
작업을 하게 된 프로젝트는 MVVM 패턴으로 구성 되었으며
해당 프로젝트를 Clean Architecture로 리팩토링하는 작업 및 조사 & 이해 한 내용을 작성하였습니다.
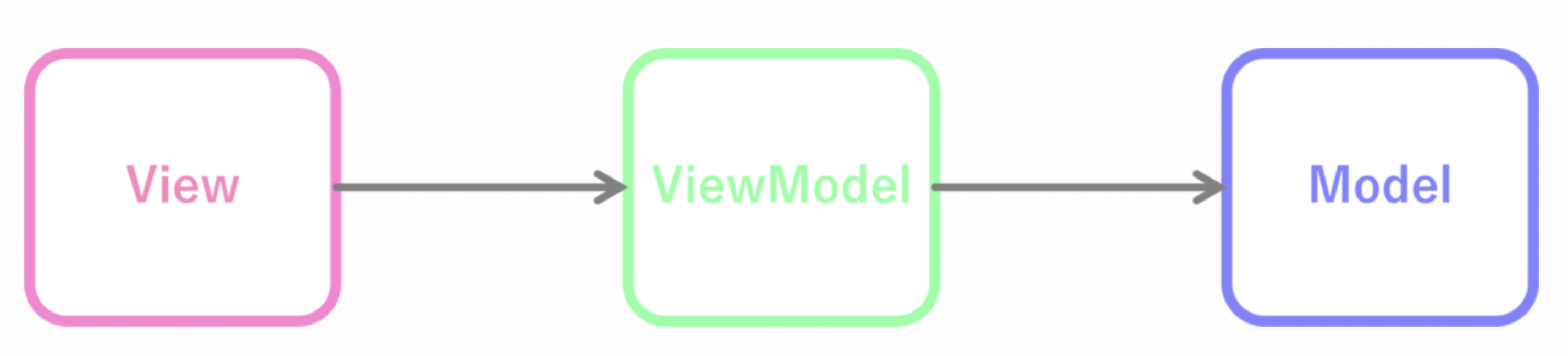
MVVM란?
Model - View - ViewModel 로 구성된 아키텍처 패턴으로 각 요소는 다음과 같은 역할을 담당
View
- Activity 및 Fragment는 View 역할을 수행
- 사용자의 액션(텍스트 입력, 버튼 클릭 등)을 수신
- ViewModel의 데이터를 관찰하여 UI를 업데이트
- 따라서 데이터의 변경 사항을 감지하고 자동으로 화면을 업데이트할 수 있음
ViewModel
- View가 요청한 데이터를 Model에 요청
- Model로부터 요청한 데이터를 수신
Model
- ViewModel이 요청한 데이터를 반환
- 데이터베이스 사용 또는 백엔드 API 호출을 통해 데이터를 가져옴 (Repository, Database 부분)
해당 프로젝트는 현재의 아키텍처 패턴을 사용하여 구성되어 있고 해당 부분을 Clean Architecture로 리팩토링을 하게 되었습니다.
📌 Clean Architecture
Clean Architecture로 리팩토링한것이 일이 얼마나 힘든 과정인지 작업을 하면서 더욱 알게 되었다.
- 변환과정에서 예상하지 못한 버그가 발생
- 개발이 아닌 리팩토링 작업을 위한 별도의 시간이 많이 필요함
구글에서 안드로이드 클린 아키텍처에 대해 찾아보면서, Domain layer가 Data layer를 알고 있는지 여부와 Data layer가 Domain layer를 알고 있는지 여부에 대해 서로 다른 글이 있었다.
