이제 테이블에 맞춰서 설계하는 방식이 아닌, 연관관계를 맺어서 좀 더 객체지향 스럽게 설계하는 방식을 알아보자
객체가 지향하는 패러다임과 관계형 데이터베이스의 패러다임의 차이가 있다. 객체는 참조로 탐색을 하지만, 테이블은 외래키로 탐색을 한다. 이러한 것을 어떻게 매핑해야하는지 알아보자.
연관관계가 필요한 이유
객체지향 설계의 목표는 자율적인 객체들의 협력 공동체를 만드는 것이다.
객체들은 연관관계에 다 걸려있어 그걸 활용하는 것이다.
jpa가 문제가 아니고 객체지향스럽게 설계하는게 뭔지 근본적으로 아는것이 중요하다.
예제 시나리오
회원과 팀이 있다
회원은 하나의 팀에만 소속될 수 있다.
회원과 팀은 다대일 관계다따라서 하나의 팀에 여러 회원이 소속될 수 있다.
객체를 테이블에 맞추어 모델링
(연관관계가 없는 객체)
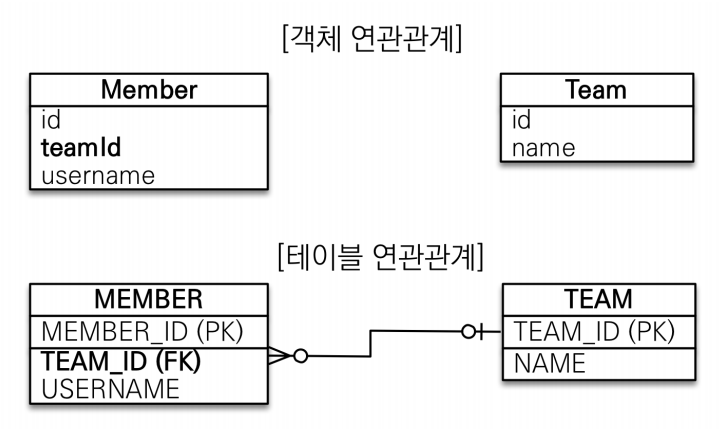
관계형 데이터베이스에선 여러 회원들이 어떤 팀에 소속되었는지 알고 싶다면 teamid를 fk로 두면 된다.
하지만 객체의 연관관계를 생각하면 외래키값을 그대로 가져오는 것은 참조가 아니므로 문제다.
Team team = new Team();
team.setName("TeamA");
em.persist(team)'
Member member = new Member();
member.setUsername("member1");
member.setTeamId(team.getId());
em.persist(member);member.setTeamId(team.getId());를 보면 이상한점이 보인다. 외래키 식별자를 직접 다루기 때문이다.
조회에도 문제가 있다.
Member findMember = em.find(Member.class, member.getId());
Long findTeamId = findMember.getTeamId();
Team findTeam = em.find(Team.class, findTeamId);객체 지향 스럽지 않은 방식임을 알 수 있다.
객체를 테이블에 맞춰 데이터 중심으로 모델링 하면 협력관계를 만들 수 없다.
테이블은 외래키로 조인을 사용해 연관테이블을 찾고 객체를 연관관계로 찾는다.
이게 패러다임의 차이이다.
단방향 연관관계
객체지향 모델링으로 객체의 연관관계를 사용해보자
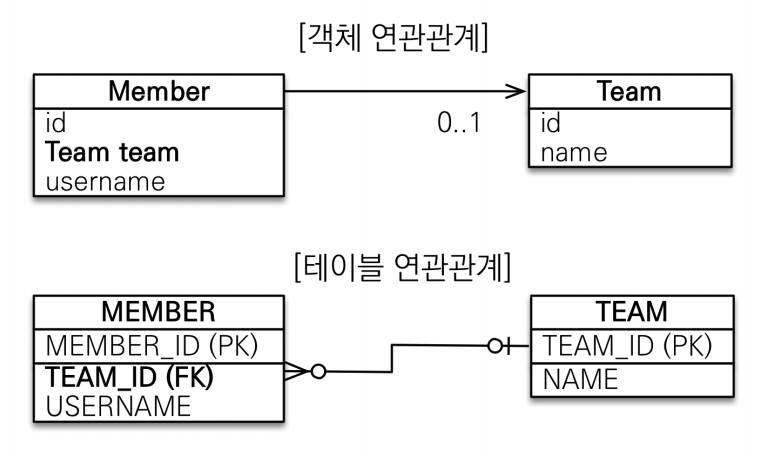
member에 team 참조값이 그대로 들어간다.
