UML을 통한 개념 모델링
ERD를 통한 개념 모델링
- 요구분석 단계에서 정의된 핵심적인 엔터티와 엔터티의 주요 속성을 도출하고 엔터티 간의 관계를 도출하여 ERD를 생성하는 단계이다.
- 데이터의 범위나 구조를 용이하게 파악할 수 있는 상위 수준의 ERD 형태이다.
개념 모델의 목적
- 요구사항을 이해관계자들(사용자, IT담당자, 개발자, 모델러 등)이 이해할 수 있도록 데이터로 간결하게 표현하는 것이다.
- 대규모 프로젝트에서 개발자가 업무의 큰 틀을 잡는 데 도움을 준다.
- 개발 프로젝트 뿐 아니라 시스템의 유지, 보수에 있어서도 유용하게 사용할 수 있다.
개념 모델의 주의사항
- 이해 관계자들 사이에서 충분한 의사소통을 통해 구체적이고 명확하게 해석이 다르지 않도록 도출해야 한다.
- 관계형 데이터 모델인 개념 모델에서는 데이터만을 대상으로 표현해야 한다.
- 논리 모델링 기간의 1/3 정도에 해당하는 적지 않은 기간을 소요해서라도 충분한 의사소통이 필요하다.
- 복잡성에 빠지지 말아야 한다.
이상(Anomaly)
이상이란
- 중복된 데이터 때문에 데이터에 의도하지 않은 현상이 발생되면 이를 이상현상이라고 한다.
- 이상 현상에는 삽입 이상, 갱신 이상, 삭제 이상이 존재한다.
삽입 이상(Addition Anomaly)
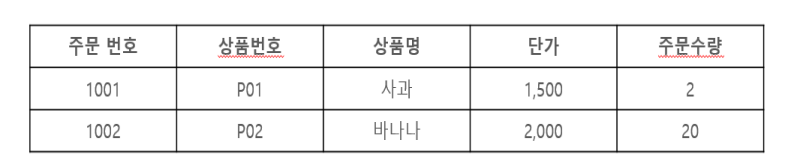
- 릴레이션에서 새로운 인스턴스를 삽입할 때 발생하는 데이터 이상 현상이다.
- 불필요한 정보를 함께 저장하지 않고는 어떤 정보를 저장하는 것이 불가능하다.
- 인스턴스 삽입 시 기존의 상품이라도 상품번호, 상품명, 단가를 모두 추가해 주어야 한다.
- 주문이 아닌 상품을 추가하기 위한 인스턴스 추가일 경우 주문번호나 주문 수량이라는 불필요한 속성의 값도 추가하여야 한다.
갱신 이상(Update Anomaly)
- 릴레이션에서 속성의 값을 업데이트할 때 발생하는 데이터 이상 현상이다.
- 반복된 데이터 중에 일부만 수정하면 데이터의 불일치가 발생한다.
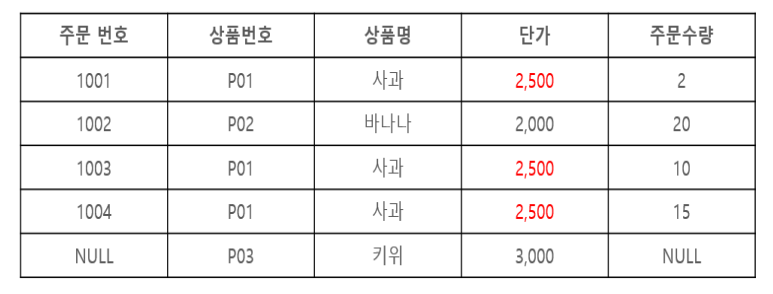
- 상품명이나 단가와 같은 속성의 값들이 변경될 경우 같은 상품은 빠짐없이 모두 수정해 주어야 한다.
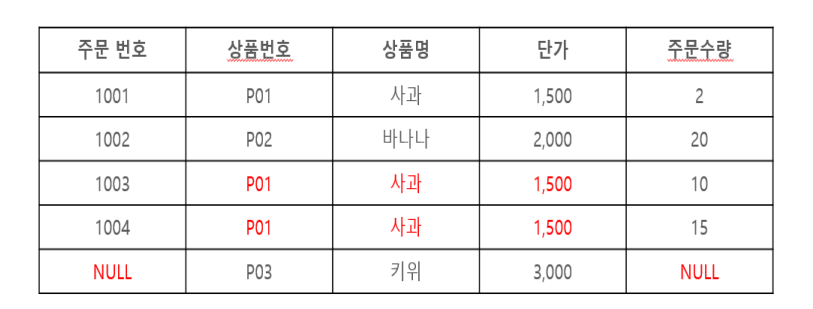
삭제 이상(Deletion Anomaly)
- 릴레이션에서 인스턴스를 삭제할 때 발생하는 데이터 이상 현상이다.
- 유용한 정보를 함께 삭제하지 않고는 어떤 정보를 삭제하는 것이 불가능하다.
