
File
File이란 ?
흔히 아는 것 처럼 하드디스크에 저장하는 단위이다. 메모리는 주소를 통해서 접근하는 장치였다. 반면에 파일이라는 것은 이름을 통해서 접근하는 단위이다. 따라서 파일이라는 것을 정의하자면 아래와 같다.
A named collection of related information
- 일반적으로 비휘발성의 보조기억장치에 저장
- 하드디스크 같은 곳에 저장 - 운영체제는 다양한 저장 장치를 file이라는 동일한 논리 단위로 볼 수 있게 해준다.
- 데이터를 저장하는 목적으로만 사용하는 것이 아님
- Operation :
create(생성),read(읽기),write(쓰기),reposition(파일을 읽거나 쓰면 파일이 여러개의 바이트로 구성이 되어 크기 때문에 어느 위치를 읽느냐 쓰느냐를 가리키는 포인터가 있음, 파일을 읽으면 보통 시작 부분을 가리키는데, 한번 읽고 나면 포인터가 다음 부분을 가리키게 된다. 그런데 필요에 따라 파일의 시작부분, 현재의 위치 포인터가 아닌 부분에서 읽고 쓰고 싶을 수 있다. 따라서 이러한 포인터의 위치를 수정해주는 연산),delete(삭제),open(read, write를 하기 전엔 open을 해야함),close(read, write를 한 다음엔 close해야함) 등
왜 open과 close가 따로 있는 것일까?
open의 역할은 파일의 내용이 아니라 파일의 metadata를 올리는 것이다.
File attribute (or file metadata)
- 파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들
- 파일 이름, 유형, 저장된 위치, 파일 사이즈
- 접근 권한 (읽기/쓰기/실행), 시간(생성/변경/사용), 소유자 등
File system
- 운영체제에서 파일을 관리하는 부분
- 파일 및 파일의 메타데이터, 디렉토리 정보 등을 관리
- 파일의 저장 방법 결정
- 파일 보호 등
Directory
- 파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별한 파일
- 일반 file은 음악 file 이면 음악이 내용으로 들어있으나, 디렉토리 파일의 내용은 디렉토리 내의 존재하는 파일들의 metadata이다.
- operation
search for a file,create a file,delete a filelist a directory,rename a file,traverse the file system(파일 시스템 전체를 탐색)
Partition (= Logical Disk)
운영체제가 보는 것은 논리적인 디스크이다. 하드디스크를 하나사서 C드라이브, D드라이브로 나누면 각각이 partition이 되는 것이다.
- 하나의 (물리적) 디스크 안에 여러 파티션을 두는것이 일반적
- 여러 개의 물리적인 디스크를 하나의 파티션으로 구성하기도 함
- (물리적) 디스크를 파티션으로 구성한 뒤 각각의 파티션에 file system을 깔거나 swapping등 다른 용도로 사용할 수 있음
디스크의 용도는 크게 file system, swap area로 나눌 수 있는 것이다.
open은 파일의 메타데이터를 메모리로 올려놓는 것이다.
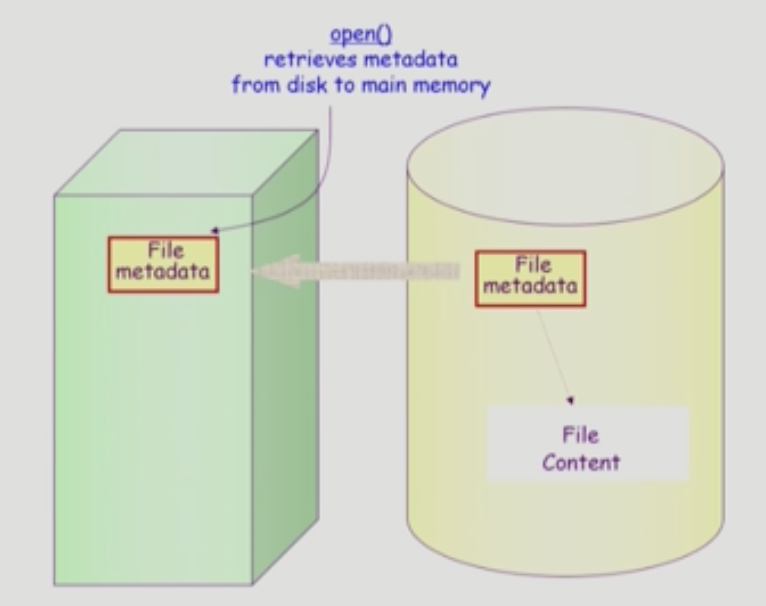
논리적인 디스크안에 파일시스템이 있으면 그 안에 file의 content와 metadata가 저장되어있다. 이 metadata 내에는 file의 content를 가리키는 포인터도 포함되어 있다.
open("a/b/c")
디렉토리 경로가 계층적일 경우 C라는 파일의 메타데이터가 어디있는지 디스크에서 찾아야한다.
