
🍀 H-Index
요새 느끼는 건데 내가 문장 이해력이 부족한가 싶다 ㅜㅜ🤣 하지만, 그래도 이런 저런 시행착오를 겪으면서 문제를 이해하여 풀었다. 내가 여기서 가장 문제를 겪었던 부분은 배열 안에 존재하는 요소 즉, 인용된 횟수가 꼭 H-Index가 아니라는 점이다. 예를 들어 citations = [3, 0, 6, 1, 5, 5, 5]일 때 H-Index는 4가 답이다.
H-Index가 4일 때 4회이상 인용된 횟수는 4이며 4이하 인용된 횟수는 3으로 3 <= 4 <= 4를 만족하기 때문이다.
less: H-Index 이하 인용된 횟수, more: H-Index 이상 인용된 횟수라 가정하면
H-Index: 0일 때 less(1) <= 0(H-Index) <= 7 👉🏻 거짓이므로 H-Index는 0이 될 수 없다.H-Index: 1일 때 less(2) <= 1(H-Index) <= 6 👉🏻 거짓이므로 H-Index는 0이 될 수 없다.
H-Index: 2일 때 less(2) <= 2(H-Index) <= 6 👉🏻 거짓이므로 H-Index는 2가 될 수 있다.
H-Index: 3일 때 less(3) <= 3(H-Index) <= 5 👉🏻 거짓이므로 H-Index는 3이 될 수 있다.
H-Index: 4일 때 less(3) <= 4(H-Index) <= 5 👉🏻 거짓이므로 H-Index는 4가 될 수 있다.
H-Index: 5일 때 less(6) <= 5(H-Index) <= 4 👉🏻 거짓이므로 H-Index는 5가 될 수 없다.
💡 따라서 가장 큰 H-Index는
4가 된다.