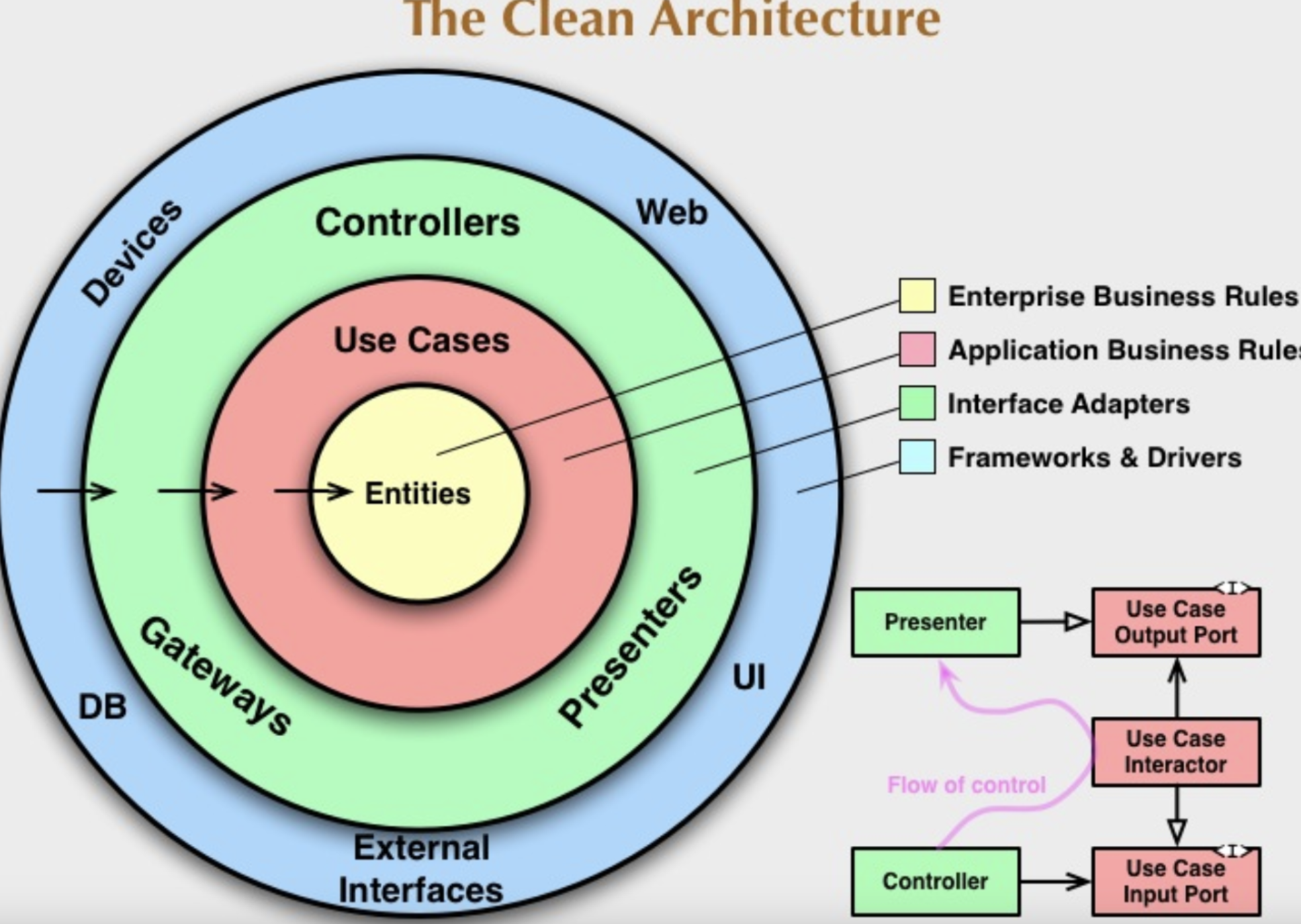
찾아 보니 이 부분은 로버트 C. 마틴의 클린 아키텍처와 Google의 앱 아키텍처 두 가지로 나뉘어 진다는 것을 알게 되었고 일반적으로 검색해서 찾는 이미지의 클린 아키텍처 구조는 로버트 C. 마틴의 클린 아키텍처였다.