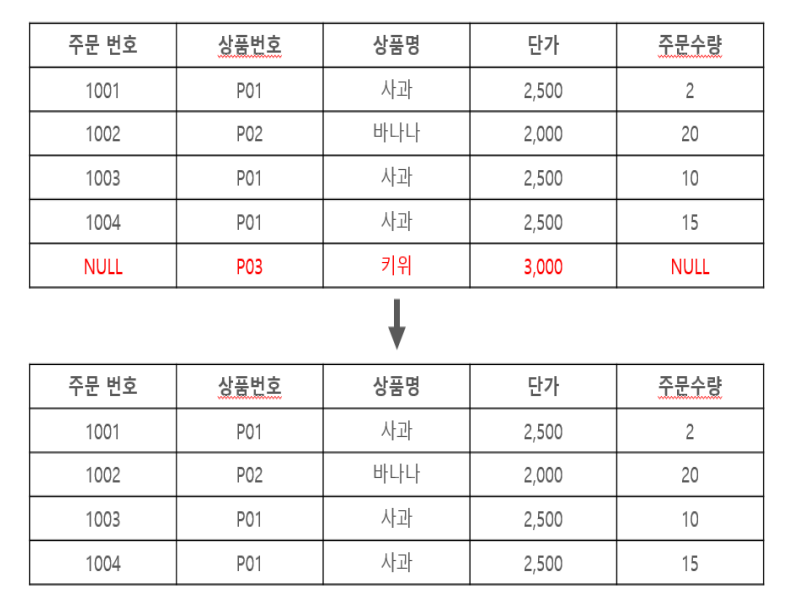
- 주문 내역을 삭제하려고 할때 관련 상품도 같이 소멸되어 상품 자체가 사라져 버리게 된다.
논리 모델(Logical Model)
논리 모델이란
- 개념 모델을 상세화하는 작업으로 전체 속성을 도출하고 도출되지 않은 대부분의 엔티티들과 관계들을 도출하는 단계이다.
- 정규화(Normalyzation)를 진행하는 단계이다.
논리 모델의 목적
-
업무에 대해 충분히 의견을 교환하고 반영하여 진행하는데 도움을 준다.
-
중복값을 제거하여 이상(Anomaly)현상을 제거하기 위해 속성간에 종속관계를 확인하고 엔터티를 분할한다.
논리 모델의 주의사항
- 업무 요건을 빠짐없이 정확하게 반영해야 한다.
- 더 이상 삭제할 엔터티나 속성은 없어야 한다.
- 주 식별자에 있어 효율성에 따라 인조 식별자를 채택할지에 대해 결정한다.
- 지나치게 성능 문제를 해결하려고 하지 않는다.
정규화(Normalization)
정규화의 목적
- 중복 데이터를 제거하여 안정성과 확장성을 도모한다.
- 안정성: 함수 종속을 기반으로 데이터의 성격에 맞는 엔터티가 도출되어 모델 구조를 정의할 수 있다.
- 확장성: 데이터의 정체성이 그대로 반영되어 업무가 수정되거나 추가 되더라도 엔터티에 반영하기가 수월해 진다.
함수 종속
- 릴레이션 내에 존재하는 속성 간의 종속성을 의미한다.
- 대표 속성(식별자)이 나머지 속성을 유일하게 식별할 수 있다면 대표 속성과 나머지 속성 사이에는 연관관계가 성립하고 이것을 함수 종속이라고 한다.
정규화의 종류
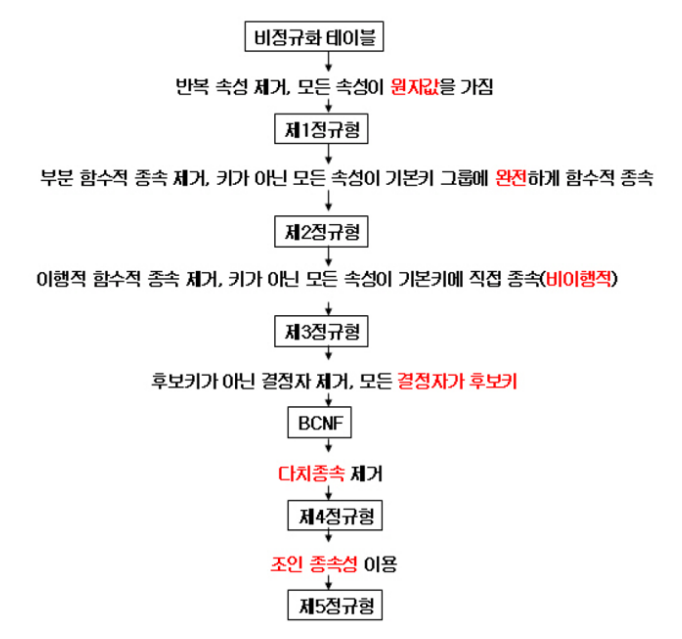
1정규형(1NF)

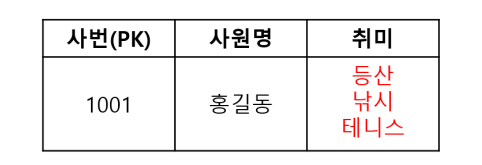
- 모든 속성은 반드시 하나의 값을 가져야 한다.(속성은 원자값을 지녀야 한다.)
