HashMap,HashTable,CoucurrentHashMap은Map인터페이스의 구현체이다.Map인터페이스를 구현하면<Key, Value>형태를 띈다.HashMap,HashTable,CoucurrentHashMap의 특징을 알아보고 차이점을 알아보자.
HashMap
-
key, value에
null을 허용한다. -
동기화를 보장하지 않는다.
HashMap은 thread-safe 하지 않아, 싱글 스레드 환경에서 사용하는게 좋다.
한편, 동기화 처리를 하지 않기 때문에 데이터를 탐색하는 속도가 빠르다.
→ 즉 HashTable과 ConcurrentHashMap보다 데이터를 찾는 속도는 빠르지만, 신뢰성과 안정성이 떨어진다.
HashMap 내부 코드
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
public V get(Object key) {}
public V put(K key, V value) {}
}public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
...
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
...
}-
HashMap은synchronized선언이 없기 때문에 동기화 락을 하지 않아 멀티 스레드에서 여러 스레드가 동시에 객체의 data를 조작하는 경우 data가 깨져버리고 심각한 오류가 발생할 수 있다. -
동기화 락을 하지 않기 때문에
HashTable보다HashMap이 훨씬 빠르다. -
따라서 단일 스레드에서만 쓰일 때는
HashMap을 사용해야 한다.
HashTable
-
key와 value에
null을 허용하지 않는다. -
동기화를 보장한다.
HashTable은 thread-safe 하기 때문에, 멀티 스레드 환경에서 사용할 수 있다.
데이터를 다루는 메소드(get(), put(), remove() 등)에 synchronized 키워드가 붙어 있다. synchronized 키워드는 메소드를 호출하기 전에 스레드 간 동기화 락을 건다. 그래서 멀티 스레드 환경에서도 데이터의 무결성을 보장한다.
그러나, 스레드간 동기화 락은 매우 느린 동작이라는 단점이 있다.
HashTable 내부코드
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized int size() { }
@SuppressWarnings("unchecked")
public synchronized V get(Object key) { }
public synchronized V put(K key, V value) { }
}public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {
...
public synchronized V put(K key, V value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
...
}-
HashMap과HashTable은 동일한 내부 구조를 가지고 있지만HashTable의 경우는 동기화된 메소드로 구성되어 있다. -
HashTable의 모든 data 변경 메소드는synchronized로 선언되어 있다. 메소드 호출 전 스레드간 동기화 락을 통해 멀티 스레드 환경에서 data의 무결성을 보장해준다. -
즉, 멀티 스레드가 동시에 이 메소드를 실행할 수 없고 하나의 스레드가 실행을 완료해야만 다른 스레드가 실행 가능하다. 이는 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있다는 것을 의미한다.
HashMap과HashTable은 동기화를 보장하느냐 하지 않느냐는 측면 이외에는 차이가 거의 없다. 사용법도 똑같다.put()메서드로 데이터를 삽입하고,get()메서드로 추출한다.
ConcurrentHashMap
- key와 value에
null을 허용하지 않는다. - 동기화를 보장한다.
ConcurrentHashMap은 thread-safe하기 때문에, 멀티 스레드 환경에서 사용할 수 있다.
ConcurrentHashMap은 HashMap의 동기화 문제를 보완하면서 멀티 스레드 환경에서 사용할 수 있도록 나온 클래스이다. (JDK 1.5에 검색과 업데이트시 동시성 성능을 높이기 위해서 나온 클래스이다.)
동기화 처리를 할 때, 어떤 Entity를 조작하는 경우에 해당 Entry에 대해서만 락을 건다. 그래서 HashTable보다 데이터를 다루는 속도가 빠르다. 즉, Entry 아이템별로 락을 걸어 멀티 스레드 환경에서의 성능을 향상시킨다.
→ConcurrentHashMap 클래스은 Hashtable 클래스보다는 더 빠르고 Multi-Thread 환경에서 쓸 수 있는 클래스이다.
ConcurrentHashMap 내부 코드
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {
public V get(Object key) {}
public boolean containsKey(Object key) { }
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) {
throw new NullPointerException();
}
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
...
