2020년 6월 10일, 인라이플 언어모델 튜닝대회의 설명회에 참석했다. 버트를 이론적으로 잘 이해했다고 생각했으므로, 대회에서 짧은 시간 안에 좋은 결과를 얻는 것은 불가능할 것이라 생각했다. 그러나 대회에서 한국어 언어모델 학습을 다루고 있었기 때문에, 그에 대한 관심을 가지고 설명회에 참석했다. 솔직히 말해서 귀찮기도 했다. 설명회날 비도 내리고, 설명회장까지 거리도 멀었던 데다 큰 기대를 품지 않았던 탓이다. 그럼에도 불구하고, 기대했던 것보다 설명회에서 얻은 성과가 커서 그에 관해 몇자 적어 볼까 한다.
인라이플배 한국어 AI 언어모델 튜닝대회: https://challenge.enliple.com/
설명회에 도착해서 인라이플 인공지능 연구소장님의 대회 취지를 듣는 동안, Nvidia DGX를 두 대나 보유하고 있다는 말씀에 정말 부러웠고, 대형 언어 모델 구축이 가능한 것을 이해할 수 있었다. 무엇보다 중소기업이 구축한 언어모델을 일반에게 공개하고, 챌린지를 통해 활용 방법을 공유하려는 취지에 놀랐다. 아래에 내가 이해한 버트 모델과 대회 참가 후기를 간략히 작성했다.
BERT 모델이란?
버트 언어 모델은 자연어처리 분야에서 혜성같이 등장해, 인공지능 분야에 새로운 지평을 열었다. 단순한 알고리즘으로 다양한 테스크에 적용이 가능하여 그 활용성이 매우 높았다. NLP 연구 동향에서, 2018년이 ELMO 언어 모델의 해였다고 한다면, 2019년 이후부터는 BERT 언어 모델의 해라고 해도 과언이 아니다. 실제로, BERT 언어 모델은 NLP챌린지의 거의 모든 분야에서 SOTA(State-of-the-art)를 찍고 있다. 버트를 이해하기 위해서는, 먼저 트랜스포머 구조를 잘 이해해야 한다. 버트가 트랜스포머 신경망 아키텍처를 기반으로 하고 있기 때문이다. 트랜스포머 아키텍처의 핵심은, 셀프어텐션 메커니즘을 적용해 각 토큰이 서로의 유사도를 반영하여 모델링할 수 있다는 데 있다. 버트는, 이러한 트랜스포머 인코더의 구조를 그대로 가져와서 아래의 그림과 같이 양방향 언어모델을 구축하는 시도라고 볼 수 있다.