- 다가 속성(Multivalued Attributes)과 복합 속성(Composite Attributes)에 대해 판단하여 처리한다.
- 다가 속성: 하나의 인스턴스에 하나의 속성이 여러 값을 가지게 되는 속성
- 복합 속성: 여러 속성이 하나의 속성으로 묶여있는 속성
- 다가 속성과 관련된 1 정규형 처리 방법
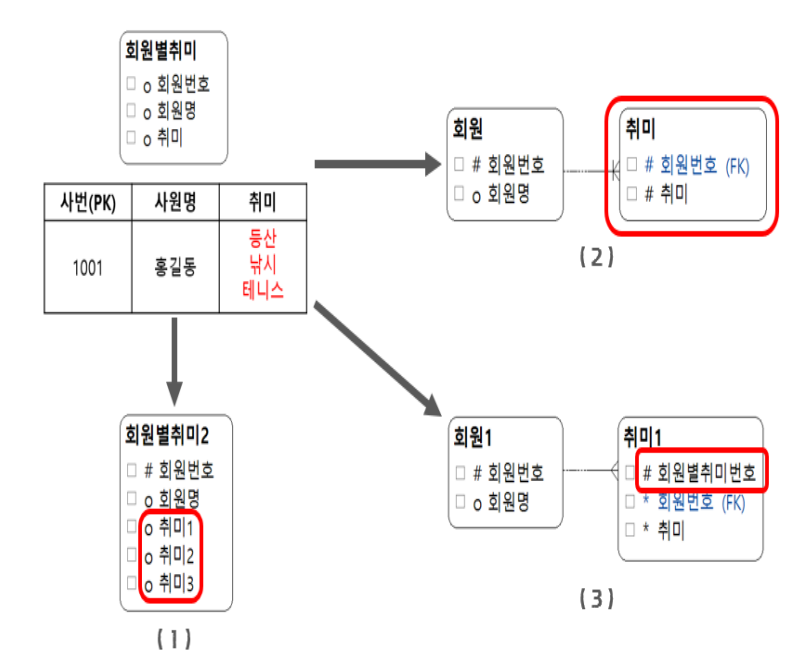
-
(1)의 경우와 같이 속성을 추가해서 인스턴스별로 하나의 속성에 하나의 값이 들어갈 수 있게 할 수 있다. 다만 이렇게 처리할 경우 속성의 갯수가 더 적을 경우가 많거나 추가한 속성의 수보다 많은 값은 처리할 수 없다. 속성이 한정적이고 제한적으로 존재할 때 처리할 수 있는 방법이다.
-
(2)의 경우와 같이 엔터티를 따로 추출해서 1 대 다 관계로 처리할 수 있다. 새로 생성된 엔터티의 인스턴스들을 구분하기 위해 속성들을 모두 식별자(복합키)로 활용하는 경우이다. (인스턴스의 구분 기준을 고려하여 식별자를 선정)
-
(3)의 경우는 (2)에서 추가적인 속성으로 인조식별자를 추가하여 인스턴스를 구분하고 나머지 속성은 비식별자로 처리하는 경우이다.
-
복합 속성과 관련된 1 정규형 처리 방법
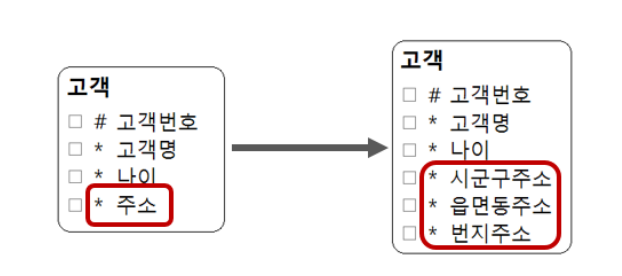
- 주소라는 속성은 여러 속성이 하나로 묶인 복합속성의 의미가 될 수 있다.
- 업무상 주소를 구분해서 사용하고자 하는 경우가 많을 때 속성을 구별하며 되려 하나의 주소로 다룰 때가 많을 때는 속성을 구분해서 사용하는 것이 좋지 않다.
