상속 관계 매핑
객체는 상속관계가 있으나 관계형 데이터베이스는 상속관계가 없다.
슈퍼타입 서브타입 관계라는 모델링 기법이 객체의 상속과 유사해서 사용할 수 있다.
상속관계 매핑 : 객체의 상속과 구조를 db의 슈퍼타입 서브타입 관계를 매핑하는 것
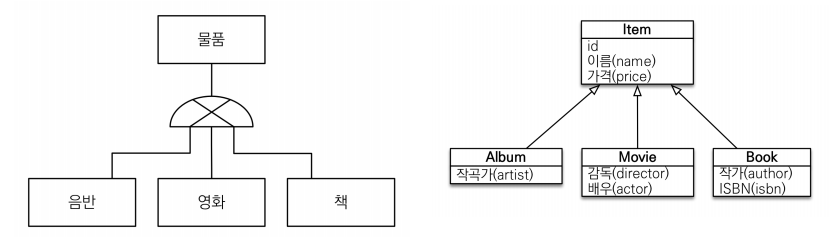
왼쪽 : 논리 모델 / 슈퍼 타입 서브 타입-> 음반, 영화, 책에서 공통적인 부분을 뽑아 내 물품
오른쪽 : 객체는 상속 관계 가능하다.
상속 관계 매핑
슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법은 ?
아래의 세가지 방법이 있다.
- 각각 테이블로 변환 -> 조인 전략
- 통합 테이블로 변환 -> 단일 테이블 전략
- 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
객체는 상속관계가 지원되기 때문에 세가지 방법 모두 객체 입장에선 똑같다.
상속관계 매핑은 세가지 방법중 아무거나 써도 매핑하도록 지원해준다.
주요 어노테이션
@Entity
public class Item {
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
public class Album extends Item{
private String artist;
}
@Entity
public class Movie extends Item{
private String director;
private String actor;
}
@Entity
public class Book extends Item{
private String author;
private String isbn;
}
를 실행하면 한테이블에 모든 컬럼 정보가 다 들어가는 것을 확인할 수 있다.
따라서 싱글 테이블 전략이 기본으로 실행되는 것이다.
어떻게 써야하는가 ? 3가지 전략 중 선택할 수 있다.
@Inheritance(strategy=InheritanceType.XXX) 를 통해 선택할 수 있다.
• JOINED: 조인 전략
• SINGLE_TABLE: 단일 테이블 전략
• TABLE_PER_CLASS: 구현 클래스마다 테이블 전략
조인 전략
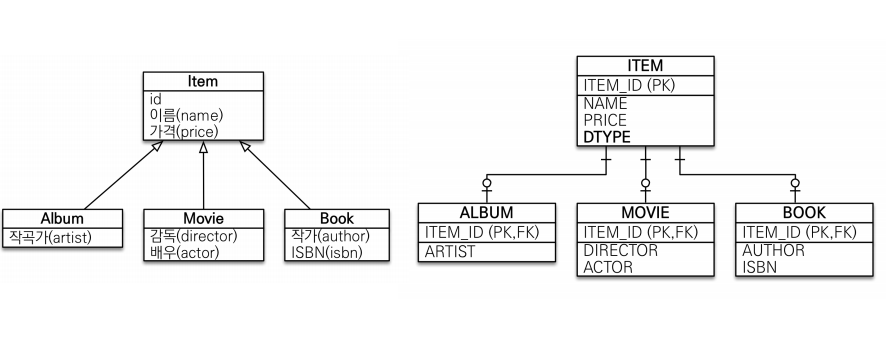
item 테이블을 만들고 album, movie, book테이블을 만들어 데이터를 나눈다. 그리고 join으로 구성하는 것 데이터를 join으로 가져온다.
item에 item_id를 두고 album의 가격이나 이름은 item에 두고 album의 고유 데이터인 artist는 album에 넣는다. 따라서 insert를 두번 한다.
조회는 pk,fk로 조인해서 가져온다.
구분을 할 수 있어야 하는데 어떻게 해야하나. 구분하는 컬럼 dtype을 둔다.
