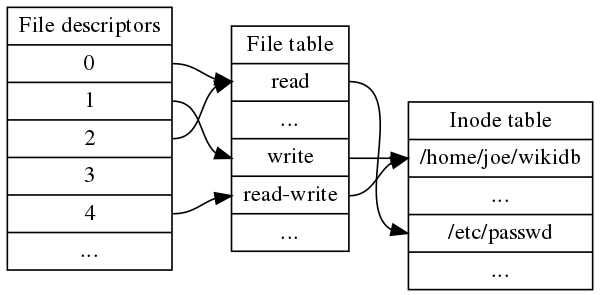
File Descriptor
File은 Metadata라는 정보를 가지고 있다. 이 정보는 이름, 식별자, 크기 권한 등을 가지고 있다.
이 파일을 2개 이상 프로세스에서 사용할 때 업데이트가 어떻게 이루어지는 지 알아보자.
프로세스가 2개 이상 만들어졌을 때, 파일의 Metadata를 모든 포르세스에 복사한다면 수정할 때마다 모든 프로세스에서 업데이트가 이루어져야 하니 비효율적이고 위험하다.
이를 해결하기 위해서 두 가지 자료구조가 필요하다.
- Inode struct: 파일마다 가지고 있는 하나의 고유번호이다. 이는 파일의 위치를 빠르게 찾을 수 있도록 indexing을 사용하여 동작한다. 그리고 이는 파일 정보(Metadata)도 가지고 있다.
- File sturct: Inode를 관리하는 구조체이다.
그렇다면 File Descriptor는 파일이 열리거나 생성될 때 이 파일들을 관리해주는 배열이라고 보면 된다.
모든 프로세스들은 각각의 File Descriptor를 이용하여 파일을 Open한다.
기본적으로 File Descriptor의 0,1,2는 프로그램이 실행될 때 할당된다.
이는 각각 Standard input, Standard output, Standard error이다.
Command with standard input
- wc: 줄, 단어, 바이트의 개수 또는 수를 출력한다.
- sort: 줄 단위로 입력값을 정렬한다.
- bc: 기본 계산
이와 같은 명령어와 file을 같이 사용할 수 있다.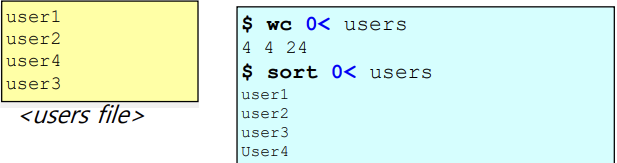
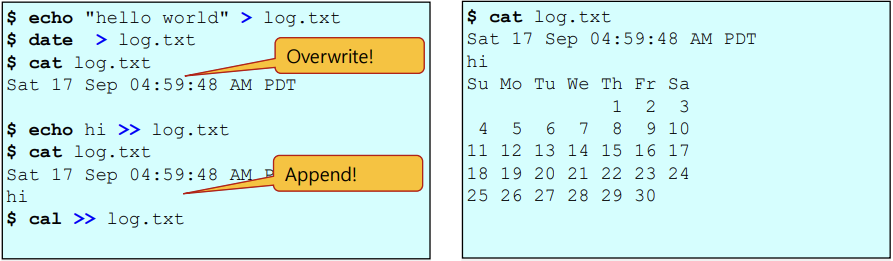
Command with standard output
- >: 입력 내용을 파일에 출력, 기존의 내용은 삭제된다.
- >>: 위와 다르게기존의 내용에 추가된다.
Command with standard error
- 2>: 에러 문구를 파일에 출력한다.
- &>: 에러 문구와 내용 모두 파일에 출력한다.
- &> /dev/null: /dev/null은 출력값을 버릴 때 사용한다.
이들을 조합하여 사용할 수 있다.
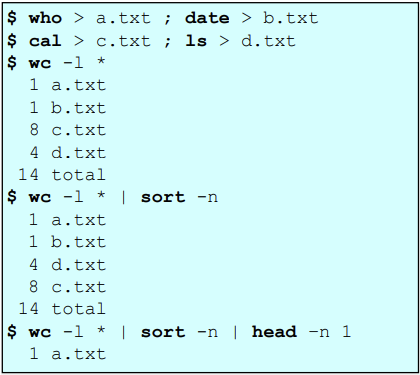
Pipe
Standard input를 나열하여 이 출력값들을 하나도 묶어준다.
command_1 | command_2 | command_3 형식으로 사용된다.
Filter
standard input으로 받은 것들 중에 원하는 것을 출력하게 하는 명령어.
standard input, output을 모두 사용하는 명령어들만 사용할 수 있다.
모두 받을 수 있는 명령어
cat, cut, awk, grep, wc, sort, bc, head
cut
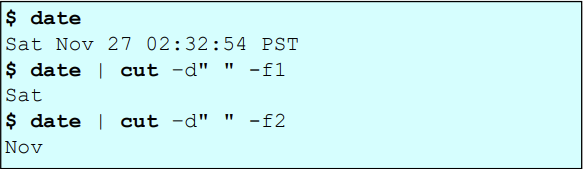
cut 명령어를 사용해 원하는 값만 출력한다.
delemeter로 ws를 지정하고 f1(1열)의 값을 출력
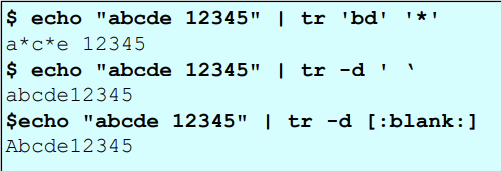
tr
문자열을 교체하거나 삭제한다.
Awk
Awk란 파일에서 데이타를 추출하여 출력하는 기능을 제공하는 명령어이다.
기능이 너무 많으니 예제로 알아보자
$ cat sample | awk ‘{print $1}’// 1열 출력
$ cat sample | awk ‘$3==0 {print $1}’// 3열이 0인 모든 행의 1열 출력
$ cat sample | awk ‘$3>0 {print $1, $2*$3}’// 3열이 양수인 모든 행의 {value}출력
- Built-in 변수로 NF와 NR을 가지고 있다.
- Fields: n 형식으로 사용된다 fields는 열이다.
printf format
- %c: char
- %d: decimal
- %o: unsigned octal(8)