2정규형(2NF)
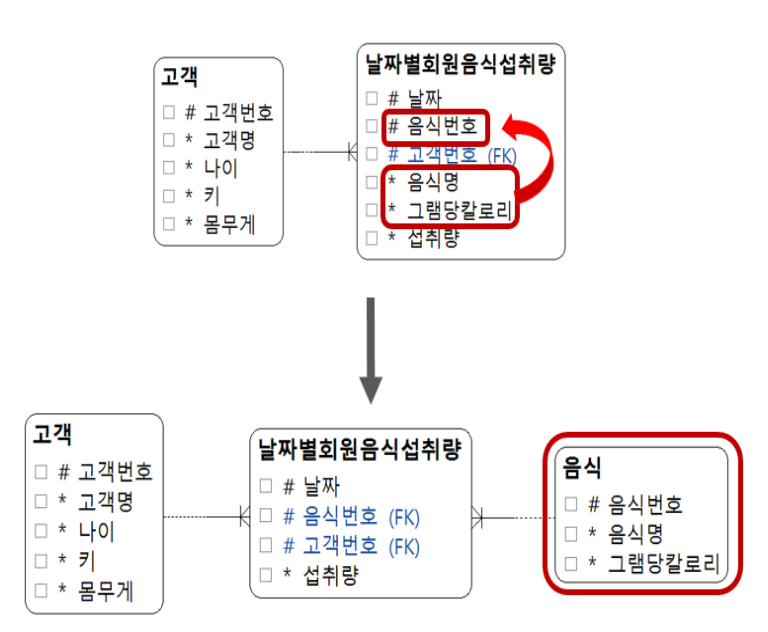
- 후보 식별자 속성과 일반 속성 간의 종속성을 판단하여 처리한다.
3정규형(3NF)

- 이행적 종속성(Transitive Dependency)을 제거하고 일반속성 간에 종속관계가 없도록 처리한다.
- 일반 속성에 결정자 속성과 종속자 속성이 있는 경우 다른 엔터티로 구별하여 분리한다.
보이스코드 정규형(BCNF)

- 모든 결정자는 주식별자가 되도록 한다.
- 결정자 속성이 일반 속성이며 종속자 속성이 주식별자에 포함되어 있다.
4 정규형(4NF)
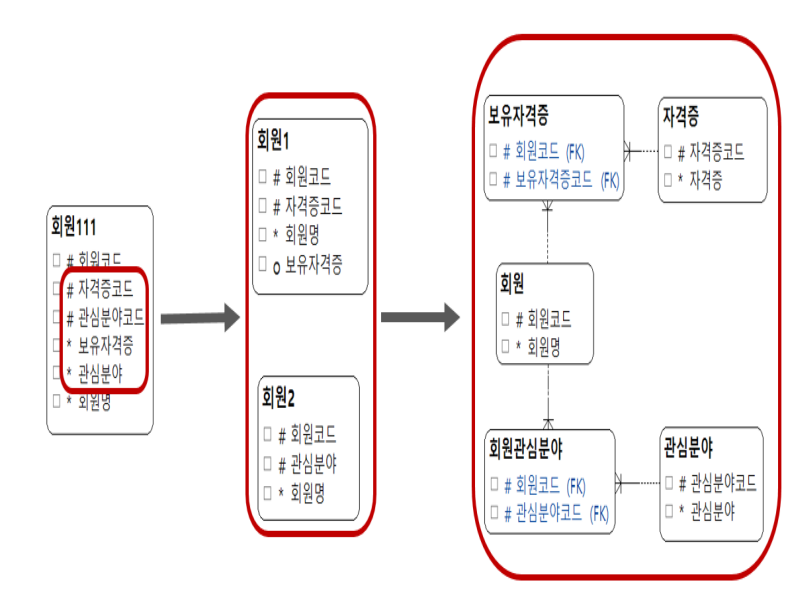
- 다가 종속인 속성들간에 서로 직접적인 연관이 없으면 다가 종속인 속성들은 새로운 엔터티로 분해하여 다가종속 관계를 제거한다.
- 보유자격증과 관심분야는 각각 다가 속성이면서 서로 관련이 없으므로 엔터티를 분리한다.
5 정규형(5NF)
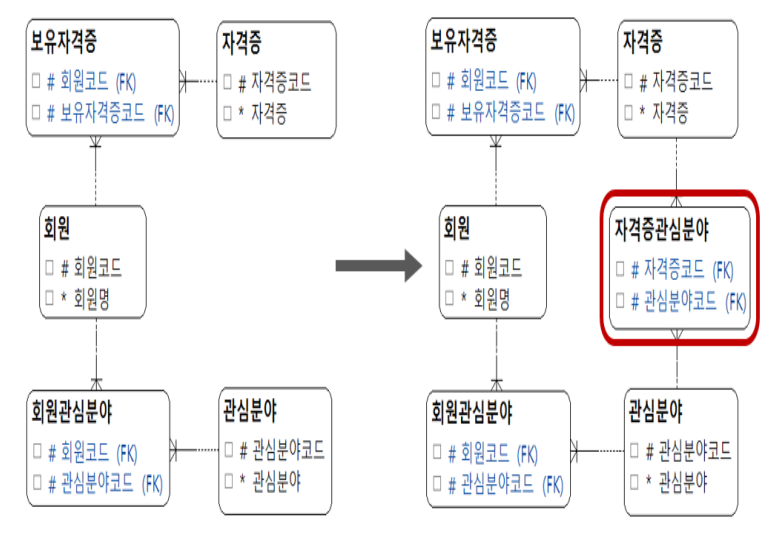
- 조인해서 원래의 릴레이션으로 복원할 수 있도록 분해하여 조인 종속성을 제거한다.
