이제 한 layer 더 아래에 있는 network layer에 대해 알아보자.
application layer는 HTTP 프로토콜을 이야기했었다. 데이터 유실등에 관해 생각하지 않고, request/response만을 생각했었다. 하지만 실제로 Transport layer를 보며 데이터의 유실이 일어날 수 있음을 알게 되었고 segment#, feedback등을 도입했었다. 하지만 우리는 segment가 어떻게 이동하는지, feedback은 어떻게 오는지 알 지 못했다. 어떻게 생각해보면 network layer 자체를 블랙박스 형태로 보고 있었던 것이다. 따라서 이제 Network layer에대해 알아보자.
Network Layer
배송에 대한 일은 IP 프로토콜이 관리한다.
패킷을 목적지까지 배송시켜주는 일에 참여하기 때문에 라우터에는 네트워크 layer까지 존재하는 스택이 있는 것이다. HTTP 메시지가 TCP segment에 담겨서 IP 패킷에 담겨 보내지면 목적지가 어딘지 분석되어 보내지고 .. 를 반복하는 것이다.
패킷을 처음 받았을 때 processing delay(패킷의 목적지를 보고, header를 분석해 에러가 있는지 확인)
Router
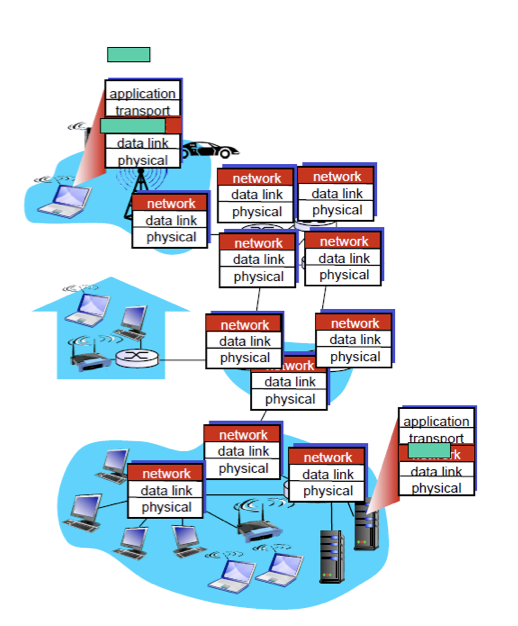
라우터에서 하는일은 두가지이다. forwarding과 routing이다.
Forwarding
라우터에서 하는일은 패킷이 들어오면 해당 패킷을 목적지 방향으로 전달하는 것이다.
패킷이 들어왔다면 목적지가 헤더에 들어있으므로 헤더를 확인하고 해당 방향으로 보내야한다. 따라서 목적지를 확인하고 목적지로 향하는 outgoing link를 확인해야한다. 라우터 안에 표가 하나 있는데, 이는 특정 목적이로 가기 위해서는 몇번 interface로 보내야한다는 정보가 적혀있다. 따라서 패킷을 받았는데 목적지 주소가 0111이었다면 라우터는 표를 보고 outgoing link가 2임을 확인한다. 이 작업을 forwarding이라고 한다.
따라서 표를 forwarding table이라고 한다.
forwarding이라는 작업은 들어온 패킷의 목적지 주소와 forwarding table의 entry를 매칭 시켜 해당 entry의 outgoing link로 보내는 것이다.
Routing
forwarding 작업은 단순하다. 그렇다면 forwarding table이 있어야하는데, 이는 누가 만드는 것일까? table은 너무 많아 사람이 만들 수 없고 자동적으로 만들어내야 한다. 이러한 일을 하는 것이 routing이다.
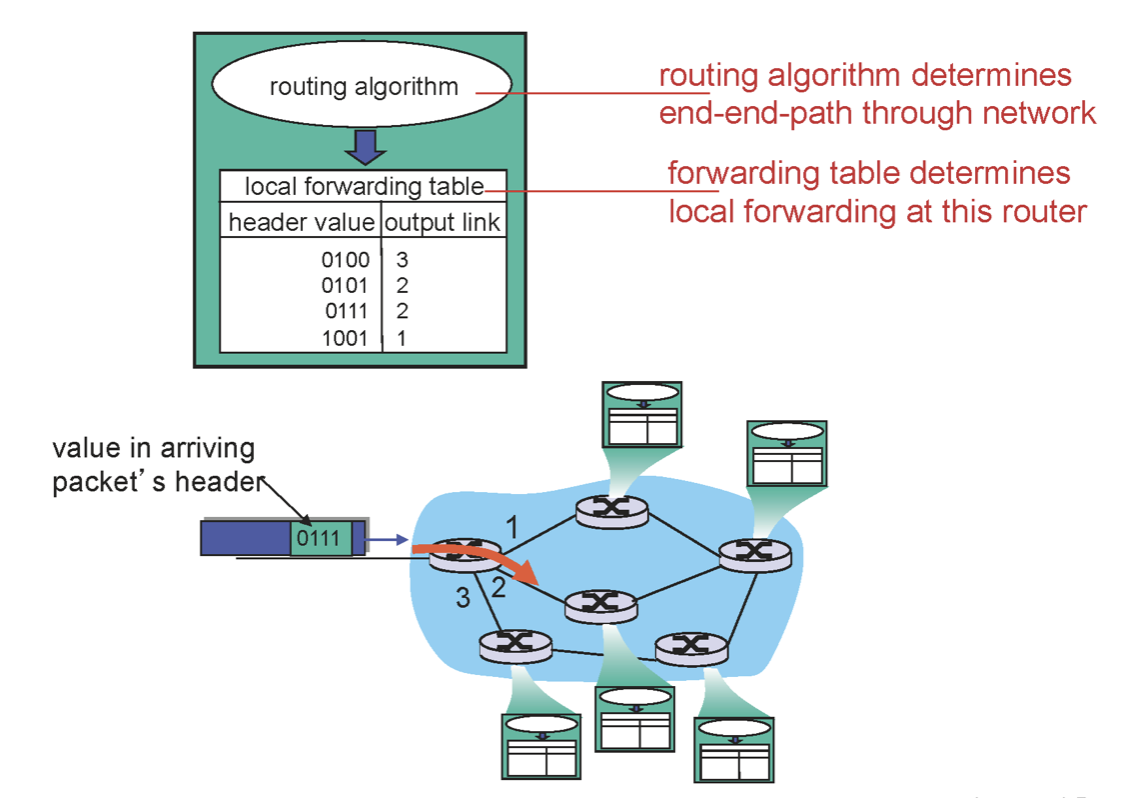
그렇다면 forwarding table의 형태가 정말 저렇게 되어있을까? 저렇다면 정말 쉽고 편리하겠지만 너무 많으면 table이 너무 커지고 검색이 안될 것이다. 따라서 이를 우체국 처럼 관리한다. 주소 범위를 통해 관리하는 것이다. 아래의 그림을 보자.
따라서 최종적으로 forwarding table의 예시를 보면 아래와 같을 것이다.
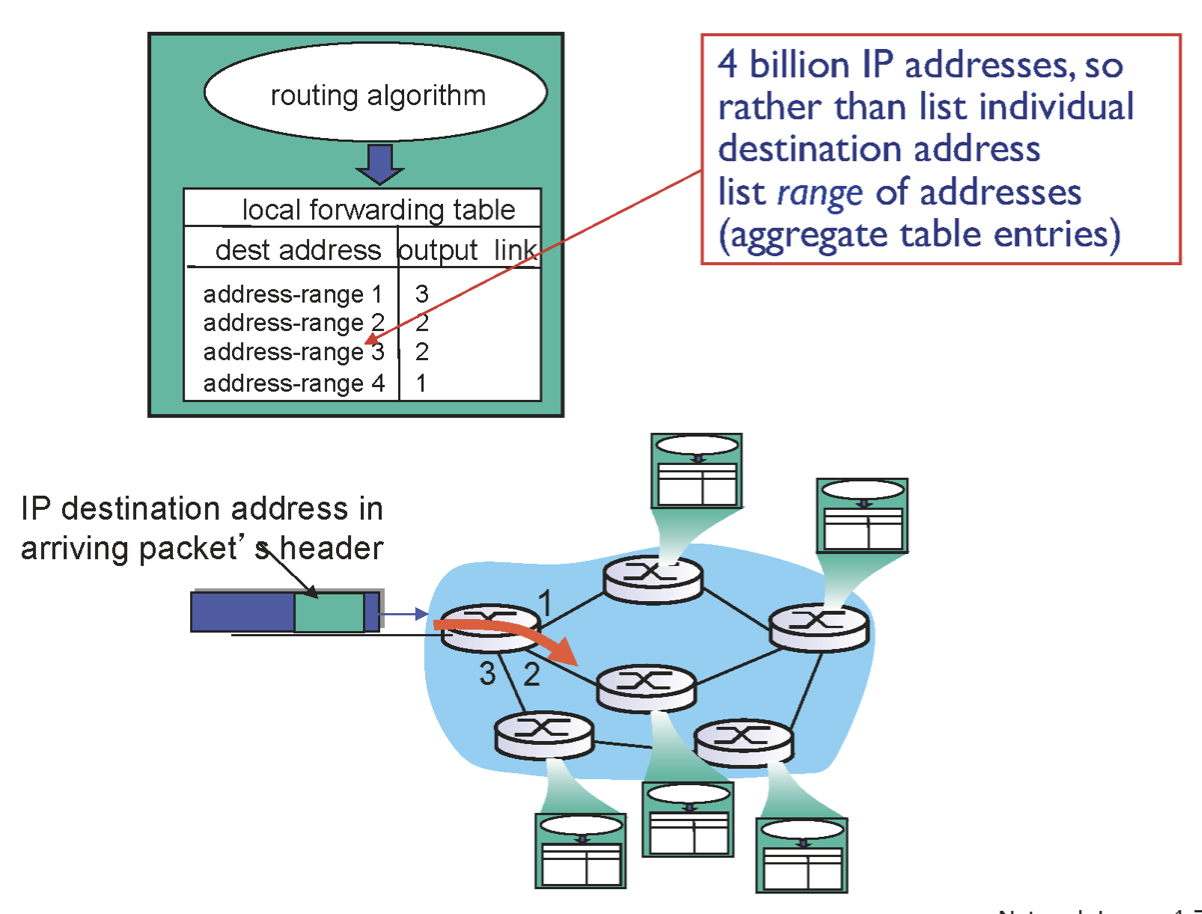
아래와 같이 나타낼 수 있다. *은 범위를 나타내는 것이다.

주소가 만약 11001000 00010111 00010110 10100001이라면 0번 패킷으로 보내면 된다.
주소가 만약 11001000 00010111 00011000 10101010는 1,2번 둘 다 맞아 떨어진다. 그렇다면 가장 구체적으로 많이 맞아 떨어지는 곳으로 간다. 따라서 1번으로 가는 것이다.
따라서 매칭이 여러개 될 때 prefix가 가장 많이 match 되는 곳으로 보내는 것이다. 따라서 이것을 Longest prefix matching이라 한다.
IP
Format
네트워크 layer의 전송단위는 패킷으로 다른 layer(application, transport)와 마찬가지로 header와 data 부분으로 나뉘어있다. data 부분에는 Transport layer의 전송단위인 segment가 들어있다.
우리가 segment 의 head에 있던 필드를 보았듯이 IP의 header에 대해 알아보자.
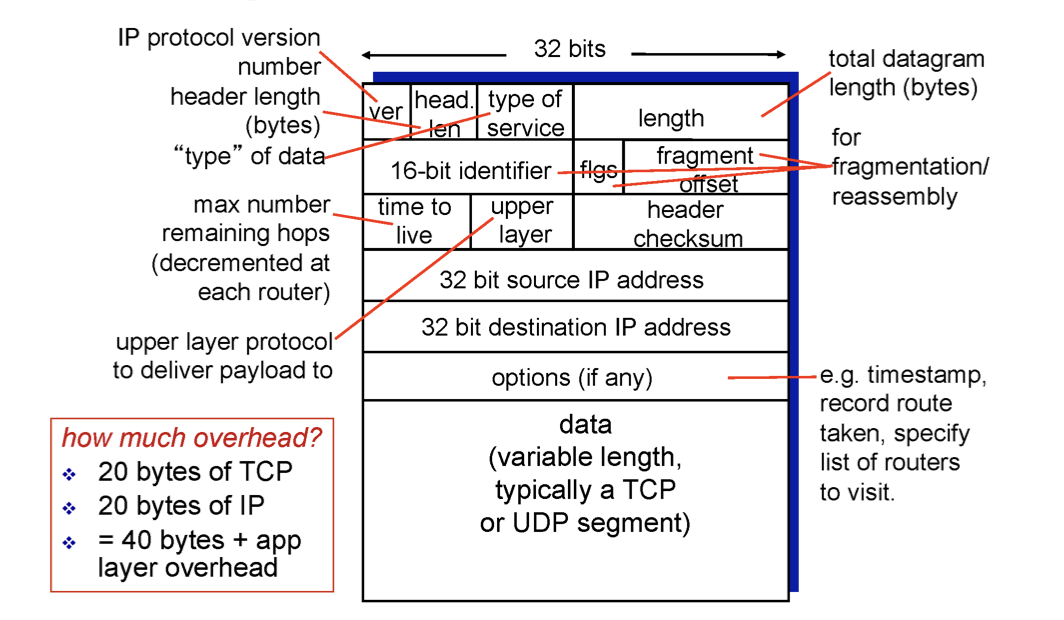
data 윗 부분이 바로 헤더이며 data는 segment가 들어가고 크기가 굉장히 크다.
필드를 살펴보자.
ver- version으로 현재 버전은 4이다.
32bit source IP address- 가장 중요한 필드이다.
- 메세지를 생성해서 보내는 사람의 IP 주소이다.