정규화된 방식이다. - 조인전략으로 문제를 해결하면 데이터가 정규화되어서 들어감 name, price가 중복되지 않고 들어가기 때문
가장 유사한 방식이다.
creat
ITEM에 @Inheritance(strategy = InheritanceType.JOINED)
를 추가해주면 조인전략으로 실행되는 것을 확인할 수 있다.
create table Album (
artist varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
create table Book (
author varchar(255),
isbn varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
create table Item (
id bigint not null,
name varchar(255),
price integer not null,
primary key (id)
)
Hibernate:
create table Movie (
actor varchar(255),
director varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
alter table Album
add constraint FKcve1ph6vw9ihye8rbk26h5jm9
foreign key (id)
references Item
Hibernate:
alter table Book
add constraint FKbwwc3a7ch631uyv1b5o9tvysi
foreign key (id)
references Item
Hibernate:
alter table Movie
add constraint FK5sq6d5agrc34ithpdfs0umo9g
foreign key (id)
references ItemINSERT
Movie movie = new Movie();
movie.setName("aa")
movie.setPrice(1000)
movie.setAuthor("111")
movie.setDirector("Aa")
em.persist(movie)를 실행하면 insert 쿼리가 두번 나가는 것을 알 수 있다.
name과 price는 item에, author와 director는 movie 테이블에 각각 insert된다.
/* insert hellojpa.Album
*/ insert
into
Item
(name, price, id)
values
(?, ?, ?)
Hibernate:
/* insert hellojpa.Album
*/ insert
into
Album
(artist, id)
values
(?, ?)
둘의 id는 같다.
em.flush
em.clear
em.find(Movie.class, movie.getId()로 1차 캐시를 비우고 조회하는 쿼리를 확인해보면 inner join을 하는 것을 확인할 수 있다.
flush와 clear를 안하면 1차 캐시에서 가져오므로 쿼리를 확인할 수 없다.
Hibernate:
select
album0_.id as id1_2_0_,
album0_1_.name as name2_2_0_,
album0_1_.price as price3_2_0_,
album0_.artist as artist1_0_0_
from
Album album0_
inner join
Item album0_1_
on album0_.id=album0_1_.id
where
album0_.id=?사진에 있던 dtyp을 우리는 예시에서 적지 않았다. 어노테이션으로 해결할 수있기 때문인데
@DiscriminatorColumn(name=“DTYPE”)
를 추가하면 알아서 테이블 생성시에 컬럼으로 추가된다.
디폴트로 엔티티명이 들어간다.
넣는게 좋다. db만 봤을 땐 dtype이 없으면 어렵다.
name을 통해 이름을 바꿀 수 있다.
@DiscriminatorValue(“XXX”)의 디폴트는 엔티티명이다.
회사 규약상 Album을 A로 표현해야할 때 위의 어노테이션을 사용하면 Dtype에 들어가는 엔티티 명을 Movie가 아닌 M등으로 설정할 수 있다.
조인 전략에선 Discriminator가 필요없어도 되지만, 싱글테이블 전략에선 꼭 들어가야한다 .
장점
정규화가 되어있고, 제약조건 같은 걸 item에 걸어서 다 맞출 수 있다.
가격으로 정산을 해야되면 item 테이블만 봐도 되는 등
외래 키 참조 무결성 제약조건 활용가능
주문 테이블에서 item을 봐야할때 item 테이블만 보면된다.
정규화되어있기 때문에 저장 공간 효율화
단점
조회시에 조인을 많이 사용한다. 따라서 조회 쿼리가 복잡하다.
데이터 저장시 insert 쿼리 두번 호출한다.
별로 그렇게 단점은 안되는데 단일 테이블 전략에 비해선 단점이 되긴한다.
저장공간이 효율화 되기 때문에 어찌보면 성능이좋을수도 있다.
조인전략을 기본으로 해야한다.
단일 테이블 전략
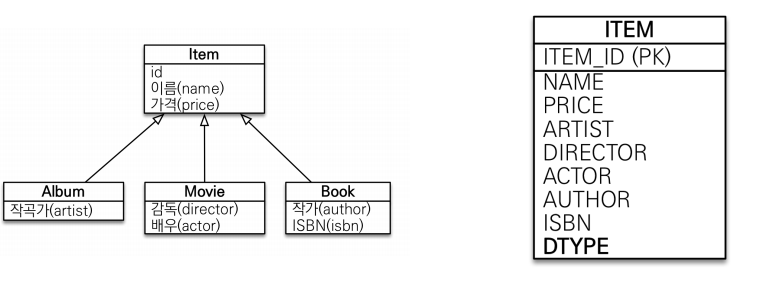
db를 설계해봤는데 너무 복잡하고 우리는 간단하게 해도 되니 심플하게 가자 할때 사용한다.