어노테이션은 데이터베이스랑 매핑하는 것이다.
public class Member{
@Id @GeneratedValue
@Column(name="MEMBER_ID")
private Long id;
@Column(name="USERNAME")
private String username;
@ManyToOne //member관점에서 생각
@JoinColumn(name="TEAM_ID") //MEMBER테이블의 TEAM_ID(FK)랑 매핑해야됨
private Team team;
}
저장해보자.
Team team = new Team();
team.setName("TeamA");
em.persist(team)'
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);
Member findMember = em.find(Member.class, member.getId());
Team findTeam=findMember.getTeam();조회도 굉장히 간편해졌다. 객체지향적으로 설계가 됐다.
위처럼 하면 persist에서 1차 캐시에 등록하기 때문에 find에서 쿼리가 나가지 않는다.
만약 쿼리가 보고 싶다면 아래와 같이 하자.
Team team = new Team();
team.setName("TeamA");
em.persist(team)'
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
Member findMember = em.find(Member.class, member.getId());
Team findTeam=findMember.getTeam();flush를 통해 db에 저장하고 clear를 통해 1차 캐시에 있는 것을 지운다.
이렇게 되면 준영속 상태가 되기 때문에 find를 하면 1차 캐시에 없으므로 db에 가서 값을 가져와 1차 캐시에 저장후 반환한다.
만약 위에서 team을 A가 아닌 B로 바꾸고 싶다면 B를 만들고 setTeam()을 통해 바꾸면 된다.
Team teamB = new Team();
temB.setName("TeamB")
em.persist(teamB)
findMember.setTeam(teamB);양방향 매핑
우리가 했던 코드에선 member에선 member.getTeam으로 갈 수 있는데 team.getMember는 안된다.
이게 되는 것이 양방향 연관관계이다.
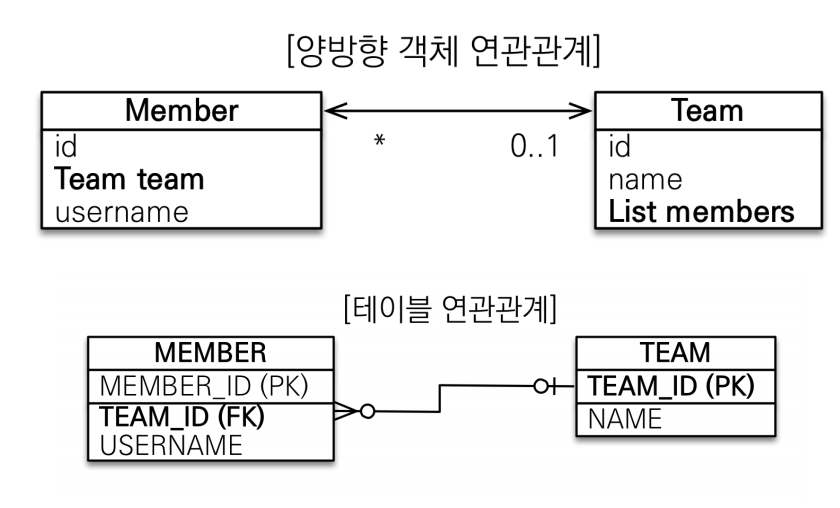
테이블은 이전의 단방향 예제와 똑같다. 객체는 양방향으로 설계해도 테이블은 바뀔 필요가 없다.
member에서 team을 알고 싶으면 team_id를 join하면 된다. 또한 team에 member들을 알고싶다면
member의fk와 join하면 된다. fk로 양방향의 모든걸 알 수 있다.
하지만 객체는 다르다. team에서 member로 갈 수 있는 방법이 없다. 그래서 team에 member를 세팅해주자
team에 리스트를 넣어주면 된다.
@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team")//일대 다 매핑에서 나는 뭐랑 연결되어있지 ? Member 에 team 나의 반대편 team과 매핑
private List<Member> members = new ArrayList<>();//NPE안뜨기 위해서 NEW
}
List<Member> members = findMember.getTeam().getMembers();
for(Member m : members) {
System.out.println("m="+m.getUsername());
}이런식으로 member에서 team을 찾아와 members를 반환하는 양방향 설계가 가능하다.
객체는 보통 단방향으로 설계하는 것이 좋다. 양방향으로 하면 신경쓸 것들이 너무 많아지기 때문이다.
mappedBy의 정체는 무엇인지 알아보자.