}-
ConcurrentHashMap는HashTable과는 다르게synchronized키워드가 메소드 전체에 붙어 있지 않다.get()메소드에는synchronized가 존재하지 않고put()메소드에는 중간에synchronized키워드가 존재한다.→ 즉,
ConcurrentHashMap은 읽기 작업에는 여러 스레드가 동시에 읽을 수 있지만 쓰기 작업에는 특정 세그먼트 or 버킷에 대한 Lock을 사용한다.따라서 다른 버킷이라면 여러 스레드가 동시에 쓰는 작업을 할 수 있다. 그래서 데이터의 각 영역이 서로 영향을 주지 않는 작업에 대해서는 경쟁이 발생하지 않기 때문에 여러 쓰레드에서 빈번하게 접근하더라도 락 획득을 위한 대기 시간을 많이 줄일 수 있다.
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final int DEFAULT_CAPACITY = 16;
// 동시에 업데이트를 수행하는 쓰레드 수
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
}-
DEFAULT_CAPACITY는 버킷의 수이고DEFAULT_CONCURRENCY_LEVEL는 동시에 작업 가능한 스레드 수이다. -
두 상수가 같은 것을 볼 수 있는데 버킷의 수가 동시 작업 가능한 스레드 수인 이유는
ConcurrentHashMap은 버킷 단위로 lock을 사용하기 때문에 같은 버킷만 아니라면 Lock을 기다릴 필요가 없다는 특징이 있기 때문이다. (버킷 하나당 하나의 Lock을 가지고 있다고 생각하면 된다.)→ 즉, 여러 스레드에서
ConcurrentHashMap객체에 동시에 데이터를 삽입, 참조하더라도 그 데이터가 다른 버킷에 위치하면 서로 락을 얻기 위해 경쟁하지 않는다.
ConcurrentHashMap 생성자
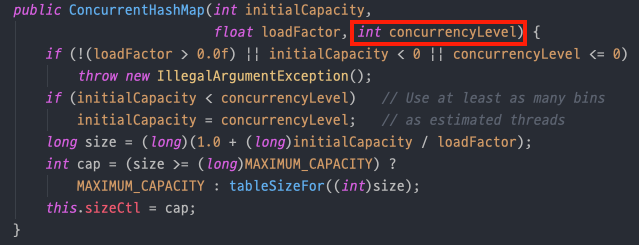
conrrencyLevel이 존재한다. 동시에 몇 개의 쓰레드를 작동하게 할 것인지 정한다. DEFAULT는 16이지만 위와 같이 직접 지정할 수도 있다.- 효과를 극대화하기 위해서는 상황에 따라 적절히 세그먼트를 나누는 것이 필요하다. 데이터를 너무 적은 수의 조각으로 나누면 경쟁을 줄이는 효과가 적을 것이고 너무 많은 수의 조각으로 나누면 이 세그먼트를 관리하는 비용이 커지기 때문이다.
ConcurrentHashMap의 동기화 방식
put()메소드를 더 살펴보자. 다음 코드에서는 새로운 entry를 put한다. put 함수는 크게 2가지 경우로 나눌 수 있는데 새로운 노드가 들어갈 배열의 인덱스가 비어있는 경우와 이미 기존 노드가 있는 경우이다.
- 빈 해시 버킷에 노드를 삽입하는 경우, lock 을 사용하지 않고 Compare and Swap 을 이용하여 새로운 노드를 해시 버킷에 삽입한다.(원자성 보장)
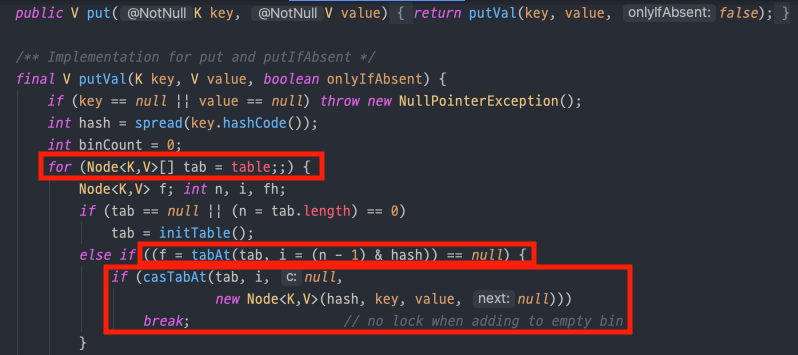
(1) 무한 루프. table 은 내부적으로 관리하는 가변 배열이다.