32bit destination IP address- 최종 목적지의 IP 주소이다.
time to live- sender가 20이라고 적어 보내면 router들을 거칠 때 마다 -1을 업데이트 해준다. 따라서 0이 되는 순단 버려지는 패킷이다.
- 네트워크 상에서 어떤일이 벌어질 지 모른다. 따라서 forwarding table이 잘못되었을 경우 loop를 돌 수도 있는 것이다. 따라서 네트워크 자원을 계속 소비하면서 끝없이 돌게 되므로 이를 방지하기 위함이다.
upper layer- data 부분에 들어가는 것이 TCP인지 UDP인지 알려주기 위함이다.
- receiver 측에서 사용한다. 받았을 때 TCP로 올릴지 UDP로 올릴지 모르기 때문이다.
이 헤더의 필드들을 종합하면 20 byte가 나온다. 또한 segment의 필드를 종합해도 20 byte가 나온다. 즉, 인터넷에 존재하는 패킷들은 대부분 TCP segment를 담고 있어 TCP 패킷이라하는데 이를 보면 IP header, TCP header로 총 헤더만 40 byte가 들어가 있어 40 byte의 오버헤드가 있다. 하지만 실제로 인터넷에 있는 패킷들을 조사해보면 상당수의 패킷이 달랑 40 byte 짜리 패킷이다. 왜일까? TCP ACK만 담은 패킷이기 때문이다.
Address (IPv4)
32비트 주소체계를 가지며 이론상으로 2의 32승개의 IP 주소를 가질 수 있다. 따라서 2의 32승이므로 인간이 읽기 어려우므로 8비트씩 끊어 10진수로 바꾼게 우리가 많이 보는 IP 주소이다. 따라서 한 단위가 8비트로 끊었으므로 255가 최대이다. 실제 라우터들은 10진수가 아닌 32 비트를 볼 것이다.
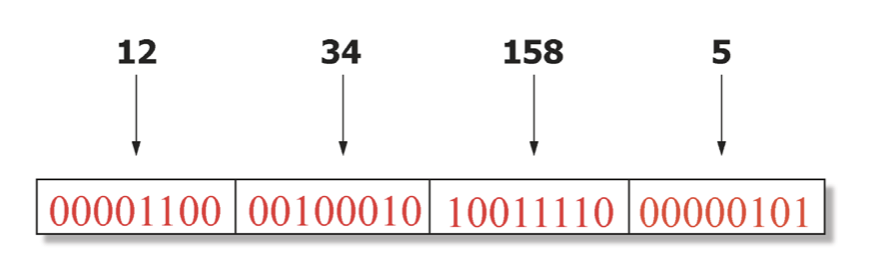
그렇다면 이는 무엇을 지칭하는 주소일까? 호스트라기 보단 호스트 내의 네트워크 interface를 지칭하는 주소이다. 따라서 컴퓨터에 네트워크 interface 카드를 여러개 꽂으면 여러개의 IP 주소를 가질 수 있다. 보통은 한개를 사용한다. 그렇다면 네트워크 interface를 여러개 가지면서 여러 IP 주소를 가지는 특수한 컴퓨터가 무엇일까? 라우터가 가장 대표적인 예이다.
우리는 인터넷을 하기 때문에 모두 IP 주소를 가지고 있을 것이다. 그렇다면 이 IP 주소는 어떻게 할당받은 것인지에 대해 고민해볼 필요가 있다.
위와 같이 네트워크가 형성되어있다고 할 때, 가장 단순하게 IP 주소를 할당하는 방법은 무작위로 할당하는 방식이다.
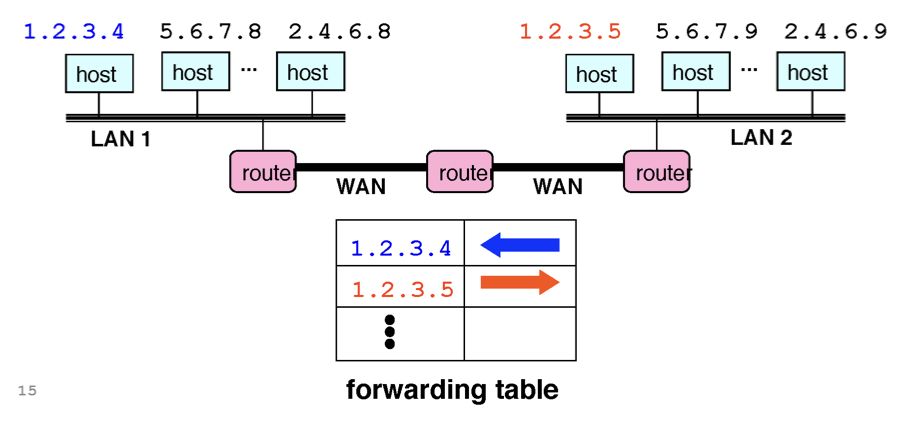
하지만 아무렇게나 배정하게 되면 문제점이 생긴다. forwarding table이 굉장히 커진다. host별로 방향이 모두 다르기 때문이다. 즉, forwarding table의 entry 가 많아져 커지므로 검색이 힘들어진다.
이러한 이유로 오늘날의 IP 주소는 무작위로 생성하지 않고 계층적으로 생성된다.
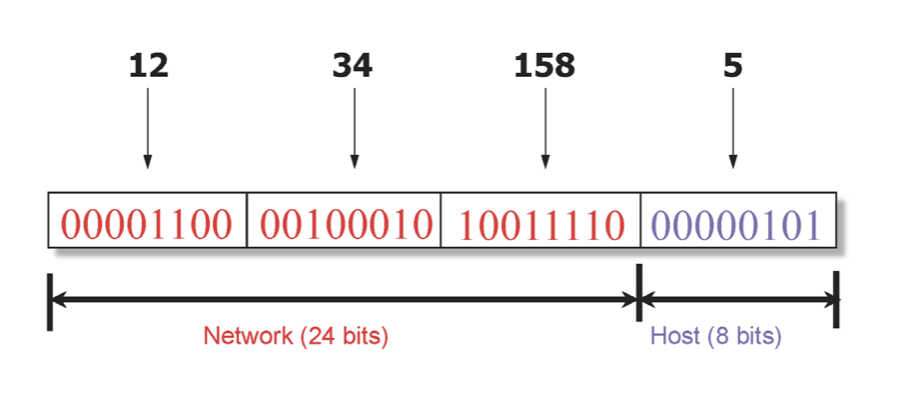
따라서 IP 주소는 개념적으로 두부분으로 나뉘게 된다. 앞부분은 network id, 뒷부분은 해당 네트워크내의 host를 지칭하는 id이다. 따라서 같은 네트워크 내에 있는 IP는 같은 prefix를 가질 것이다.
이를 보기 쉽도록 12.34.158.0/24와 같이 표기한다. 이는 사람이 알기 쉽도록 표기한것이고 기계들은 비트가 편하므로 아래와 같이 비트맵으로 나타낸다.
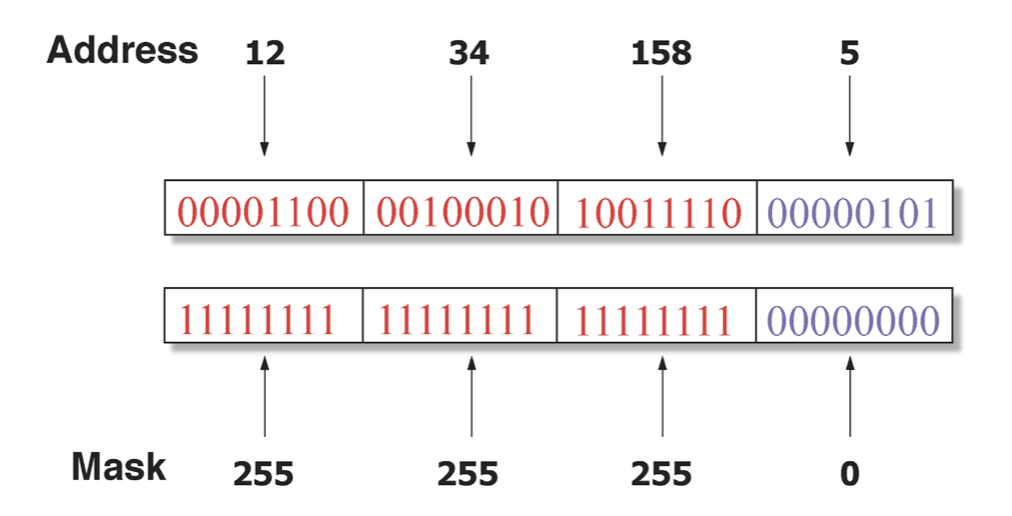
이게 흔히 알고 있는 subnet mask인데, subnet mask란 이 주소 중에서 어디까지가 subnet id(prefix)인지 나타낸 것이다.
따라서 prefix 방식으로 구성하면 같은 네트워크에 있으면 같은 prefix를 가진다.
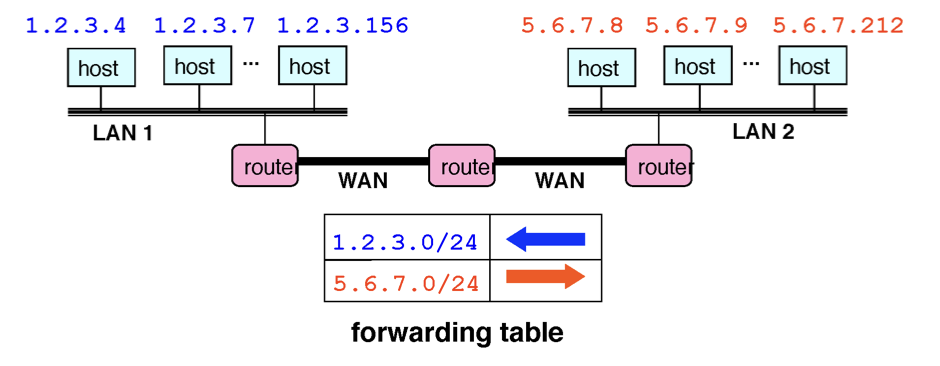
위와 같은 방식이 되는 것이다. 이렇게 되면 forwarding table이 간결해진다. 또한 새로운 호스트에 IP 주소를 주기 쉽다. 다른 네트워크를 생각하지 않고 같은 prefix에 호스트 번호만 다르면 된다.
Classful Addressing
인터넷이라는 것은 네트워크들의 집합이다. 결국 인터넷의 구성요소는 네트워크들이다. 그렇다면 네트워크들은 자기자신의 prefix를 가져야한다. 그런데, prefix의 크기는 모두 다르다. 예전에는 네트워크들에게 prefix를 배정할 때 Class라는 기준을 두고 배정했다.
Class가 A,B,C가 있다고 할 때 아래와 같다.
|Class|A|B|C|
|-----|-|-|-|
|blocks|/8|/16|/24|
|prefix bit 수|8|16|24|
|host bit 수|24|16|8|
Class A가 무조건 0으로 시작하는 0* 주소라면 2의 7승인 128개의 기관이 Class A의 주소를 가질 수 있었다. 즉, 아주 극소수만 가질 수 있었다.
Class B는 기관당 2의 16승 개의 host를 가질 수 있는 주소 공간이고 2의 16승 개의 기관이 배정될 수 있다.
Class C는 기관당 2의 8승 개의 host를 가질 수 있는 주소 공간이고 2의 24승 개의 기관이 배정될 수 있다.
이렇게 보면 A가 host를 많이 보유할 수 있어 좋아보이지만 보유할 수 있는 기관들이 너무 한정되어있어, 선구자들이 먼저 선점해버린 것이다. 그렇다면 선점한 기관들이 모두 2의 24승개의 host 주소를 사용했을까? 아니다. 이는 매우 큰 수로 한 기관내에서 사용할 수 없다. 따라서 낭비되는 주소가 생긴다.
C는 많은 기관에 줄 수 있으나 255개까지만 host를 처리할 수 있다. 학교만 생각해도 사람 수를 모두 커버하지 못한다.
만약 한 기관에서 필요한 host는 1000개 라고 한다면 적합한 Class가 없다. 이를 통해 Class라는 개념이 유연하지 못함을 알 수 있었다.
Classless Inter-Domain Routing
따라서 class를 사용하지 않고 마음대로 잘라서 사용하는 주소 할당 방법이 생긴 것이다.

따라서 /8, /16, /24가 아닌 /15등이 가능해진 것이다.
이를 host가 1000개 필요하다면 /22를 받아 2의 10승의 host를 사용하면 된다.
결국 아래와 같이 forwarding 되는 것이다.


Subnets
subnet이란 같은 subnet Id 즉, 같은 prefix를 가진 device의 집합이다.

subnet을 다른 말로 정의하면 라우터를 거치지 않고 접근이 가능한 host들의 집합이다.
라우터는 IP 주소를 가질까? 가진다. 오히려 host보다 더 많이 가진다. 위 그림에서 라우터의 인터페이스 즉, IP 주소는 3개이다. /24라고 할 때 이 세개의 prefix는 모두 다르다. 이 말은 라우터는 하나의 서브넷에 속한 것이 아닌, 여러개의 서브넷에 걸쳐있다는 것을 알 수 있다. 따라서 이 교집합을 통해서만 다른 곳으로 갈 수 있는 것이다.
그렇다면 아래의 상황에서 서브넷은 몇개일까?
