📌 스트림(Stream)이란?
스트림(Stream)은 Java 8부터 지원되기 시작한 기능입니다. 컬렉션에 저장되어 있는 요소들을 하나씩 순회하면서 처리할 수 있는 코드패턴입니다. 람다식과 함께 사용되어 컬렉션에 들어있는데이터에 대한 처리를 매우 간결한 표현으로 작성할 수 있습니다.
Stream 특징
- 요청할 때만 요소를 계산합니다. 내부 반복을 사용하므로, 추출 요소만 선언해주면 알아서 반복처리를 진행합니다.
- 스트림에 요소를 따로 추가, 제거하는 작업은 불가능합니다.
특징
1. 원본 데이터 소스: 스트림은 데이터를 처리하기 위한 원본 데이터 소스에서 시작합니다. 이 데이터 소스는 컬렉션, 배열, 파일, 네트워크 연결 등 다양할 수 있습니다.
-
중간 연산: 중간 연산은 스트림에서 데이터를 가져와 다른 스트림을 반환하는 연산입니다. 이러한 연산은 데이터를 변환하거나 필터링하는 데 사용됩니다. 대표적인 중간 연산으로 filter, map, distinct, sorted 등이 있습니다.
-
최종 연산: 최종 연산은 스트림의 처리를 시작하고 결과를 반환하는 연산입니다. 최종 연산이 호출되어야 중간 연산이 실제로 실행됩니다. 최종 연산은 스트림을 닫고 더 이상 사용할 수 없게 만듭니다. 대표적인 최종 연산으로 forEach, collect, reduce, min, max 등이 있습니다.
-
스트림 파이프라인: 스트림은 여러 중간 연산과 최종 연산을 연결하여 데이터 처리 파이프라인을 구성할 수 있습니다. 이를 통해 데이터를 연속적으로 변환하고 처리할 수 있습니다.
-
게으른 연산(Lazy Evaluation): 스트림은 게으른 연산을 수행합니다. 즉, 최종 연산이 호출되기 전까지 중간 연산은 실제로 수행되지 않습니다. 이로 인해 필요한 연산만 실행되므로 효율적인 처리가 가능합니다.
-
병렬 처리: 스트림은 병렬 처리를 지원하며, 데이터를 여러 스레드를 사용하여 병렬로 처리할 수 있습니다. 이는 대량의 데이터를 효율적으로 처리하는 데 유용합니다.
외부 반복 & 내부 반복
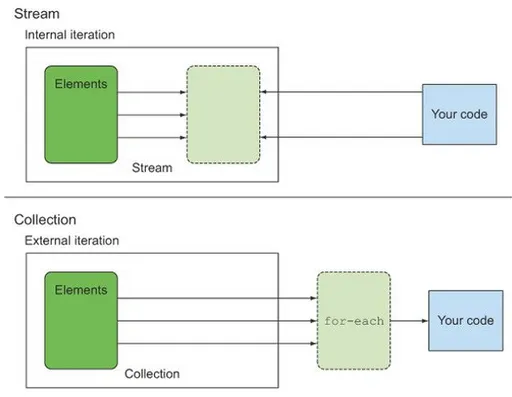
성능 면에서는 '내부 반복'이 비교적 좋습니다.
내부 반복은 작업을 병렬 처리하면서 최적화된 순서로 처리해줍니다.
하지만 외부 반복은 명시적으로 컬렉션 항목을 하나씩 가져와서 처리해야하기 때문에 최적화에 불리합니다.
즉, Collection에서 병렬성을 이용하려면 직접 synchronized를 통해 관리해야만 합니다.
📌 Stream 연산
스트림은 연산 과정이 '중간'과 '최종'으로 나누어집니다.
filter, map, limit 등 파이프라이닝이 가능한 연산을 중간 연산, count, collect 등 스트림을 닫는 연산을 최종 연산이라고 합니다.
❗️ 둘로 나누는 이유는, 중간 연산들은 스트림을 반환해야 하는데, 모두 한꺼번에 병합하여 연산을 처리한 다음 최종 연산에서 한꺼번에 처리하게 됩니다.
Stream 중간 연산
- filter(Predicate) : Predicate를 인자로 받아 true인 요소를 포함한 스트림 반환
- distinct() : 중복 필터링
- limit(n) : 주어진 사이즈 이하 크기를 갖는 스트림 반환
- skip(n) : 처음 요소 n개 제외한 스트림 반환
- map(Function) : 매핑 함수의 result로 구성된 스트림 반환
- flatMap() : 스트림의 콘텐츠로 매핑함. map과 달리 평면화된 스트림 반환
Stream 최종 연산
- (boolean) allMatch(Predicate) : 모든 스트림 요소가 Predicate와 일치하는지 검사
- (boolean) anyMatch(Predicate) : 하나라도 일치하는 요소가 있는지 검사
- (boolean) noneMatch(Predicate) : 매치되는 요소가 없는지 검사
- (Optional) findAny() : 현재 스트림에서 임의의 요소 반환
- (Optional) findFirst() : 스트림의 첫번째 요소
- reduce() : 모든 스트림 요소를 처리해 값을 도출. 두 개의 인자를 가짐
- collect() : 스트림을 reduce하여 list, map, 정수 형식 컬렉션을 만듬
- (void) forEach() : 스트림 각 요소를 소비하며 람다 적용
- (Long) count : 스트림 요소 개수 반환
참고
피드백 및 개선점은 댓글을 통해 알려주세요😊