- 무손실 조인(Lossiess Join): 하나의 릴레이션을 여러 개의 릴레이션으로 분해하고 공통 속성으로 조인하여 데이터 손실 없이 다시 원래의 릴레이션으로 복원할 수 있음
- 비부가적 조인: 하나의 릴레이션을 여러 개의 릴레이션으로 분해하고 원본 릴레이션에 없는 데이터가 존재하지 않음
- 5정규형은 무손실 분해가 되고 필요 없는 데이터가 생기지 않는 비부가적 분해가 된 것이다.
물리모델

- 실제로 데이터베이스에 이식할 수 있도록 모델의 구조보다는 인덱스, 뷰, 테이블 타입과 사용하는 DBMS와 같은 물리적 요소에 집중하여 데이터베이스를 설계하는 단계이다.
- 성능을 고려해 비정규화(Denormalyzation)를 진행하는 단계이다.
-
논리적 DB 설계
(데이터 모델링)물리적 DB 설계 DBMS의 종류나 제품에
상관없이 진행
(ERD는 어떤 데이터베이스를
사용해도 적용 가능)특정 DBMS를 전제로 진행
(적용 DBMS의 특성을 고려)
물리 모델의 목적
- 성능을 최적화 하기 위해 성능을 거려하여 엔터티를 합치거나 모델 구조를 약간 변경(비정규화)할수 있다.
물리 모델의 주의사항
- 모델의 구조는 많아도 10% 이내의 변화 정도만 이루어 져야 한다.
- 화면이나 SQL이 작성되면서 필요한 인덱스와 뷰를 도출한다.
- 비정규화는 특정 성능 문제를 해결하기 위한 목적이 아니라면 고려하지 않는다.
- 슈퍼타입과 서브관계의 물리적 변환
슈퍼타입과 서브타입

- 위의 세가지 소모임 관련 엔터티는 유사항 속성들을 지니고 있다. 공통적으로 지닌 유사항 속성들을 기준으로 하나의 엔터티로 일반화를 진행할 수 있다.

- 노란색 부분을 제외한 속성들은 공통적인 소모임 엔터티들의 공통적인 속성들을 의미하며 슈퍼타입으로 볼 수 있으며 소모임 구분이라는 속성을 통해 서브타입에 해당하는 속성들이 존재하게 된다.
- 서브타입에 해당하는 속성들은 소모임 구분에 따라 해당되는 속성이 있고 해당되지 않는 속성이 있으며 예시의 경우 각 서브타입 속성은 소모임 구분에 따라 배타적인 관계로 관리된다.
- 소모임에서 소모임 구분에 따라 슈퍼타입과 서브타입으로 속성을 구분하여 통합 엔터티로 표시한 것이지만 이전에 세개의 엔터티로 표기한 것처럼 서브타입의 갯수만큼 엔터티가 따로 존재했던 것으로 생각할 수 있다.
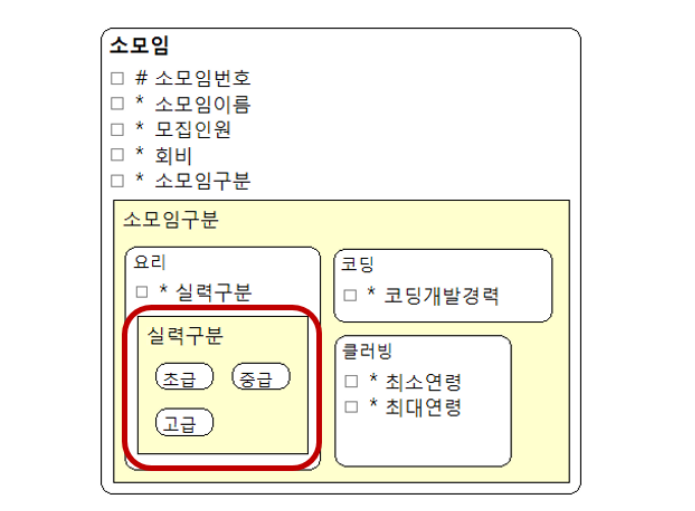
- 서브타입중에 요리에 해당하는 소모임일 실력 구분 속성에 해당하는 속성값이 셋중의 하나인 배타적관계 임을 나타낼 수 있다. 이는 실력 구분별 요리 소모임 엔터티가 초급, 중급, 고급일 때마다 각각 엔터티로 구분되어 존재할 수 있음을 의미한다.

- 요리 소모임의 경우 소모임별 배울 요리 엔터티와 관계를 가지게 되며 소모임별 배울 요리는 소모임의 서브타입 엔터티에 해당한다.