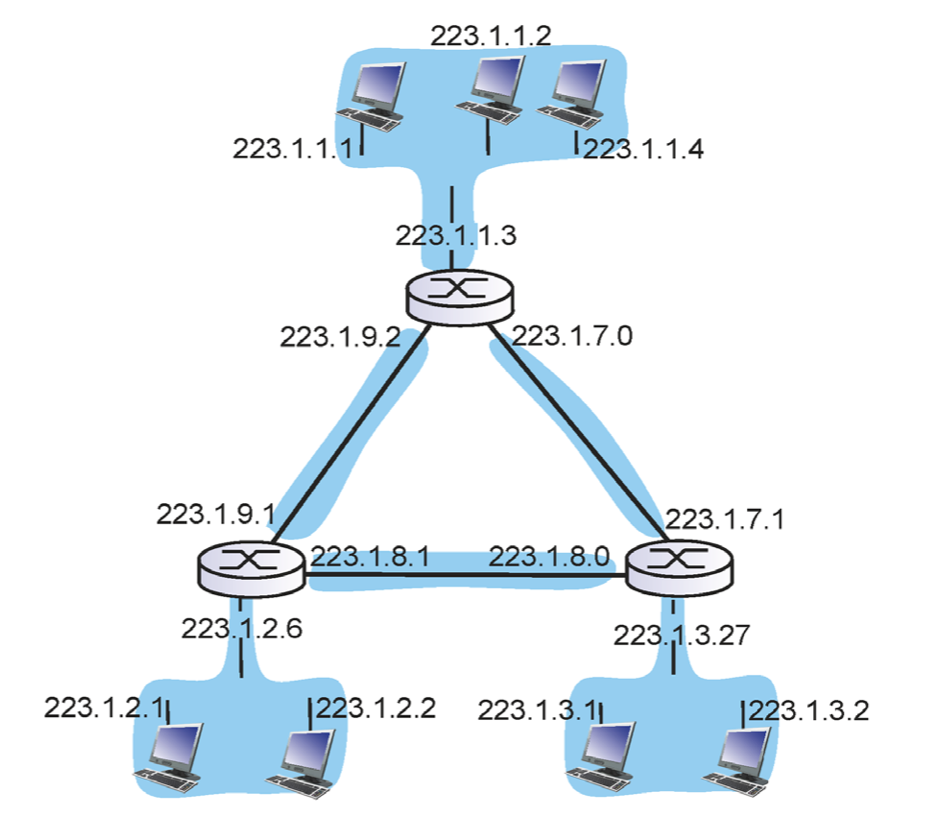
파란색으로 그려져 있는 6개이다. 각각의 라우터들은 3개의 서브넷에 걸쳐져 있다.
32 bit 공간이라는 의미는 이론상으로 인터넷에서 호스트를 최대 2의 32승개를 지원할 수 있다는 말이다. 2의 32승개는 약 40억 정도 된다. 그래서 70년대 초에 인터넷을 디자인을 한 사람은 이 host가 많다고 생각했으나, 인터넷이 발달하면서 90년대부터 걱정되기 시작했다. 95년에 이 걱정이 현실이 되어 앞으로 몇년내에 이것들이 다 고갈 되리라 예견되었다. 따라서 IPv6이 디자인되었다.
IPv6의 가장 중요한 변화는 주소공간이 128 bit로 늘어난 것이다. 이는 굉장히 큰 주소공간으로 전혀 주소공간의 부족을 걱정하지 않아도 되는 크기이다. 이것이 1996년 이야기이다. 하지만 현재 우리가 사용하고 있는 IP 프로토콜은 IPv4이다.
예견이 잘못되었거나, 주소공간이 고갈되었는데 어떠한 다른 방식으로 살아남았거나다. 우리는 개인당 소유하는 전자기기의 수가 늘어나면서 주소공간을 그만큼 사용하고 있다. 어떻게 아직 IPv4를 사용하고 있을까? 공유하고 있다는 것이다. 40억개의 주소공간을 각자 가지고 있는 것이 아닌 공유하고 있기 때문에 아직도 사용하고 있을 수 있다.
Network Address Translation
인터넷상에서 데이터를 주고 받기 위해선 고유한 IP 주소를 가지고 있어야한다. 그래서 NAT를 사용하는 방식을 살펴보자.
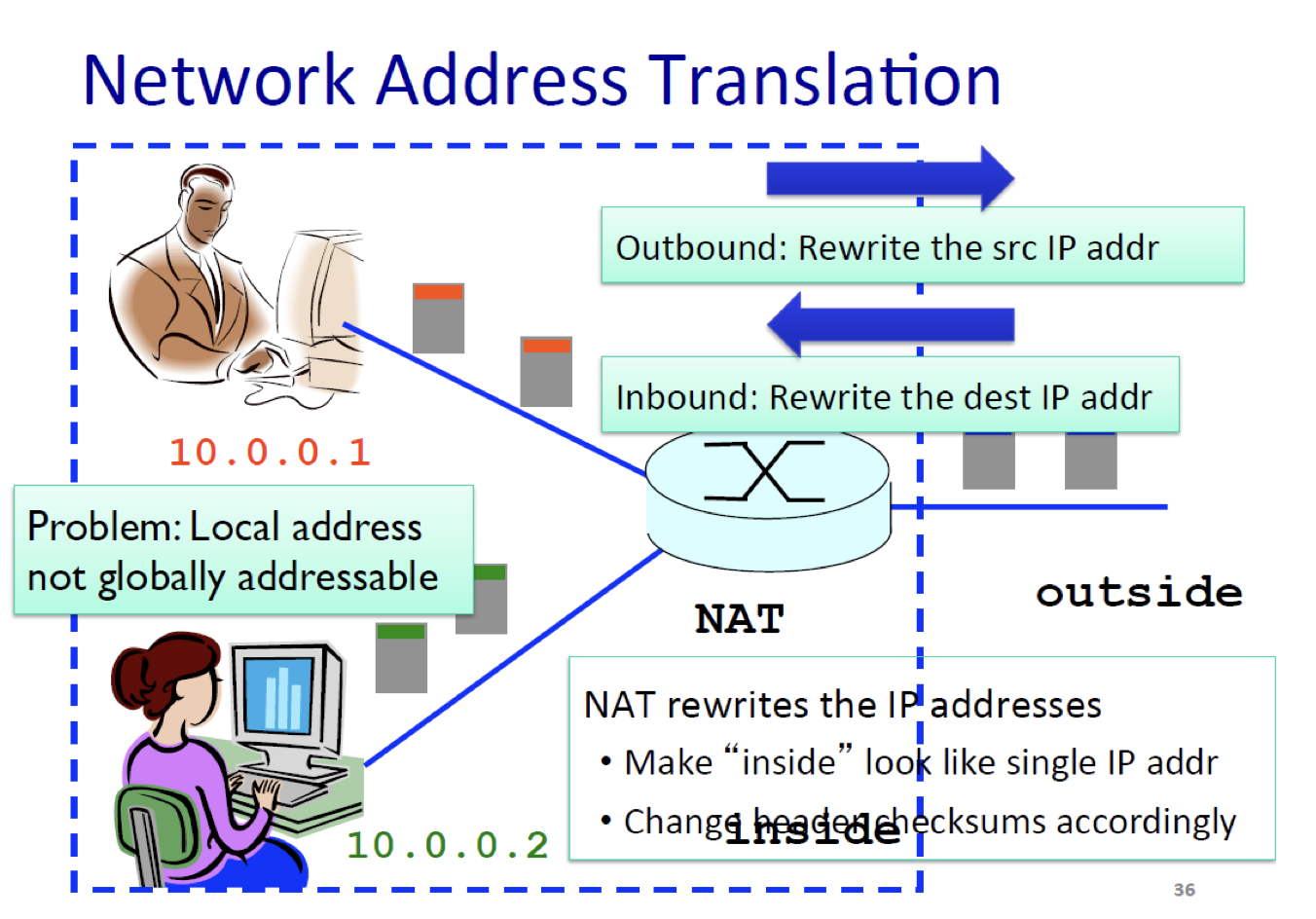
내부에선 유일한데, 외부와는 무관한 것이다. 따라서 내부의 source IP가 외부로 나갈 땐 NAT 를 통해 바꿔주는 것이다. NAT로 통해 바뀐 IP 주소는 전세계 유일하다.
아래의 그림을 살펴보자.
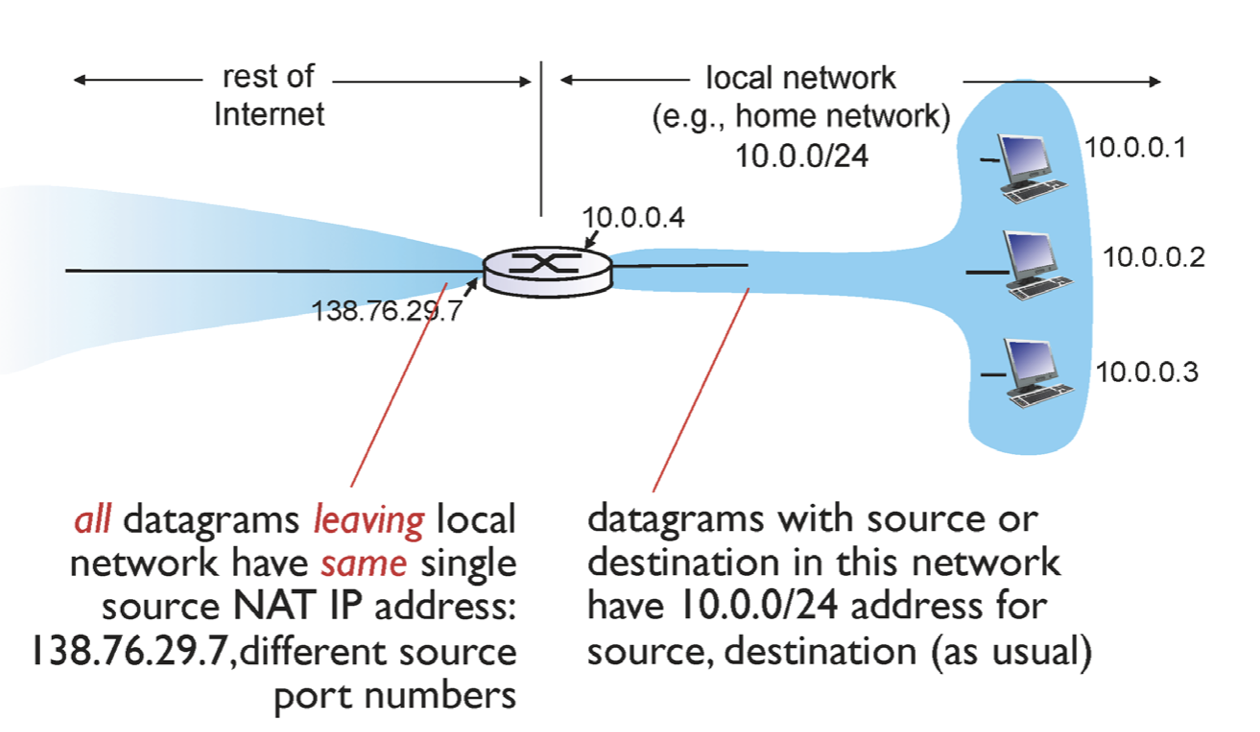
오른쪽의 세가지 주소는 내부에서만 유일하다. 즉, 남들도 내부에서 사용하고 있는 재사용 주소이다. 따라서 이 주소가 나갈땐 라우터를 통해 IP 주소와 Port number를 바꿔준다. 디바이스끼리 다른 PORT를 사용할 수 있으니 PORT까지 바꿔줘야한다.
그러면 패킷이 destination 으로 갔다가 돌아올 때 PORT number를 통해 어디로 가야하는지 찾는 것이다. 따라서 이를 통해 문제를 해결할 수 있다. 하지만 문제점도 있다.
라우터는 패킷이 전송될 때 header에 있는 source IP 주소와 TCP header에 있는 PORT number를 바꾼다. Network Layer는 패킷의 header만 봐야하는데, port number 를 변경하면서 Transport Layer의 port number도 변경되었다. 이것은 Layer violation이다. 또한 라우터는 forwarding하는 일에 집중해야 하는데 이러한 IP, Port 변환작업도 해야한다.
IP 주소의 기능은 호스트의 인터페이스를 찾기 위함이고 port number는 호스트내의 프로세스를 찾을 때 사용한다. 하지만 NAT에서는 port numebr가 호스트를 찾을 때 사용되었다. 그렇다면 NAT를 사용하는 네트워크 내부에서 서버를 운영할 수 있을까? 80번을 열고 웹서버를 운영하고 싶어도 80번으로 들어와도 프로세스까지 들어오지 못한다. 따라서 서버를 운영하질 못한다.
처음 IPv4를 70년대에 디자인할 때 주소공간과 보안에 관해선 생각해 놓지 못했다. 지금은 무언가 터지면 그걸 막기 위해 덕지덕지 무언갈 붙여서 급하게 대처하고 있다. 결론적으로 IPv4를 무조건적으로 붙잡고 있으면 안된다. 따라서 IPv6로 바꿔야한다는 목소리가 나오지만, 반대의 목소리도 나오고 있다. IPv6도 90년대에 디자인되어 벌써 많은 시간이 지나 앞으로 또 어떤 요구사항이 나올지 모른다는 것이다.
아키텍처를 바꾸는 것에 많은 시간이 필요하기 때문에 IPv6로 마음대로 바꾸지 못하고 있는 것이다. 그래서 미래엔 어떤 요구사항이 와도 유연하게 변경할 수 있는 유연한 프로토콜을 디자인해야할 것이다.
Dynamic Host Configuration Protocol
IP가 192.168.1.47, subnet mask가 255.255.255.0, routes가 192.168.1.1, DNS가 192.168.1.1이라고 하자.
이것들은 인터넷을 하기 위해 알고 있어야 하는 정보들이다. route는 내가 외부로 패킷을 보내기 위해 무조건 전달해야할 라우터의 정보가 적혀있는 것이다. 무조건 이 route에 던져야 패킷이 외부로 가는 것이다. 192.168.1.1가 내 IP와 prefix가 같은 것을 볼 수 있다. 같은 네트워크 내의 첫번째에 위치한 것을 알 수 있다. DNS는 만약 내가 웹서버를 열었을 때 local name server의 IP 주소이다. 이는 route와 같은 것을 볼 수 있다.