로버트 C. 마틴의 클린 아키텍처 구조
로버트 C. 마틴의 클린 아키텍처는
- Presentation layer는 Domain layer를 알고 있지만,
- Domain layer는 Data layer를 알지 못하며,
- Data layer는 Domain layer를 알고 있는 형태
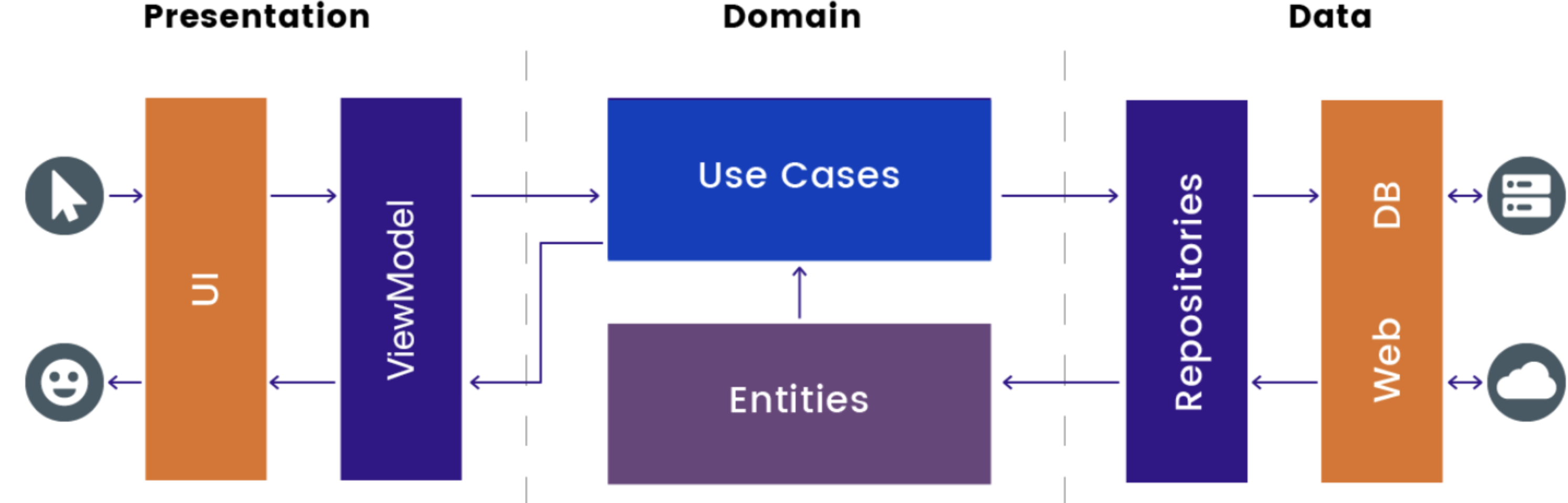
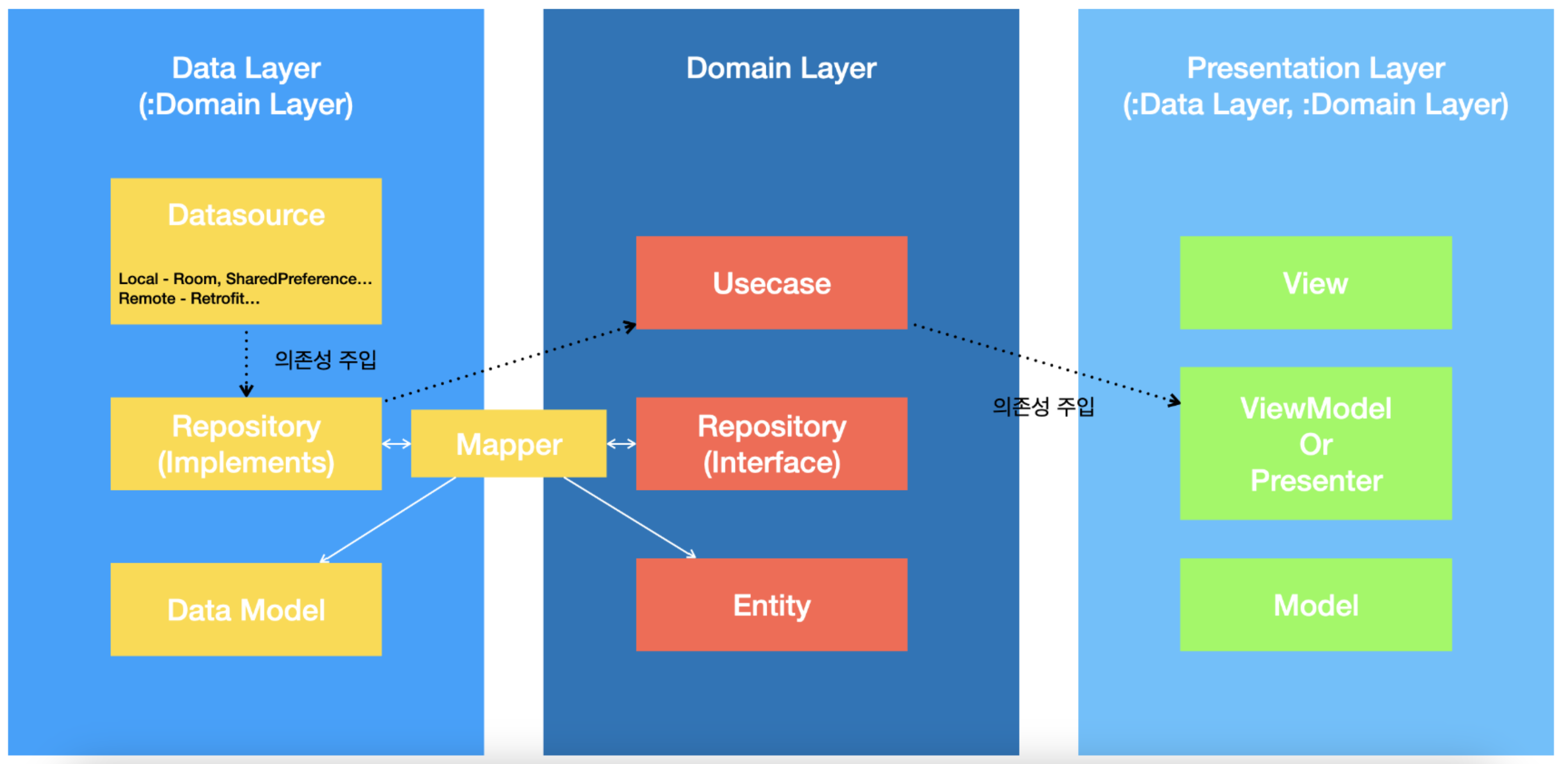
