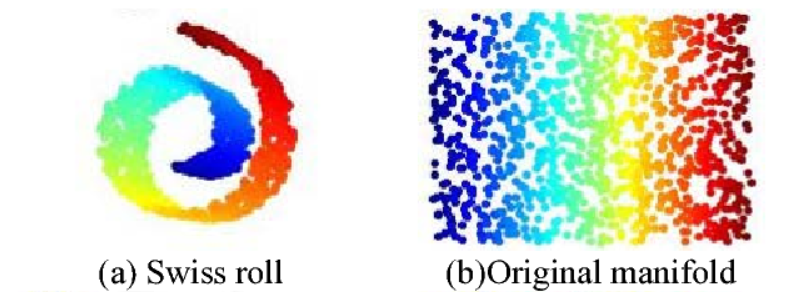
Manifold Learning
출처: https://www.analyticsvidhya.com/blog/2021/02/a-quick-introduction-to-manifold-learning/
- 고차원 데이터를 저차원 데이터로 차원을 축소하여 표현하는 것
- sample을 모두 error없이 가져가는 subspace가 있을 것이다.
- Used for
- Data Compression
- Data Visualization
- Curse of Dimensionality(차원의 저주)
- 차원이 증가할수록 해당 공간의 크기가 기하급수적으로 증가하기 때문에 동일한 개수의 데이터 밀도는 차원이 증가할수록 급속도로 희박해짐
- 차원이 증가할수록 필요한 샘플 데이터의 개수가 기하급수적으로 증가
- Discoviering Most Important Features
- 실제(고차원)로는 거리가 가까운 애들도 manifold(저차원)상에서는 멀게 표현될 수 있다.
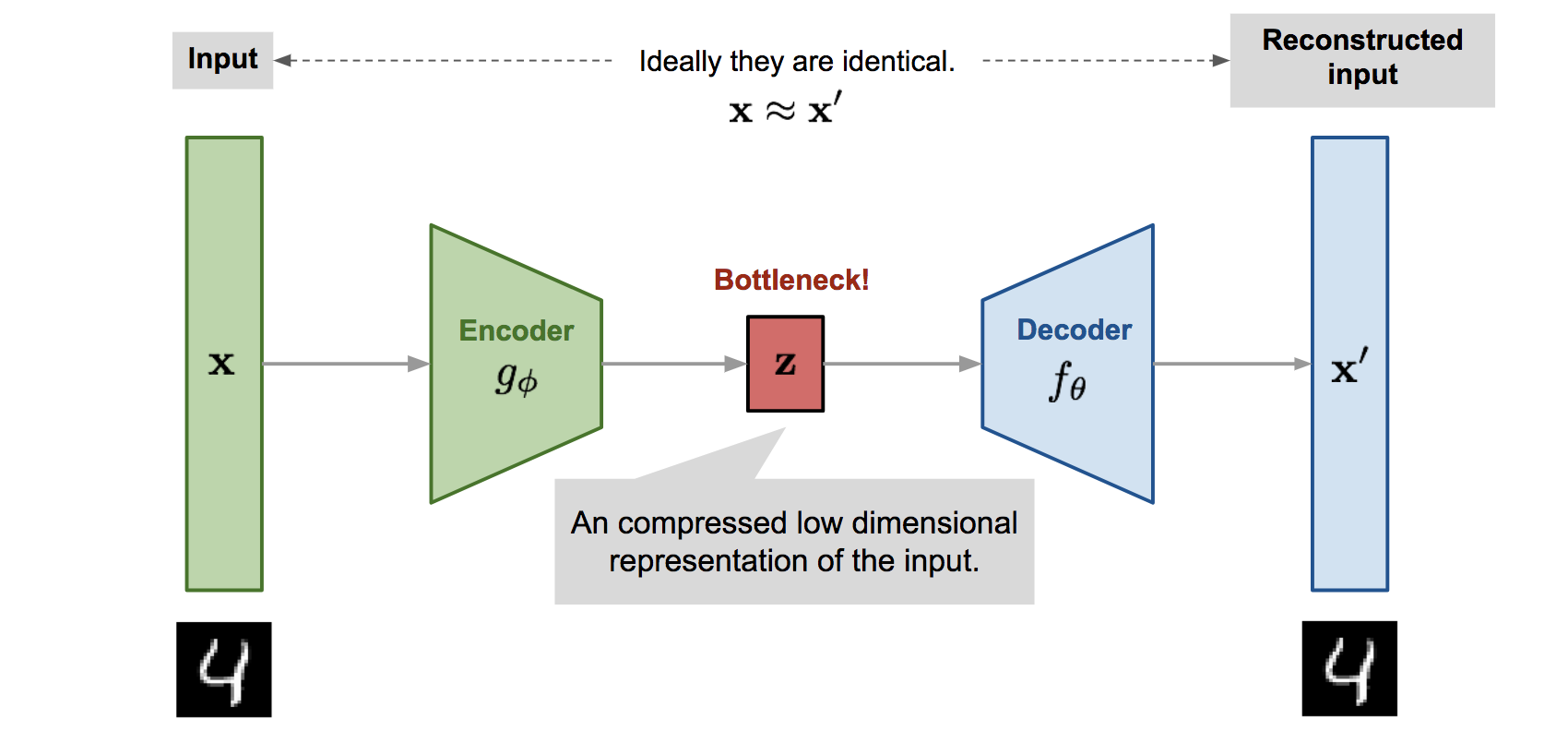
AutoEncoder(AE)
- Unsupervised Learning
- Nonlinear Dimensionality Reduction(= Feature Extraction, Manifold Learning)
- Generative Model Learning
- ML Density Estimation
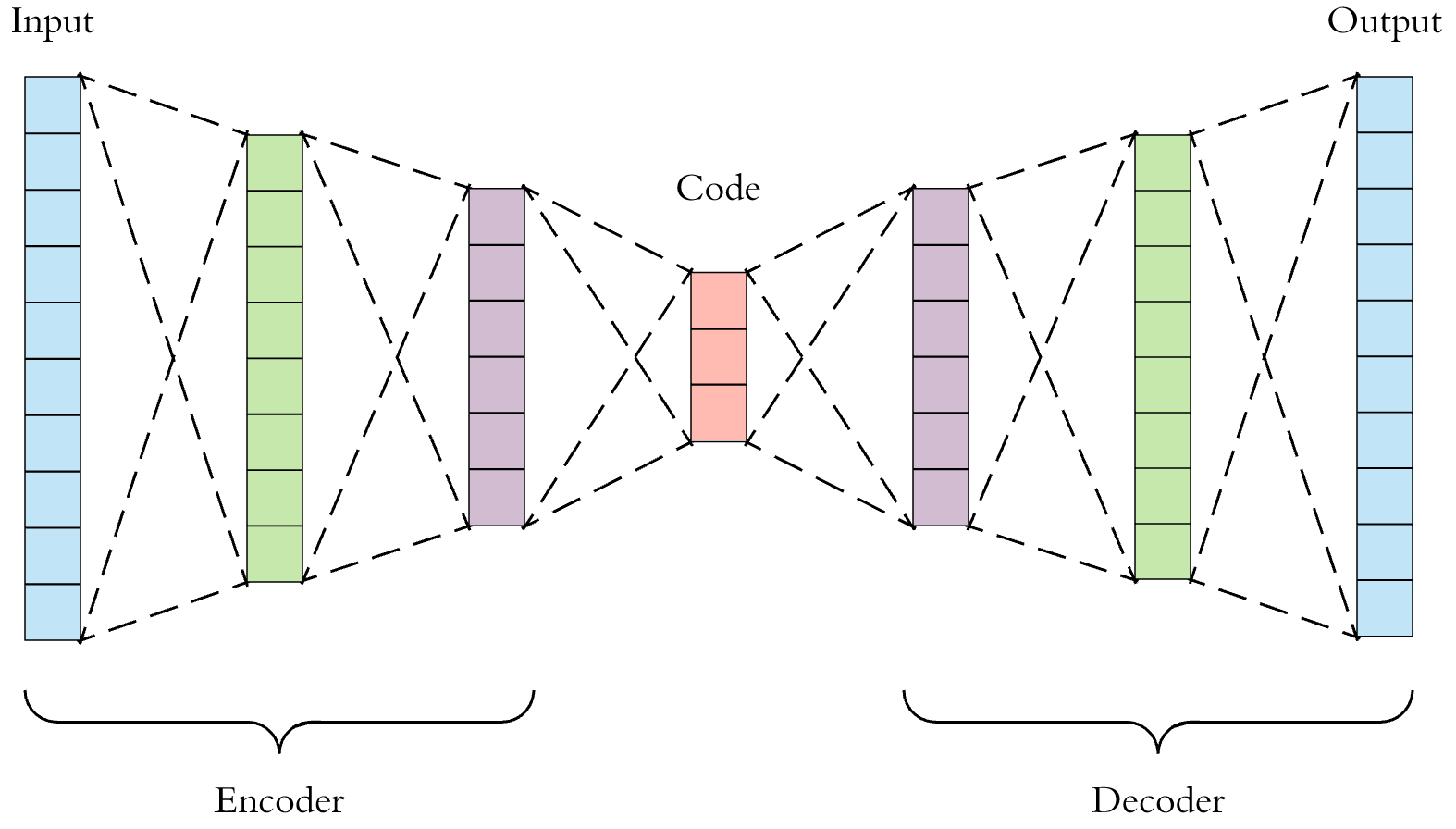