연관관계의 주인과 mappedBy
객체와 테이블이 관계를 맺는 차이?
객체 연관관계가 되는 포인트는 두가지이다.
회원에서 팀으로 가는 연관관계하나, 팀에서 회원으로 가는 연관관계 하나
따라서 단방향 연관관계가 두개가 있는 것이다.
이걸 억지로 우리끼리 양방향이라고 하는 것이다.
테이블에서의 연관관계는 하나다
외래키를 통한 양방향 관계가 하나 있다.
외래키를 통해 양쪽을 다 알 수 있다.
테이블의 연관관계는 fk값 하나로 모든 연관관계가 끝이나는데 객체 세상은 좀 더 어지러워서 참조가 양쪽 다 있어야한다.
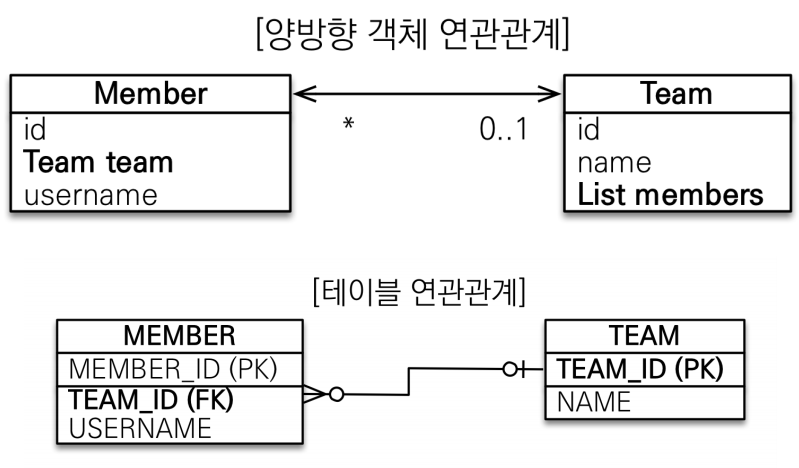
둘의 차이를 이해해야하는 게 중요하다.
따라서 객체의 양방향 관계는 단방향 연관관계를 2개 만들어야한다. 즉, 각각 참조를 만들어야한다.
테이블은 외래 키 하나로 두 테이블의 연관관계를 관리한다.
그래서 fk로 서로서로 join해서 조회가 가능하다.
Member의 team과 Team의 member 중 하나로 외래 키를 관리 해야한다.
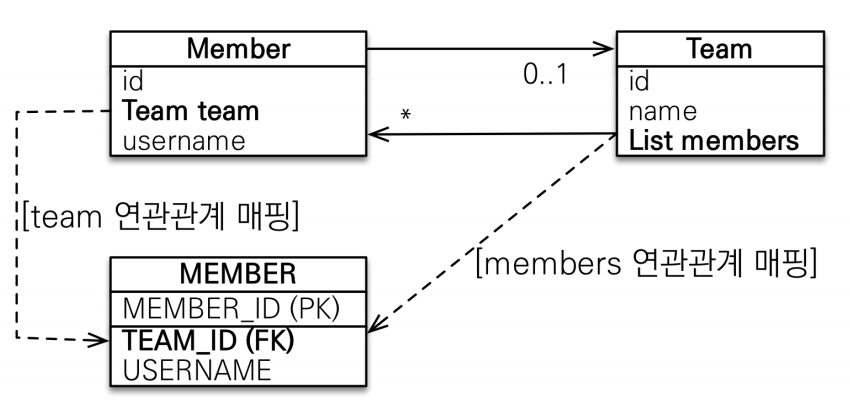
둘 중 뭐를 fk로 매핑해야 할까
team이 바뀌었을 때 fk가 바뀌어야하는가 members가 바뀌었을 때 fk가 바뀌어야하는가.
딜레마에 빠질 수 있으나 자세히 보면 뭔가 이상하다.
member가 team을 바꿀 때 member에 있는 team을 바꿔야하나, team에 있는 member가 바뀌어야하나
테이블 입장에선 fk만 바뀌면 된다.
원래는 team만 신경쓰면 되는데 양방향이되면서 members도 신경쓰게 된다.
rule -> 둘 중 하나로 외래키를 관리 해야한다.
member는 주인을 정해야한다.
연관관계의 주인
양방향 매핑에서 나오는 것임
- 객체의 두 관계 중 하나를 연관관계의 주인으로 지정한다.
