4 IP 주소
1.개요
인터넷에 연결된 각 장치를 구별하기 위해 TCP/IP 프로토콜 모음의 IP 계층에서 사용하는 식별자를 인터넷 주소(Internet address) 또는 IP 주소(IP address)라고 한다. IPv4주소는 32비트 주소로서 인터넷에 있는 호스트나 라우터의 연결을 전 세계적으로 유일하게 나타낸다. IP 주소는 인터페이스의 주소이다. IP 주소는 유일하다.
1.1 주소 공간
주소를 지정하는 IPv4 프로토콜은 주소 공간(address space)을 가지고 있다. 주소 공간은 프로토콜에서 사용되는 주소의 총 개수이다. 프로토콜이 주소를 나타내기 위해 b비트를 사용한다면, 각 비트는 0 또는 1의 값을 가질 수 있으므로 주소 공간은 2**b이다.
1.2 표기법
IP 주소를 나타내는데 사용되는 세 가징 일반적인 표기법을 살펴보자. 2진 표기법, 점 10진 표기법, 16진 표기법이 있다. 가장 많이 사용되는 방법은 기수(base) 256표기법이다.
- 2진 표기법: 기수 2
2진 표기법(binary notation)에서 IPv4 주소는 32비트로 나타낸다. 주소를 보다 읽기 쉽도록 각 옥텟(8비트) 사이에 하나 이상의 공백을 둔다. 각 옥텟은 바이트(byte)라고도 한다. 따라서 보통 IP 주소를 32비트 주소, 4옥텟 주소, 또는 4바이트 주소로 부른다. 다음은 2진 표기법으로 표기한 IPv4 주소의 예를 보여주고 있다.

- 점 10진 표기법: 기수 256
IPv4 주소를 보다 간결하고 읽기 쉽게 하려고 IPv4 주소를 보통 바이트를 구분하는 소수점(점)을 이용하여 10진 형식으로 표기한다. 이 형식은 점 10진 표기법(dotted-decimal notation)이라고 불린다. 다음 그림은 IP주소를 점 10진 표기법으로 나타내고 있다. 각 바이트(octet)는 8비트이므로, 점 10진 표기법에서 표현되는 각 숫자는 0과 155 사이의 값을 갖는다.

- 16진 표기법: 기수 16
IPv4 주소를 가끔 16진 표기법(hexadecimal notation)으로 표현할 수가 있다. 각 16진수 숫자는 4비트에 해당한다. 이것은 32비트 주소는 8개의 16진 숫자로 구성된다는 것을 의미한다. 16진 표기법은 주로 네트워크 프로그래밍에서 사용되고 있다.

1.3 주소의 범위
경우에 따라 한 개의 주소 대신에 주소의 범위를 다루는 것이 필요할 때가 있다. 처음 주소와 마지막 주소를 알면, 이 범위 내 주소의 개수를 찾는 것이 필요하다.

1.4 연산
간혹 2진법이나 점 10진법을 사용하여 32비트 수에 대해 연산을 수행하는 경우가 있다. 이러한 수는 IPv4 주소나(이후에 설명될 마스크와 같이) IPv4 주소와 연관된 수를 나타낸다. 이 절에서는 NOT, AND, OR 연산을 소개한다.
- 비트 단위의 NOT 연산
비트 단위의 NOT 연산은 일한 연산(unary operation)으로 한 개의 입력을 받는다. 수에 NOT 연산을 취하면 그 수에 대한 보수를 계산하는 것이다. 2진법으로 표시된 32비트 수에 NOT 연산을 적용하면 각 비트의 역이 취해진다. 다음 그림은 NOT 연산을 보여준다.
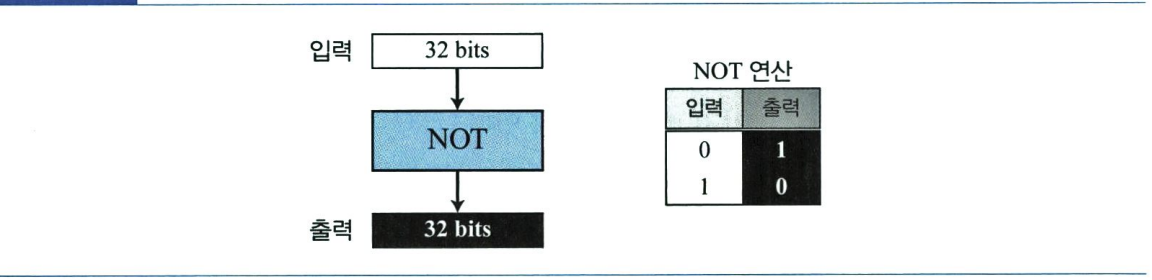
32비트 수에 NOT 연산을 직접 사용할 수 있지만, 수가 4바이트 점 10진법으로 표기되어 있다면 더 빠른 방법이 있다. 이는 각 바이트를 255에서 빼는 것이다.

- 비트 단위 AND 연산
비트 단위 AND 연산은 이항 연산(binary operation)으로 두 개의 입력을 취한다. AND 연산은 두 개의 입력에서 해당하는 두 비트를 서로 비교하여 둘 중에서 작은 비트 값을 취한다. 두 비트의 값이 같은 경우 둘 중 하나의 값을 취한다. 다음 그림은 AND 연산을 보여준다.
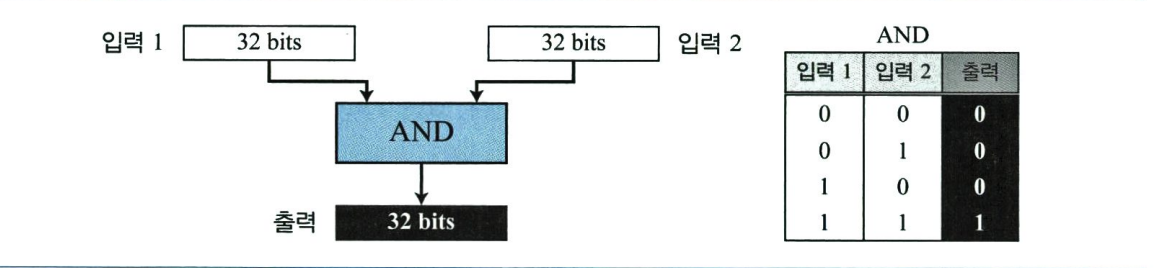
2진법으로 표기된 두 개의 32비트 수에 AND 연산을 직접 사용할 수 있지만 숫자들이 10진법으로 표기된 경우 두 가지 빠른 방법이 있다.
- 수중에서 적어도 하나가 0 또는 255이면 AND연산은 작은 바이트 값을 취한다. 만약 같은 경우 둘 중의 하나를 취한다.
- 두 바이트가 0도 아니고 255도 아니면 각 바이트를 (각 항이 2의 거듭제곱인) 8항의 합으로 쓸 수 있다. 각 쌍 중에서 작은 항을 취하고(같은 경우 둘 중의 하나를 취하고) 결과를 구하기 위하여 모두를 더한다.

즉, 둘 중 작은것을 취하고 같다면 둘중 아무거나 쓰면 된다.
- 비트안위 OR 연산
비트 단위 OR 연산은 이항 연산으로 두 개의 입력을 취한다. OR 연산은 두 수에 해당하는 비트들을 비교하여 둘 중에서 큰 값을 취한다. 같은 경우에 둘 중의 하나를 취한다. 다음 그림은 OR연산을 보여준다.
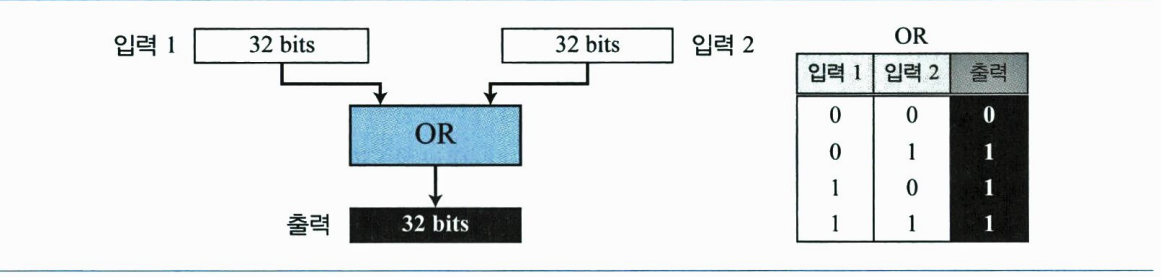
다음 그림은 2진법이나 점 10진법에 적용하는 방법을 보여준다.