이 문제를 풀고 나서 다른 사람풀이를 봤는데 정렬을 이용하여 풀었다. 하지만 정렬을 이용하지 않고 counting sort에서 로직 중 일부에 영감을 얻어 활용하였다. 여기서 일부라 함은 숫자를 index를 활용하고 숫자가 나온 횟수를 index의 값으로 담는 로직. 나의 문제 풀이 전략은 배열의 index를 인용된 눈문수로 잡고 index 위치의 값은 인용된 논문수가 같은 것을 count한 값을 넣어 H-Index를 구하였다. 말로는 역시 어렵다.... 따라서 figma를 이용하여 만든 그림을 보자.

이후 index를 H-Index로 잡고 H-Index 이상 인용된 논문의 횟수가 작을 때 바로 전의 시점의 H-Index가 최대값이 된다. 이 또한 그림으로 살펴 보자!!
아래 변수에 대한 정리를 잠깐 하고 가자.
less는 👉 H-Index이하 인용된 논문의 횟수
more는 👉 H-Index이상 인용된 논문의 횟수
total_citations_counts 👉🏻 전체 논문의 수

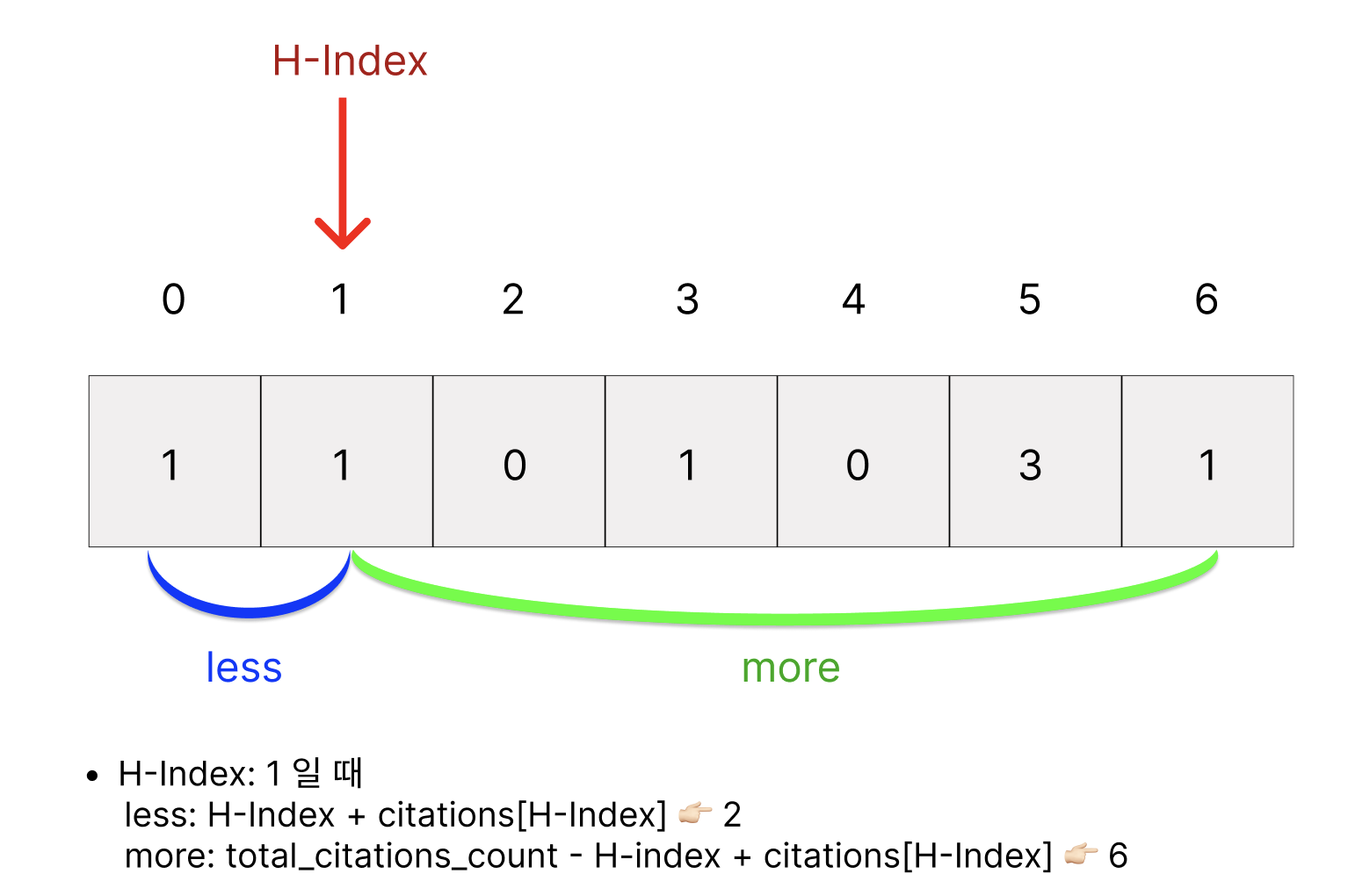
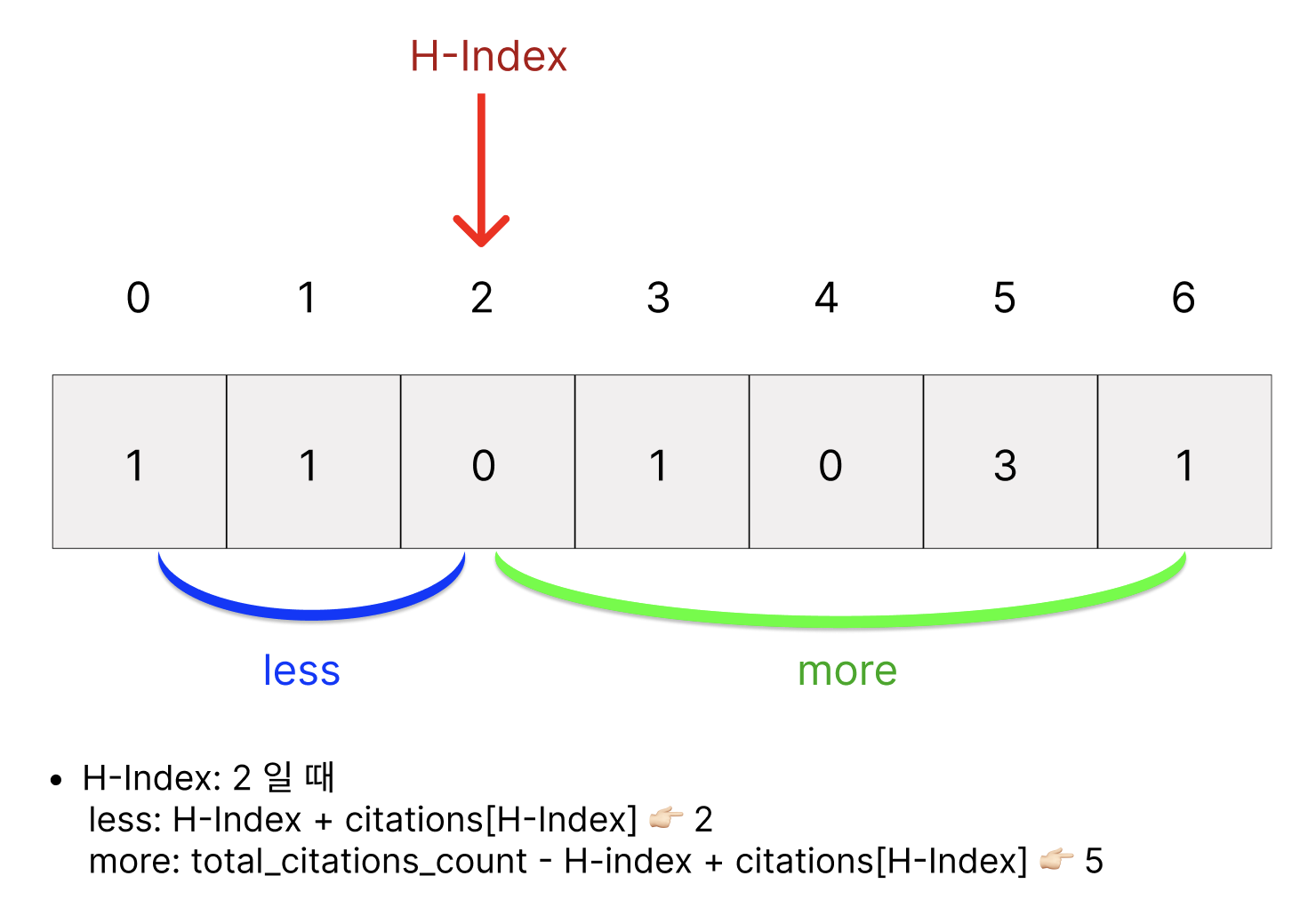


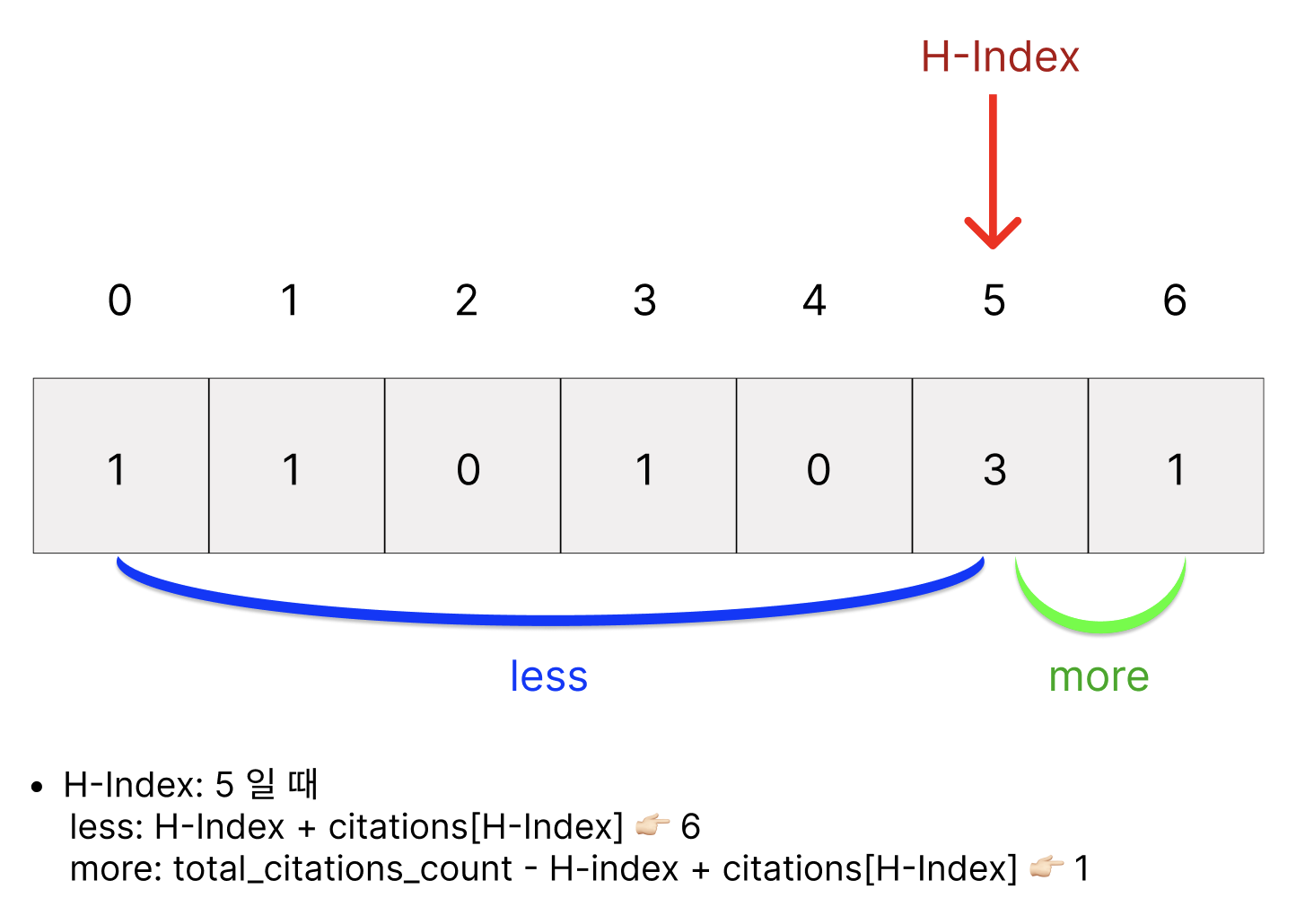
이 때 less <= H-Index <= more라는 조건을 만족하지 않으며 이 이후 시점부터는 H-Index > more가 되게되어 이전에 값인 4가 최대의 H-Index가 된다.
1️⃣ Python
이제 위의 로직을 코드로 옮기면 아래와 같다.
def count_arr(arr, max_num):
counted_arr = [0] * (max_num + 1)
for num in arr:
counted_arr[num] += 1
return counted_arr