이러한 정보들은 필수적인데 내가 적어놓은것일까? 아니다. 이를 하는 것이 바로 Dynamic Host Configuration Protocol이다.
가장 중요한 단어는 Host Configuration이다. 즉, host 뚜겅을 딱 열었을 때 제일 처음에 configure해주는 것이다. dynamic 하다는 것은 어딜 가든 뚜껑만 열면 동적으로 이러한 정보를 제공해주겠다는 것이다. 내가 강의실에서 노트북을 열었을 때와 카페에 가서 노트북을 열었을 때 이러한 정보가 같을까? 아니다.
그런데 이러한 정보를 동적으로 해주는 이유는? 새로운 곳으로 갔을 때 해당 장소의 IP 주소와 route 주소를 알기 어렵기 때문이다. 하지만 항상 그런것은 아니다. 자기자신에게 고정된 IP를 사용한다면 위의 정보들을 내가 세팅해서 사용하는 것이다.
고정 IP를 사용하면 DHCP를 사용할 필요가 없다. A 기관에서 고정 IP를 사용한다고 가정하자. 그래서 기관의 사원들 별로 사원번호와 고정IP를 부여한다. 그래서 이 기관에 있을 땐 무조건 이걸 사용하는 것이다. 하지만 이러한 방식을 사용하면 금전적으로든 여러 방식으로 A기관이 손해를 본다.
예를 들어 사원이 만명이라면, 이 기관내에 IP가 최소 10000개 이상 필요하다. 하지만 DHCP를 사용하면 꼭 만개가 필요한것은 아니다. 동시에 active한 사원만큼만 필요하기 때문이다. 그대신 사원이 address를 요청했는데 자리가 남아있어 IP를 대여해주는데, 이때 회수를 꼭 해야한다. 따라서 고정 IP보다 유연하다는 장점이 있으나, 회수해야하는 단점이 있다.
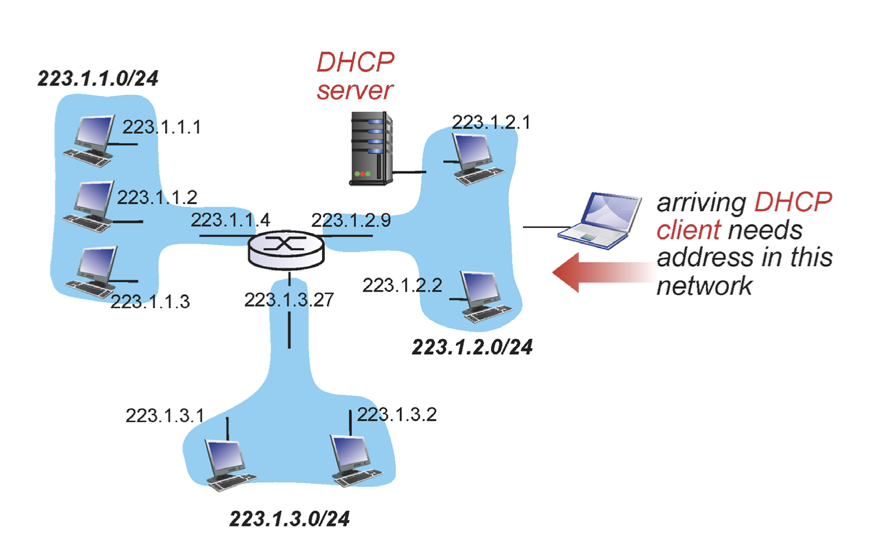
나는 사실상 노트북을 열었을 때 DHCP가 있는지도, DHCP의 IP도 모른다. 말그대로 아무것도 모르는 것이다. 예를 들어 강의실에 들어왔는데 누가 나에게 정보를 줄 수 있는 사람인지 구별할 수 없다는 것이다. 이때 어떻게 알 수 있는가? 모두에게 물어보면된다.
아래의 시나리오를 보자.
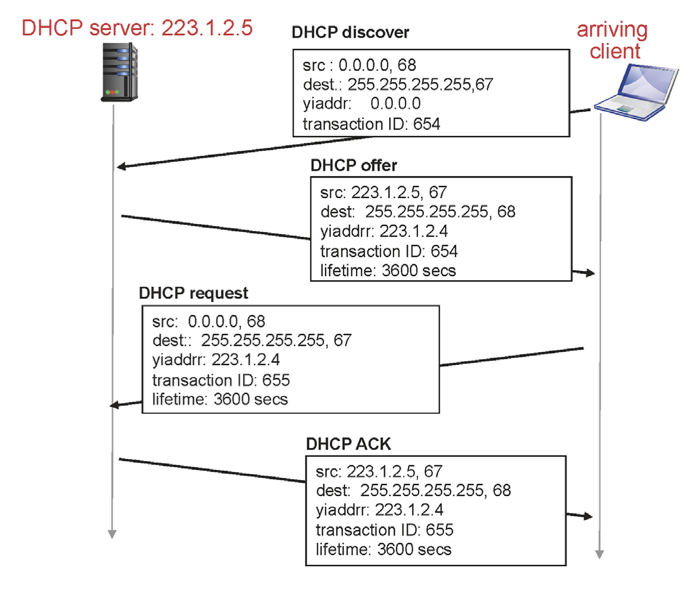
따라서 나 아직 아무것도 모른다는 의미로 0.0.0.0(무명)을 source로 해서 보낸다. 목적지는 255.255.255.255로 32비트로 봤을 땐 모두가 1인것이다. 모든 address가 1인경우는 broadcast이다. broadcast는 subnet에 있는 모든 member들은 이 메세지를 받으라는 것이다. 목적지 PORT 는 67번이다.
따라서 이 서브넷에 있는 모든 member가 이 메세지를 들을 것이다. 하지만 모든 host들이 이 메세지를 받아들이긴 하되 DHCP 서버만 의미있게 받아들이고 나머지는 무시해야한다. 어떤 원리로 나머지는 무시할 수 있을까? 255.255.255.255이므로 모든 host가 받는건 보장이 되어있다. 하지만 모두 67번 PORT는 닫고 있어 67번 PORT를 열고 있는 DHCP만 이 메세지를 의미있게 받아들일 수 있다. 즉, DHCP 는 67번 PORT를 사용하고, client는 68번 PORT를 사용한다.
DHCP는 offer를 준다. 이때 broadcast하는데, 이는 아직 내가 무명이기 때문이다. offer에 담긴것은 DHCP가 부여한 IP를 1시간동안 사용할 수 있다는 것이다. 그래서 나는 이를 받아 사용한다는 request를 보내야한다. 이때 source는 확정된것이 아니기때문에 여전히 무명으로 보낸다. request에 응답을 보내 끝나면 나는 이제 IP를 사용할 수 있다. offer에는 단순히 위의 그림에 있는 정보들만 아니라 DNS, route 정보도 적혀있다.
여기서 offer만 받지 않고, request를 받아 다시 응답까지 받는 이유는 무엇일까?
discover메세지가 의미하는 바는 나 처음 왔으니 도와달라는 것이다. 보통의 서버에는 DHCP가 하나만 있으나, 어떤 경우에는 여러개 있을 수도 있다. 따라서 DHCP가 2개 있으면 각각 offer가 오고 나는 여기서 원하는 걸 골라서 사용하기 위해 이러한 과정이 있는 것이다.
그렇다면 request는 왜 broadcast일까? 그냥 목적지 주소에 DHCP를 사용하면 안될까?
이것도 마찬가지로 DHCP가 여러개 있을 수 있기 때문이다. 내가 선택하지 않은 DHCP들에게도 내가 선택한 IP를 알리기 위함이다.
보통은 gateway router에 local DNS도 돌아가고, DHCP 서버도 동작하고 있다. 따라서 내가 처음에 노트북을 열었을 때 broadcast하면 모두가 듣긴 듣되 DHCP만 듣고 나머지는 무시한다. 서버프로세스가 없기 때문에.
그럼 gateway router에서 NS, DHCP와 더불어 어떤 기능을 또 하고 있을까? routing도 물론 하지만, routing은 Network layer에서 하는 것이고 NS, DHCP는 application layer에서 하는것이라고 볼 수 있다. NAT도 여기에서 동작한다.
만약 내가 SK 인터넷을 사용할 때 회선을 하나 준다. 이게 바로 IP 주소다. 무선 공유기를 사용한다면 이를 구성원들과 나눠쓴다. 따라서 이게 NS, NAT, DHCP이다. 무선 공유기가 gateway router인것이다. 그렇다면 이 것을 같이 사용하는 구성원들의 IP는 같을까? 아니다 내부에선 다 다르고 나갈땐 변환되어 같은걸로 나갈 것이다. 그렇다면 SK가 배당해준 IP는 전세계적으로 유일한 IP일까? 모른다. 또 NAT를 통한다면 유일하지 않을 것이다.
따라서 이를 통해서도 볼 수 있듯이 NAT내에 있는 것은 서버로 사용하지 못한다. NAT로 request가 들어오면서 port 번호가 변환되기 때문이다.
우리가 IP header의 필드들이 보았는데, 두번째 행의 필드들을 알아보지 않았다. 이에 대해 알아보자. 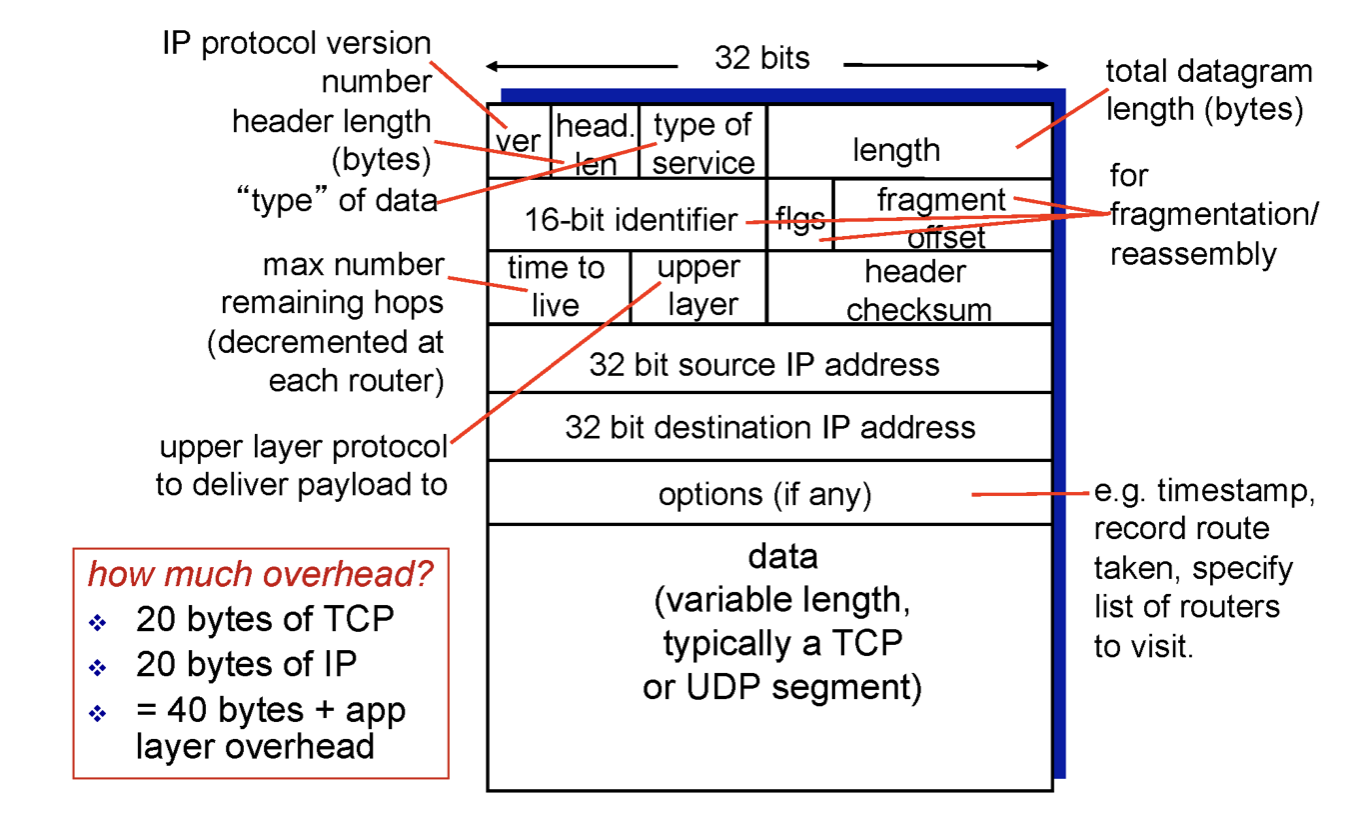
4000byte짜리 패킷을 생성해서 보낸다고 했을 때 link level에서 보낼 수 있는 크기는 정해져있다. 이는 max.transfer size로 각 link layer technology 마다 다르다. 예를 들어 4000바이트를 보냈는데 특정 링크에서 처리할 수 있는 크기가 1500이라면 갈 수 없다. 따라서 거기서 바로 분리를 해서 여러개의 독립적인 frame으로 바뀌어 분리된다. 따라서 이러한 작업을 위해 필요한게 두번째 행에 있던 필드들이다.