2. 클래스 기반 주소지정
처음부터 IP 주소는 클래스(class) 개념을 사용하였다. 이러한 구조를 클래스 기반 주소 지정(classful addressing)이라 부른다. 1990년대 중반에 새로운 구조가 등장하였는데, 이를 클래스 없는 주소지정(classless addressing)이라고 하며, 원래의 구조를 대체할 것으로 소개되었다.
2.1 클래스
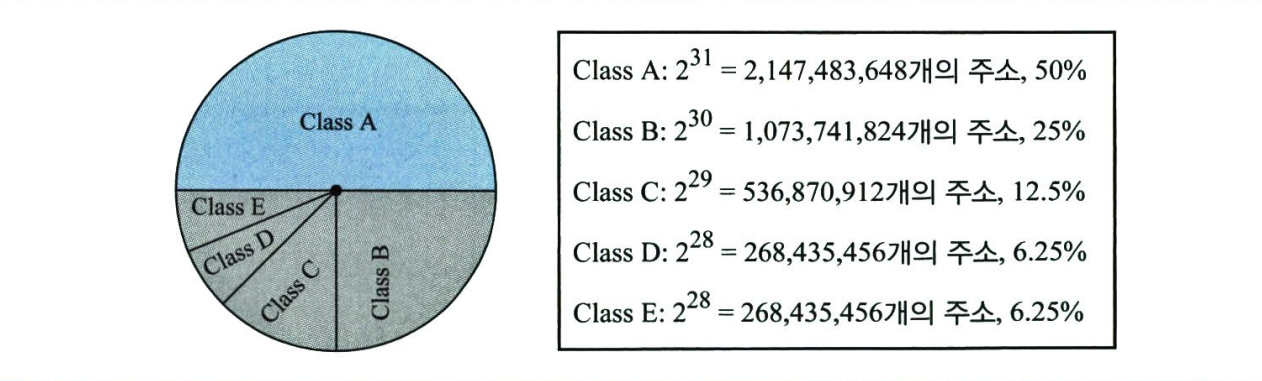
클래스 기반 주소지정에서 IP 주소 공간은 다섯 개의 클래스(A, B, C, D, E)로 나누어진다. 각 클래스는 전체 주소 공간의 일부분을 차지한다. 다음 그림은 주소 공간에 대한 각 클래스의 점유율을 보여준다.
- 클래스 찾기
주소가 2진 표기법, 또는 점 10진 표기법으로 주어졌을 때, 주소의 클래스를 알 수 있다. 다음 그림을 참조하라
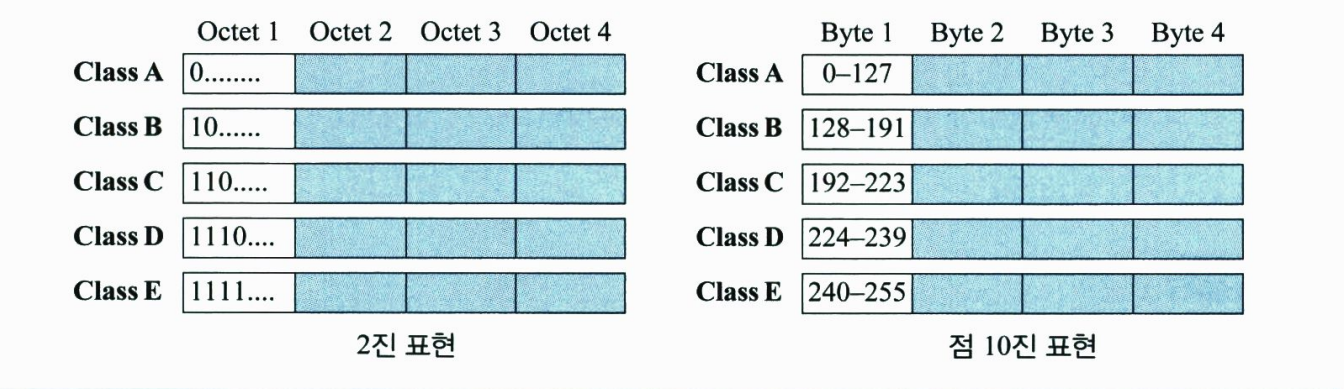
A나 E 클래스에는 특수 주소가 존재한다. 특수 주소는 클래스 분류에서 예외 주소로서 이 장의 후반부에 논한다.
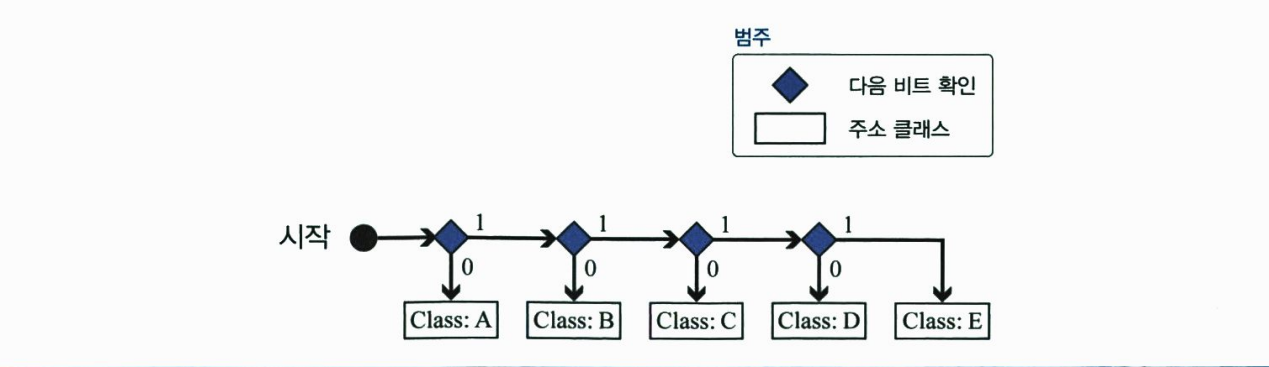
컴퓨터는 종종 IPv4 주소를 2진법 표기를 사용하여 저장한다. 이 경우 다음 그림과 같이 주소를 찾기 위해 연속적인 확인 절차에 기반한 알고리즘을 사용하는 것이 편리하다.


- Netid 와 Hostid
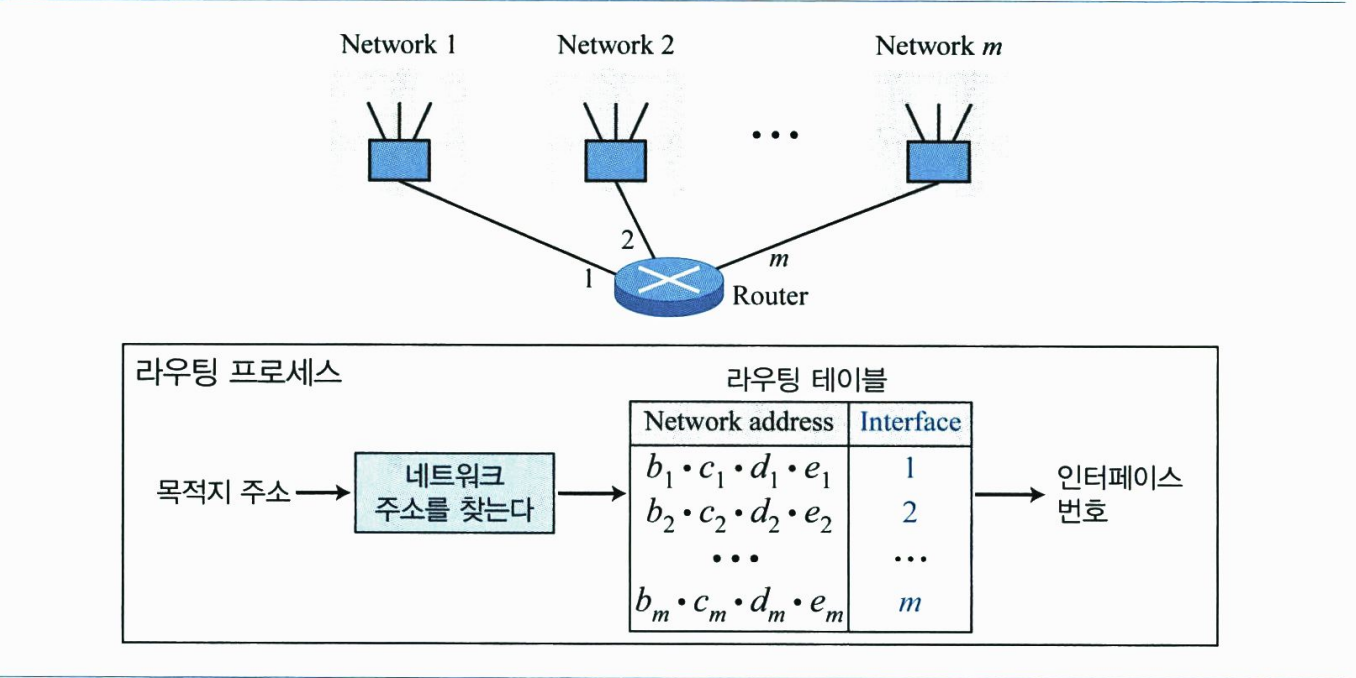
클래스 기반 주소지정에서 클래스 A, B, C의 IP 주소는 네트워크를 구분하는 netid와 호스트를 구분하는 hostid로 나누어진다. 각 부분은 주소의 클래스에 따라 길이가 서로 다르다. 다음 그림은 netid와 hostid의 바이트를 보여주고 있다. 클래스 D와 E는 netid와 hostid로 나누어지지 않으며, 이에 대한 설명은 뒤에서 살펴본다.
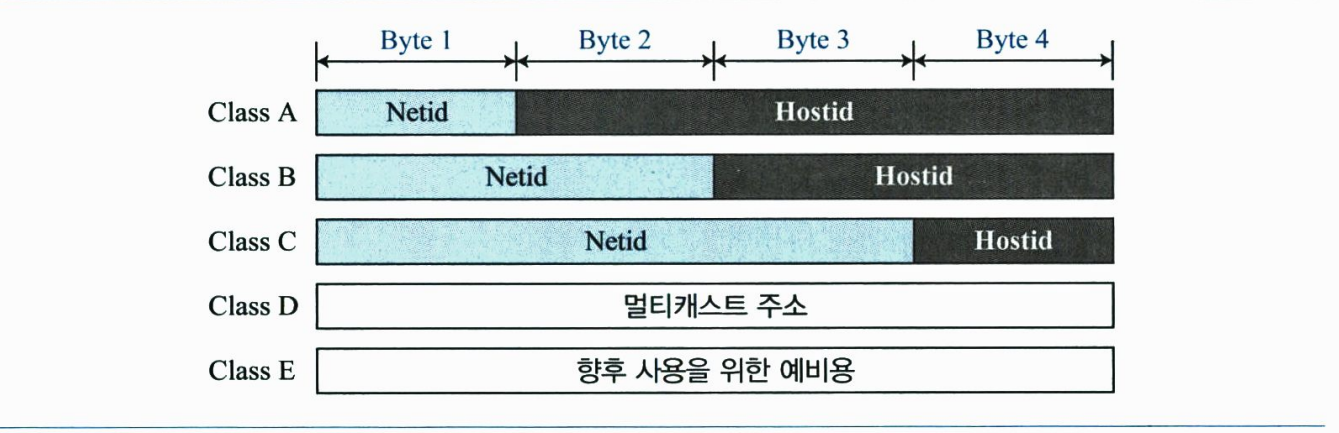
클래스 A는 1바이트의 netid와 3비트의 hostid를 갖는다. 클래스 B는 2바이트의 netid와 2바이트의 hostid를 갖는다. 클래스 C의 경우, netid가 3바이트이고, hostid는 1바이트로 나타낸다.
2.2 클래스와 블록
클래스 기반 주소지정에서 발생하는 한 가지 문제점은 각 클래스가 정해진 수의 블록(block)으로 나뉘고 각 블록의 크기는 고정되어 있다는 것이다. 각 클래스에 대해 살펴보자
- A클래스
클래스 A에서는 1바이만 netid를 정의하고 가장 왼쪽 비트는 0이 되어야 하므로 다음 7비트는 이 클래스 내의 블록 수를 찾는데 사용된다. 그러므로 클래스 A는 2**7 = 128 개의 블록으로 나누어지고 이 블록은 128개의 기관에 할당될 수 있다. 그리고, 클래스 A의 각 블록은 16,777,216개의 주소를 가질 수 있으며, 이는 모든 주소를 사용하기 위해 기관 규모가 매우 커야 한다는 것을 의미한다. 이 클래스에서 많은 주소가 소진되었다. 아래 그림은 클래스 A의 블록들을 보여주고 있다.