ITEM에 Inheritance(strategy = InheritanceType.SINGLE_TABLE)를 추가해도 되고 안해도 기본값이 단일 테이블 전략이기 때문에 생략해도 된다.
create table Item (
DTYPE varchar(31) not null,
id bigint not null,
name varchar(255),
price integer not null,
artist varchar(255),
author varchar(255),
isbn varchar(255),
actor varchar(255),
director varchar(255),
primary key (id)
)Album, Movie, Book의 컬럼이 모두 Item으로 들어가서 성능면에서 좋다
/* insert hellojpa.Album
*/ insert
into
Item
(name, price, artist, DTYPE, id)
values
(?, ?, ?, 'Album', ?)insert 쿼리가 한번 나간다.
select
album0_.id as id2_0_0_,
album0_.name as name3_0_0_,
album0_.price as price4_0_0_,
album0_.artist as artist5_0_0_
from
Item album0_
where
album0_.id=?
and album0_.DTYPE='Album'조회를 할 때도 조인할 필요없이 id와 dtype만 가지고 할 수 있다.
단일 테이블 전략은 @DiscriminatorColumn(name=“DTYPE”) 이 없어도 자동으로 생성된다.
조인 전략은 어떻게든 테이블이 나눠져 있으니 찾을 수 있는데 싱글 테이블 전략은 테이블 하나에 들어있으니 dtype이 필수 이기 때문이다.
jpa 스펙상 조인 전략에도 dtype이 필수로 들어가야하나, hibernate는 이를 필수로 하지 않아 조인전략시에는 넣지 않아도 된다.
근데 왠만하면 넣는게 좋다.
db설계가 아예 바뀌었는데도 코드는 어노테이션 말고 바뀐게 없다.
조인 전략을 했다가 성능이 너무 안나와서 싱글 테이블 전략으로 가기로 했을 때 JPA를 사용하면 어
노테이션만 바꾸면 된다. 기존에는 쿼리문을 다바꿨어야했다.
장점
• 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
• 조회 쿼리가 단순함
단점
• 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야된다. 따라서 데이터의 무결성 입장에서 좋지 않다. album을 넣으면 movie의 컬럼인 director 같은 건 다 null이 들어감
• 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 조회 성능이 오히려 느려질 수 있다. 하지만 보통 조인 전략 보단 빠르다. 조회성능이 느려질 수 있는 상황까지 가려면 임계점을 넘겨야 하는데, 그정도는 쉽지 않다
구현 클래스마다 테이블 전략
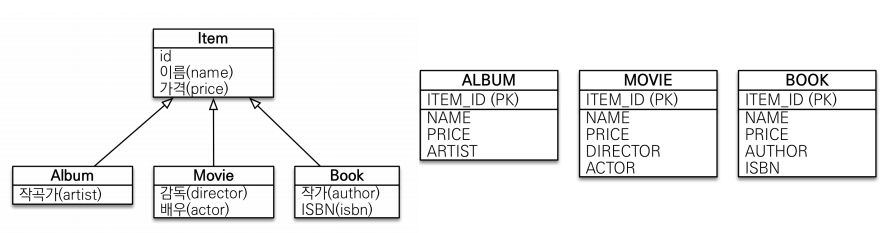
ITEM 테이블을 없애버리고 ITEM의 속성들을 다 내리는 것이다.
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)를 추가하자.
abstract가 없으면 item만으로도 사용될 수 있다는 것이므로 public abstract class Item으로 변경해주자
create table Album (
id bigint not null,
name varchar(255),
price integer not null,
artist varchar(255),
primary key (id)
)
Hibernate:
create table Book (
id bigint not null,
name varchar(255),
price integer not null,
author varchar(255),
isbn varchar(255),
primary key (id)
)
Hibernate:
create table Movie (
id bigint not null,
name varchar(255),
price integer not null,
actor varchar(255),
director varchar(255),
primary key (id)
)Item이 만들어지지 않은것을 볼 수 있다. 또한 각각의 엔티티에 공통 속성이 다 들어가있다.
/* insert hellojpa.Album
*/ insert
into
Album
(name, price, artist, id)
values
(?, ?, ?, ?)