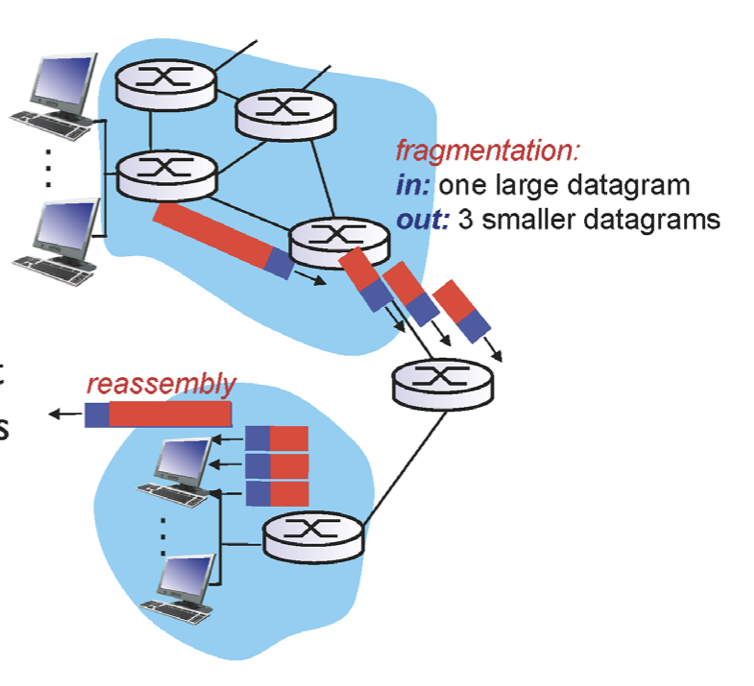
아래와 같은 패킷이 있다고 가정해보자. 길이는 4000이고 id는 패킷별로 유일하게 sender가 정하는 것이다. flag는 이 뒤로 fragment된게 있는지 나타난 것이다. 따라서 처음에는 fragment된게 없으므로 전부 0이다.
1500인 link를 만나면 분리가 되어야한다. 4000byte이므로 header는 20byte이므로 실제 data는 3980byte이다. 첫번째 fragment를 보면, ID는 유지를 해야한다. 어떤 패킷인지 알아야하기 때문이다. 그리고 flag를 1로 둬 첫번째 fragment 뒤에 또 fragment가 있음을 나타낸다. 또한 offset을 0으로 둬 제일 첫번째 fragment임을 나타낸다. 두번째 fragment도 마찬가지인데 offset이 185임을 알 수 있다. 이는 header의 크기를 줄이기 위해서 나누기 8을 한것이다. 즉, 첫 fragment는 1479까지 이고, 두번째 fragment부터는 1480이다. 이를 8로 나눠 나타낸 것이다.
따라서 두번째 fragment의 data는 1480 ~ 2959까지의 data이다. 세번째 fragment의 data는 2960 ~. 980까지이다.
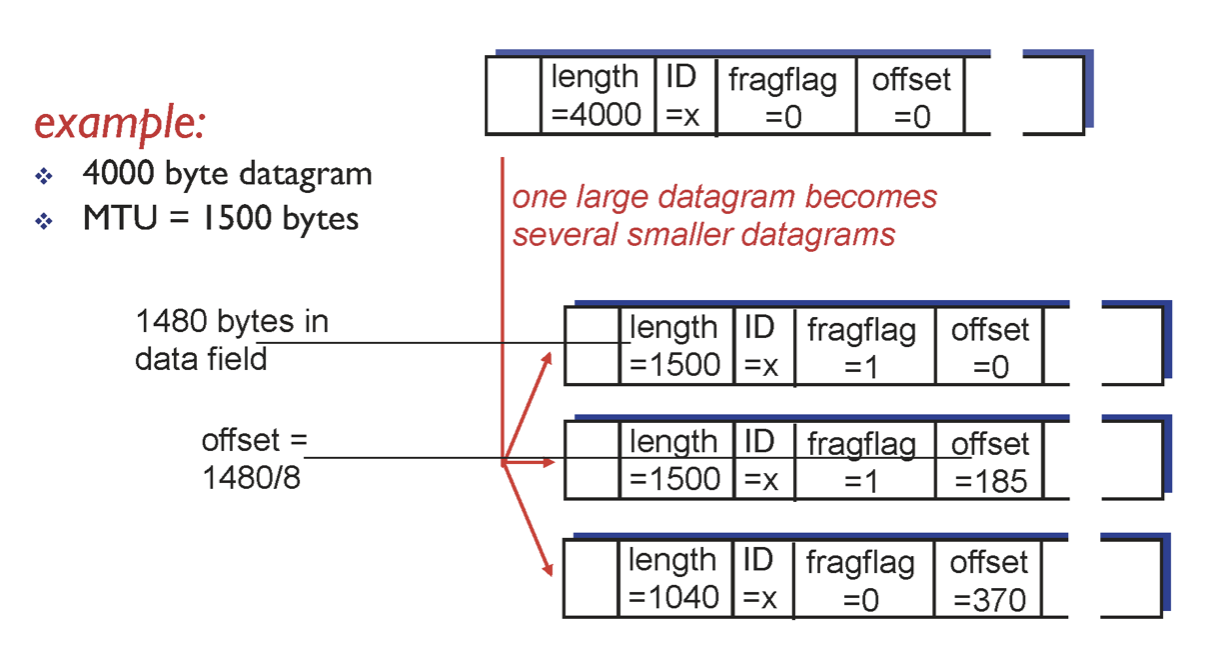
만약 분리되어 독립적인 패킷이 되어 가다가 중간에 하나가 유실되었다면 어떻게 될까? 우선 reassemble이 안되므로 올리지 못하고 그냥 버리는 것이다. 즉, TCP가 알아서 timer 터지고 재전송 한다.
Internet control message protocol
ICMP는 사용자 데이터가 아닌 네트워크 상황을 알기 위한 control message를 운반한다. 예를 들어 패킷이 source에서 부터 출발해 destination에 도착했는데 destination의 PORT가 열려있지 않은 경우 drop 된다. 혹은 TTL을 통해 drop되면 source에서는 무슨일이 일어난지 모른다. 따라서 이러한 일들을 source에게 알려주는 것이 필요하다. 이는 네트워크 자체에서 생성되는 것이며 이게 바로 ICMP로 Internet control message protocol이다.
이 메세지는 패킷이 만들어지는데 data 부분에 어떤일이 일어났는지 쓰여있다.

네트워크상에서 일어난 이벤트를 source에게 알려주기 위함
IPv6
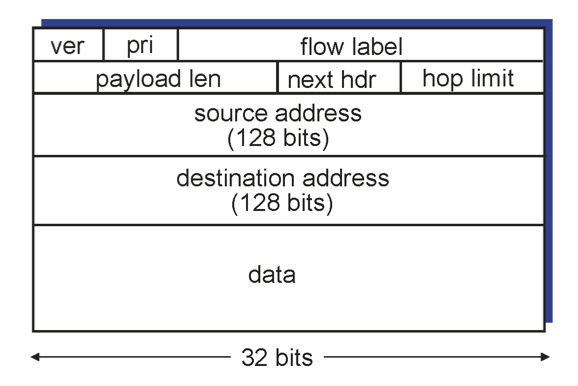
IPv4에 비해 굉장히 간소한 것을 볼 수 있다. 또한 가장 큰 차이는 주소공간의 확대이다.
중요한 것은 IPv6가 아니라 IPv6던 어떤 것이든 넘어가게 될 것인데, 이러한 과도기이다. 기존의 것과 새로운 것을 연결되어야 할 것이다.
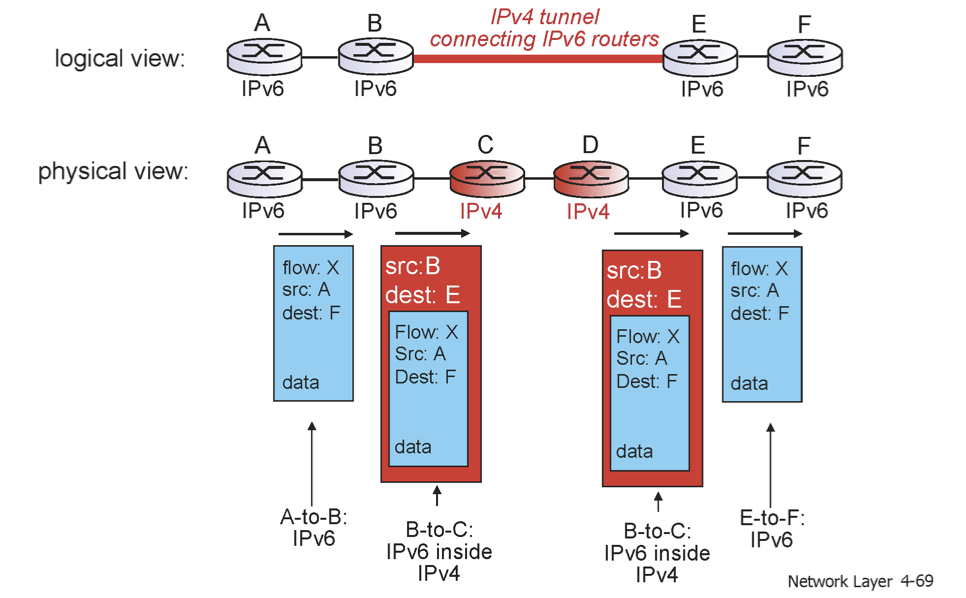
IPv4 route는 IPv4 이후의 라우터들의 header부분을 해석하지 못한다. 따라서 과도기 때에는 이들이 공존할 것이므로 IPv4에서 IPv6을 해석할 수 있게 header의 format을 맞춰줘야 한다. 따라서 위의 그림에서 C와 D는 IPv6를 이해하지 못하지만 B와 E는 IPv6를 이해할 수 있어 이 과정이 가능하다. 이러한 과정을 Tunneling이라 한다.
Routing Algorithm
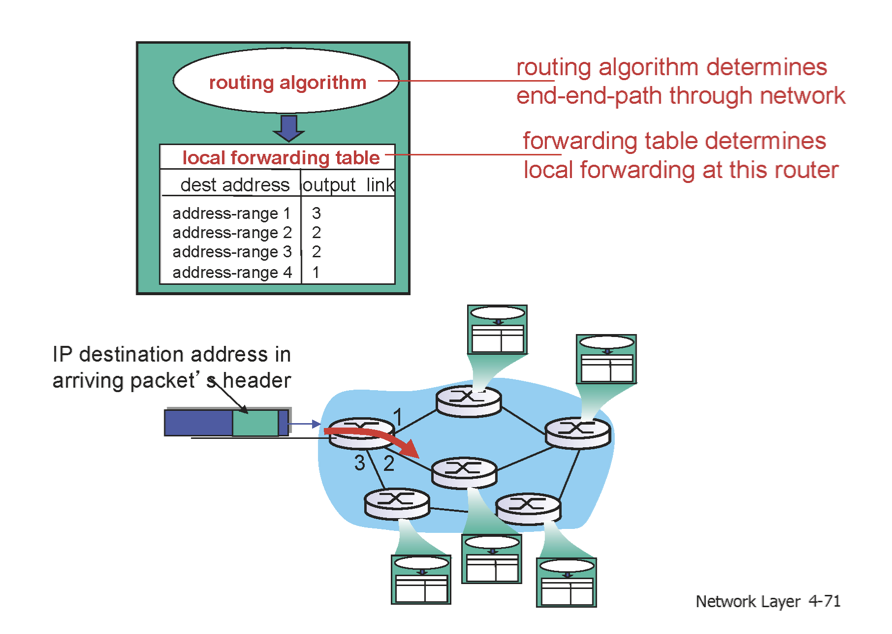
destination address 를 forwarding table에서 Longest prefix matching을 통해 찾아 outgoing link를 알 수 있다고 했었다. forwarding 작업은 forwarding table lookup에 지나지 않는다.
그렇다면 과연 forwarding table은 누가 만들어놨는가에 대해 고민해봐야한다. 이를 채워놓은 것이 routing algorithm이다.
우리는 네트워크를 그래프와 시킬 것이다. 따라서 가장 최소한으로 걸리는 경로를 찾아 table을 구성하면 되는 것이다.
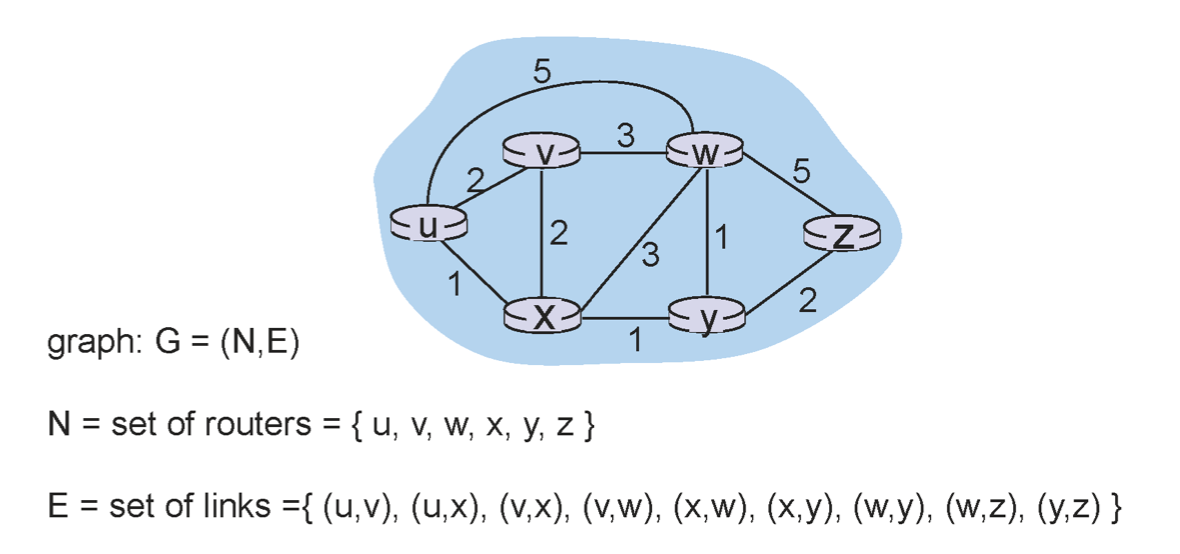
목적지 까지 최소 cost를 찾는 것이 routing algorithm의 목적이다.