(2) 새로운 노드를 삽입하기 위해, 해당 버킷 값을 가져와(tabAt 함수) 비어 있는지 확인한다.(== null)
(3) 다시 Node 를 담고 있는 volatile 변수에 접근하여 Node 와 기대값(null) 을 비교하여(casTabAt 함수) 같으면 새로운 Node 를 생성해 넣고, 아니면 (1)번으로 돌아간다(재시도)
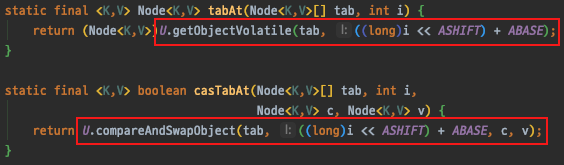
-
volatile 변수에 2번 접근하는 동안 원자성(atomic)을 보장하기 위해 기대되는 값과 비교(Compare)하여 맞는 경우에 새로운 노드를 넣는다(Swap).
-
CAS 구현은
java.util.concurrent.atomic패키지의Atomic*클래스들과 동일하게 내부적으sun.misc.Unsafe을 사용하고있다. (Unsafe 는 jdk11 부터 없어 졌다고 한다.)
-
이미 노드가 존재 하는 경우는
synchronized (노드가 존재하는 해시 버킷 객체)를 이용해 하나의 스레드만 접근할 수 있도록 제어한다.서로 다른 스레드가 같은 해시 버킷에 접근할 때만 해당 블록이 잠기게 된다.

- synchronized 안의 로직은 HashMap 과 비슷한 로직이다. 동일한 Key 이면 Node 를 새로운 노드로 바꾸고, 해시 충돌(hash collision) 인 경우에는 Separate Chaining 에 추가 하거나 TreeNode 에 추가한다.
TREEIFY_THRESHOLD값에 따라 체이닝을 트리로 바꾼다.
읽기 작업에는 동기화가 적용되지 않는데 어떻게 진행되는가?
- 검색
get()에는 동기화가 적용되지 않으므로 업데이트 작업put()remove()과 겹칠 수 있다. 그래서 검색은 가장 최근에 완료된 업데이트 작업의 결과가 반영된다.
정리
| HashMap | HashTable | ConcurrentHashMap | |
|---|---|---|---|
| key와 value에 null을 허용 | O | X | X |
| 동기화 보장(Thread-safe) | X | O | O |
| 추천 환경 | 싱글 스레드 | 멀티 스레드 | 멀티 스레드 |
결론
싱글 스레드 환경이면 HashMap을, 멀티스레드 환경이면 HashTable이 아닌 ConcurrentHashMap을 쓰자. 그 이유는 HashTable보다 ConcurrentHashMap이 성능적으로 우수하기 때문이다. HashTable은 스레드간 락을 걸어 데이터를 다루는 속도가 느리다. 반면, ConcurrentHashMap은 Entry 아이템 별로 락을 걸어 데이터를 다루는 속도가 빠르다.
java8 에서 ConcurrentHashMap은 각 테이블 버킷을 독립적으로 잠그는 방식이다. 빈 버킷으로의 노드 삽입은 lock 을 사용하지 않고 단순히 CAS 만을 이용해 삽입한다. 그 외의 업데이트(삽입, 삭제 및 교체)는 lock(synchronized) 을 이용하지만 각 버킷의 첫 번째 노드를 기준으로 부분적인 잠금을 획득하여 스레드 경합을 최소화 하고 안전한 업데이트를 한다.
References
- https://tecoble.techcourse.co.kr/post/2021-11-26-hashmap-hashtable-concurrenthashmap/
- Hashtable, HashMap, ConcurrentHashMap 비교
- [Java] HashTable, Hashmap, ConCurrentHashMap 차이
- HashMap, Hashtable, ConcurrentHashMap 동기화 처리 방식
- https://limkydev.tistory.com/40
- http://blog.leekyoungil.com/?p=159
- https://devlog-wjdrbs96.tistory.com/269
- https://pplenty.tistory.com/17