- 연관관계의 주인만이 외래 키를 관리(등록, 수정)
- 주인이 아닌쪽은 읽기만 가능하다.
- 주인은 mappedBy 속성 사용하지 않는다.
- 주인이 아니면 mappedBy 속성으로 주인 지정 -> 뭐에 의해서 매핑이 되었는지 지정해줘야한다.
누구를 주인으로 할 것인가
외래키가 있는 곳을 주인으로 정하는 것이 좋다.
Member의 team을 주인으로 하고 team의 members에 mappedBy를 건다.
진짜 매핑은 team이고 읽기만 할 수 있는 가짜 매핑은 members이 된다.
이렇게 해야 헷갈리지 않는다.
다른걸 다 떠나서 members로 정할 수 있는데 뭐가 문제일까 ?
members를 주인으로 지정하면 team에 members의 값을 바꿨는데 다른 테이블에 update쿼리가 나가게 된다. 왜냐면 member테이블의 fk와 매핑되어있기 때문이다.
이거 자체가 너무 헷갈리게 되고 성능이슈도 조금 있다.
진짜 매핑은 외래키가 있는 곳에 하자 db입장에서 외래키가 있는곳이 무조건 N이고 없는 곳이 1이다. N쪽이 연관관계 주인이 된다. 연관관계의 주인이라고 하니 비즈니스 적으로 중요한것 같지만, db테이블에서 그냥 N 쪽이 주인이 되면 된다.
예시
자동차랑 자동차 바퀴를 예시로 들어보자.
비즈니스 상에선 자동차가 중요하다. 하지만 연관관계 주인은 자동차 바퀴가 될 것이다. N쪽이기 때문이다.
N쪽이 주인이 되면 외래키와 같은 테이블에서 관리가 되기 때문에 설계가 깔끔해진다.
참고
양방향 연관관계 주의
Member member = new Member();
member.setUsername("member1");
em.persist(member);
Team team = new Team();
team.setName("TeamA");
team.getMembers().add(member);
em.persist(team);team에 members에 생성한 member 추가하면 실행시 insert 쿼리가 두번 나간다.
근데, db에 가보면 member 테이블에 team_id가 null이다. 왜일까.
연관관계 주인이 member에 있는 team인데, 설정을 안해줬기 때문이다.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);그러면 이번엔 연관관계 주인에만 값을 넣고, 주인이 아닌 것은 값을 넣지 말아보자
이렇게 하면 정상적으로 값이 들어간다.
따라서 둘 다 넣으면 헷갈릴 일이 없다.
어차피 읽기 전용이어서 가짜는 업데이트할때 쓰지 않는다.
역방향에만 연관관계 설정하는걸 제일 조심해야한다.
이걸 어떻게 헷갈리지 않고 조심할 수 있을까.
양방향 매핑시 양쪽에 다 값을 넣어주면 된다.
JPA 입장에서 보면 team값만 넣어주면 되긴하다. 하지만 객체지향적으로 생각하면 양쪽에 값을 다 걸어야한다.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
Team findTeam = em.find(Team.class, team.getId());
List<Member> members = findTeam.getMembers();
for (Member m : members) {
System.out.println("m = " + m.getUsername());
}이렇게 위와 같이 team의 members엔 추가를 안해주고 member에만 team을 추가해줬다.
그리고 나서 team을 찾아 members를 조회하면 ? 다 조회가 된다.
왜냐면 jpa에서 지연로딩이라고 표현하는데, team에서 getmembers라고 호출하고 member를
jpa에서 members의 데이터를 사용하는 시점에 쿼리를 날린다. fk를 비교하고 데이터가 나옴
따라서 team에 members값을 세팅해주지 않아도 괜찮다.
근데 객체지향 스럽지 않다.
사실 문제가 있다.
위에선 flush와 clear를 했다. 근데 안했다고 가정해보자.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);까지 라고 하면 team과 member가 1차 캐시에 들어가 있을 것이다.
Team findTeam = em.find(Team.class, team.getId());
List<Member> members = findTeam.getMembers();
for (Member m : members) {
System.out.println("m = " + m.getUsername());
}1차 캐시에 있는게 바로 나온다. 그래서 member가 안들어가있다. db에서 select쿼리가 나가지 않는다.
실행해보면 아무것도 출력되지 않는다. 지금 size를 찍으면 0이 나온다.
team이 그대로 영속성 컨텍스트에 들어가있는것이다. 컬렉션에 아무것도 없는 것이다. 따라서 메모리에서 그대로 가져온것으로 순수한 객체 상태이다.