- 클래스B
클래스 B의 두 바이트가 클래스를 나타내고 가장 왼쪽의 두 비트는 10이므로 다음 14비트는 이 클래스의 블록수를 찾는 데 사용된다. 그러므로 클래스 B는 2**14 = 16,384 블록으로 나누어지고 16,384 기관에 할당할 수 있다. 이 클래스의 각 블록은 65,536개의 주소를 포함하는데 이렇게 많은 주소를 사용할 수 있는 기관은 많지 않다. 다음 그림은 클래스 B의 블록들을 보여준다.

- 클래스 C
클래스 C의 세 바이트가 클래스를 나타내고 가장 왼쪽의 세 비트는 110 이므로 다음 21비트는 이 클래스 내의 블록 수를 찾는데 사용된다. 그러므로 클래스 C는 2**21 = 2,097,152 블록으로 나누어지고 256개의 주소를 포함하는 블록들은 2,097,152개의 기관에 할당될 수 있다. 다음 그림은 클래스C의 블록들을 보여준다.

- 클래스 D
클래스 D 주소는 단지 한 블록이다. 따라서 클래스 D는 이후에 살펴볼 멀티캐스팅을 위해 설계되었다. 클래스 D의 각 주소는 인터넷상에서 호스트들의 한 그룹을 정의하는데 사용된다. 그룹에 클래서 D의 주소가 할당되면, 이 그룹의 멤버인 모든 호스트는 정상적인 주소(유니캐스트)에 추가적으로 멀티캐스트 주소를 갖게 되는 것이다.

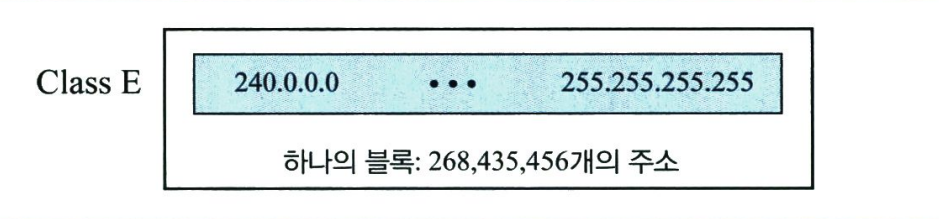
- 클래스 E
클래스 E 주소도 단 하나의 블록을 갖는다. 다음 그림과 같이 클래스 E는 예약된 주소로 사용하기 위해 설계되었다.
2.3 2계층 주소지정
IPv4 주소지정의 목적은 인터넷 패킷을 위한(네트워크층의) 목적지를 지정하는 것이다. 클래스 기반 주소지정이 처음 설계되었을 때 전체 인터넷은 많은 네트워크로 나누어지고 각 네트워크에는 많은 호스트가 연결되는 것으로 가정하였다. 즉, 인터넷은 네트워크들의 네트워크로 간주되었다. 네트워크는 인터넷에 연결하기 위해 원하는 조직에 의해 생성되는 것이 정상적이었다.
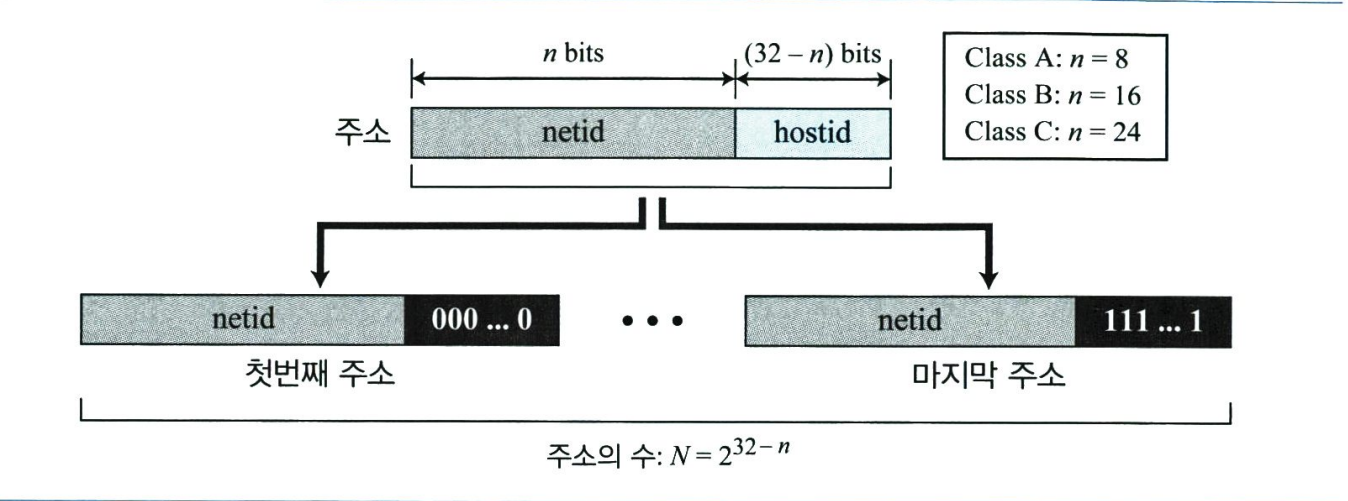
네트워크 내의 모든 주소는 한 블록에 속하므로 클래스 기반 주소지정에서는 각 주소는 netid와 hostid 부분을 포함한다. Netid는 네트워크를 정의하고 hostid는 네트워크에 연결된 특정 호스트를 정의한다. 다음 그림은 클래스 기반 주소지정에서 IPv4 주소를 보여준다. 클래스 내의 n 비트가 네트워크를 정의하면 32-n 비트는 호스트를 정의한다. 그러나 n의 값은 블록이 속한 클래스에 따른다. n의 값은 클래스가 A,B,C인가에 따라 각각 8, 16 또는 24가 될 수 있다.

- 블록에서 정보 추출하기
블록은 주소의 범위이다. 블록 내의 주소가 주어지면 블록에 속한 주소의 수, 처음과 마지막 주소를 알아야 한다. 이 정보를 알아내기전에 주소의 클래스를 알아야 한다. 블록의 클래스를 찾으면 netid의 비트 수인 n값을 알 수 있다. 즉 다음 그림과 같이 세 가지 정보를 알 수 있다.
- 블록 내의 주소의 수 N은 N= 2**(32-n)이다.
- 처음 주소는 왼쪽의 n비트를 유지하고 오른쪽의(32-n)비트를 0으로 함으로써 구할 수 있다.
- 마지막 주소는 외쪽의 n비트를 유지하고 오른쪽의 (32-n) 비트를 1로 함으로써 구할 수 있다.
-
네트워크 주소
앞의 두 예제에서 주소가 주어지면 블록에 대한 정보를 찾을 수 있음을 알 수 있다. 네트워크 주소(Network Address)인 첫 주소는 목지 주소로 패킷을 전송하는 데 사용되므로 매우 중요하다. 네트워크 주소는 실제로 네트워크의 식별자이다. 각 테으워크는 네트워크 주소에 의해 식별된다.
-
네트워크 마스크
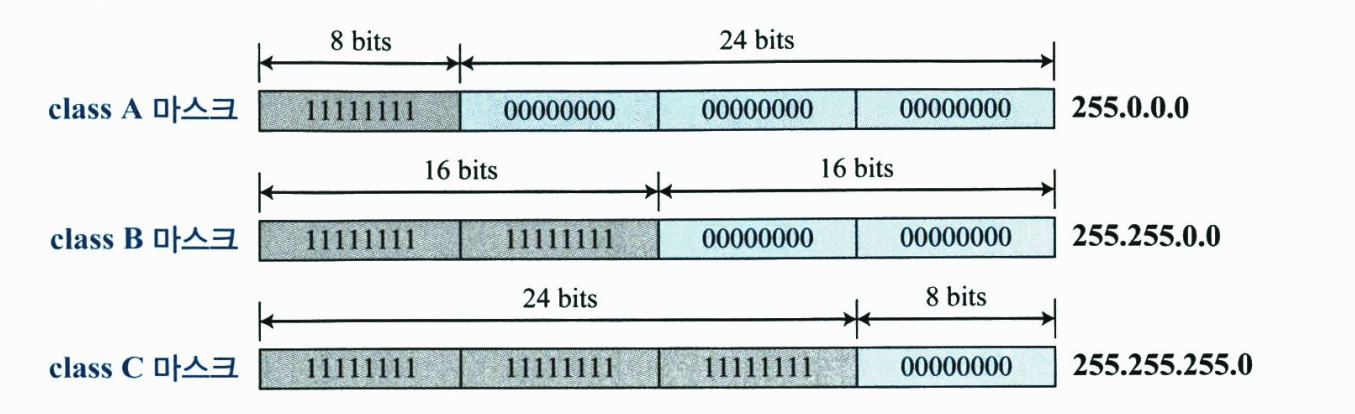
네트워크 주소를 추출하기 위하여 앞에서 설명한 방법은 개념을 설명하기 위한 것이었다. 인터넷 내의 라우터는 패킷의 목적지 주소에서 네트워크 주소를 추출하기 위하여 보통 알고리즘을 사용한다. 이를 위하여 네트워크 마스크를 사용한다. 클래스 기반 주소지정에서 네트워크 마스크(network mask) 또는 디폴트 마스크(default mask)는 n개의 왼쪽 비트는 1이고 (32-n)개의 오른쪽 비트는 0인 32비트 수이다. 클래스 기반 주소지정에소 n값은 클래스에 따라 다르므로 아래 그림과 같이 세 개의 디폴트 마스크가 있다.
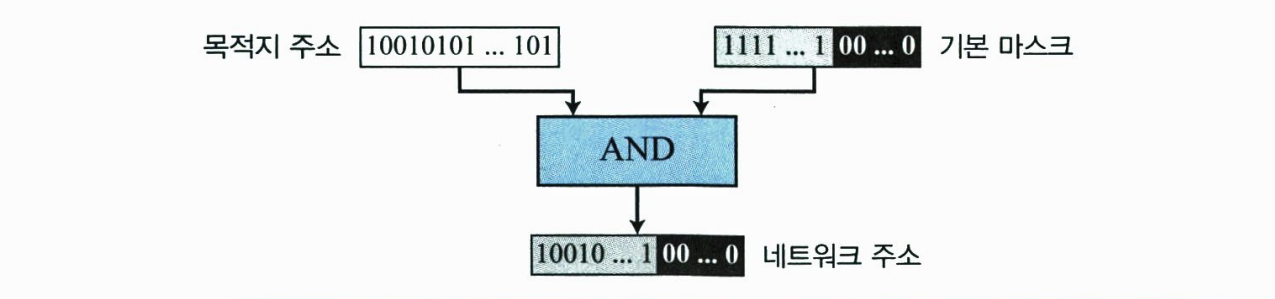
패킷의 목적지 주소에서 네트워크 주소를 추출하기 위해 AND 연산을 사용한다. 목적지 주소가 디폴트 마스크와 AND 연산을 하면 결과가 아래 그림과 같이 네트워크 주소가 된다.

