집계 함수
여러 행의 값을 기반으로 계산된 단일 결과 값을 반환하는 함수
이러한 함수는 일반적으로 GROUP BY 절과 함께 사용되어 데이터를 그룹화하고 각 그룹에 대한 요약 정보를 제공하는 데 사용
주요 집계 함수
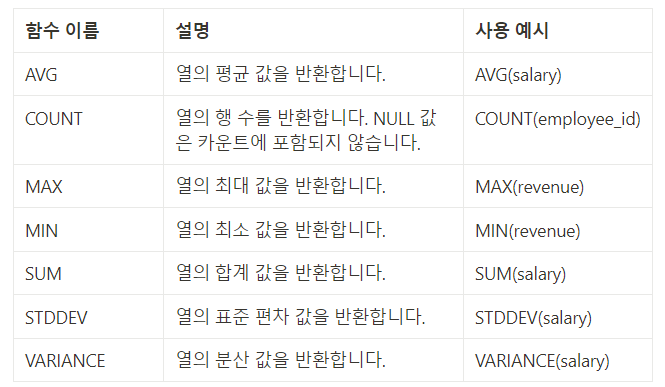
-> 집계 함수는 주로 SELECT 문의 SELECT 절과 GROUP BY 절에서 사용
집계함수에서 null처리
AVG(): NULL 값을 무시하고 평균 계산. NULL 값은 분모에서 제외COUNT(): NULL 값을 카운트 X
단,COUNT(*)의 경우는 행의 수를 카운트하므로 NULL 값이 있는 열이라도 카운트 OMAX()및MIN(): NULL 값을 무시하고 최대값 또는 최소값을 계산SUM(): NULL 값을 무시하고 합계를 계산. NULL 값은 0으로 간주되어 합계에 영향을 주지 않음STDDEV()및VARIANCE(): NULL 값을 무시하고 표준 편차 또는 분산을 계산
->COUNT(*)만 주의 !!!!
Group-by절
특정 열(들)의 값에 따라 그룹화하는 데 사용
- 부서별로 그룹화하여 부서별 직원수, 부서별 평균 급여 계산
SELECT
department_id,
COUNT(employee_id) AS employee_count,
AVG(salary) AS average_salary
FROM
employees
GROUP BY
department_id;
HAVING 절
그룹화된 결과에서 특정 조건을 만족하는 그룹만을 필터링
즉, 집계 후 필터링
- WHERE절은 집계 전 필터링
SELECT
department_id,
COUNT(employee_id) AS employee_count,
AVG(salary) AS average_salary
FROM
employees
GROUP BY
department_id
HAVING
COUNT(employee_id) >= 5;- 각 부서별로 직원 수가 5명 이상인 부서의 직원 수와 평균 급여를 계산할 때 그룹화를 진행하고 나서 필터링하므로 HAVING 절을 사용하여 직원 수가 5명 이상인 그룹만을 필터
실습
SELECT * FROM tb_sal_his;
-- 집계 함수 (다중행 함수)
-- 여러 행을 묶어서 한 번에 함수를 적용
SELECT
COUNT(*) "지급 횟수",
SUM(pay_amt) "지급 총액",
AVG(pay_amt) "평균 지급액",
MAX(pay_amt) "최대 지급액",
MIN(pay_amt) "최소 지급액"
FROM tb_sal_his
;
SELECT
*
FROM tb_emp;
SELECT
COUNT(*)
FROM tb_emp;
SELECT
emp_nm
FROM tb_emp;
SELECT
COUNT(emp_nm)
FROM tb_emp;
SELECT
emp_nm
FROM tb_emp
WHERE emp_nm LIKE '김%'
;
SELECT
COUNT(emp_nm)
FROM tb_emp
WHERE emp_nm LIKE '김%'
;
SELECT
direct_manager_emp_no
FROM tb_emp
;
-- COUNT()는 null값 카운트 x
-- 단, COUNT(*)는 null값 카운트 o
SELECT
COUNT(direct_manager_emp_no)
FROM tb_emp
;
SELECT
COUNT(emp_no) "총 사원수",
MIN(birth_de) "최연장자 생일",
MAX(birth_de) "최연소자 생일"
FROM tb_emp
;
-- 부서별로 사원수가 몇명인지
-- 부서별로 최연장자의 생일은 언젠지?