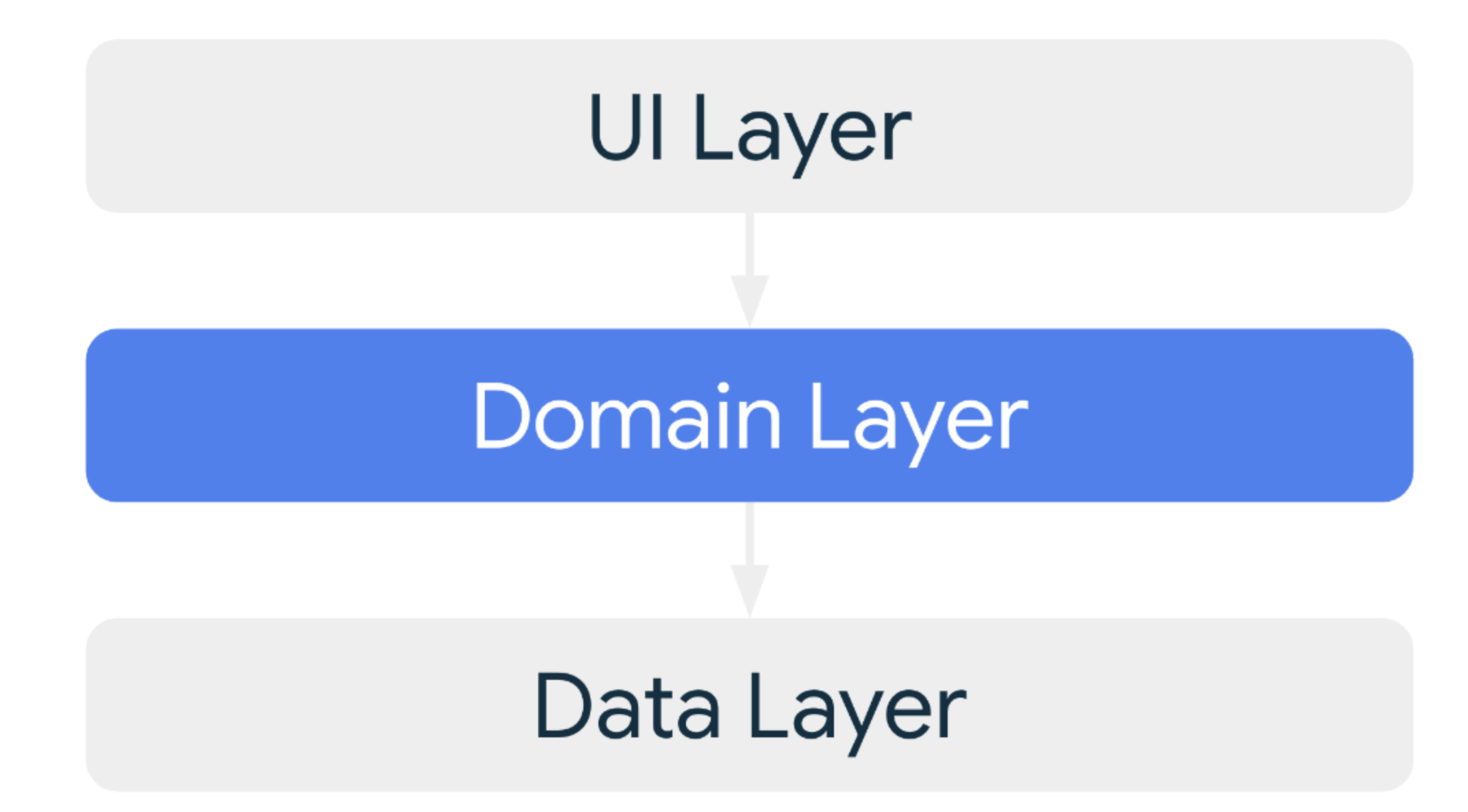
Google의 앱 아키텍쳐
Google의 안드로이드 문서에서 소개되고 있는 앱 아키텍쳐는 클린 아키텍쳐가 아니였고 Google의 앱아키텍쳐에서는 ‘domain layer가 data layer를 알고 있다’는 개념으로 시작
📌 폴더 구조
- 작업 한 프로젝트의 폴더 구성은 이런식으로 작성
🔖
.