2.4 3계층 주소지정: 서브넷팅
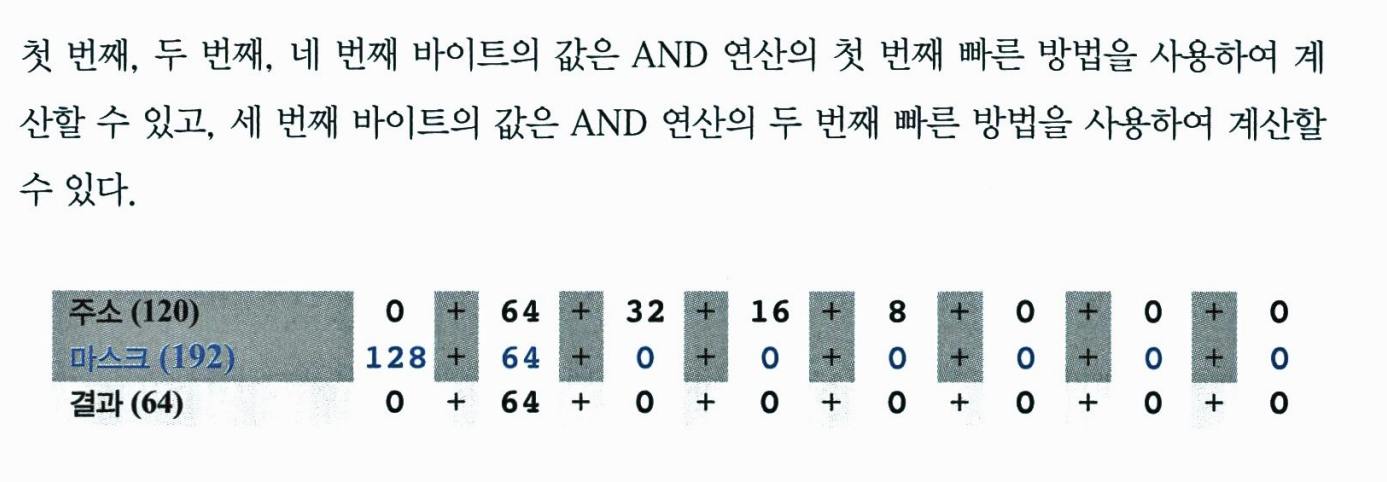
앞에서 설명한 바와 같이 IP 주소지정은 2계층 주소지정으로 설계 되었다. 인터넷 내의 호스트에 도달하기위해 먼저 네트워크에 도달해야하고, 그 다음에 호스트에 도달해야한다. 다음의 두 가지 이유로 인해 두 계층보다 많은 계층이 필요함을 알게 되었다. 첫 번째로 A,B 클래스는 보안과 관리를 위해 네트워클 몇개의 서브네트워크로 나눌 필요가 있었다. 두 번째로 C블록은 대부분의 조직이 필요로 하는 크기보다 작으므로 클래스 A,B가 자신들의 블록을 더 작은 블록으로 나누어 C에게 공유하였다. 블록을 작은 블록으로 나누는 개념을 서브넷팅(Subnetting)이라고 부른다. 서브넷팅에서 네트워크는 몇 개의 작은 서브네트워크로 나뉘고 각 서브네트워크는 자신의 서브네트워크 주소를 가진다.
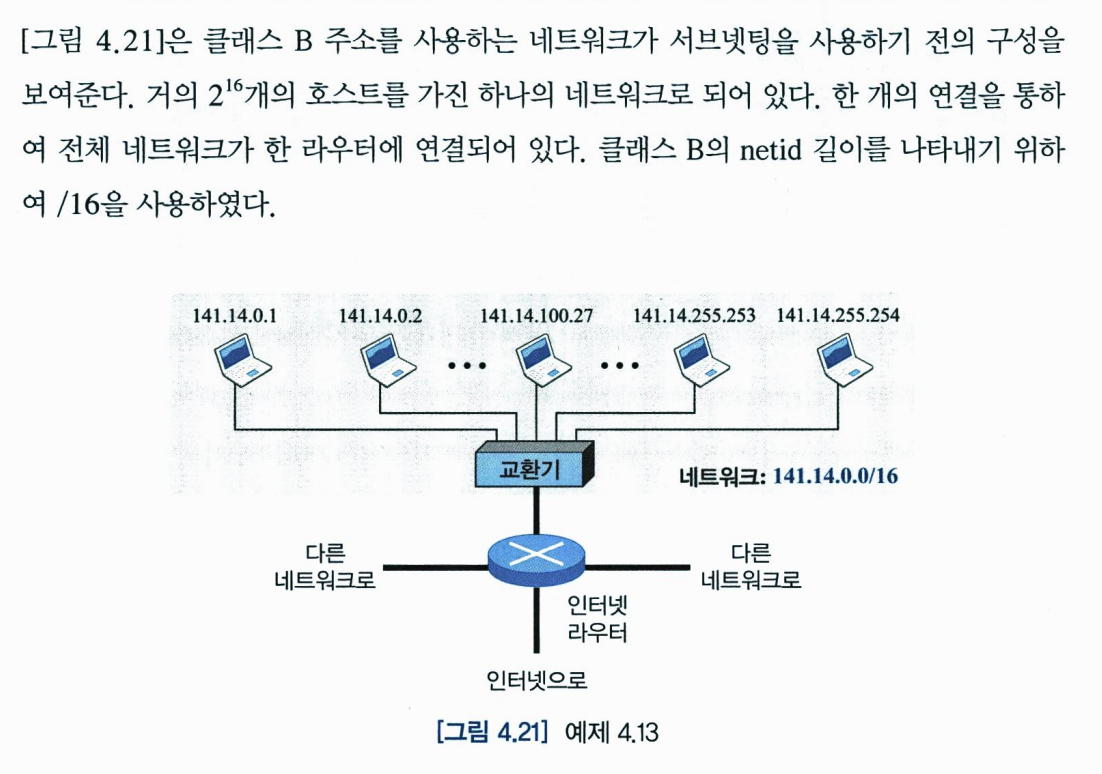
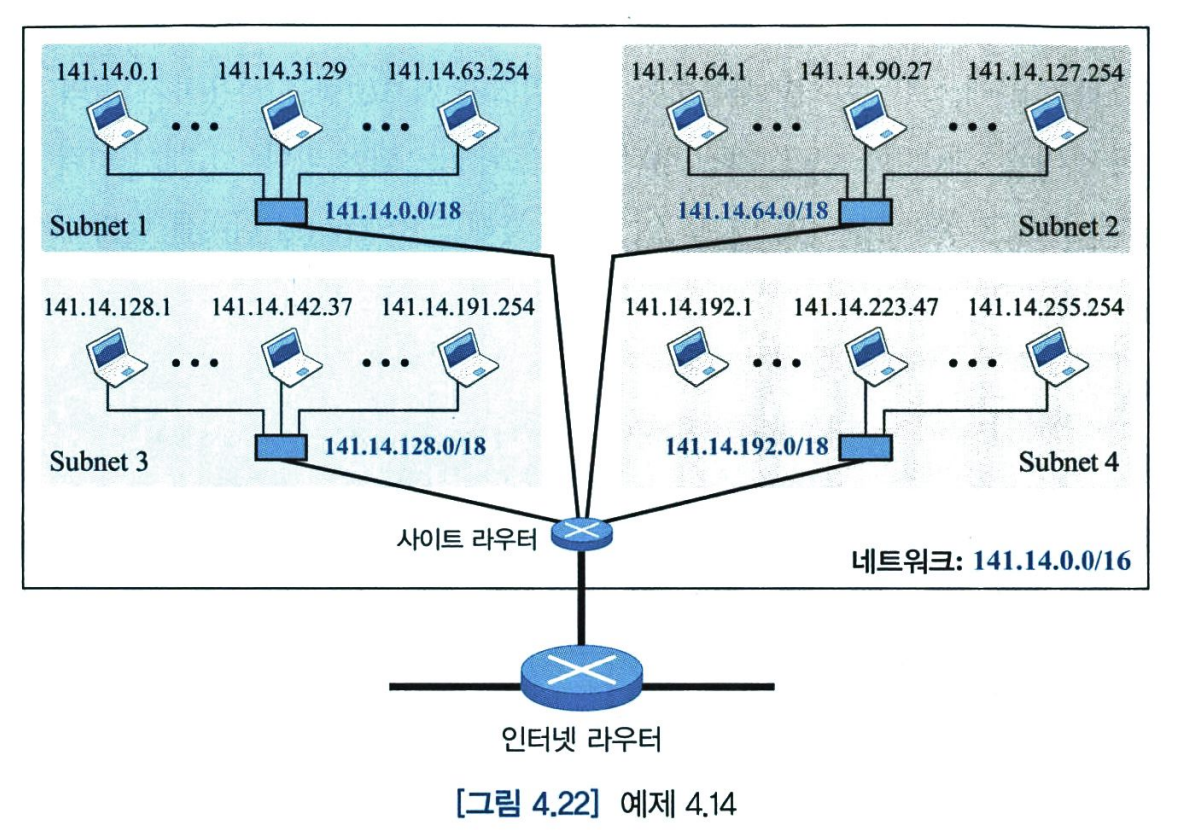
아래 그림은 위 네트워크로 서브넷팅을 구성한 예를 보여준다. 전체 네트워크는 같은 라우터를 통하여 인터넷에 연결된다. 그러나 아래 네트워크는 별도의 라우터를 사용하여 네트워크를 네 개의 서브넷으로 나누었다. 인터넷에서는 한 개의 네트워크로 보이지만 내부적으로는 네 개의 서브넷으로 구성되어있다. B클래스 이고 4개의 서브넷으로 나누므로 각 서브넷은 2**14개의 호스트를 가질 수 있다. 네트워크는 네 개의 서로 다른 학부(건물)를 가진 대한 캡퍼스에 속할 수 있다. 서브넷팅 후에 각 학부는 자신의 서브넷을 가지나 외부 네트워크에서는 전체 네트워크가 하나의 네트워크로 보인다. /16과 /18은 netid와 subnetid의 길이이다.
- 서브넷 마스크
앞에서 네트워크 마스크(디폴트 마스크)에 대해 설명하였다. 네트워크 마스크는 네트워크가 서브넷팅되지 않은 경우 사용한다. 네트워크를 몇 개의 서브넷으로 나눌 경우 각 서브넷에 대해 서브넷 마스크(subnet mask)를 생성할 필요가 있다. 아래 그림과 같이 서브넷은 subnetid와 hostid를 가진다.
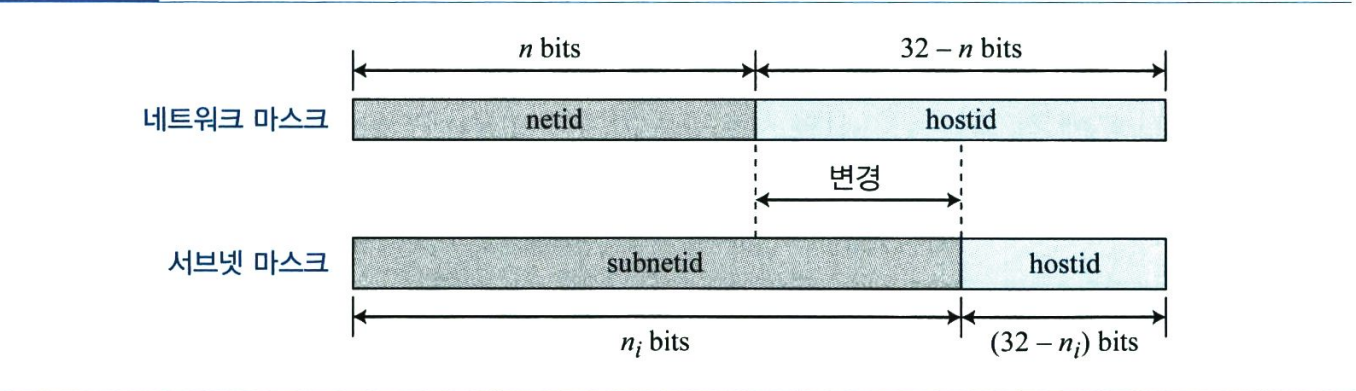
서브넷팅은 netid의 길이는 증가시키고 hostid의 길이는 감소시킨다. 네트워크를 같은 수의 호스트를 가지는 s개의 서브넷으로 나누면 다음과 같이 각 서브넷의 subnetid를 구할 수 있다.
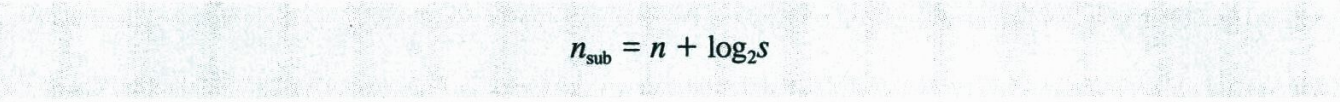
여기서 n은 netid의 길이이고 n(sub)는 각 subnetid의 길이이며, s는 2의 거듭제곰인 서브넷의 개수이다.