1. AutoEncoder(AE)
출처: https://gaussian37.github.io/dl-concept-autoencoder2/
Input과 Output이 똑같이 설정된 비지도학습 신경망 모델(Unsupervised -> Supervised)
- Hidden Layer 앞부분을 인코더(Encoder), 뒷부분을 디코더(Decoder)
- 인코더는 차원 축소(Manifold Learning), 디코더는 생성 모델(Generative model Learning) 역할 수행
- Input Data를 잠재공간(Latent Space)에 압축시켜 새로운 Feature로 사용
- Feature Extraction의 일종
- Dimension을 줄일 수 있다는 장점
- 데이터를 원래의 데이터로 잘 복원하도록 학습
- 잘 복원된다면 Feature로서의 의미가 더 클 것
- Input 데이터를 잘 표현하는 weight 학습
- Activation Function 없이 사용하는 AutoEncoder은 Linear AutoEncoder(PCA와 같은 manifold)
- Linear AutoEncoder의 Loss를 MSE로 하면 PCA와 동일한 subspace(manifold)를 배움
- reconstruction error 사용(mse or cee)
2. Stacked AutoEncoder(SAE)

출처: https://www.hindawi.com/journals/mpe/2018/5105709/
AE를 쌓아올린 모델
1) Input Data로 AE1을 학습(tied 방식 사용- input과 output weight 동일하게)
2) 1)에서 학습된 모형의 Hidden Layer을 Input으로(AE1의 weight 고정) 해 AE2를 학습
3) 2) 과정을 원하는 만큼 반복
4) 1)~3) 과정에서 학습된 Hidden Layer을 쌓아 올림
5) 마지막 Layer에 Classification의 기능이 있는 Output Layer를 추가 (ex. softmax)
6) Fine-tuning
- Initialization 방법이 없을 때 AE의 이러한 특성을 활용해 모델 초기화에 많이 사용
3. Denoising AutoEncoder(DAE)
Robust(강건한)한 Feature을 만들기 위한 AE
- Robust: 학습해보지 않은 데이터라 하더라도 잘 분류하는 것
- Input에 약간의 Noise 추가해 학습
- Input = x+noise, Output = x
- 사람이 데이터에 대해 같다고 생각할 만큼의 noise 추가
- noise 추가해도 manifold상에서 똑같은 곳에 분포
- AE보다 CNN에서 Edge Detector가 더 잘 작동한다.
4. Stacked Denoising AutoEncoder(SDAE)
SAE에서 AE를 DAE로 대체한 모형
5. Stochastic Contractive AutoEncoder(SCAE)
: Reconstruction Error
: Stochastic Regularization
- Noise를 추가해도 의미적으로 같지만 원래 공간에서 다른 애들을 만든다.