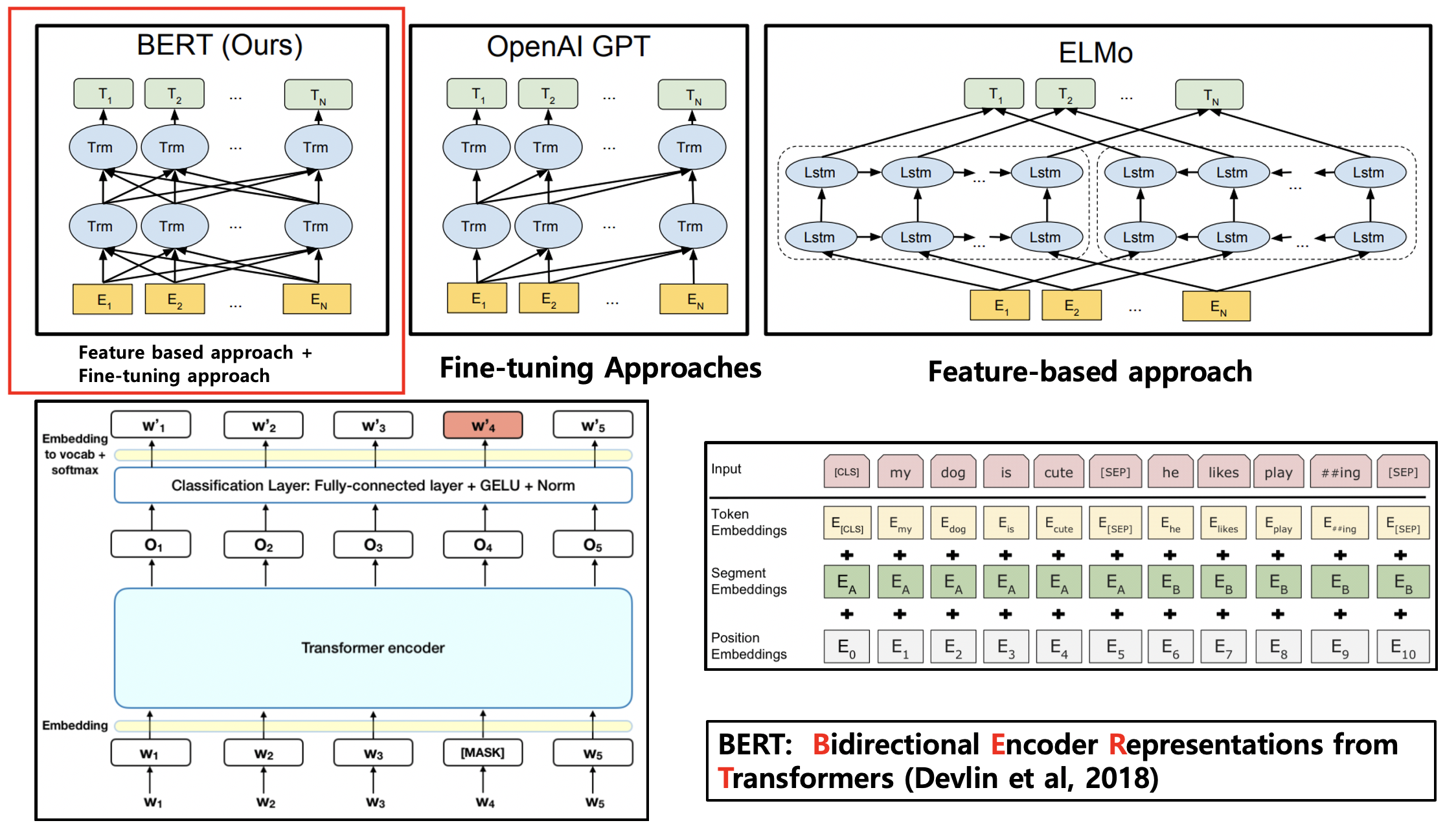
BERT 모델의 novelty는?
BERT 모델의 novelty는 마스킹된 언어 모델링으로 문장에서 마스킹된 부분을 예측하여 해당 토큰의 양방향 문맥 정보를 얻으려는 시도에 있다. 기존 contextual word embedding 방식의 선구자인 ELMO에 비해 BERT는 feature-based 방식뿐 아니라 fine-tuning 방식으로 적용이 가능한 PLM(Pre-trained Language Model)이라는 장점이 있다. 버트 논문이 기여하는 바는, 이러한 대용량 사전학습 모델을 메타 학습 차원에서 다양한 테스크에 적용할 수 있는 범용 전이학습 모델 개발이라는 데 있다. 다만, 버트가 다음 문장을 예측하는 NSP 학습은 지극히 단순한 태스크이므로, 이후 다른 연구에서 성능에 큰 영향이 없다고 판단하여 이를 적용하지 않은 사례도 있었다.
KorQuAD challenge란?
KorQuAD는 Stanford Question Answering Dataset(SQuAD)과 동일한 방식으로 구성하였다. v1.0의 경우 위키백과에서 1,637건의 문서를 수집해서, 크라우드소싱으로 QA70K를 생성(LG-CNS)하였다. KorQuAD는 한국어 기계독해를 위해 만든 데이터셋으로, 질의응답 응용에 적용할 수 있다. KorQuAD 2.0은 KorQuAD 1.0에서 질문답변 20,000+ 쌍을 포함하여 총 100,000+ 쌍으로 구성된다. KorQuAD 1.0과는 다르게 1~2 문단이 아닌 Wikipedia article 전체에서 답을 찾아야 하고, 다양한 표·리스트·HTML 구조를 이해해야 하는 복잡한 태스크이다. KorQuAD 챌린지는 이러한 데이터셋을 기반으로 질의에 대한 답변의 정확도(EM) 및 F1 점수를 측정하여 순위를 정한다. https://korquad.github.io/
KorQuAD challenge의 참가는?