- 서브넷 주소
네트워크가 서브넷 된 경우 서브넷의 첫 주소는 서브넷의 식별자이고 라우터가 해당하는 서브넷으로 가는 패킷에 대해 경로를 지정하는 데 사용한다. 서브넷 내의 한 주소가 주어지면 네트워크 주소를 찾을 때와 같은 방법을 사용하여 서브넷 주소를 찾을 수 있다. 즉, 주어진 주소와 서브넷 마스크를 AND 연산 한다.

2.5 슈퍼넷팅
대부분 기관은 할당받은 블록을 다른 조직과 공유하지 않으므로 서브넷팅은 클래스 기반 주소지정에서 생기는 주소 고갈 문제를 완전히 해결할 수 없다. 클래스C가 블록은 남아있지만 클래스 C블록의 크기는 인터넷에 연결하기 원하는 기관의 요구사항을 만족하기에는 충분히 크지 않으므로 슈퍼넷팅(Supernetting)이라는 해결책이 도입되었다. 슈퍼넷팅을 사용함으로써, 기관은 큰 범위의 주소를 생성하기 위해 몇 개의 클래스 C블록을 신청할 수 있다. 예를 들어, 1000개의 주소가 필요한 기관은 4개의 클래스C 블록을 부여받을 수 있다.
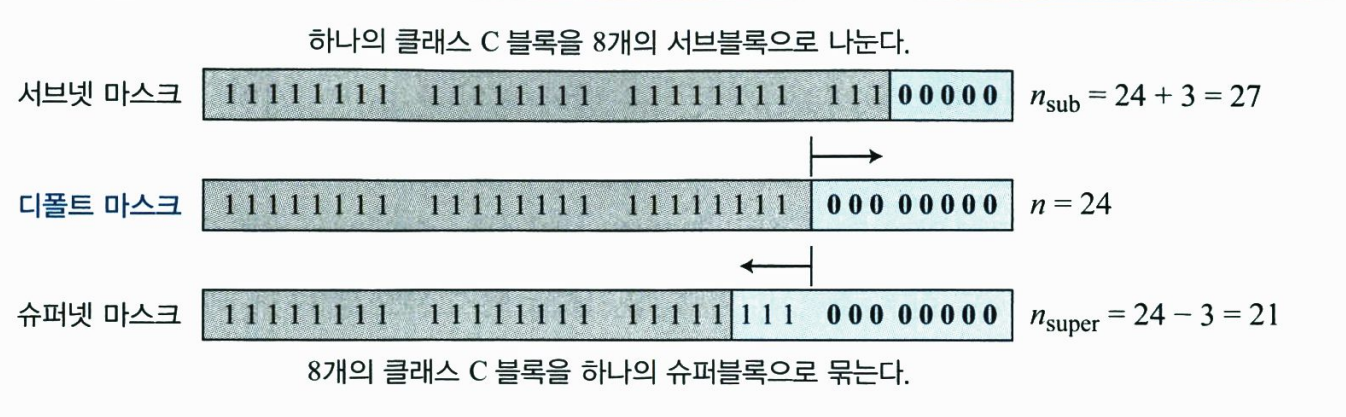
- 슈퍼넷 마스크
슈퍼넷 마스크(supernet mask)는 서브넷 마스크의 반대이다. 클래스 C에서 서브넷 마스크느는 이 클래스의 디폴트 마스크보다 1의 개수가 더 많다. 클래스 C의 슈퍼넷 마스크는 이 클래스의 디폴트 마스크보다 1의 개수가 더 적다.
아래 그림은 서브넷 마스크와 슈퍼넷 마스크의 차이점을 보여준다.
슈퍼넷팅에서 한 개의 슈퍼넷으로 결합될 수 있는 클래츠 C의 주소의 개수는 2의 거듭제곱이어야 한다. Superneid의 길이는 다음 공식에 의해 찾을 수 있다.
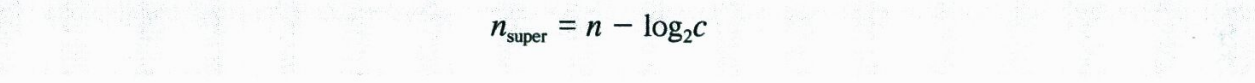
여기서 n(super)는 supernetid의 길이이고, c는 결합된 클래스 C 블록의 개수이다.
그렇지만 슈퍼넷팅은 두 가지 새로운 문제를 발생시킨다. 첫째로 결합될 수 있는 블록의 수는 2의 거듭제곱이므로, 주소의 낭비가 발생한다. 두 번재로 슈퍼넷팅과 서브넷팅은 인터넷 내에서 패킷라우팅을 더우 복잡하게만든다.
3.클래스 없는 주소지정
클래스 기반 주소지정 문제를 해결하기 위한 단기적인 해결책이다. IPv6가 개발되기 전 단기적인 해결책이다.
3.1 가변 길이 블록
클래스 없는 주소지정 방식에서 전체 주소 공간은 가변 길이 블록으로 나누어진다. 단, 블록에 포함되는 주소의 개수는 2의 거듭제곰(power)이 되어야 한다는 제약 조건이 있다. 한 기관은 하나의 주소 블록을 할당받을 수 있다. 아래 그림은 전체의 주소 공간이 어떻게 겹치지 않고 여러 개의 블록으로 나누어지는지를 보여준다.

3.2 2단계 주소 체계
클래스 기반 주소지정 방식과 동일한 개념이 클래스 없는 주소지정 방식에도 적용될 수 있다. 기관에는 하나의 주소 블록이 할당될 수 있으며, 블록은 프리픽스(prefix)와 서픽스(suffix)로 나누어진다. 프리픽스는 netid와 같은 기능을, 서픽스는 hostid와 같은 기능을 담당한다. 블록 내에 있는 모든 주소는 같은 프리픽스를 가지며, 각 주소는 서로 다른 서픽스를 가진다. 아래 그림은 클래스 없는 블록의 프리픽스와 서픽스를 보여준다.

클래스 기반 주소지정 방식에서, netid 길이인 n은 주소의 클래스에 따라 다르며, 8 16, 또는 24 중 하나의 값을 가진다. 클래스 없는 주소지정 방식에서 프리픽스 길이인 n은 브록긩 크기에 따라 다르며 0, 1, 2, 3,......., 32 중에서 하나의 값이 될 수 있다. 클래스 없는 주소지정 방식에서 n의 값은 프리픽스 길이를 나타내며, 32-n의 값은 서픽스 길이를 나타낸다.