Hibernate:
select
album0_.id as id1_2_0_,
album0_.name as name2_2_0_,
album0_.price as price3_2_0_,
album0_.artist as artist1_0_0_
from
Album album0_
where
album0_.id=?insert와 join도 각각의 테이블에 넣고 각각의 테이블에서 조회하면 된다.
여기선 @DiscriminatorColumn을 사용할 필요도 없고 넣어도 사용되지 않는다.
이 전략이 단순하게 바라봤을땐 좋아보이는데, 조회할 때 객체지향적이니 Item타입으로 조회할 상황이 생길 수도 있다.
Item item = em.find(Item.class, album.getId());와 같이 조회를 한다고 했을 때,
select
item0_.id as id1_2_0_,
item0_.name as name2_2_0_,
item0_.price as price3_2_0_,
item0_.artist as artist1_0_0_,
item0_.author as author1_1_0_,
item0_.isbn as isbn2_1_0_,
item0_.actor as actor1_3_0_,
item0_.director as director2_3_0_,
item0_.clazz_ as clazz_0_
from
( select
id,
name,
price,
artist,
null as author,
null as isbn,
null as actor,
null as director,
1 as clazz_
from
Album
union
all select
id,
name,
price,
null as artist,
author,
isbn,
null as actor,
null as director,
2 as clazz_
from
Book
union
all select
id,
name,
price,
null as artist,
null as author,
null as isbn,
actor,
director,
3 as clazz_
from
Movie
) item0_
where
item0_.id=?와 같이 모든 테이블을 다 뒤져야된다.
쓰면 안되는 전략이다.
장점
• 서브 타입을 명확하게 구분해서 처리할 때 효과적
• not null 제약조건 사용 가능
단점
• 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
• 자식 테이블을 통합해서 쿼리하기 어려움
MappedSupeclass
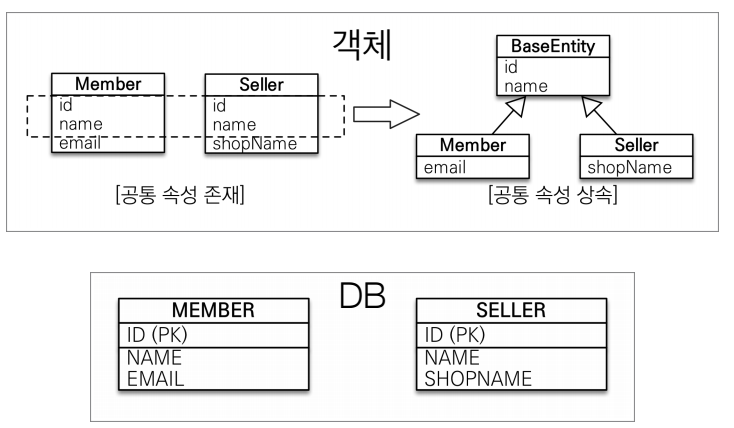
단순하게 객체 입장에서 id,name이란 필드가 계속 나오는게 귀찮을 때 부모클래스에 두고 속성만 사용하고 테이블은 따로두고 싶을 때 사용한다.
db는 완전다른데 속성만 가져다 쓰고 싶은것이다.
예를 들어
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;가 모든 테이블에 있어야한다고 가정한다면, 모든 테이블의 위의 코드들을 복붙 해야한다.
이렇게 되면 중복도 발생하는 느낌이 들고,, 개발자 입장에서 많이 귀찮다.
그래서 MappedSuperclass를 사용하는 것이다.
@MappedSuperclass
public class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}를 만들고 해당 속성(필드)를 사용하고 싶은 클래스에서 BaseEntity를 상속받으면 된다.
그럼 상속받은 클래스의 엔티티를 생성할 때 위의 속성이 자동으로 컬럼으로 들어간다.
상속 관계 매핑은 전혀 아니라는 것을 주의하자.
엔티티가 아니므로 테이블과 매핑되지 않는다. 따라서 생성된 테이블을 보면 BaseEntity 테이블은 없다.
부모 타입으로 조회가 안된다.
em.find(BaseEntity.class, ~) 사용 불가
직접 사용할 일이 없으니 추상 클래스 권장하며 설계상 이런것들은 다 추상 클래스로 만드는 것이 좋다.
테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통으로 적용하는 정보를 모을 때 사용
참고: @Entity 클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속 가능