-- GROUP BY : 저장된 컬럼으로 소그룹화 한 후
-- 각 그룹별로 집계함수를 각각 적용
SELECT
emp_no,
emp_nm,
birth_de,
dept_cd
FROM tb_emp
ORDER BY dept_cd
;
SELECT
COUNT(*) "부서별 사원수",
MIN(birth_de) "부서별 최연장자 생일",
MAX(birth_de) "부서별 최연소자 생일"
FROM tb_emp
GROUP BY dept_cd
;
SELECT
*
FROM tb_sal_his
ORDER BY emp_no
;
SELECT
emp_no,
TO_CHAR(SUM(pay_amt), 'L999,999,999'),
TO_CHAR(AVG(pay_amt), 'L999,999,999'),
MAX(pay_amt),
COUNT(pay_de)
FROM tb_sal_his
GROUP BY emp_no
ORDER BY emp_no
;
SELECT
emp_no,
emp_nm,
dept_cd
-- COUNT(*)
FROM tb_emp
;
-- GROUP BY절에 사용한 컬럼만
-- SELECT에서 직접조회 가능
SELECT
emp_no,
addr,
COUNT(*)
FROM tb_emp
GROUP BY emp_no, addr
;
SELECT
dept_cd,
sex_cd,
COUNT(*),
MAX(birth_de)
FROM tb_emp
GROUP BY dept_cd, sex_cd -- 부서별로 성별로 그룹핑
ORDER BY dept_cd
;
-- 사원별로 2019년에 급여 평균액과
-- 최소지급액, 최대지급액 조회
-- WHERE : 집계 전 필터링
SELECT
emp_no,
TO_CHAR(SUM(pay_amt), 'L999,999,999') "사원별 총급여액",
TO_CHAR(ROUND(AVG(pay_amt), 2), 'L999,999,999.99') "사원별 평균급여액",
TO_CHAR(MAX(pay_amt), 'L999,999,999') "사원별 최고급여액",
COUNT(pay_de) "급여 수령횟수"
FROM tb_sal_his
WHERE pay_de BETWEEN '20190101' AND '20191231' -- 2019
GROUP BY emp_no
ORDER BY emp_no
;
-- HAVING : 집계 후 필터링
SELECT
emp_no,
TO_CHAR(SUM(pay_amt), 'L999,999,999') "사원별 총급여액",
TO_CHAR(ROUND(AVG(pay_amt), 2), 'L999,999,999.99') "사원별 평균급여액",
TO_CHAR(MAX(pay_amt), 'L999,999,999') "사원별 최고급여액",
COUNT(pay_de) "급여 수령횟수"
FROM tb_sal_his
WHERE pay_de BETWEEN '20190101' AND '20191231' -- 2019
GROUP BY emp_no
HAVING AVG(pay_amt) >= 4000000
ORDER BY emp_no
;
— 부서별로 가장 어린사람의 생년월일, 연장자의 생년월일, 부서별 총 사원 수를 조회
— 그런데 부서별 사원이 1명인 부서의 정보는 조회하고 싶지 않음.
-- 부서별 사원이 1명인 부서의 정보는 집계 후 필터링 (HAVING)
SELECT
dept_cd,
MAX(birth_de),
MIN(birth_de),
COUNT(emp_no) cnt
FROM tb_emp
GROUP BY dept_cd
HAVING COUNT(emp_no) > 1
ORDER BY dept_cd
-- ORDER BY : 정렬
-- ASC : 오름차 정렬 (기본값), DESC : 내림차 정렬
-- 항상 SELECT절의 맨 마지막에 위치
SELECT
emp_no
, emp_nm
, addr
FROM tb_emp
ORDER BY emp_no
;
SELECT
emp_no
, emp_nm
, addr
FROM tb_emp
ORDER BY emp_nm ASC
;
SELECT
emp_no
, emp_nm
, dept_cd
FROM tb_emp
ORDER BY dept_cd, emp_nm DESC -- dept_cd에는 ASC생략
;
-- dept_cd 오름차 정렬 먼저 한 후에 emp_nm 내림차 정렬 진행
SELECT
emp_no AS 사번
, emp_nm AS 이름
, addr AS 주소
FROM tb_emp
ORDER BY 이름 DESC
;
SELECT
emp_no
, emp_nm
, dept_cd
FROM tb_emp
ORDER BY 3 ASC, 1 DESC -- dept_cd : 3번째, emp_no: 1번째
;
SELECT
emp_no
, emp_nm
, dept_cd
FROM tb_emp
ORDER BY 3 ASC, emp_no DESC
;
SELECT emp_no AS 사번, emp_nm AS 이름, addr AS 주소
FROM tb_emp
ORDER BY 이름, 1 DESC -- 이름 ASC
;
SELECT
emp_no
, SUM(pay_amt) 연봉
FROM tb_sal_his
WHERE pay_de BETWEEN '20190101' AND '20191231'
GROUP BY emp_no
HAVING AVG(pay_amt) >= 4500000
ORDER BY emp_no
;
SELECT
EMP_NM ,
DIRECT_MANAGER_EMP_NO
FROM TB_EMP
ORDER BY DIRECT_MANAGER_EMP_NO DESC
;
-- 사원별로 2019년 월평균 수령액이 450만원 이상인 사원의 사원번호와 2019년 연봉 조회
SELECT
emp_no
, SUM(pay_amt) 연봉
FROM tb_sal_his
WHERE pay_de BETWEEN '20190101' AND '20191231'
GROUP BY emp_no
HAVING AVG(pay_amt) >= 4500000
ORDER BY SUM(pay_amt) DESC
;연습 문제
-- 실습문제
-- 1. employees테이블에서 각 사원의 부서별 부서 번호(department_id)와
-- 평균 급여(salary)를 조회하세요.