보통 루트 디렉토리의 위치를 주어져있기 때문에 루트 디렉토리 부터 경로를 따라 내려가면서 C 파일을 찾게 되는 것이다.
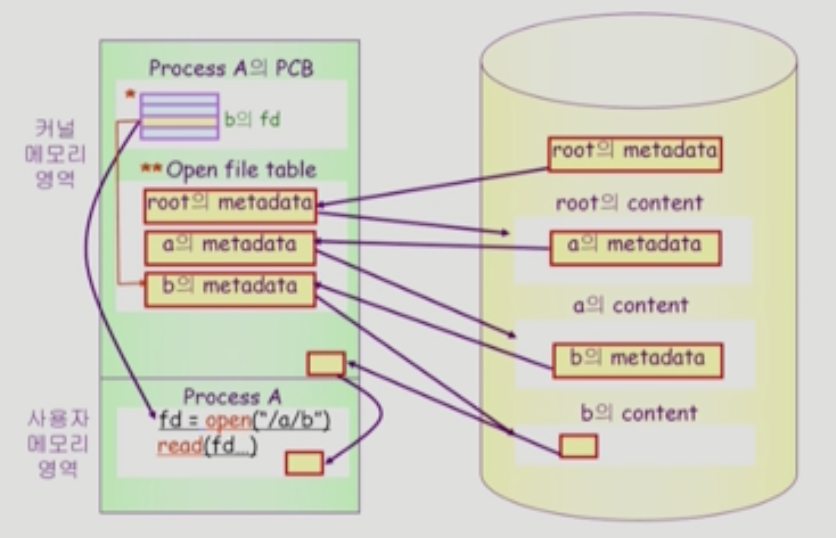
- ProcessA가 open("/a/b")를 통해 system call -> CPU 제어권이 운영체제로 넘어감
- 운영체제에는 ProcessA의 PCB와 open한 file들이 어떤건지 global한 table로 관리되고 있음
- root디렉토리의 메타데이터를 먼저 메모리에 올림 => root를 open
- meatadata 내에는 content를 가리키는 포인터가 있다고 했다. 따라서 root의 metadata를 통해 root의 실제 content를 살펴봄
- root는 디렉토리이기 때문에 content가 디렉토리 밑에 있는 파일들의 metadata이다. "/a/b"이므로 root 디렉토리 아래 a 디렉토리가 존재한다. 따라서 root 디렉토리 내에 있는 a 파일의 metadata를 메모리에 올림 => a open
- a의 metadata에 있는 pointer를 통해 content를 찾음 -> a 또한 디렉토리이기 때문에 디렉토리 내의 file들의 metadata를 가지고 있음
- a의 content내의 b의 metadata를 메모리에 올림 => b open
- b를 open하면 b의 metadata를 메모리에 올리고 ProcessA의 open이 끝난다.
- system call의 결과 값 리턴 -> 각 프로세스 마다 프로세스가 open한 파일들에 대한 포인터를 가지고 있는 배열이 존재함 b의 위치를 가리키는 포인터가 배열 어딘가에 만들어지고 배열의 몇번째 인덱스인가 ? -> file descriptor(fd)가 되어 이게 반환되는 것이다.
- b라는 file을 read하면 open을 이미 해놨기 때문에 root 부터 내려가며 찾을 필요 없이 fd만을 가지고 b의 metadata를 보면 됨
b에서 뭔가를 읽어 오고 싶다면, read(fd)와 같이 file descriptor를 통하면 된다.
read(fd)를 하게 되면 system call 이기 때문에 CPU가 운영체제로 넘어간다. A의 PCB에 가서 fd에 대응 하는 file의 메타데이터 부분(b의 metadata)을 Open file table에서 찾아 content(b의 metadata에 content를 가리키는 pointer가있음)를 찾아읽으면 된다. 이때 운영체제가 content를 바로 사용자에게 가져다 주는 것이 아니라 자신의 메모리 공간 일부에 읽어놓는다. 그 다음에 사용자 프로그램에게 이 내용을 copy해서 전달하면 read가 끝난다.