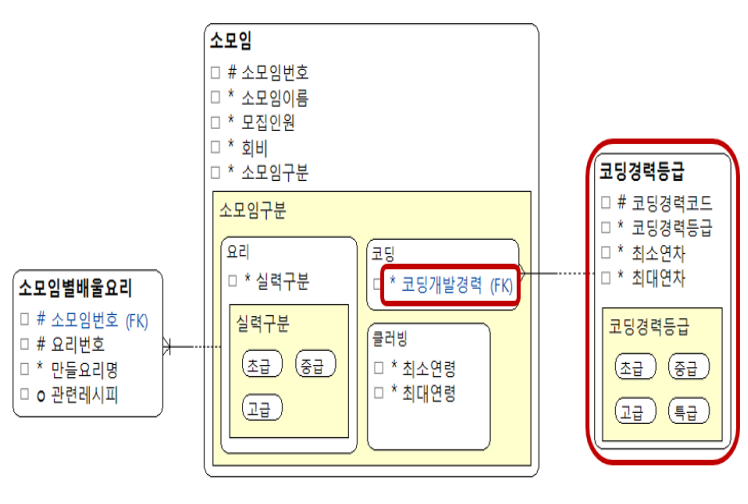
- 코딩 소모임의 경우도 코딩경력등급 엔터티와 관계를 맺어줄 수 있으며 소모임의 코딩개발경력 속성은 코딩경력등급 엔터티의 주식별자의 외래키가 되게 속성을 정의할 수도 있다.
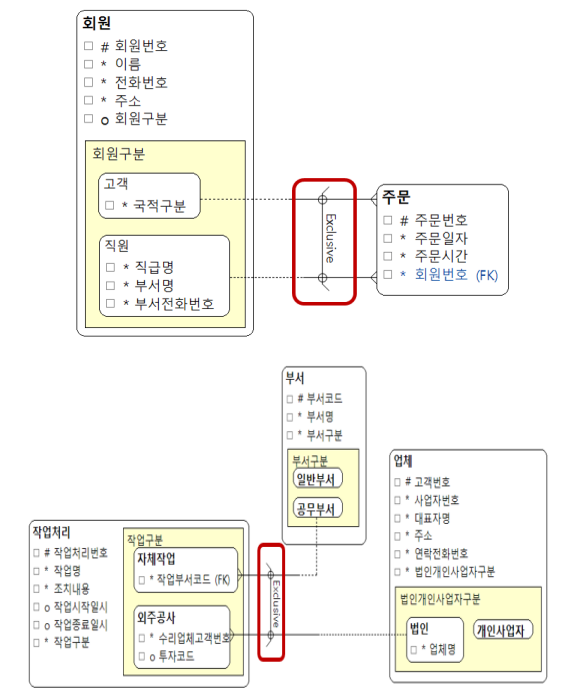
- 서브타입은 서로 배타적(둘 중 하나만 해당)이고 서브타입 속성 값에 따라 서브타입엔터티들도 배타적으로 연결될 때 위와같이 배타적 관계 표시를 할 수 있다.
서브타입의 물리모델 변환
통합 엔터티로 변환
| 장점 | 단점 |
|---|---|
| 서브타입 구분 없는 데이터 접근이 간편하다 (조회 시 조인이 필요없다.) (Entity Integrity) | 테이블의 컬럼 수가 증가된다. |
| View를 활용해 각 서브타입 조회 및 수정이 가능하다. | 서브타입 별로 처리 시 서브타입의 구분이 필요해 지는 경우가 많다. |
| 특정한 서브타입을 NOT NULL로 제한할 수 없다. |
각 서브타입마다 하나의 엔터티로 변환
| 장점 | 단점 |
|---|---|
| 서브타입 별로 처리 시 서브타입의 유형 구분이 불필요하다. (Entity Integrity) | 전체적인 데이터를 처리하는 경우 UNION이 발생한다. |
| 단위 테이블의 크기가 감소한다 | 여러 테이블을 합친 View는 조회만 가능하며 인스턴스를 개별적으로 구분하기 위한 UID 유지 관리가 어렵다. |
| 불필요한 컬럼이 줄어든다. | 복잡한 SQL 처리 시 통합이 어렵다. |
서브타입 속성의 NULLABLE
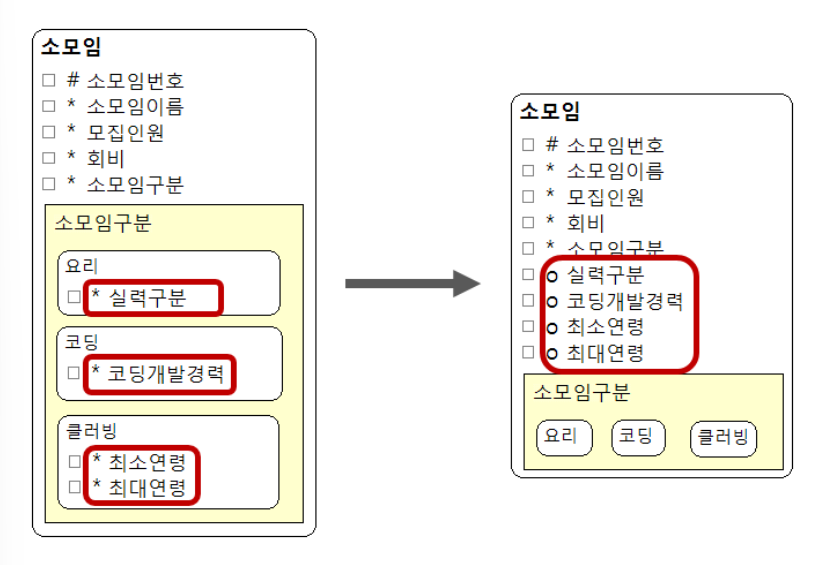
- 물리모델로 변환할 때는 배타적 관계에 해당하는 서브타입의 속성들은 NULL값이 들어올 수 있음을 고려해야 한다.