├── dataModule
│ │
│ ├── api
│ │
│ ├── db
│ │ ├── AppDatabase
│ │ └── Dao
│ │
│ ├── model
│ │ ├── ModelEntity
│ │ └── Mapper
│ │
│ └── repository
│ └── RepositoryImpl
│
│
├── domainModule
│ │
│ ├── model
│ │ └── Model
│ │
│ ├── repository
│ │ └── Repository
│ │
│ └── usecase
│ └── Usecase
│
│
├── presentationModule
│ │
│ ├── di
│ │
│ ├── ui
│ │ ├── Adapter
│ │ ├── ViewModel
│ │ └── Fragment
│ │
│ └── util
│
.📌 코루틴?
코루틴은 Kotlin에서 비동기 프로그래밍을 쉽게 할 수 있도록 도와주는 도구. 코루틴을 사용하면 비동기 작업을 순차적으로 작성할 수 있어서 코드를 읽기 쉽고 이해하기 쉽게 만들 수 있습니다.
코루틴은 '경량 스레드'라고도 불리며, 이는 코루틴이 스레드와 동시에 실행될 수 있지만, 스레드에 비해 생성과 관리의 비용이 적기 때문. 코루틴을 사용하면 많은 수의 동시 작업을 효율적으로 처리할 수 있습니다.
코루틴을 시작하려면 launch 또는 async 같은 코루틴 빌더를 사용하고, 이 작업들은 특정CoroutineScope 내에서 실행됩니다. CoroutineScope는 코루틴의 생명주기를 결정하며, 모든 코루틴은 특정 CoroutineScope에 속합니다. launch 빌더는 결과를 반환하지 않는 작업에 주로 사용되며, async 빌더는 결과를 반환하는 작업에 사용됩니다. suspend 키워드는 해당 함수가 코루틴 또는 다른 suspend 함수 내에서만 호출될 수 있음을 나타냅니다. 이는 코루틴을 통해 실행되어야 하는 긴 작업을 표시하는 데 유용합니다.
Flow란?
코루틴의 Flow는 비동기 데이터 스트림
- 코루틴 flow는 코루틴 상에서 리액티브 프로그래밍을 지원하기 위해 만들어진 구현체
- 코루틴에서 데이터 스트림을 구현하기 위해서는 Flow를 사용해야한다
Reactive 리액티브 프로그래밍이란?
데이터가 변경될 때 이벤트를 발생시켜 데이터를 계속해서 전달한다.
