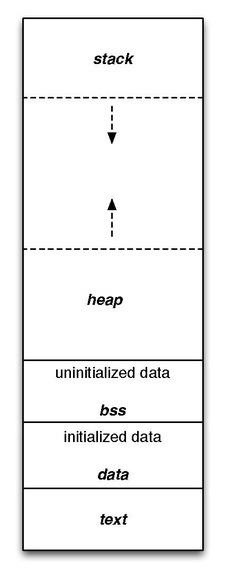
프로세스가 차지하고 있는 메모리를 살펴보면 크게 Code, Data, Heap, Stack의 영역으로 나누어져 있고 이들 각각을 segment라고 부릅니다. 이렇게 메모리 영역을 나누면 CPU의 연산을 빠르게 하고 메모리 공간의 효율을 좋게 할 수 있습니다.
Code
그림에서 제일 아래 text가 code 부분입니다.
작성한 코드가 들어가는 부분입니다. 기계어도 포함됩니다.
이 부분은 "read only" 영역이라 쓰기 작업이 들어오면 "access violation"이 발생합니다.
프로세스가 종료될 때까지 계속 유지되는 영역입니다.
- access violation이란 적절한 권한이 없는 프로세스가 제한된 메모리 영역에 읽고 쓰기를 시도할 때 엑세스 위반이 발생합니다.
Data
전역변수(global), 정적변수(static), 배열(array), 구조체(structure) 등이 저장됩니다. 이 영역 또한 프로세스의 종료까지 유지 됩니다.
1) 초기화된 데이터 : data에 저장
2) 초기화되지 않은 데이터 : bss(Block Stated Symbol)에 저장
-
사실 bss도 초기화를 합니다. 단, 값을 초기화 하는 것이 아닌, 메모리 상의 공간을 초기화 시키는 것입니다.
-
즉, data 영역이 런타임 이전에 초기화 하는 것이고, bss는 런타임 이후 초기화하는 것입니다.
-
왜 초기화의 유무로 data 영역과 bss영역을 구분할까요?
-
프로그램을 만들어서 컴파일 한 뒤 링크를 하고 이미지로 만들어 임베디드 시스템의 Rom에 저장을 했다고 가정해봅시다. 초기화 된 데이터는 초기값을 저장해야 하기 때문에 Data 영역에 저장되어 Rom에 저장되게 됩니다. 하지만 초기화 되지 않은 데이터까지 Rom에 저장된다면 큰 Size의 Rom이 필요하게 됩니다. 어차피 초기화되지 않은 변수를 비싼 Rom에 저장할 필요가 없기 때문에 이를 Ram에 저장하는 것입니다.그래서 초기화의 유무로 Data와 Bss로 나눈 것입니다. <메모리 공간의 효율 증가>
-
Ram vs Rom
- Ram(Random Access Memory) : 휘발성 메모리 → 전원이 차단되면 데이터가 사라집니다.
- Rom(Read Only Memory) : 비휘발성 메모리 → 전원이 차단되어도 데이터가 사라지지 않습니다.
-
함수 내(main 함수 포함) 변수들은 여기 해당되지 않고 Stack 영역에 해당합니다.
Heap
프로그래머가 동적으로 사용하는 영역입니다. 사용자가 직접 관리 할 수 있는 "그리고 해야만 하는" 메모리 영역입니다. Heap 영역은 사용자에 의해 메모리 공간이 동적으로 할당되고 해제됩니다.
malloc, free 또는 new, delete에 의하여 할당, 또는 반환되는 영역입니다.
자바나 C++ 과 같이 garbage collector가 활동하는 경우, 자동으로 반환되는 경우도 있습니다.
Stack
지역변수, 매개변수, 복귀 번지 등이 저장되어 있는 프로그램이 자동으로 사용하는 임시메모리 입니다.
함수 호출 시 생성되고, 함수 종료시 반환됩니다.
- Stack도 데이터지만 함수(function)안에서만 쓰면 끝이기 때문에 함수 종료시 반환하여 Ram의 소비용량을 줄일 수 있습니다. <메모리 공간의 효율 증가>
그리고 Stack이라는 이름으로 유추 가능하셨겠지만 Last In First Out을 사용합니다.
다른 세그먼트들이 하위 영역으로부터 할당되지만 Stack 세그먼트는 상위 영역부터 할당됩니다.
- Heap 영역이 커지면 Stack 영역이 작아지게 되고, 역도 성립합니다.
- heap overflow: heap이 stack 영역을 침범하는 것
- stack overflow: stack이 heap 영역을 침범하는 것
정리
CPU 연산을 빠르게 하고 메모리 공간의 효율을 위해 프로세스가 차지하고 있는 메모리는 크게 4등분 되어 있습니다.
- Code(text) 영역: Instruction(명령어) 집합의 저장소
- Data 영역: 초기화된 Global 변수 집합의 저장소
- Bss 영역: 초기화되지 않은 Global 변수 집합의 저장소
- Heap 영역: 사용자가 동적으로 할당하고 해제하는 저장소
- Stack영역: 함수 내부에 정의된 변수 집합의 저장소로 함수 호출시 생성되고 함수 종료시 반환됩니다.
CPU 연산의 효율과 H/W 구현의 단순화를 위하여 크게 Instruction(Code)과 Data(Data, Bss, Stack)으로 나누어져 있습니다.
메모리 공간의 효율을 위하여 Data는 Data, Bss, Stack으로 다시 나누어져 있습니다.
Code, Data, Bss 영역은 컴파일시 크기가 결정되고 Heap, Stack 영역은 런타임시 크기가 결정됩니다.