- 슬래시(/) 표기법
클래스 기반 주소지정 방식에서 정의되는 netid 길이 또는 클래스 없는 주소지정 방식에서 정의되는 프리픽스 길이는 블록에 속하는 주소에서 블록에 대한 정보를 추출하기 위한 중요한 역할을 한다. 그렇지만 클래스 기반 방식과 클래서 없는 방식은 다음과 같은 차이점이 있다.
- 클래긋 기반 주소지정 방식에서 netid 길이는 주소 자체로부터 얻어질 수 있다. 주소가 주어지면 주소의 클래스가 정해지며, 따라서 netid 길이(즉, 8, 16, 24)도 알 수 있다.
- 클래스 없는 주소지정 방식에서는 블록 내의 주소만 가지고는 프리픽스 길이를 알 수 없다. 주소는 임의의 프리픽스 길이를 갖는 블록에 속한다.
클래스 없는 주소지정 방식에서 주소의 블록을 알기 위해서는 프리픽스 길이 정보가 주소 정보에 포함되어야한다. 이 경우에는 프리픽스 길이인 n이 주소 옆에 슬래시 (/)로 구분되어 추가되어야 한다. 이러한 표기법을 보통 슬래시 표기법이라고 한다. 클래스 없는 주소지정에서는 아래 그림과 같이 표현된다. 슬래시 표기법을 공식적으로는 클래스 없는 도메인 간 라우팅(CIDR: Classless Interdomain Routing) 표기법이라고 한다.
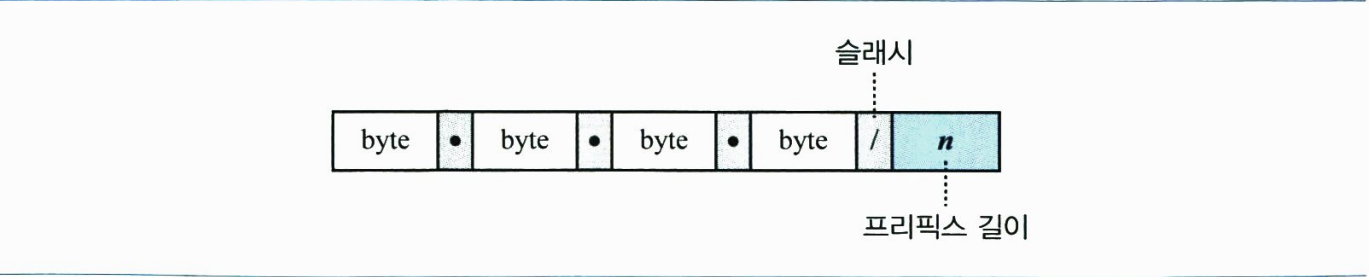

- 네트워크 마스크
클래스 없는 주소지정 방식에서 정의되는 네트워크 마스크는 클래스 기반 주소지정 방식에서 정의된 것과 같은 개념을 갖는다. 네트워크 마스크는 32비트 숫자이며, 왼쪽부터 n개의 연속적인 비트는 1로 설정하고 그 나머지 비트는 0으로 설정한다.

- 블록 정보 추출
슬래시 표기법(CIDR)으로 표시된 주소는 첫 번째 주소(네트워크 주소), 주소의 개수, 그리고 마지막 주소 등과 같은 블록에 포함된 모든 정보를 포함한다. 이러한 세 종류의 정보를 다음과 같이 구할 수 있다.





3.3 블록 할당
CIDR이 올바르게 동작하기 위해서는 블록을 할당할 때 다음과 같은 세 가지 제약조건이 만족되어야 한다.
- 요구 주소의 수인 N(주소의 개수)은 2의 거듭제곱이 되어야 한다. 이것은 프리픽스 길이인 n이 정수가 되기 위하여 필요하다.
- 블록에 속하는 주소의 개수로 프리픽스 길이의 값을 알 수 있다. N = 2**(32-n)이다. 이것이 N이 2의 거듭제곱이 되어야 하는지에 대한 답이다.
- 할당하고 하는 블록에 속하는 주소들은 연속적인 숫자여야 하며 또한 다른 블록에 할당되지 않은 상태로 있어야 한다. 블록의 시작 주소를 선택하는 데에는 한 가지 제약조건이 있다. 시작 주소는 블록에 속하는 주소의 개수로 나누어질 수 있어야한다.
즉, 프리픽스를 10진수로 표현한 값을 X라고 하면 시작 주소는 X * N(주소의 개수) 이다.

- 클래스 기반 주소지정 방법과의 관계


3.4 서브넷팅
3단계 계층 서브넷팅을 이용하여 구성될 수 있다. 하나의 블록을 할당받은 기관(또는 ISP)은 블록을 여러 개의 서브-블록으로 나눈 후에 각 서브-블록을 서브넷에 할당한다. 기관은 더 많은 단계를 추고로 만들수도 있다. 서브넷은 여러 개의 서브-서브넷으로 나누어질 수 있다.
- 서브넷 설계
네트워크에서 서브넷은 패킷의 경로 설정이 가능하도록 신중하게 설계되어야 한다. 기관이 할당받은 주소의 총 개수는 N이고, 프리픽스 길이는 n이며, 각 서브넷에게 할당된 주소의 개수는 Nsub, 각 서브넷의 프리픽 길이는 nsub, 그리고 서브넷의 총 개수는 s라고 하자. 그러면 서브넷이 올바르게 작동하기 위해서 다음과 같은 단계가 필요하다.
- 각 서브넷에 속하는 주소의 개수는 2의 거듭제곱이어야 한다.
- 각 서브넷을 위한 프리픽스 길이는 다음 공식을 이용하여 구해야 한다.
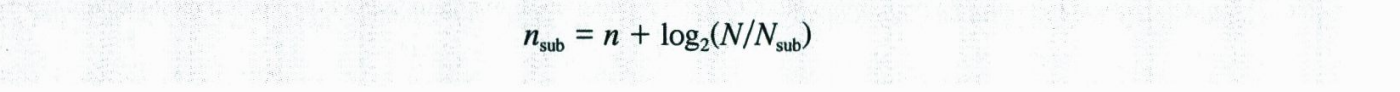
- 각 서브넷에 속하는 시작 주소는 해당 서브넷엔 속하는 주소의 개수로 나누어질 수 있어야 한다.
- 각 서브넷에서 정보 찾기
서브넷을 설계한 후에 첫 번째 주소와 마지막 주소 등과 같은 각 서브넷에 대한 정보를 찾는 방법은 인터넷의 각 네트워크에 대한 정보를 찾는 방법과 동일하다.


- 주소 결합
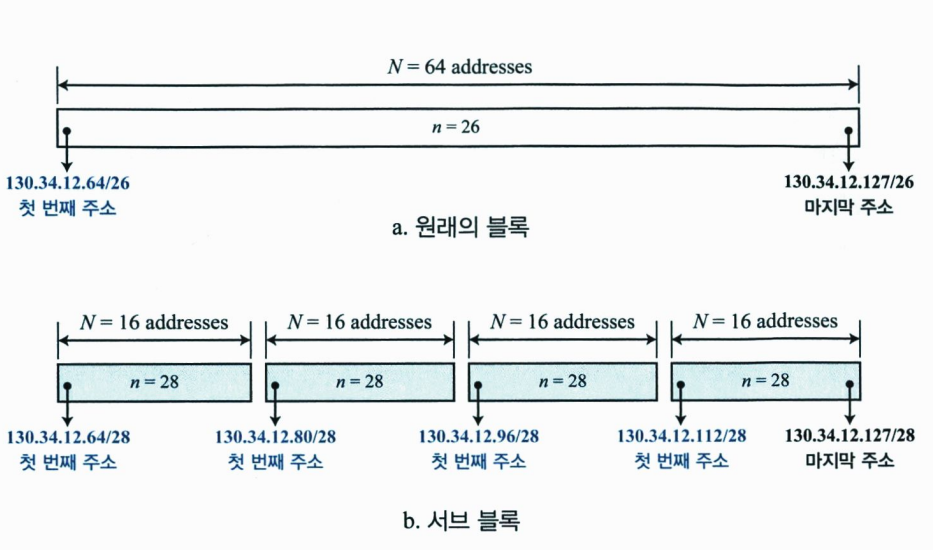
CIDR 구조의 한 가지 장점은 주소 결합이다. ICANN은 ISP에게 큰 주소 블록을 할당한다. ISP는 할당된 블록을 여러 개의 서브-블록으로 나눈 후에 각 서브-블록을 고객들에게 할당한다. 여러 개의 주소 블록이 하나의 블록으로 결합될 수 있으며 ISP에게 할당될 수 있다.