- manifold 상에서 같은 위치상에 위치하게 regularization을 넣음
6. Contractive AutoEncoder(CAE)
SCAE에 Taylor Expansion을 사용하여 Stochastic이 아닌 Deterministic하게 norm형태로 바꿔 계산
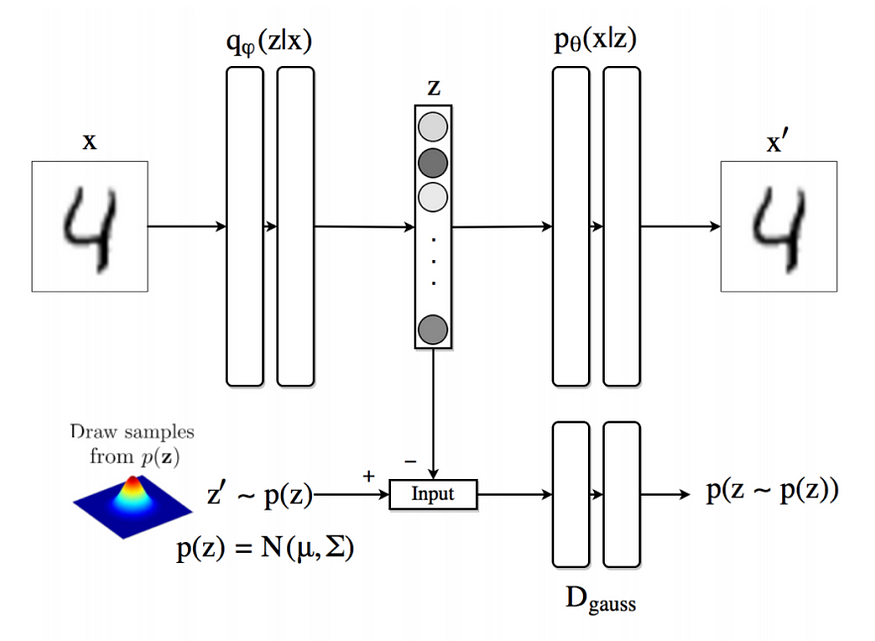
7. Variational AutoEncoder(VAE)
출처: https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html
Generator이 목적(뒷단이 목적 - 앞의 AE와 다름)
-
genetor은 이미지를 만들어 내는 애
-
무작정 만들어내는 것이 아니라 control 할 수 있으면 좋음
-
z는 control하는 역할 control하기 쉬운 분포 사용(normal, uniform 많이 사용)
- z는 prior distribution에서 sampling해서 얻어냄(random variable)
-
network 자체는 deterministic
- : Deterministic function parameterized by
-
-
-
적분 힘드니까 sample 여러개 모아서 monte carlo 방법으로 sum하면 prior distribution 알 수 있다!
- 하지만 실제로는 안된다. VAE사용해야한다.
- x는 train data의 고정된 샘플이다.
- p(x) 값이 높길 바란다.
- 인간에게 비슷한 것들이 mse로 봤을 때는 안 비슷한 것과 보다 더 크다.
- 나와야할 이미지들의 안나오고 의미 없는 이미지들이 나옴
-
x를 보여주고 적어도 이 x는 잘 generate하는 z 만들어 봐. (이상적인 sampling함수 만든다.)
- 이 모르는 확률 분포 추정을 할 때 Variational Inference 방법 사용
- parameter을 잘 바꿔가며 true posterior을 잘 만들어 보자. 이 posterior로 sampling
-
를 사용하여 구함
- KL은 확률 분포 간의 거리를 구하는 함수()
- KL을 좌변으로 넘기면 ELBO는 보다 작거나 크게된다.
- KL을 minimize하면 되는데, 이를 위해서는 ELBO를 최대화하면 됨.
- ELBO를 최대화하는 를 구하면 됨
-
ELBO를 최대화하는 를 구하는 것은 이상적인 sampling 함수를 찾는 과정
-
maximum likelihood를 구한다.(학습)
-
generator 학습을 하고 싶다. prior에서 sampling하니까 잘 안돼. 그래서 이상적인 함수에서 sampling. x를 evidence로 주고 x로 잘 generate하는 z를 sampling하는 도입.
-
거기서 sampling해서 z를 구한 다음 x 나올 확률을 maximize한다.
-
하다보니 x가 입력으로 들어가서 sampling하고 나오는 값이 x가 되었다. AE가 되어버렸다.
-
수학적으로 보면 기존 AE와 VAE는 관련이 없다.
-
샘플링용 함수에 대한 NLL + 샘플링의 용이성과 통제성을 위한 조건을 prior에 부여하고 이와 유사해야 한다는 조건 부여
-
사실상 일단 AE와 다른 점은 Loss에 KL term이 붙는다는 정도(그 앞은 AE와 동일)
- AE는 데이터 압축이 목적
- VAE는 데이터 생성이 목적: prior를 잘 해석하는 generator가 함께 학습
8. Conditional Variational AutoEncoder(CVAE)

출처: https://ratsgo.github.io/generative%20model/2018/01/28/VAEs/
- manifold 학습할 때 label 정보 안썼는데 학습이 됐다.
- VAE에 그 label 정보 사용하는 것이 CVAE
- label 정보를 알고 있으면 encoder, decoder에 모두 사용
- label을 일부만 알고 있는 경우, 모를 경우에는 label을 추정하는 별도의 network를 두면 됨. 그리고 추정한 label 사용(semi-supervised)
9. Adversarial AutoEncoder(AAE)
https://medium.com/vitrox-publication/adversarial-auto-encoder-aae-a3fc86f71758
- VAE는 Decoder의 분포만 바꿨다.