성능 개선
뷰와 인덱스 설계
뷰란
- 하나의 테이블, 혹은 여러 테이블에 대하여 특정 사용자나 조직의 관점에서 데이터를 바라볼 수 있도록 해주는 수단으로서 가상 테이블이라고도 부른다.
- 복잡한 쿼리가 요구 되는 것들을
- 접근 권한 제어를 위해 생성할 수 있다.
인덱스란
- 인덱스는 검색의 기준이 되는 컬럼만을 뽑아 정렬한 상태를 유지하고 있으며 인덱스의 각 튜플은
- 원래 데이터가 저장되어 있는 테이블에 대응하는 튜플의 주소 값을 가지고 있다.
- SQL의 WHERE절에서 비교 대상이 되는 컬럼 또는 JOIN에 사용되는 컬럼이어야 한다.
- 튜플의 수가 적으면 인덱스를 지정하여도 별 효과가 없다.
- 인덱스로 지정한 컬럼에 의해 검색했을 때 검색 결과가 전체 튜플의 10~15% 미만일 때 인덱스의 효과가 있다.
- 기본키로 지정한 컬럼에 대해서는 자동적으로 인덱스를 만들어 준다.
비정규화(Denormalization)
- 정규화 작업이 완료된 후 데이터 물리 모델링 과정 중 시스템의 성능 향상, 개발 과정의 편의성, 운영의 단순화를 추구
- 중복은 감수하고 데이터베이스의 성능을 향상시키는 것. (특히 검색 속도)
- 정규화를 통한 데이터 무결성 유지도 중요하지만, 다수 사용자가 동시 이용하는 환경에서 일정 성능을 유지하는 것도 매우 중요.
비정규화의 종류
수직 분할
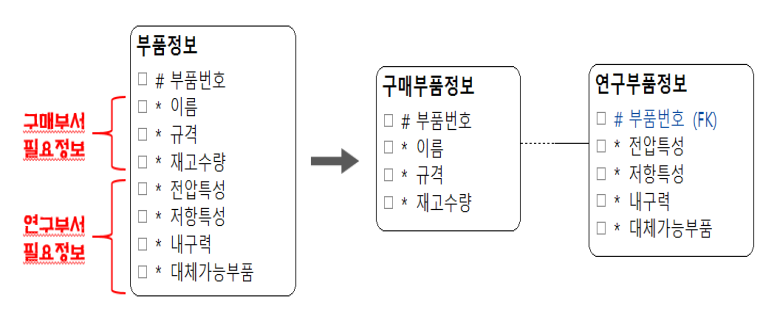
- 엔터티의 튜플 수 및 속성의 수가 매우 많고, 엔터티의 속성들이 그룹화되어 각 그룹이 특정 부서 혹은 응용 프로그램에 의해서만 사용될 때
- 엔터티의 데이터량이 많을수록 검색속도는 느려지므로, 엔터티를 분할하여 데이터량을 줄임으로 써 성능 향상을 도모할 수 있다.
- 수직 분할은 반복되지는 않지만 속성들이 그룹화 되어 각 그룹이 특정 부서 혹은 응용프로그램에 의해서만 사용될 때에 사용할 수 있으며 수직 분할하면 본래 하나의 엔터티였기 때문에 카디널리티는 1:1이 된다.
수평 분할
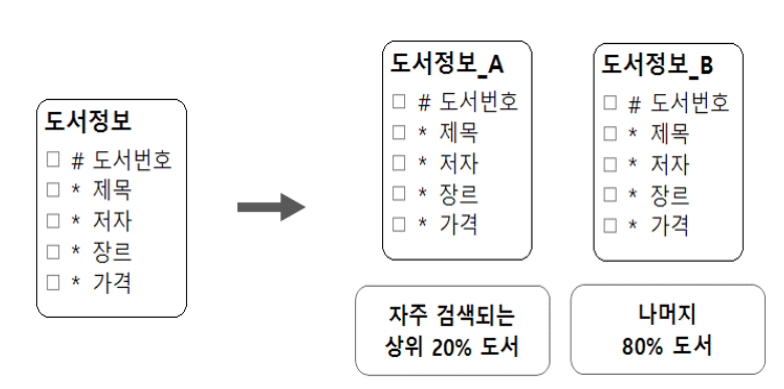
- 튜플의 검색빈도가 다르다는 점을 이용하여 엔터티를 분할하면 엔터티의 데이터 크기가 감소하여 성능 향상의 효과를 볼 수 있다.