명령형 : 사용자는 데이터를 요청하고 일회성으로 결과값을 수신데이터가 필요할 때 마다 결과값을 요청해야함 → 비효율적
반응형 : 데이터를 발행하는 주체가 있고 소비자는 구독을 함, 발행자는 새로운 데이터가 들어오면 소비자에서 지속적으로 발행
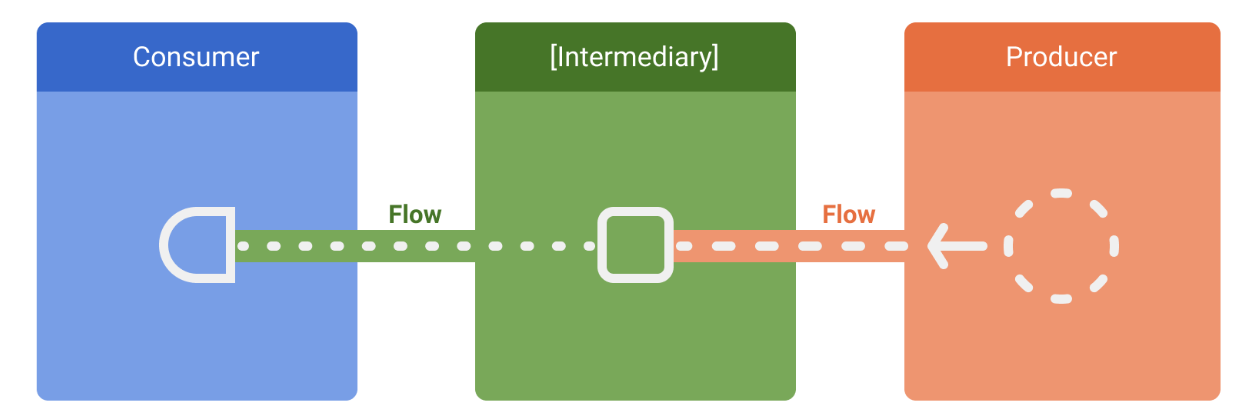
Flow의 데이터 핵심은 각 3가지로 구성
- 생산자 (Producer)
- 중간 연산자 (Intermediary)
- 소비자 (Consumer)
1. 생산자 (Producer)
- 생산자는 데이터를 발행하는 역활을 함
fun flowSomething(): Flow<Int> = flow { // flow 블록 선언
repeat(10) { // 숫자 반복
emit(Random.nextInt(0, 500)) // 랜덤 숫자 발행
delay(100L)
}
}2. 중간 연산자 (Intermediary)
생산자가 데이터를 생성했으면 중간 연사자는 데이터를 수정을 함.
a라는 객체를 발행 후, b라는 객체랑 둘을 바꿀 수가 있음
중간 연산자는 생산자 소비자 처럼 필수 요소는 아님
Flow에서 지원하는 대표 중간 연산자
- map (데이터 변형)
- filter (데이터 필터링)
- onEach (데이터 연산 수행)
fun main1() = runBlocking {
flowSomething().map {
"$it $it"
}.collect { value ->
println(value)
}
}
fun main2() = runBlocking {
(1..20).asFlow().filter {
(it % 2) == 0
}.collect {
println(it)
}
}3. 소비자 (Consumer)
중간 연산자가 생산자가 생성한 데이터를 변환 후 소비자에게 데이터를 전달
Flow에선 collect를 이용해 데이터를 전달하고 소비함
하지만 collect는 여러 이벤트에서 사용 불가이며 여러 이벤트를 사용 할 수 있는 launchIn을 선호
- 소비자는 UI를 나타내며 ViewModel에서 필요한 처리를 view에서 나타내는 것
fun events(): Flow<Int> = (1..3).asFlow().onEach { delay(100) }
fun main() = runBlocking {
events()
.onEach { events -> println("Event: $events") }
.collect() // 여러 이벤트에 사용 불가 ui,네트워크 호출 등등
println("Done")
}fun readDateDatas(date: String) {
viewModelScope.launch {
repository.readDateData(date).collect {
readDateData ->
}
}
}📌 코루틴을 클린 아키텍처에 적용하는 경우, 구조 설계는 크게 다음과 같이 이루어질 수 있음
-
Domain Layer
Domain Layer는 UseCase 또는 Interactor 정의하는 곳.
이 계층에서는 비즈니스 로직을 비동기적으로 실행하기 위해 코루틴을 사용할 수 있고 UseCase 또는 Interactor 코루틴 빌더인
suspend함수를 사용할 수 있습니다.class GetExampleDataUseCase(private val exampleRepository: ExampleRepository) { suspend operator fun invoke(): Result<ExampleData> { return exampleRepository.getExampleData() } }여기서,
Result는 성공 또는 실패의 상태를 나타내는 래퍼 클래스입니다. 이 클래스는 코루틴이 완료되면 반환
-
Data Layer
Data Layer는 Repository와 Data Source를 정의하는 곳입니다.