def solution(citations):
max_citation = max(citations)
counted_arr, total_citations_count = count_arr(citations, max_citation), len(citations)
less_citations_count = 0
answer = 0
for h_index in range(len(counted_arr)):
less_citations_count += counted_arr[h_index]
more_citations_count = total_citations_count - less_citations_count + counted_arr[h_index]
if h_index > more_citations_count:
break
answer = h_index
return answercount_arr는 맨 위의 그림에 존재하는 배열을 만들기 위해 코드로 옮긴 것이고 H-Index를 배열의 처음부터 끝까지 돌면서 H-Index가 최대가 되는 시점 즉, h_index > more_citations_count 이전 시점이다.
시간 복잡도는 O(N)이며 정렬을 이용했을 때보다 빠르지만 count_arr는 메모리 공간을 많이 차지한다는 단점이 있다. 이는 counting sort할 때의 단점과 같다. 하지만, 논문별 인용 횟수는 0회 이상 10,000회 이하입니다.조건에서 최대의 배열의 길이가 10000인 것을 고려하면 좋은 풀이지 않을까 생각이 든다.
2️⃣ Javascript
자바스트크립트 코드는 python코드를 그대로 옮겨서 구현했다.
const createCountArr = (arr, maxNum) => arr.reduce((acc, cur, idx) => {
acc[cur] += 1
return acc
}, Array(maxNum + 1).fill(0))
function solution(citations) {
let [answer, lessCitationsCount] = [0, 0];
const totalCitationsCount = citations.length;
const countedArr = createCountArr(citations, Math.max(...citations));
for (let HIndex = 0; HIndex < countedArr.length; HIndex++){
lessCitationsCount += countedArr[HIndex];
const moreCitationsCount = totalCitationsCount - lessCitationsCount + countedArr[HIndex]
if (HIndex > moreCitationsCount) break;
answer = HIndex
}
return answer;
}🔥 마치며
처음에는 어떻게 풀면 좋을까 고민하다가 문뜩 counting sort 알고리즘의 일부분이 떠올랐다. 이 알고리즘은 죠르디를 사랑하시는 어느 개발자 분한테 배운 것인데 항상 고마운 분이다. 뭐 여튼 가끔 코딩을 하다가 보면 이게 내가 짠 코드가 맞나 싶은 신박한 코드들이 만들어지는데 이 때마다 기분은 되게 좋다!!!!😁😁😁 그리고 counting sort는 따로 블로그를 적어볼 생각이며 메모리 공간을 많이 차지하는 단점이 있는 대신에 정렬하는데 있어 시간은 O(N)이 걸린다.