- 수평 분할 결과로 나온 엔터티 중 도서정보_A는 자주 검색되는 상위 20%의 도서이고 도서정보_B는 나머지 80%의 도서이다. 즉, 20%의 책이 전체 검색 빈도의 80%를 차지한다고 생각할 수 있으며 수평분할 된 엔터티는 속성은 동일하지만 서로 아무런 관계도 성립하지 않는다.
속성 중복
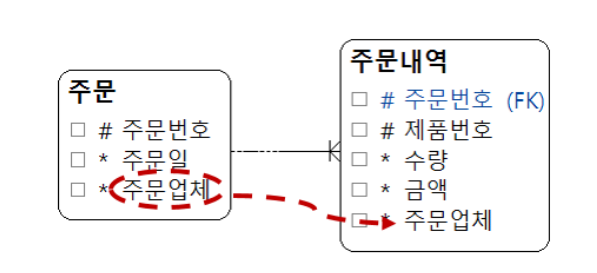
- 주문 내역에 주문업체 속성이 중복되게 추가한 것으로 조인을 하지 않고 주문내역으로부터 주문업체 정보를 얻을 수 있다.
- 과도하게 중복된 속성들을 사용하게 되면 데이터의 무결성(데이터의 불일치)이 깨질 수 있다.
- 입력, 수정, 삭제에 있어 응답시간이 늦어질 수 있다.
엔터티 통합
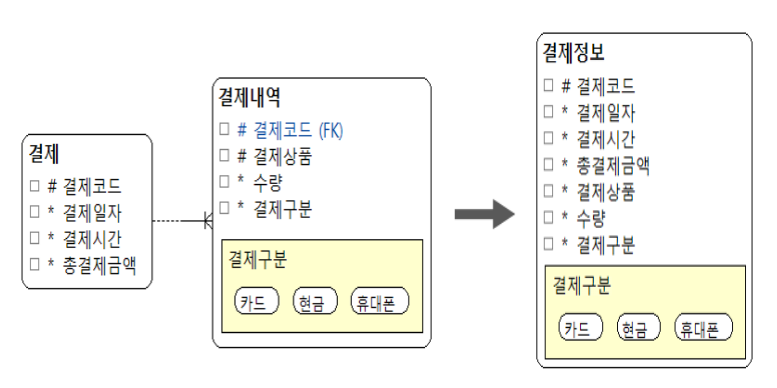
- 항상 혹은 대부분 조인에 의한 검색을 하고, 검색이 빈번히 이루어지는 두 개 이상의 엔터티를 대상으로 한다.
- 조인 연산에 걸리는 시간을 단축시켜 준다.
- 중복이 존재할 수 있어 이상(Anomaly) 현상이 발생할 수 있다는 것을 고려해야 한다.
테이블 타입
문자 데이터 타입
| 데이터 타입 | 설명 |
|---|---|
| CHAR(n) | 고정길이 문자 / 최대 2000byte / 디폴트 값은 1byte |
| VARCHAR2(n) | 가변길이 문자 / 최대 4000byte / 디폴트 값은 1byte |
| NCHAR(n) | 고정길이 유니코드 문자(다국어 입력가능) / 최대 2000byte / 디폴트 값은 1byte |
| NVARCHAR(n) | 가변길이 유니코드 문자(다국어 입력가능) / 최대 2000byte / 디폴트 값은 1byte |
| LONG | 최대 2GB 크기의 가변길이 문자형 |
| CLOB | 대용량 텍스트 데이터 타입(최대 4Gbyte) |
| NCLOB | 대용량 텍스트 유티코드 데이터 타입(최대 4Gbyte) |
숫자형 데이터 타입
| 데이터 타입 | 설명 |
|---|---|
| NUMBER(P,S) | 가변숫자 / P(1 ~ 38, 디폴트 값: 38) / S(-84 ~ 127, 디폴트 값: 0) / 최대 22byte |
| FLOAT(P) | NUMBER의 하위타입 / P(1 ~ 128, 디폴트 값: 128) / 이진수 기준 / 최대 22byte |
| BINARY_FLOAT | 32비트 부동소수점 수 / 최대 4byte |
| BINARY_DOUBLE | 64비트 부동소수점 수 / 최대 8byte |
날짜 데이터 타입
| 데이터 타입 | 설명 |
|---|---|
| DATE | BC 4712년 1월 1일부터 9999년 12월 31일, 연, 월, 일, 시, 분, 초까지 입력 가능 |
| TIMESTAMP | 연도, 월, 일, 시, 분, 초, 밀리초까지 입력 가능 |
LOB 데이터 타입
| 데이터 타입 | 설명 |
|---|---|
| CLOB | 문자형 대용량 객체 고정길이와 가변길이 문자집합 지원 |
| NCLOB | 유니코드를 지원하는 문자형 대용량 객체 |
| BLOB | 이진형 대용량 객체 |
| BFILE | 대용량 이진 파일에 대한 위치, 이름 저장 |

엔지니어로의 성장일지