- Encoder의 분포를 바꾸지 못한 이유는 KL term을 계산하기 어렵기 때문
- 이 한계를 극복하기 위한 노력이 AAE
- KL 조건
- sampling 되어야 함
- KL divergence가 계산가능해야함
- AAE는 sampling은 가능하지만 KL divergence 계산은 불가능한 함수를 써보자.
- KL 대신 GAN Loss 쓰면 가능하다.
- GAN(Generative Adversarial Network)
- VAE는 density를 정하고 가는데, GAN은 정하지 않고 간다.
- generator에서 가짜 데이터를 만들고 가짜와 진짜 데이터를 discriminator에서 구별한다.
- generator은 discriminator을 속이려고 노력하고, discriminator은 구별하려고 노력(학습)
- generator와 discriminator의 목적이 적대적(정반대)이므로 advesarial이다.
- generator에서 만든 sample들이 실제 data의 분포를 따라가게 만듦
- discriminator을 두고 학습 진행
- 학습 과정
- Update AE
- Update Discriminator
- Update Generator
- manifold를 우리가 원하는 대로 만들 수 있다.(기존에는 normal distribution만 됐다.)
AutoEncoder 실습코드
# AutoEncoder 모델링
class AE(torch.nn.Module): # nn.Module 클래스를 상속받는 AE 클래스 정의(함수 그대로 이용 가능)
def __init__(self): # 인스턴스 생성 시 지니게 되는 성질 정의
super(AE, self).__init__() # nn.Module 내의 메소드 상속받아 이용
self.encoder = nn.Sequential(
torch.nn.linear(28*28, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 32)
)
self.decoder = nn.Sequential(
torch.nn.Linear(32, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 512),
torch.nn.ReLU()
torch.nn.Linear(512, 28*28)
)
def forward(self, x):
encoded = self.encoder(x) # latent variable vector 생성
decoded = self.decoder(encoded)
return encoded, decoded
# Optimizer&Criterion
model = AE.to(device)
optimizer = torch.optim.Adam(model.parameters, lr = 0.001)
criterion = nn.MSELoss()
# train, evaluate 함수
def train(model, train_loader, optimizer, log_interval):
model.train()
for batch_idx, (image, _) in enumerate(train_loader):
image = image.view(-1, 28*28).to(device)
target = image.view(-1, 28*28).to(device)
optimizer.zero_grad() # 기울기 초기화
encoded, decoded = model.forward(image) # 모델 계산
loss = criterion(decoded, target) # loss 계산
loss.backward() # 역전파법
optimizer.step() # 파라미터 업데이트
if batch_idx % log_interval == 0:
print(f'Train Epoch: {epoch},\tTrain Loss: {loss.item()}')
def evaluate(model, test_loader):
model.eval()
test_loss = 0
real_image = {}
gen_image = {}
with torch.no_grad(): # 파라미터 값 고정(학습되지 않도록)
for image, _ in test_loader:
image = image.view(-1, 28*28).to(device)
taget = image.veiw(-1, 28*28).to(device)
encoded, decoded = model(image)
test_loss += criterion(decoded, image).item()
real_image.append(image.to('cpu'))
gen_image.append(image.to('cpu'))
test_loss /= len(test_loader.dataset)
return test_loss, real_image, gen_image
# 모델 학습
for epoch in range(1, epochs+1):
train(model, train_loader, optimizer, 200)
test_loss, real_image, gen_image = evaluate(model, test_loader)
print(f'\nEpoch: {epoch},\tTest Loss: {test_loss}')
f, a = plt.subplots(2,10, figsize=(10,4))
for i in range(10):
img = np.reshape(real_image[0][i],(28,28))
a[0][i].imshow(img, cmap = 'gray_r')
a[0][i].set_xticks(())
a[0][i].set_yticks(())
for i in range(10):
img = np.reshape(gen_image[0][i],(28,28))
a[1][i].imshow(img, cmap = 'gray_r')
a[1][i].set_xticks(())
a[1][i].set_yticks(())
plt.show()참고
파이썬 딥러닝 파이토치 (이경택, 방성수, 안상준)
https://www.youtube.com/watch?v=o_peo6U7IRM
https://www.youtube.com/watch?v=rNh2CrTFpm4