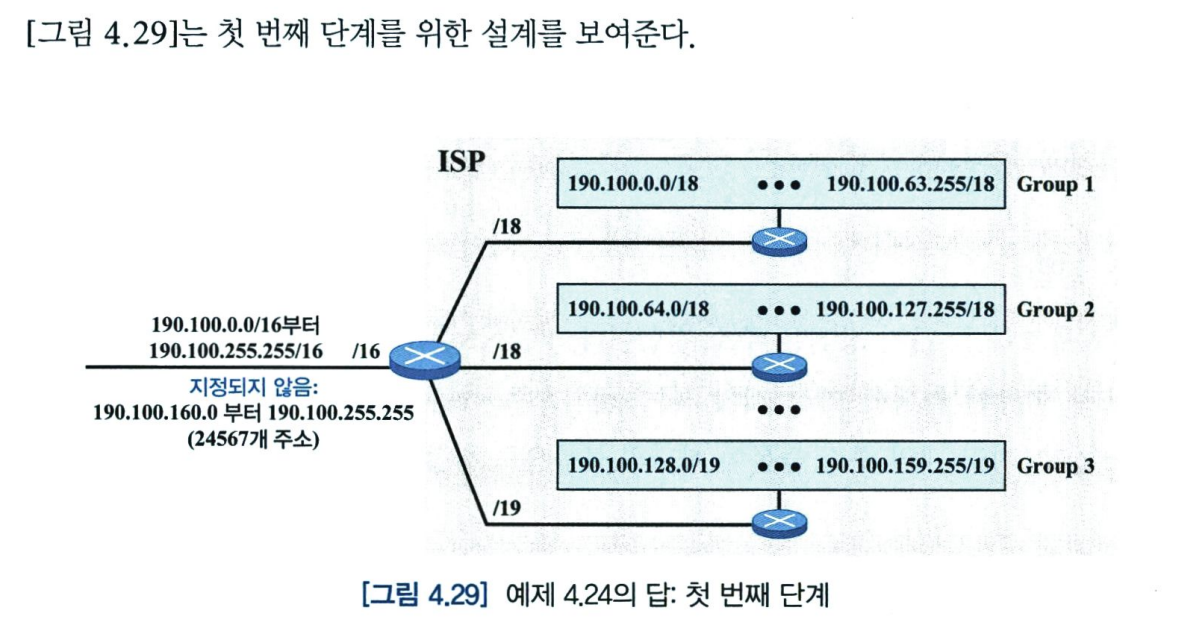

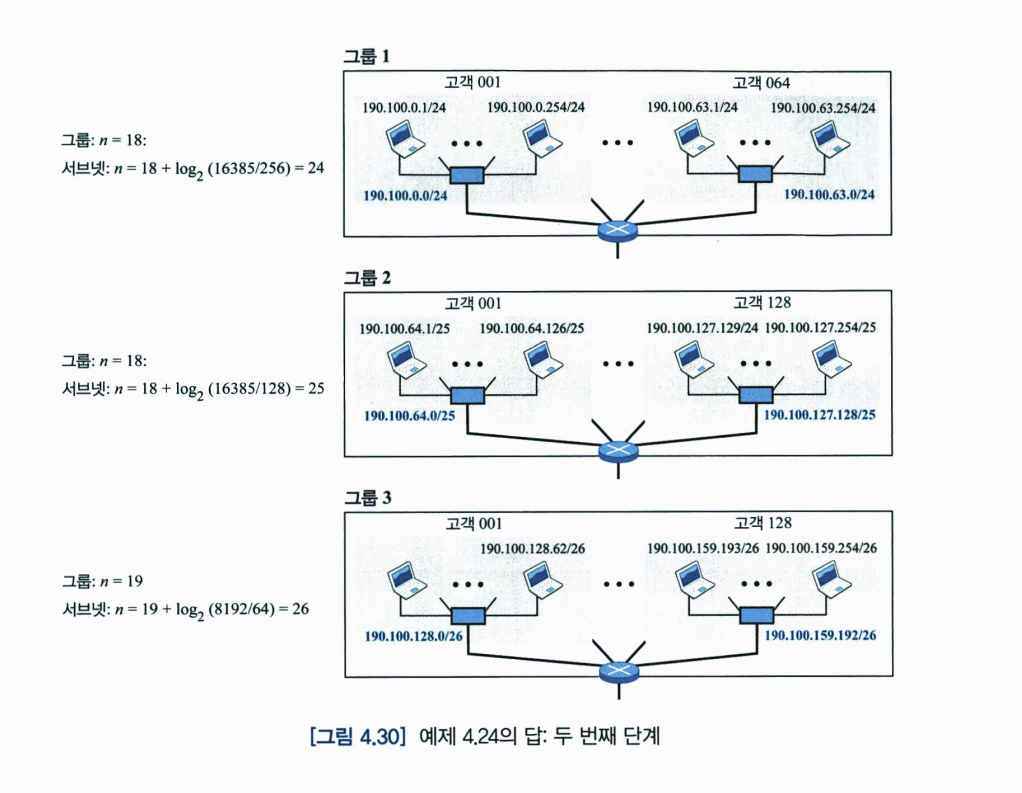
4. 특수 주소
클래긋 기반 주소지정 방식에서 일부의 주소는 특수 목적을 위하여 예약되었다. 클래스 없는 주소지정 방식에서도 클래스 기반 주소지정 방식과 같은 목적의 특수 주소들이 정의된다.
4.1 특수 블록
주소의 일부 블록은 특수 목적을 위하여 예약된 것이다.
- 모두 -0인 주소
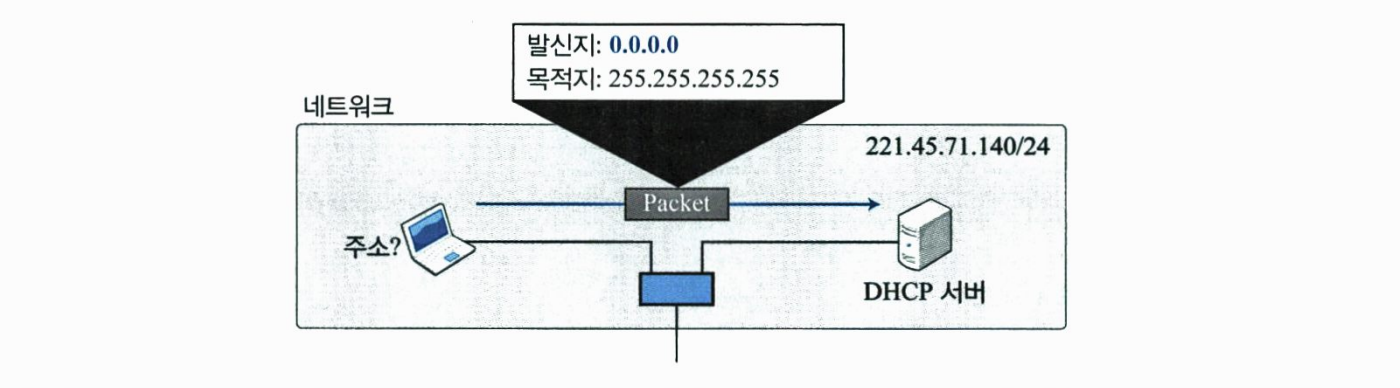
하나의 단일 주소로 표현되는 0.0.0.0/32 블록은 IPv4 패킷을 전송하고자 하는 호스트가 자신의 IPv4 주소를 모르는 경우에 통신을 위하여 사용한다. 일반적으로 부트스트랩(bootstrap) 시간에 이 주소를 사용한다. 호스트는 자신의 주소를 알기위하여 이 주소를 발신지 주소로 설정하고 목적지 주소로 제한된 브로드캐스트 주소(limited broadcast address)로 설정한 IPv4 패킷을 부트스트랩 서버(DHCP 서버)로 전송한다.
- 모두 -1인 주소: 제한된 브로드캐스트 주소
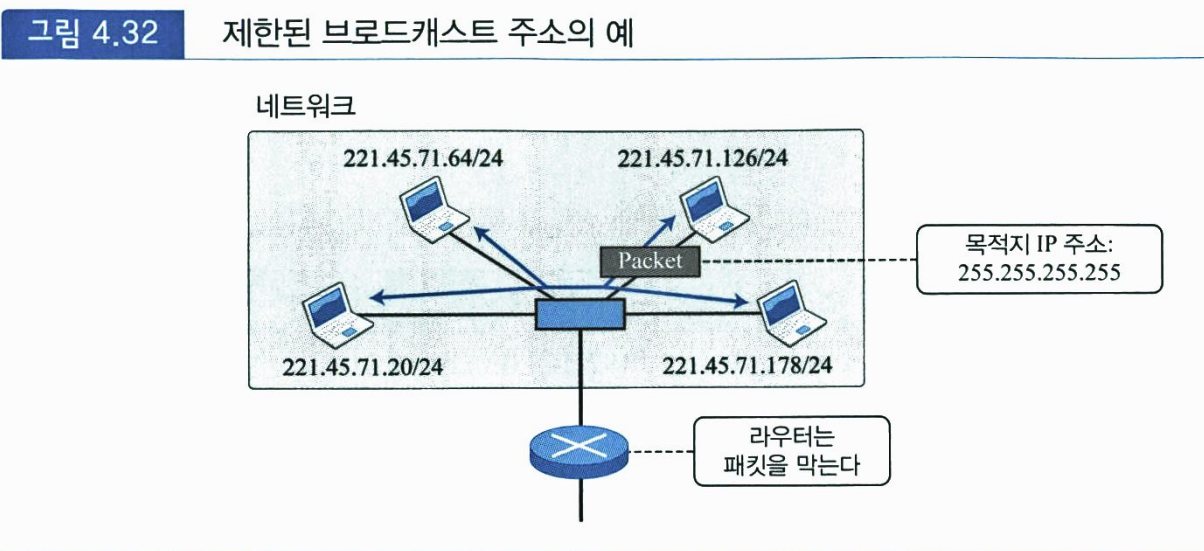
하나의 단일 주소로 표현되는 1.1.1.1/32 블록은 현제 네트워크 내의 제한된 브로드캐스트 주소(limited broadcast address)로 예약되었다. 네트워크 내의 모든 다른 호스트에게 메시지를 전송하고자 하는 호스트는 이 주소를 IPv4 패킷의 목적지 주소로 사용한다. 라우터는 브로드캐스팅을 로컬 네트워크로 제한하기 위하여 이런 유형의 주소를 가지고 있는 패킷의 포워딩을 막는다.
- 루프백 주소
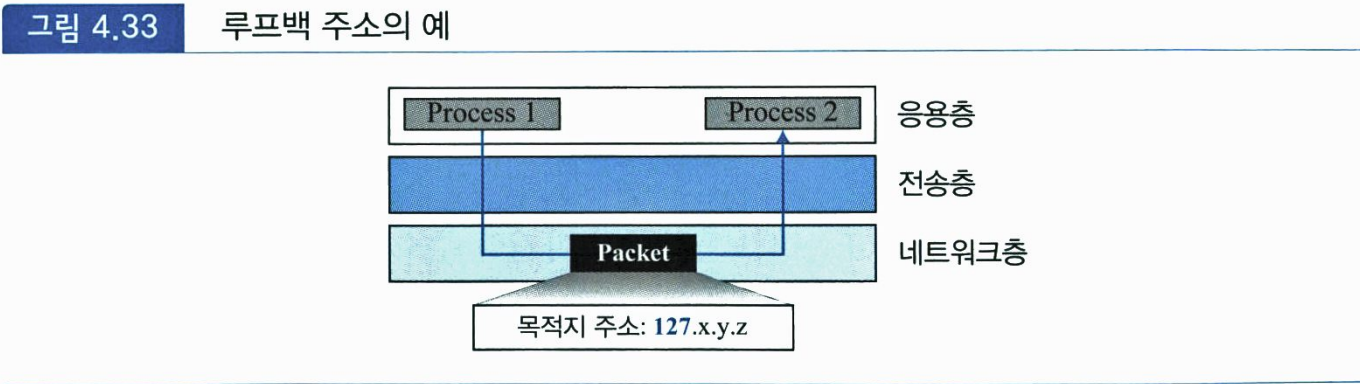
127.0.0.0/8 블록은 루프백 주소(loopback address)로 사용된다. 루프백 주소는 컴퓨터 내에 설치된 소프트웨어를 시험하기 위하여 사용되는 주소이다. 이 주소를 사용하는 패킷은 컴퓨터 외부로 전송되지 않고 단순히 프로토콜 소프트웨어로 보내진다. 클라이언트 프로세스(실행 중인 응용 프로그램)가 동일한 컴퓨터에 있는 서버 프로세스로 메시지를 전송하는 경우에 사용될 수 있다. 루프백 주소는 IPV4 패킷의 목적지 주소로만 사용 될 수 있다.
- 사설 주소
여러 블록이 사설 용도를 위하여 할당되었다. 이 주소들은 전역 네트워크에서 인식되지 않는다. 이 주소들은 네트워크가 분리되어 있거나 또는 주소 변환 기술(NAT: Network Address Translation)을 사용하여 사설 망(private network)을 인터넷에 연결하는 데 사용된다.