이 계층에서도 코루틴을 사용하여 네트워크 요청, 데이터베이스 액세스 등을 비동기로 처리할 수 있습니다.
class ExampleRepositoryImpl(private val dataSource: ExampleDataSource) : ExampleRepository { override suspend fun getExampleData(): Result<ExampleData> { return dataSource.fetchData() } }Data Source에서 데이터를 가져올 때도
suspend키워드를 사용하여 비동기로 실행할 수 있습니다.
-
Presentation Layer (ViewModel)
Presentation Layer는 사용자 인터페이스를 구현하는 곳입니다.
이 계층에서는 ViewModel을 사용하여 View와 Domain Layer 간의 상호작용을 관리합니다. ViewModel에서는
viewModelScope를 사용하여 코루틴을 실행합니다. 이는 ViewModel의 생명주기에 연결되어, ViewModel이 정리되면 자동으로 코루틴도 취소됩니다.class ExampleViewModel(private val getExampleDataUseCase : GetExampleDataUseCase) : ViewModel() { val exampleData = MutableLiveData<Result<ExampleData>>() fun loadExampleData() { viewModelScope.launch { val result = getExampleDataUseCase() exampleData.value = result } } }viewModelScope.launch는 코루틴을 시작하는 코루틴 빌더.loadExampleData는 ViewModel에서 View로 데이터를 로드하는 함수입니다. 이 함수는 사용자 인터페이스에서 호출할 수 있으며, 이를 통해 비즈니스 로직을 비동기로 실행하고 결과를 UI에 업데이트할 수 있습니다.이와 같이 코루틴을 사용하면, 클린 아키텍처를 유지하면서도 쉽게 비동기 로직을 구현할 수 있습니다.
📌 해당 클린아키텍처의 내용과 코루틴의 내용을 토대로 프로젝트를 클린아키텍쳐로 리팩토링하여 작성한 것을 일부만 예시
Data 모듈
-
KeywordDao: DAO를 통해 데이터베이스에 접근하고 쿼리를 수행합니다. 메인 스레드에서 DB 작업을 수행하면서 UI가 멈추는 것을 방지할 수 있습니다.
- Dao (데이터 접근 객체): 데이터베이스와 직접적으로 소통하며, 데이터를 저장하고 조회하는 역할을 합니다.
@Dao interface KeywordDao @Query("SELECT * FROM keywords ORDER BY `order` DESC") fun findAll(): Flow<List<KeywordEntity>> } -
Entity : 의 핵심 로직을 나타내며, 이 경우는 키워드에 대한 데이터를 담당
@Entity(tableName = "keywords") data class KeywordEntity( @PrimaryKey(autoGenerate = true) val id: Long = 0, val value: String = "", val order: Long = 0, ) -
KeywordEntityMapper :
이 클래스의 메서드들은
KeywordEntity객체를Keyword객체로 변환하거나(mapFromEntity),Keyword객체를KeywordEntity객체로 변환합니다(mapToEntity).KeywordEntityMapper는 애플리케이션의 다양한 레이어 사이에서 도메인 모델의 무결성을 유지하고,
각 레이어가 서로 독립적으로 유지되도록 도와주는 역할을 합니다.class KeywordEntityMapper { fun mapFromEntity(entity: KeywordEntity): Keyword { return Keyword( id = entity.id, value = entity.value, order = entity.order, ) } fun mapToEntity(domainModel: Keyword): KeywordEntity { return KeywordEntity( id = domainModel.id, value = domainModel.value, order = domainModel.order, ) } } -
KeywordRepositoryImpl : Repository는 데이터를 가져오는 역할을 수행하며, 보통 네트워크와 로컬 데이터베이스 사이의 중간 계층 역할을 합니다.
- Repository : Dao 또는 다른 데이터 소스 (예를 들어, 웹 서비스 등)를 활용하여 필요한 데이터를 가져오거나 업데이트하는 역할을 합니다.
class KeywordRepositoryImpl @Inject constructor( private val keywordDao: KeywordDao, private val keywordEntityMapper: KeywordEntityMapper, private val api: Api ) : KeywordRepository { override fun fetchNewsList(keyword: String, page: Int ): Flow<NewsList> = flow { val response = api.keywordNews(keyword, page) if (response.isSuccessful) { response.body()?.let { val newsList = it.toNewsList() emit(newsList) } ?: throw RuntimeException("API Response body is null") } else { throw RuntimeException( "API Response Error: ${response.errorBo()?.string()}") } } override fun fetchKeywordList(): Flow<List<Keyword>> { return keywordDao.findAll().map { it.map(keywordEntityMapper::mapFromEntity) } } }
DoMain 모듈
-
KeywordRepository : 애플리케이션의 다른 부분에서 데이터에 접근할 때 사용되는 메서드들을 정의합니다. 이 인터페이스를 구현한 클래스는 데이터를 가져오거나 데이터를 변경하는 등의 작업을 수행합니다.