두가지 접근 방식이 있다. 첫번째 방법은 네트워크 상황을 모두 아는 상태로 구하는 것, 두번째 방법은 모든 것을 아는 것이 아니라 이웃들하고만 정보를 주고 받는 경우이다.
첫번째 방법이 link state algorithm이고, 두번째 알고리즘이 distance vector algorithrm이다.
Link state
왜 link state일까? 아래의 그림에서 U와 Z는 직접 연결되어있지 않지만, 가는데까지의 상황을 모두 알아야 한다. 따라서 자신의 네트워크 상황을 모두 broadcast해서 모두가 알고 있게 만드는 것이다.
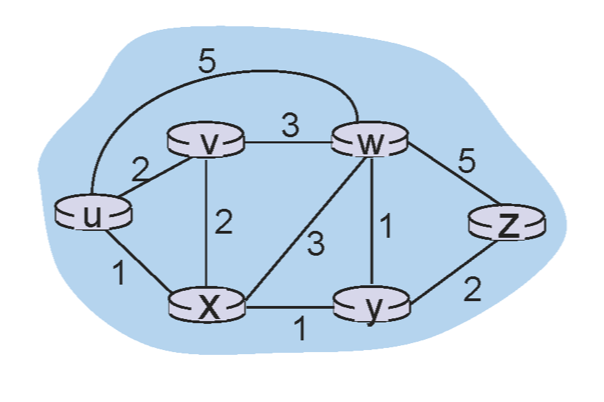
그래프의 최단 경로를 찾는 것이므로 즉, 다익스트라 알고리즘을 사용하는 것과 같다.
결국에 궁극적으로 하고자 하는 것은 forwarding table의 entry를 채우는 것이다.

notation은 위와 같다.
예제를 살펴보자.
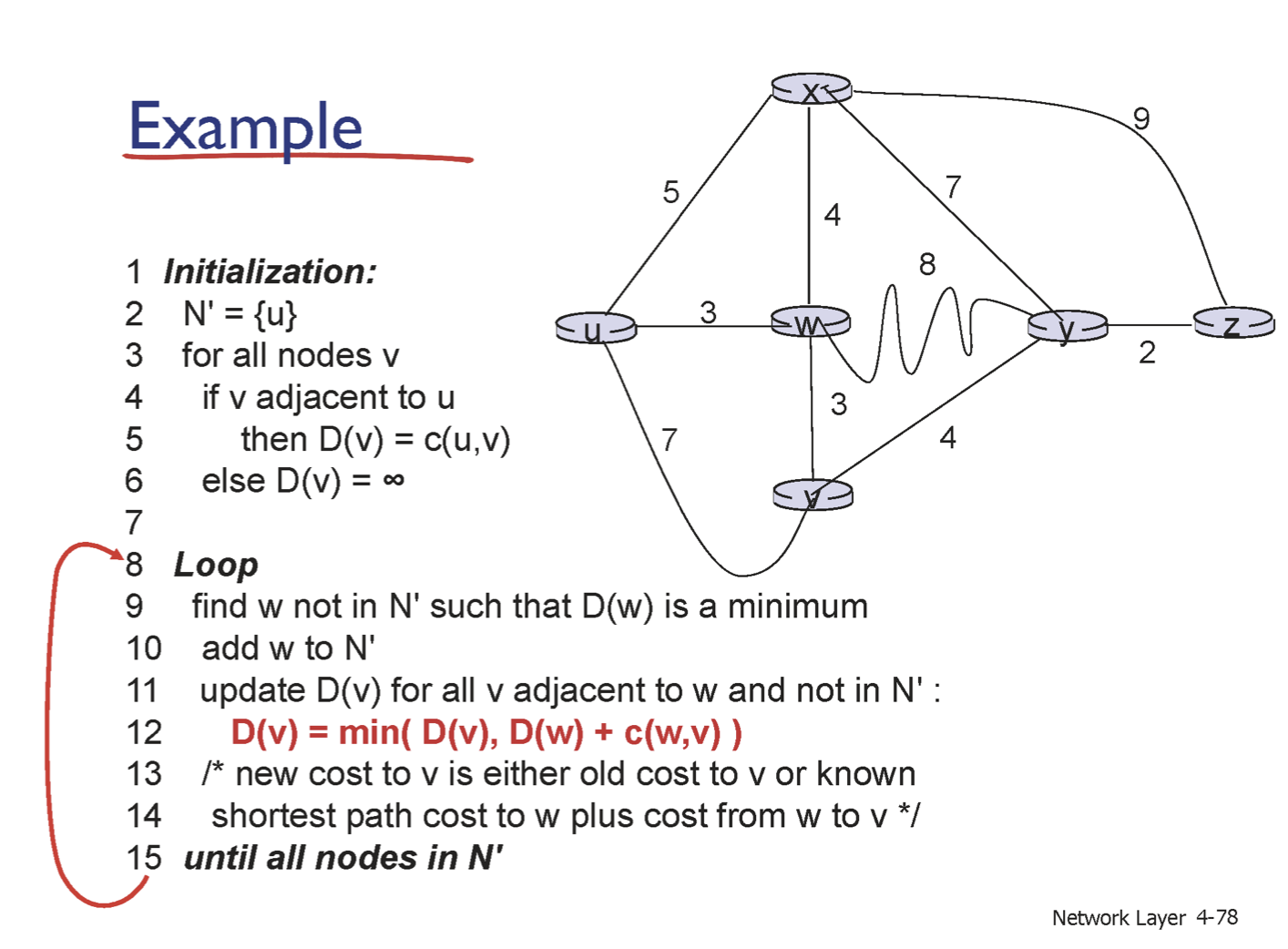
우선 N'을 초기화 한다. N'이란 현재까지 내가 최단거리를 알게된 노드의 집합이다.
내가 u이기 때문에 나는 u의 최단 거리를 알고 있으므로 u로 초기화하는 것이다.
그리고 모든 노드 v에 대해 D(v)를 초기화한다. 이때 u와 인접하면 u와 v까지의 거리로 초기화 한다.
그럼 아래의 표와 같이 ㅇ된다.
| N' | D(V) | D(W) | D(X) | D(y) | D(z) | |
|---|---|---|---|---|---|---|
| Round 0 | u | 7,u | 3,u | 5,u | ∞ | ∞ |
그리고 N'에 속하지 않으면서 가장 작은 distance를 가진 것은 W이다. 따라서 이제 N'에 W가 포함된다. N'에는 최단 거리를 가진 노드의 집합이므로 W의 거리는 확정이다.
그리고 새로 속한 W와 인접하면서 N'에는 있지 않은 모든 v에 대해서 D(v) = min(D(v),D(w)+c(wv))로 D(v)를 update 한다.
| N' | D(V) | D(W) | D(X) | D(y) | D(z) | |
|---|---|---|---|---|---|---|
| Round 0 | u | 7,u | 3,u | 5,u | ∞ | ∞ |
| Round 1 | u,W | 6,w | 5,u | 11,w | ∞ |
따라서 위와 같이 update할 수 있다. 이를 반복하다보면 아래와 같은 표를 최종적으로 얻을 수 있다.
| N' | D(V) | D(W) | D(X) | D(y) | D(z) | |
|---|---|---|---|---|---|---|
| Round 0 | u | 7,u | 3,u | 5,u | ∞ | ∞ |
| Round 1 | u,W | 6,w | 5,u | 11,w | ∞ | |
| Round 2 | u,W,x | 6,w | 11,w | 14,x | ||
| Round 3 | u,W,x,y | 10,v | 14,x | |||
| Round 4 | u,W,x,y,v | 12,y | ||||
| Round 5 | u,W,x,y,v,z |
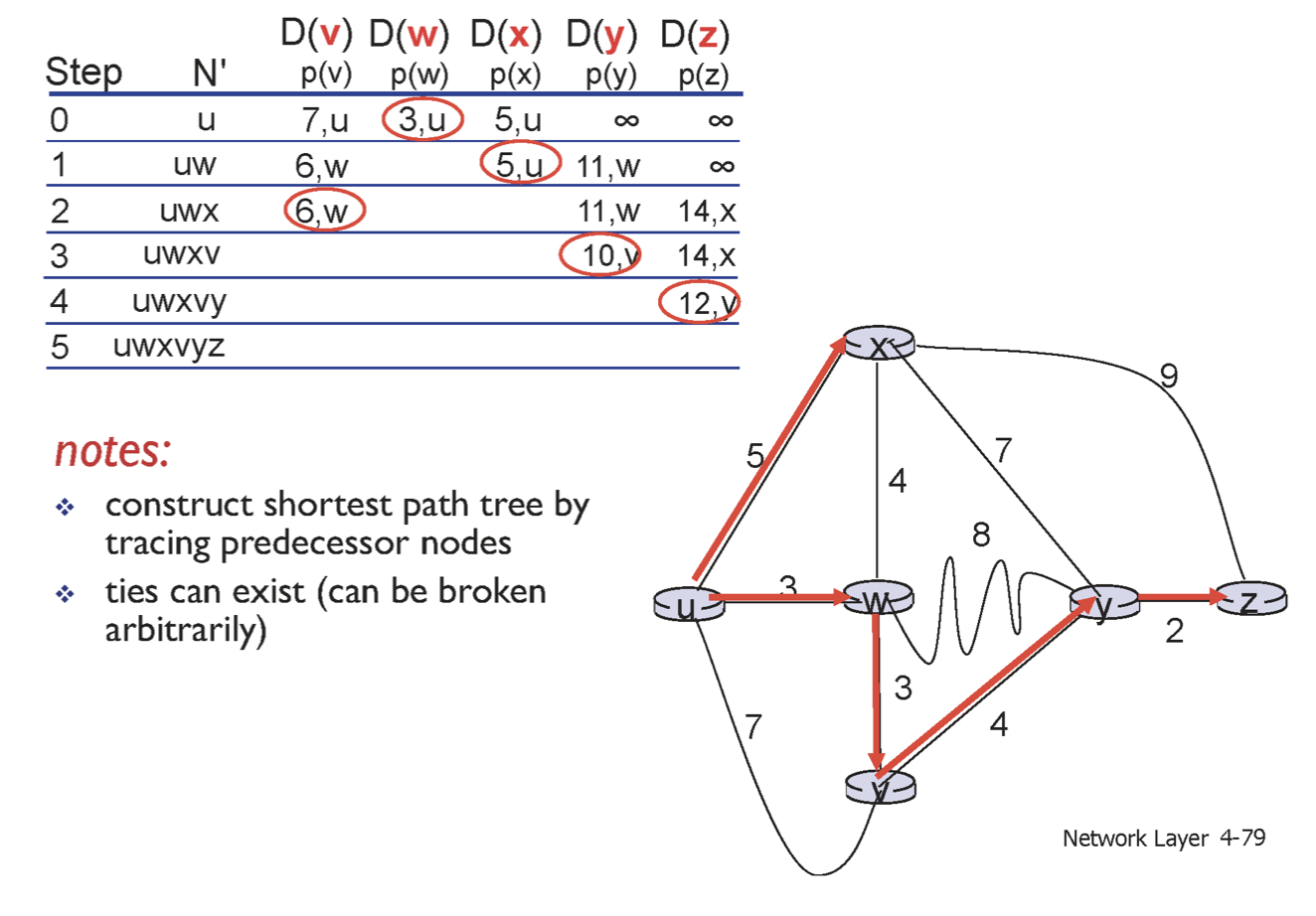
따라서 최종적으로 forwarding table은 아래와 같다.
| destination | outgoing |
|---|---|
| v | w |
| x | x |
| y | w |
| w | w |
| z | w |
complexity를 생각하면 O(n^2)이다.
다익스트라 알고리즘을 사용하면 oscillations현상이 일어날 수 있다. 아주 적은 양의 data를 보낸다고 가정하자. 각각 1과 e를 가진 data들을 D와 C에서 보내면 해당 link의 cost가 traffic으로 인해 올라간다. 따라서 cost가 왼쪽으로 쏠렸다가 오른쪽으로 쏠렸다가 할 수 있는 것이다.
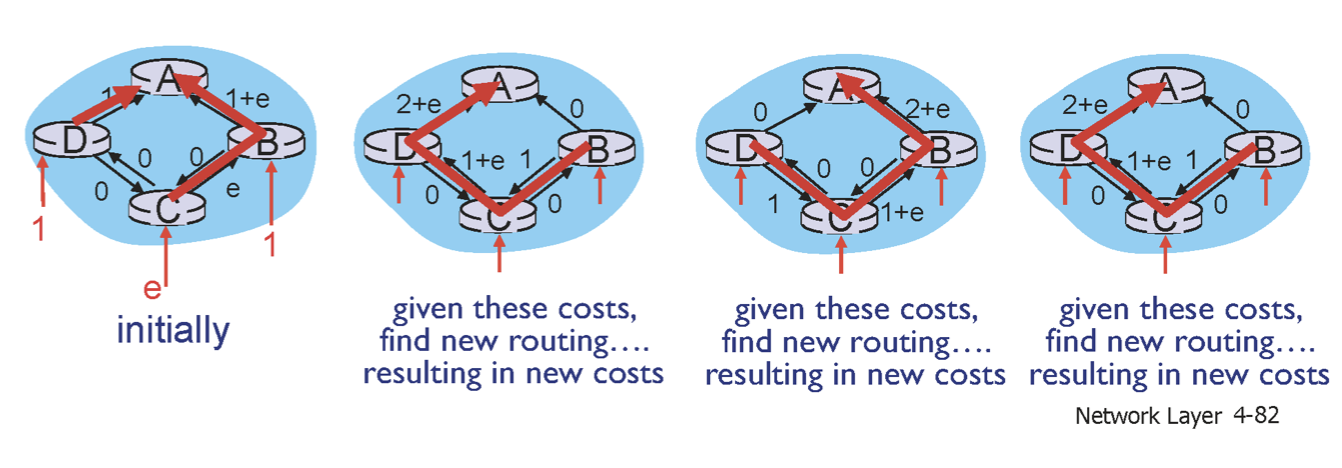
그런데 생각해보자. 우리는 모든 라우터들의 cost들을 알고 있을 수 있을까? 따라서 현실적으로 broadcast의 범위는 하나의 네트워크이다.