- 멀티캐스트 주소
224.0.0.0/4 블록은 멀티캐스트 통신을 위하여 예약된 블록이다.
4.2 블록에 속하는 특수 주소
블록에 속하는 일부 주소를 특수 주소로 사용하는 것은 의무사항은 아니고 권고사항이다. 이러한 주소는 호스트에 할당할 수 없다.
- 네트워크 주소
블록에 속하는 첫 번째 주소(서픽스가 모두 0)는 네트워크 주소를 나타낸다. 이 주소는 네트워크 자체를 정의한다. 마찬가지로 서브넷에 속하는 첫 번째 주소를 서브넷 주소라고 하며 동일한 임무를 수행한다. - 직접 브로드캐스트 주소
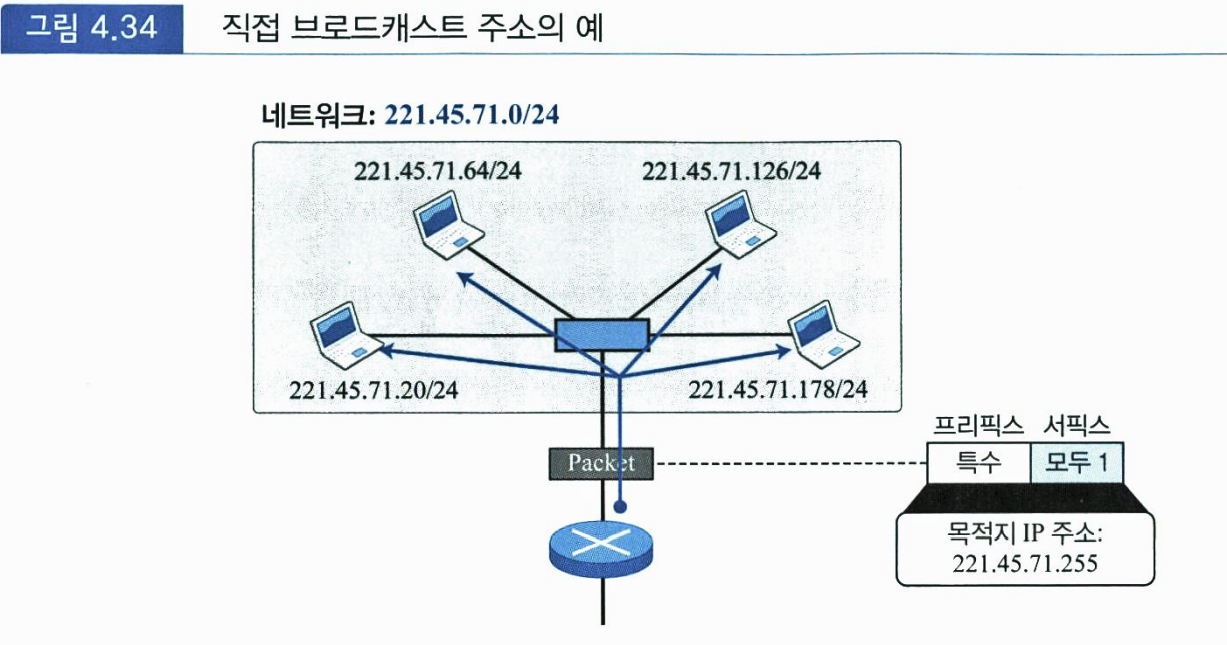
서픽스가 모두 1로 설정된 블록 또는 서브-블록의 마지막 주소는 직접 브로드캐스트 주소(direct broadcast address)로 사용된다. 이 주소는 일반적으로 라우터가 특정한 네트워크에 있는 모든 호스트에게 패킷을 전송하기 위하여 사용된다. 이 주소는 IPv4 패킷에서 목적지 주소로만 사용할 수 있다.
5. IPv6 주소
IPv4 주소가 고갈됨에 따라 IP6v 포로토콜을 개발하게 되었다.
IPv6 주소는 그림과 같이 128비트 또는 16바이트 길이이다. IPv6에서 주소 길이는 IPv4 주소 길이의 4배이다.

5.1 표기법
- 점 10진 표기법
IPv4 주소와 호환성을 갖기 위해 점 10진 표기법(dotted-decimal notation)을 사용한다.

이 표기법은 부분적으로 사용될 수는 있지만 거의 사용되지 않는다. - 콜론 16진 표기법
IPv4 주소를 보다 읽기 쉽게 하기 위해 IPv6는 콜론 16진 표기법(colon hexadecimal notation)을 규정하였다. 이 표기법에서 128비트는 각각의 길이가 2바이트인 8개인 영역으로 나누어진다.
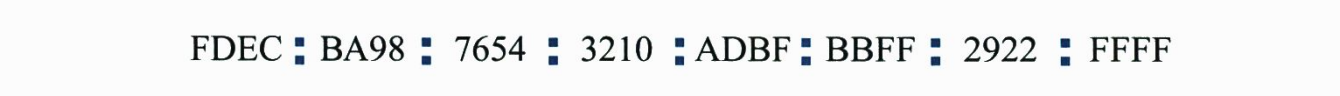
한 섹션에서 앞의 0은 생략될 수 있다. 예를들어 0074는 74로, 000F는 F로, 0000은 0로 표기할 수 있다. 오직 앞의 0만이 생략될 수 있다.
제로 압축(zero compression)이라는 생략법은 0으로만 구성된 연속된 섹션이 있는 경우에 0을 모두 지우고 두 개의 콜론으로 대체할 수 있다.

이러한 생략 방식은 주소마다 한 번만 허용된다. 만약 두 개의 연속된 0섹션이 있다면 그 중 한개의 0 섹션만 생략할 수 있다. - 혼합 표기법
때로는 콜론 16진 표기법과 점 10진 표기법을 혼합하여 표기할 수 있다.

이 표기법에도 제로 압출을 적용할 수 있다. - CIDR 표기법
IPv6는 계층적인 주소지정을 사용한다.




5.2 주소 공간
IPv6의 주소 공간은 2의 128승이다. (절대로 주소가 고갈되지 않는다.)
5.3 세 가지 주소 유형
- 유니캐스트 주소
유니캐스트 주소(unicast address)는 단일 인터페이스(컴퓨터 또는 라우터)**를 정의한다. - 에니캐스트 주소
에니캐스트 주소(anycast address)는 단일 주소를 모두 공유하는 컴퓨터 그룹을 정의한다. (유니캐스트가 모인 것) - 멀티캐스트 주소
멀티캐스트 주소(multicast address)는 컴퓨터 그룹을 정의한다.(에니캐스트가 모인 것)
6. IPv6 주소 공간 할당
IP6v의 주소 공간은 다양한 크기의 블록으로 나누어지며, 각 블록은 특별한 목적을 위해 할당된다. 전체 주소 공간은 8개로 나누어진다.
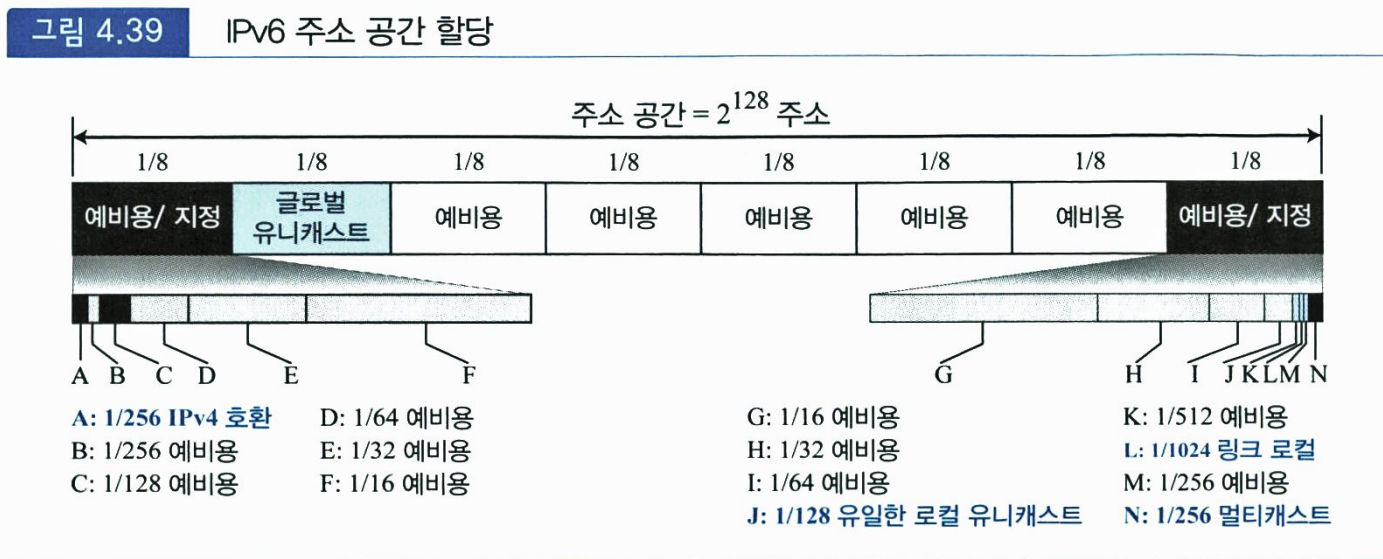
주소 공간의 1/8만이 사용자들 사이에서 유니캐스트 통신을 위해 사용되고 있다.