만약에 이 프로그램 또는 다른 프로그램이 동일한 파일의 동일한 위치를 요청하면 (read) 운영체제가 한번읽어놓은것이 있기 때문에 바로 전달 해줄 수 있다. -> buffer caching
file에 대한 read/write를 할 땐 buffer cache에 데이터가 있던 말던 운영체제로 CPU가 넘어간다. 이미 메모리에 있는 것에 대해 요청 -> 이것 또한 system call 이기 때문에 운영체제로 CPU가 넘어가고 buffer cache에 있는걸 준다.
buffer cache에 내용이 있든 말든간에 system call을 통해 CPU로 운영체제가 넘어간다. 따라서 LRU, LFU등을 자연스럽게 사용할 수 있는 것이다. paging 시스템에선 LRU 를 사용하지 못하고 clock을 사용했던 것과는 대조된다.
file descriptor 테이블은 프로세스마다 가지고 있다고 해서 per-process file descriptor table이라고 한다.
Open file table은 파일을 open했으면 프로세스마다 가지고 있는것이 아니라 system wide하게 관리하므로 system-wid open file table이라고 한다. 글로벌하게 하나 있는 것이다.
운영체제 구현에 따라 이러한 테이블이 두종류가 아닌 세종류일 수도 있다. 메타데이터가 디스크에 있을 때는 위에서 설명한 것만이 메타데이터(파일 이름, 유형, 저장된 위치, 파일 사이즈, 접근 권한 (읽기/쓰기/실행), 시간(생성/변경/사용), 소유자 등)가 되는데, 메타데이터를 메모리로 올려놓게 되면 추가적인 메타데이터가 필요하다. 바로 현재 프로세스가 해당 파일의 어느 위치를 접근하고 있다 라는 offset이다. 하지만 이것은 프로그램마다 별도이다. A라는 프로그램이 B를 open 했지만, 다른 프로그램도 B를 open한다면 같은 곳에 올라와있어도 읽고 있는 위치가 다를 수 있으므로 offset은 프로세스마다 별도로 가지고 있어야한다.
따라서 offset을 따로 관리하는 테이블을 추가로 따로 두는 것이 일반적이다.
File Protection
메모리에 대한 protection은 read, write 권한이 있느냐에 대해만 알아봤었다. 왜냐면 메모리라는 것은 프로세스마다 별도로 가지고 있으므로 자신만 볼 수 있기 때문이다. 따라서 연산이 무엇인가, 권한이 무엇인가만 봐주면 됐다.
하지만 파일은 여러 프로그램이 같이 사용할 수 있기 때문에 파일에 대한 접근 권한이 누구한테 있는가? 접근 연산이 어떤게 가능한가? 를 가지고 있어야한다.
Access Control 방법
Access control Matrix
각각의 사용자들이 각각의 파일들에 대해 어떤 권한이 있는지 행렬로 표현하는 것이다.

- Access control list: 파일별로 누구에게 어떤 접근 권한이 있는지 표시
- Capability : 사용자별로 자신이 접근 권한을 가진 파일 및 해당 권한 표시
그래서 표를 확인하고 맞는 권한을 주면 된다. 하지만 이러한 방법은 행렬 자체가 희소 행렬이 된다. 파일들은 엄청 많지만 특정 사용자가 본인만 사용하기 위해 만든 파일일 경우 다른 사용자들은 전혀 권한이 없을 것이다. 근데 이러한 행렬에 칸을 모두 만들면 굉장히 낭비가 된다.
따라서 행렬을 만드는 것 대신 linked list 형태로 만드는 방법을 생각할 수 있다. 주체를 누구로 하는가에따라 두가지 방법이 있다.
- 파일을 주체로 파일에 권한이 있는 사용자들을 묶어 놓는 것이다.
사용 권한이 없는 많은 사용자에 대해선 연결할 필요가 없는 것이다. 따라서 행렬에 의한 공간낭비를 막는다.
사용자를 주체로 linked list로 만들수 있다. 이를 Capability list라고 하는데, 각각의 사용자를 중심으로 각각의 사용자가 권한을 가지고 있는 파일들을 연결한 것이다.
따라서 모든 사용자에 대해 모든 권한을 나타내는 것이 가능한데 이 방법은 부가적인 오버헤드가 크다.
Grouping
일반적인 운영체제에서는 grouping 방법을 사용한다.