인라이플 설명회에서 버트의 개념에 대한 설명을 코드에 기반하여 들을 수 있었다. 또한, 구글 CoLab 사용법과 CodaLab을 사용하여 챌린지 자료를 업로드하고, 자체 모델의 성능을 테스트하는 방법 역시 들을 수 있었다. CoLab과 CodaLab에 대한 설명은 당시에 선뜻 이해되지 않았지만, 매뉴얼이 잘 작성되어 있어 그대로 따라해 보기도 했다. 대회의 마감 시간이 임박하였으므로, 아래와 같이 몇가지 시도만 해 보았다. (설명회 발표자료)
- 구글 CoLab은 소형 모델로 미세조정 학습이 가능하고, 총 4시간 가량 학습하면, KorquAD v1.0 베이스라인 이상의 성능을 낼 수 있다.
- 구글 CoLab은 하루 12시간만 이용할 수 있는 등 사용의 제한이 있고, 이를 여러 번 사용할 경우, 일정 시간 동안 GPU를 사용할 수 없으므로, 로컬 GPU가 없으면 계획적으로 준비하여 학습을 하는 것이 바람직하다.
- 초기화 값이 랜덤하게 설정되므로 학습 후 결과에 미세한 차이가 있을 수 있다. 따라서, 같은 학습 조건이라도 성능에 미미한 차이가 있을 수 있으므로 여러 번 학습해 보아야 한다.
- 하이퍼파라미터 값(학습 배치사이즈 등)을 변경하여 시도해 보고, 다양한 결과를 도출해 보았다. 그 결과, 인라이플에서 제공한 하이퍼파라미터 값이 소형 모델에서 가장 높은 성능을 냈다.
max_seq_length: 512
doc_stride: 128
max_query_length: 96
max_answer_length: 30
n_best_size: 20
train_batch_size: 16
learning_rate: 5e-5
warmup_proportion: 0.1
num_train_epochs: 10.0
max_grad_norm: 1.0
adam_epsilon: 1e-6
weight_decay: 0.01
- 학습에 사용된 pytorch 기반의 코드는 인라이플에서 제공한 코드이다. 구글 코랩에서 단일 GPU를 사용할 때 pytorch 기반의 코드를 이용하는 것이 적합하고, Multi-GPUs를 사용하는 경우에는 일부 코드를 변경해야 한다.(공유 코드)
인라이플 대형 언어모델 활용 시 메모리 오류가 있다면(인라이플 AI연구소의 답변)
빅모델의 로컬학습 시 메모리 오류 문제를 해결할 수 있는 학습 방법은?
- 가장 쉽게 시도할 수 있는 방법은 GPU를 사용하지 않고 CPU를 사용하는 방법이다.
물론, 연산 시간이 많이 걸린다는 단점이 있기는 하지만 실행 여부를 확인해 볼 수 있다.- 가능한 한, 배치 사이즈를 gpu당 1로 낮춰 파인튜닝 하는 방법이 있을 것 같다.
공개해 드린 모델 src 폴더의 run_qa.py 파일에서 --per_gpu_train_batch_size를 1로 변경해 보자.
parser.add_argument("--per_gpu_train_batch_size", default=16, type=int ...- 위의 방법을 적용하기 어렵다면, max_seq_length를 512에서 384로 더 낮추는 방법도 있다.
토큰을 낮춘 만큼 메모리 사용량은 많이 줄지만, 그만큼 볼 수 있는 토큰이 줄어 든다.
위와 동일한 파일에서 --max_seq_length를 384로 변경해 보자.
parser.add_argument("--max_seq_length", default=512, type=int, ...
참가 후기 및 앞으로의 계획
- 자연어처리 및 버트에 대한 지식이 없더라도 위에서 공유한 매뉴얼과 인라이플 소형 모델을 활용하여 4시간 정도만 투자한다면 KorQuAD v1.0 리더보드에 이름을 올릴 수 있다.
- 앞으로 인라이플 소형 모델을 활용하여 공격적인 댓글을 필터링하는 기술을 개발하고 싶다. 공격적인 댓글 5만 문장을 레이블링 하고, 그 가능성이 확인된다면 인라이플의 대형 모델도 적용해 볼 계획이다.

아쉽네요~ 미리 알았으면 저도 한번 참여해 보는거였는데.. 학습시킬때 GPU메모리는 얼마정도면 충분할까요?