interface KeywordRepository { fun fetchKeywordList(): Flow<List<Keyword>> fun fetchNewsList(keyword: String, page: Int): Flow<NewsList> } -
UseCase : UseCase는 특정 작업을 수행하기 위한 시나리오를 담당하며
Repository에 의존하며,
suspend operator fun invoke메서드를 통해 호출되며, 이는 코루틴이 사용되어 비동기 작업을 동기 작업처럼 쉽게 처리할 수 있도록 도와줍니다. 즉,invoke메서드를 통해 Use Case를 함수처럼 호출하면, 내부적으로는 비동기적으로 작업을 처리하고 결과를 반환하게 됩니다.data class Keyword( val id: Long = 0, val value: String = "", val order: Long = 0, ) data class KeywordList( val keywordList: List<Keyword>, val categoryList: List<Category>, val categoryCount: Int, val categoryMaxCount: Int )class FetchKeywordListUseCase @Inject constructor( private val keywordRepository: KeywordRepository ) { suspend operator fun invoke(): Flow<List<Keyword>> { return keywordRepository.fetchKeywordList() } } class FetchKeywordNewsListUseCase @Inject constructor( private val keywordRepository: KeywordRepository ) { suspend operator fun invoke(keyword: String, page: Int) : Flow<NewsList> { return keywordRepository.fetchNewsList(keyword, page) } }
Presentation 모듈
- SearchViewModel : UseCase를 통해 데이터를 가져오고, 이를 LiveData나 Flow로 래핑하여 UI에 바인딩할 수 있도록 합니다.
fetchKeywordList()함수에서viewModelScope.launch를 사용하여 코루틴을 시작하고,fetchKeywordListUseCase()의 결과를keywords라는 LiveData에 저장. 이는 UI가 이 LiveData를 관찰하고 있기 때문에, 데이터가 변경되면 UI도 자동으로 업데이트
@HiltViewModel
class SearchViewModel @Inject constructor(
private val fetchKeywordListUseCase: FetchKeywordListUseCase,
private val fetchCategoryListUseCase: FetchCategoryListUseCase,
private val fetchKeywordNewsListUseCase: FetchKeywordNewsListUseCase
) : ViewModel() {
val keyword = MutableLiveData("")
val keywords = MutableLiveData<KeywordList>()
val news = MutableLiveData<List<News>>(emptyList())
private var lastPage = 1
fun fetchKeywordList() {
viewModelScope.launch {
fetchKeywordListUseCase()
.flatMapLatest { keywords ->
fetchCategoryListUseCase(onlyUser = true)
.map { KeywordList(keywords, it, it.size,
CATEGORY_MAX_COUNT) }
}
.flowOn(Dispatchers.IO)
.catch { }
.collect { keywords.value = it }
}
}
fun fetchNews(keyword: String, page: Int = 1) {
if (keyword.isBlank()) return
if (keyword != this.keyword.value) {
this.news.value = emptyList()
}
viewModelScope.launch {
fetchKeywordNewsListUseCase(keyword, page)
.flatMapLatest { news ->
fetchCategoryListUseCase(onlyUser = true)
.map { Pair(news, it) }
}
.take(1)
.flowOn(Dispatchers.IO)
.catch {}
.collect {}
this@SearchViewModel.keyword.value = keyword
}
}
companion object {
const val CATEGORY_MAX_COUNT = 3
}
}이렇게 각각의 컴포넌트들은 역할에 따라 나눠져 있으며, ViewModel을 통해 연결되어 사용자 인터페이스와 상호작용. 이는 각 컴포넌트가 서로에게서 독립적으로 작동할 수 있게 하며, 이는 유지보수성과 테스트 용이성을 향상시킵니다.
📌 마무리
클린 아키텍처의 원형만 살펴보고 인강으로 들으면서 공부도 좋았지만 이렇게 직접적으로 리팩토링을 하면서 이해가 더 잘 됐던 것 같다.
아직은 부족한 부분도 수정해야할 부분도 많지만,
더욱 더 안드로이드 및 코틀린 공부에 더욱 전념 해야겠다고 생각하게 되었다.

어떤 강의 들으셧나요??