-- 단, 부서번호가 null이면 0으로 변경하여 조회세요.
SELECT
NVL(department_id, 0) "부서별 부서번호",
AVG(salary) "평균 급여"
FROM employees
GROUP BY department_id
ORDER BY department_id
;
-- 2. employees테이블에서 부서별 부서 번호(department_id)와 부서별 총 사원 수를 조회하세요.
-- 단, 부서번호가 null이면 0으로 변경하여 조회세요.
SELECT
NVL(department_id, 0) AS dep_id
, COUNT(employee_id) AS total_count
FROM employees
GROUP BY department_id
ORDER BY dep_id
;
-- 3. employees테이블에서 부서의 급여 평균이 8000을 초과하는 부서의 부서번호와 급여 평균을 조회하세요.
SELECT
department_id,
ROUND(AVG(salary), 2) AS avg_sal
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 8000
ORDER BY department_id
;
-- 4. employees테이블에서 급여 평균이 8000을 초과하는 각 직무(job_id)에 대하여
— 직무 이름(job_id)이 SA로 시작하는 사원은 제외하고 직무 이름과 직무별 급여 평균을
— 급여 평균이 높은 순서로 정렬하여 조회하세요.
SELECT
job_id
, ROUND(AVG(salary), 2) AS avg_sal
FROM employees
WHERE job_id NOT LIKE 'SA%'
GROUP BY job_id
HAVING AVG(salary) > 8000
ORDER BY avg_sal DESC
;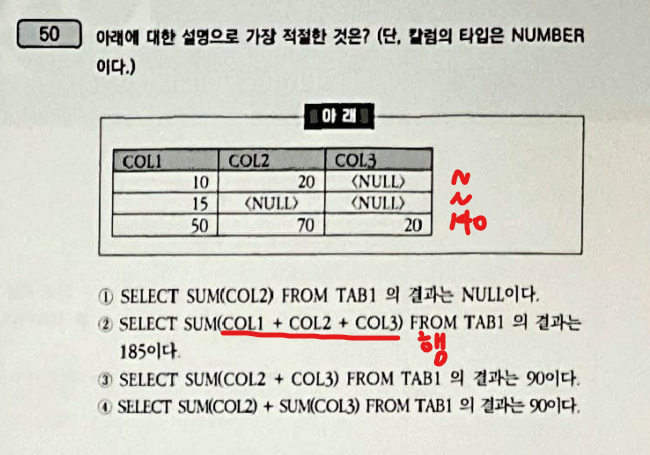
- SUM(COL2 + COL3) 와 SUM(COL2) + SUM(COL3) 의 차이점
- SUM(COL2 + COL3)는 COL2 + COL3를 먼저 진행, COL2 + COL3는 행으로 더하는 것인데 이 경우는 NULL이 껴있으면 NULL로 나옴
- SUM(COL2) + SUM(COL3)는 집계함수 메서드임 SUM()을 이용한 것으로 이 경우는 NULL이 빠짐
-> SUM(COL1 + COL2 + COL3) = 140
-> SUM(COL1) + SUM(COL2) + SUM(COL3) = 75 + 90 + 20 = 185

백엔드 개발자