따라서 양쪽으로 다 값을 세팅해줘야된다.
members에 member넣으면 출력이 된다.
테스트케이스에서도 member.getTeam은 되는데 반대는 null이 되는 상황이 나온다.
양방향 연관관계 에선 양쪽에 값을 세팅해야한다.
순수 객체 상태를 고려해서 항상 양쪽에 값을 세팅하자
flush와 clear를 하면 db에서 다시 조회해야하기 때문에 jpa가 members를 다시 조회해야한다는 메커니즘이 동작하는데 아니면 안된다. 최악의 상황에선 버그가 발생할 수도 있다.
강사님이 추천하는 방법은 member에 setTeam을 할때 team.getMembers().add(this) 를 setTeam에 넣어 실수를 방지하는 것이다.
member에 team을 세팅하는 시점에 members에도 값이 들어가기 때문에 실수를 방지할 수 있다.
로직이 들어가게 되면 단순히 setter가 아닌 이름을 바꿔 안에 로직이 있음을 알게 하는 것이 좋다.
예시로 setTeam -> changTeam
연관관계 편의메서드는 양쪽에 있을 경우 문제가 생길 수 있음을 주의하자.
team.addMember(member)
...
team클래스
public void addMember(Member member){
member.setTeam(this);
members.add(member);
}연관관계 편의 메서드는 어디 들어가든 상관없는데, 어디가 맞는지는 상황마다 좀 다르다 그래서 상황을 보고 정하자
양방향 매핑시에 무한루프 조심해야한다.
Member에 toString을 생성한다고 생각해보자.
@Override
public String toString() {
return "Member{" +
"id=" + id +
", username='" + username + '\'' +
", team=" + team +
'}';
}위와 같이 될 것이다.
그럼 이때 team은 team.toString을 불러온다. 그럼 team의 toString을 보자
@Override
public String toString() {
return "Team{" +
"id=" + id +
", name='" + name + '\'' +
", members=" + members +
'}';
}위와 같이 members를 불러온다. 무한루프에 빠지게 되는것이다.
members는 members안에 member들의 toString을 다 찍는다.
JSON 생성 라이브러리 같은데도 주의해야한다.
엔티티를 직접 컨트롤러에서 RESPONSE로 직접보내는데 양방향으로 되어있으면, 컨트롤러에서 엔티티를 반환할때 MEMBER면 TEAM이 있고, TEAM엔 MEMBERS가 있으므로 무한 루프를 돌게 된다.
LOMBOK에서 TOSTRING 쓰지않는게 좋다.
JSON에서는 컨트롤러에는 엔티티를 반환하지 말것, 문제가 생김 무한루프,
엔티티를 API에 반환해버리면 나중에 그 엔티티를 변경하는 순간 API스펙이 바뀌는 것이다.
엔티티 (DTO)로 변환해서 반환하는 것을 추천한다.
양방향 매핑 정리
단방향 매핑만으로도 연관관계 매핑은 이미 완료가 된 것이다.
JPA 모델링 할 때 단방향 매핑으로 설계를 끝내야한다.
테이블 설계를 하면서 객체 설계를 같이하면 FK가 다 나온다. 그럼 단방향 매핑을 다 건다.
이때 양방향으로 설계하지말고 처음엔 단방향으로 설계를 끝내고 나서 조회기능이 추가될 때 반대방향으로 매핑을 걸어 양방향 매핑을 해주자.
객체 입장에서 양방향으로 설계 되어봤자 좋을 게 없다.
양방향 매핑은 언제 ? JPQL로 역방향 탐색할 일이 많다. 이때 많이 사용한다.
단방향 매핑을 잘해두면 양방향은 필요할 때 코드 몇줄로 추가만 하면된다.
실제 우리가 예제에서 한 테이블도 단방향 연관관계와 양방향 연관관계에서의 테이블이 바뀌지 않고 그대로 이다.
비즈니스 로직을 기준으로 연관관계의 주인을 선택하면 안된다. 할 순 있는데 그게 중요한게 아니기 때문에 연관관계 주인은 외래 키의 위치를 기준으로 정해야된다.
이러면 헷갈릴게 하나도 없다.
그래도 객체 지향적으로 볼 때 team쪽에 넣고 싶다. 라고 하면 연관관계 편의메서드를 만들면된다.
참고