각각의 파일에 대해 사용자 그룹을 세가지로 나눈다. 소유주에 대해 권한이 read, write, excution 등 무엇이 있는지 표시하고, 사용자와 동일 그룹에 있는 사용자들에 대한 권한을 표시하고, 나머지 사용자들에 대한 권한을 표시한다. 따라서 총 9개의 비트만 있으면 되는 것이다.
- 전체 user를 owner, group, public의 세 그룹으로 구분
- 각 파일에 대해 세 그룹의 접근 권한(rwx)를 3비트씩으로 표시
아래는 UNIX의 예시를 나타낸 것이다.
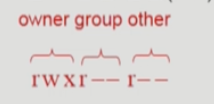
Password
password를 걸어주는 방법이다.
보통 password를 거는 것은 로그인을 생각하기 쉽다. 이 방법은 모든 파일이나 디렉토리에 password를 걸어 관리하는 방법이다. 하지만 접근 권한 별로 password를 두어야하기 때문에 password가 너무 많아져 관리가 어렵고 암기에 문제가 있다.
File System의 Mounting
하나의 물리적인 디스크를 파티션을 통해 여러개의 논리적인 디스크로 만들 수 있고 논리 디스크엔 파일 시스템을 설치할 수 있음을 배웠다. 이러한 root file system
다른 디스크의 파일시스템에 접근해야할 때는 어떻게 해야하는가 ?
이것을 제공하기 위한 것으로 mounting이라는 연산이 있다. mounting은 root file system의 특정 디렉토리 이름에다가 또다른 파티션에 있는 파일 시스템을 mount를 해주면 mount된 디렉토리에 접근 하면 다른 root file system으로 접근할 수 있게 된다.
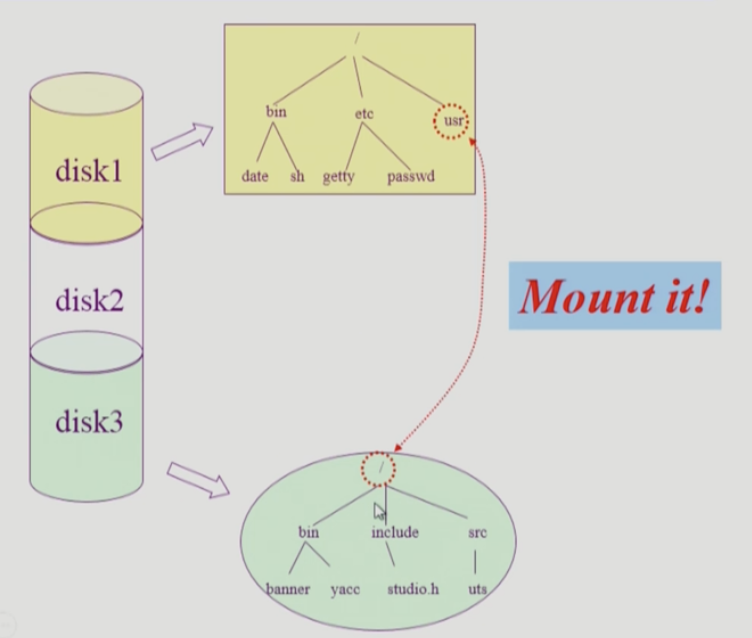
따라서 다른 파티션에 존재하는 파일 시스템에 접근할 수 있게 되는 것이다.
Access Methods
파일에 접근하는 방법
순차 접근 (sequential access)
- 카세트 테이프를 사용하는 방식처럼 접음
- 첫번째 곡을 듣고 다시 듣고 싶다면 되감아야함 - 읽거나 쓰면 offset은 자동적으로 증가
직접 접근 (direct access, random access)
- LP 레코드 판과 같이 접근하도록 함
- 파일을 구성하는 레코드를 임의의 순서로 접근할 수 있음
- 요즘은 직접 접근이 가능한 매체가 많다. 따라서 되감기를 하지 않는다. (CD, HDD 등)
- 특정 위치를 접근한 다음 바로 다른 위치로 접근하는 것이 가능
A->B->C 순으로 저장되어있는데 A다음 C를 보고 싶을 때 꼭 B를 거쳐야 하는것이 순차 접근이고, 바로 C로 접근할 수 있는 것이 직접 접근이다.
출처
Operating System Concepts 10th
KOCW 강의 - [운영체제] 이화여자대학교 반효경 교수