하나의 네트워크란 관리 주체가 동일한 네트워크들의 집합이다. 누가 책임지느냐에 따라 달라진다. 관리하는 사람이 사용하고 싶은 알고리즘을 사용하는 것이다. 더 나아가서 각 네트워크 주체별로 알고리즘을 골라서 사용한다. 그렇다면 이 네트워크들끼리 사용하는 알고리즘도 있을 것이다. 즉, A기관 부터 B기관 까지의 알고리즘도 있을 것이다. A기관 내의 네트워크 알고리즘은 A기관이 결정하면 되는데 그렇다면 기관끼리의 알고리즘은 어떻게 결정할까?
Distance vector
이 알고리즘은 broadcast를 통해 모든 cost를 알고 잇는게 아니라 인접한 cost를 통해 전체를 유추해 최소 경로 테이블을 만드는 과정이다. 따라서 직관적이지 않다.
중요한 것은 아래의 식이다.
x에서 y까지 최소 경로는 무조건 x의 이웃중에 하나를 거쳐갈 수 밖에 없다. 만약 x의 이웃이 a,b,c가 있고 a를 거쳐서 가는게 최소 경로라면 x에서 a까지 가는 경로 + a에서 y까지 가는 경로인 c(x,a)+da(y)가 x에서 y까지 가는 최소 cost일 것이다. 이때 우리는 c(x,a)를 알고 있으므로 da(y)는 모른다. 따라서 이는 방금과 같이 구하면된다.

즉, dx(y) = min{c(x,v)+dv(y)}에서 dv(y)는 v'가 v의 이웃중 가장 작은 코스트를 가질 때 dv(y)=min{c(v,v')+dv'(y)}이다.
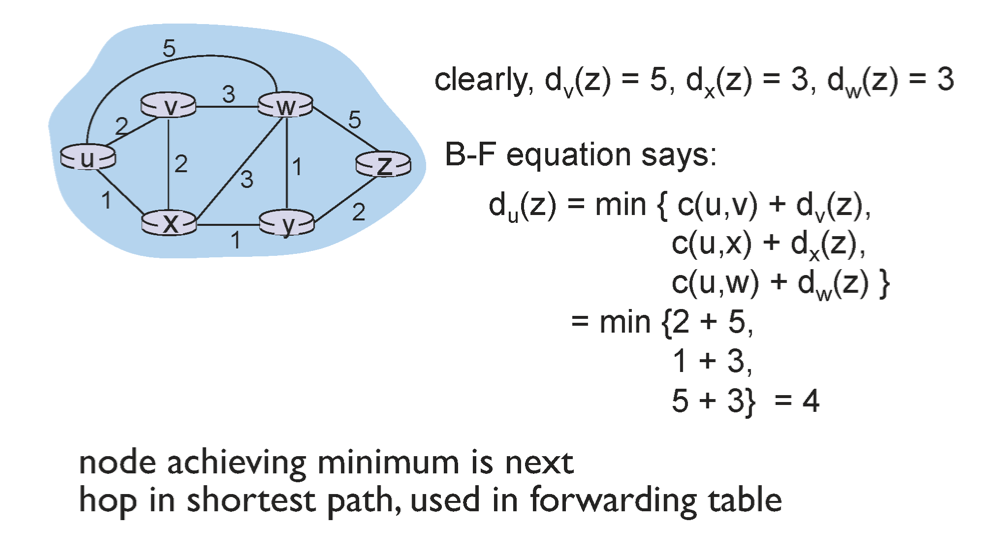
여기선 v가 자신과 인접한 노드와의 cost들의 리스트(벡터)들을 넘겨주기 때문에 distance vector이다.
자기자신의 distance 값이 바뀌면 이웃들에게 그 값을 전달한다. 이 값을 전달 받으면 다시 계산하고 udpate 되면 다시 전달한다.
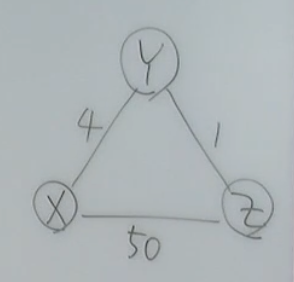
위와 같은 네트워크가 주어진다고 가정해보자.
그렇다면 이웃 노드들의 cost만 알고 있으므로 표를 아래와 같이 채울 수 있다.

그러면 이제 X는 Y,Z로 부터 인접 노드까지의 cost를 각각 받아 아래와 같이 된다.
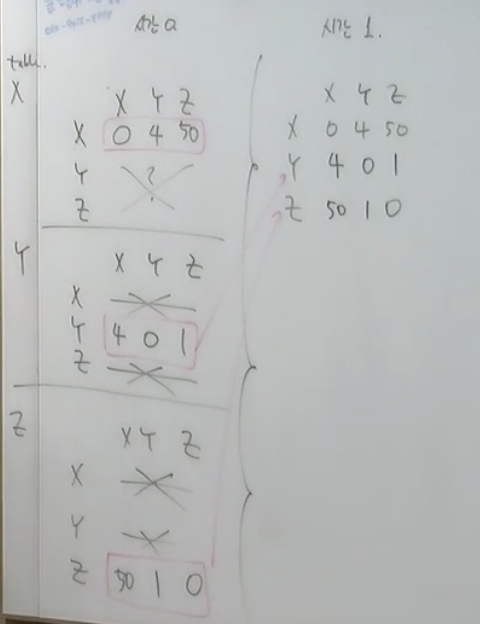
이제 받은 값을 통해 dx(y) = min{c(x,v)+dv(y)}을 대입하면 된다.
x에서 y를 가는 것(dx(y))은 min{c(x,y)+dy(y), c(x,z)+dz(y)}이다. 이는 4이므로 update되지 않는다.
x에서 z를 가는 것(dx(z))은 min{c(x,z)+dz(z), c(x,y)+dy(z)}이다. 각각 5, 50이므로 기존의 50보다 5가 더 작아 5로 update된다. 이를 Y, Z에 대해 반복하면 아래와 같아진다.

업데이트 된 값이 있으면 이를 이웃에게 전달한다. 따라서 전달하면 아래와 같다.

업데이트 된 값을 전달 받았으니 다시 계산해봐야한다. dy(x)를 계산해보자.
dy(x) = min{c(y,x) + dx(x), c(y,z) + dz(x)} = min { 4+0, 1+5 } = 4이다. 이제 모두 변하는 값이 없으므로 계산은 끝난다.
최종적으로 안정화가 되어서 계산이 끝났는데, 만약 x와 y사이의 link cost가 변하면 update를 해줘야한다. 그리고 이를 다시 계산했을 때 값이 update 된다면 이웃에게 전달해준다.
그런데 만약 c(x,y)가 50으로 바뀌었다고 생각해보자. 그러면 dy(x) = min{c(y,x) + dx(x), c(y,z) + dz(x)} = min { 50+0, 1+5 } = 6으로 바뀌게 된다. 하지만 생각해보면 이는 잘못된 것이다. dz(x)는 더이상 5가 나올 수 없기 때문이고 이는 다시 자기 자신으로 돌아오는 길이기 때문이다. 따라서 이는 50이 될 때 까지 많은 연산을 필요로 한다.
distance vector에서는 이와같이 특수한 현상이 나타한다. 이는 전체 큰 그림을 보지 못한채 이웃값에만 의존하기 때문에 이 값이 자기자신에 의존하는지 몰랐기 때문이다. 이러한 현상을 count to infinity라고 한다. 따라서 이를 방지하기 위해선 dz(x)를 무한대로 알려줘야한다. 왜냐하면 이는 y로 다시 갔다가 x로 가는 값이기 때문이다. 무한대로 알려주게 되면 올바른 값인 50이 된다.
만약 50이 아닌 60으로 바뀌었다면 round를 한번 더 갈 것이다.
다른 예시는 다음과 같다.
이러한 routing algorithm은 위에서도 이야기 했었지만, 한 네트워크 내에서의 범위이다.

위와 같이 인터넷이 있을 때 link state를 사용할 수 있을까? 없다. 따라서 계층을 나눠 생각한다. 각각의 네트워크들은 내부에서는 위의 알고리즘을 사용한다. 그리고 이러한 네트워크끼리의 연결은 다른 라우팅 알고리즘을 사용해 계층을 나누는 것이다.
예를 들어 A기관에서 B기관에 접속하려한다고 생각해보자. A는 link state 알고리즘을 사용해 최적의 경로로 나오고 A에서 B까지 또 routing algorithm을 사용하고 B에 가서도 다른 routing algorithm을 통해 목적지에 도달한다. 즉, 각자 독립적으로 자치권이 있다고 해서 하나의 기관을(네트워크를) autonomous system(AS)라고 한다. 이제까지 본 알고리즘은 AS내부의 알고리즘이었다.
따라서 이를 Intra-AS routing algorithm이라고 하며 AS 외부에서 동작하는 알고리즘은 inter-AS routing algorithm이다.
Intra-AS는 최소 cost가 목적이지만, inter-AS는 최단 경로가 목적이 아니다. 무작정 최단 경로가 아닌 기술적인, 경제적인 요건이 들어가게 된다. 예를 들어 우리나라에서 중국의 네트워크에 접근하고 싶다면 북한을 통해야하는데, 이를 피하기 위해 돌아가는 것이 있다.
AS는 자치권을 가진 네트워크 집합인데, 이는 각자의 number를 가지고 있다.

inter-AS의 그래프는 아래와 같이 나타낼 수 있다.
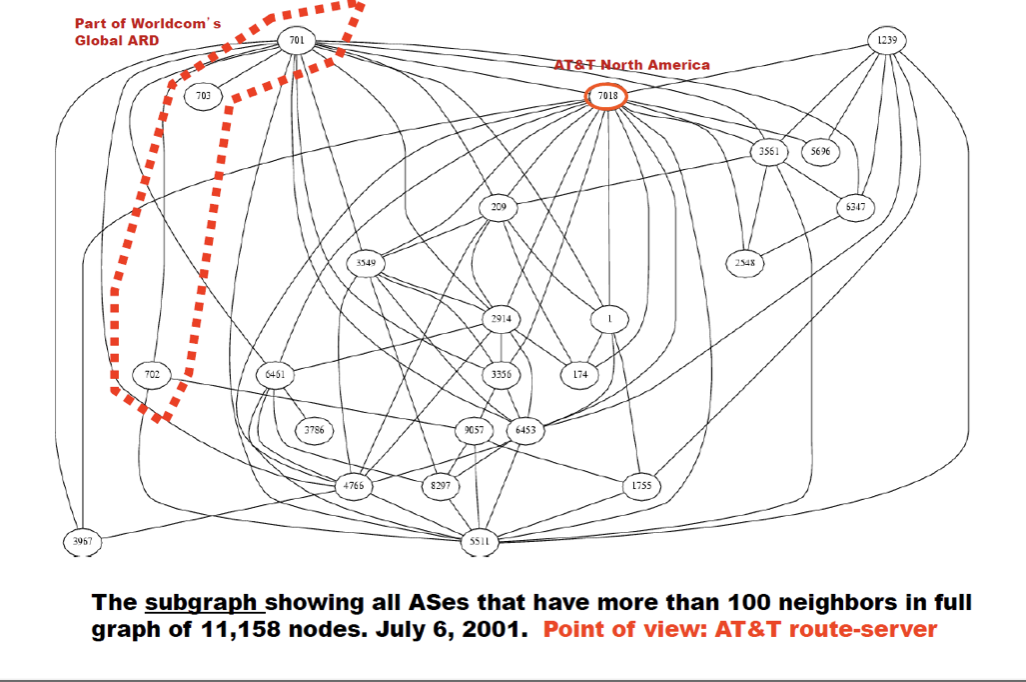
AS를 운영하려면 돈이 필요하다. 또한 A기관이 있다고 했을 때 이 A기관 하나로는 아무것도 하지 못한다. 다른 AS들과 연결이 되어야 할 것이다. 이러한 것을 운영하기 위해 KT나 SKT등에 돈을 주고 서비스를 받는 것이다. 따라서 AS 사이에는 아래와 같은 제공자와 사용자가 존재한다.
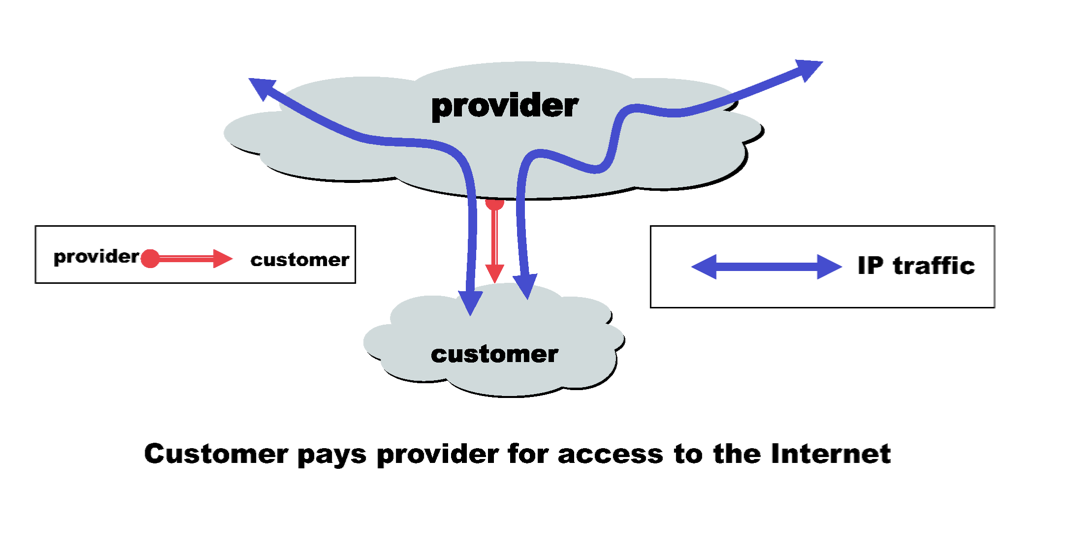
연결을 제공하는 AS를 provider라고 하고 서비스를 받는 AS를 customer라 한다. 누구나 provider가 되고 싶을 것이다. 누가 provider가 되고 누가 customer가 되는것을 누가 정할까? (양현석이 말하길 협상할 때 무서운 사람이 아무것도 필요없는 사람이라고 했다) SKT는 사용자가 굳이 필요없다. 하지만 사용자는 SKT가 필요하다. 그렇다면 만약 SKT와 KT가 만나면 어떻게 될까? 특수한 관계인 peer가 맺어진다.
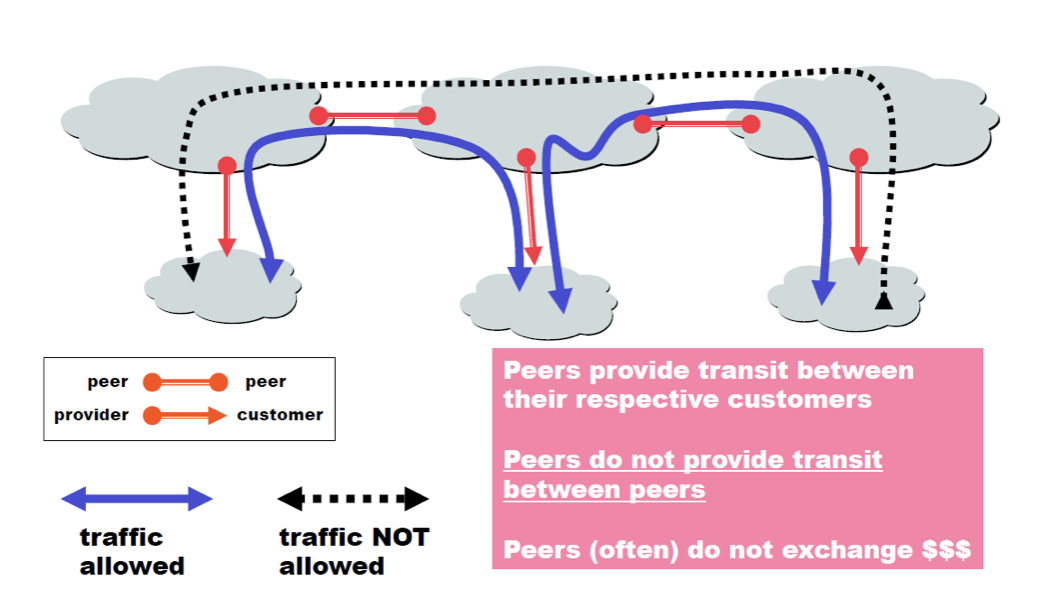
이들은 서로 비슷하니 돈을 받지 않는다. 만약 SKT를 북미대륙을 관장하는 AT&T와 비교한다면 SKT는 customer가 된다. 즉, 상대적인 것이다.
그래서 결론적으로 아래와 같은 traffic이 형성되는 것이다.
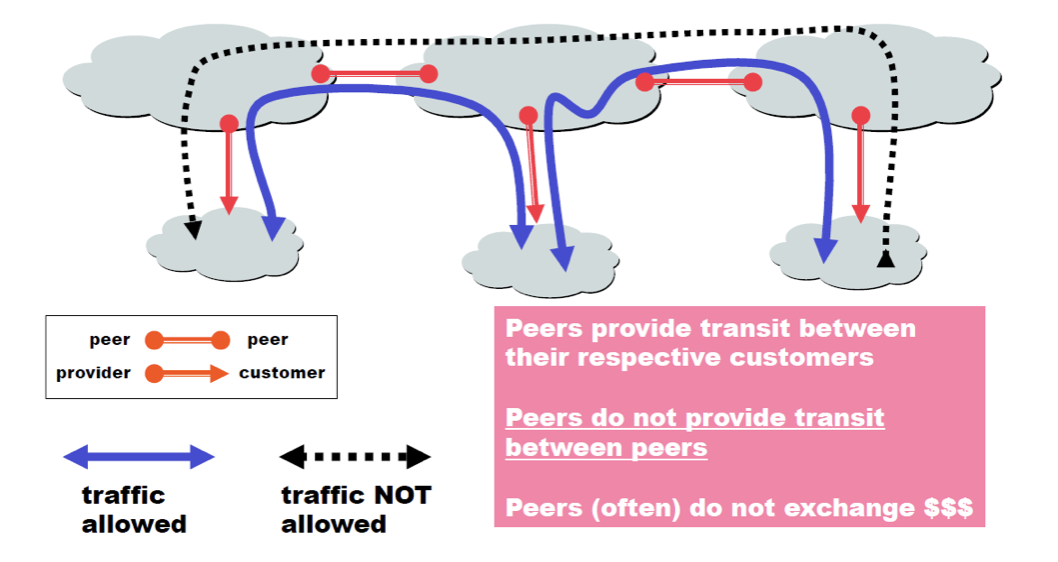
검은색은 traffic이 형성되지 않는다. 돈을 안주기 때문이다.
따라서 이걸 구현한것이 BGP이다.
BGP
Border Gateway Protocol이다. AS의 경계에 있는 gateway router간에 어떻게 routing하는지에 대한 것이기 때문이다. 가장 큰 특징은 Policy Based이다. 최단경로가 목적인 Intra-AS와 달리 정책에 따라 경로가 좌우된다.
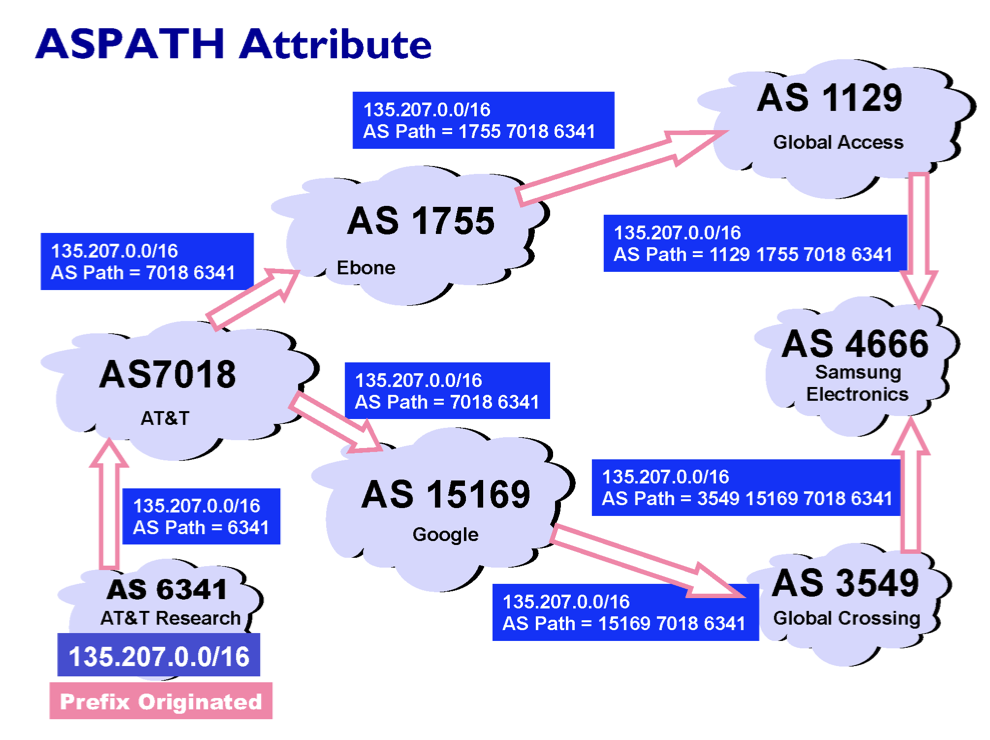
자신의 AS를 다른 AS들에게 광고하는 그림이다. 전달하는 것을 보면 자신의 IP prefix와 AS Path를 전달하는데 처음에는 자신의 AS number이다. 하지만 전달되면서 AS Path에 자신의 AS number를 추가한다. 이를 통해 AS 4666은 AS6341까지 가는 길을 2가지 받게 되어 선택하면 된다. Path를 보며 hopes가 적고 거쳐가기 꺼려지는 AS를 피해 선택한다. 또한 경제적인 비용도 생각해야 할 것이다.
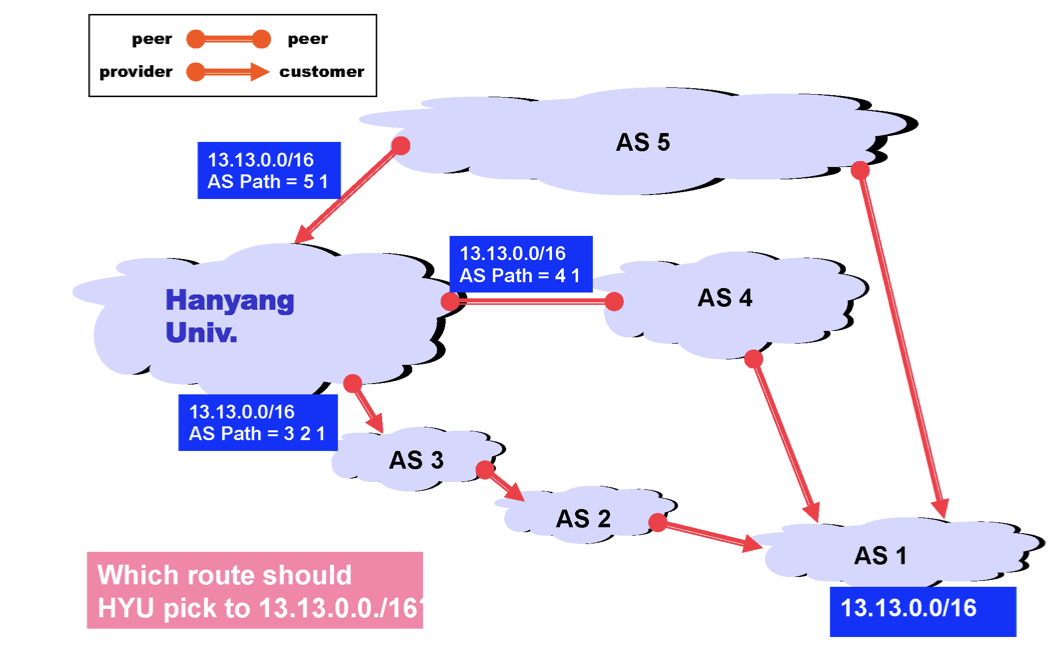
위의 상황에선 AS1으로 향하는 경로는 3가지가 있다. 사실 경로만 따졌을 땐 AS 5, AS 4를 고르겠지만 실제 선택하는 것은 AS 3, AS 2 경로일 것이다. 왜냐하면 내가 provider의 입장이기 때문이다. 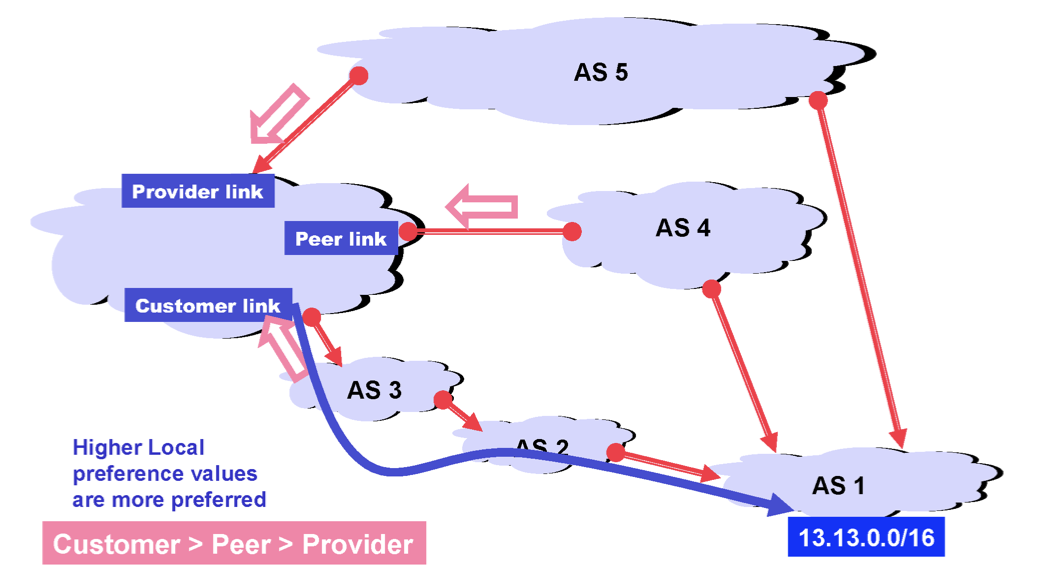
출처
