지속가능한 서비스로 개선하기✔
이번 포스트에서는 어플리케이션 단에서 서비스 이해도를 바탕으로 아키텍처를 개선하여 성능 향상을 이뤄보고자 한다. 또한 기존 개선 방안(병렬 처리)과 비교하여 어떠한 기대효과를 가져왔는 지 비교해보자.
목표
유저 시나리오에서의 병목 현상을 해결하고 트래픽의 증가에 대응할 수 있는 지속가능한 서비스로 개선한다.
소개
개선에 앞서 포스트를 보는 이의 이해도를 살짝 올리기 위해 개발하고 있는 서비스와 문제 상황를 간단하게 소개하겠다. 필자는 회사에서 채용사이트 & 빌더 서비스를 맡아 백엔드 개발을 진행하고 있다.
채용사이트 & 빌더
- 기업만의 채용사이트를 만들고 관리할 수 있다.
- 기업은
디자인이라는 개성 넘치는 채용사이트 폼을 생성하고 꾸민다. - 특정 디자인을
게시하면 기업 도메인을 통해 취업준비생들이 인사담당자가 만든 채용사이트에 접근 가능하다.
유스케이스(Use Case) 다이어그램
여러 기능들이 있지만 앞으로 볼 문제에 필요한 흐름만 간단하게 표현해봤다.
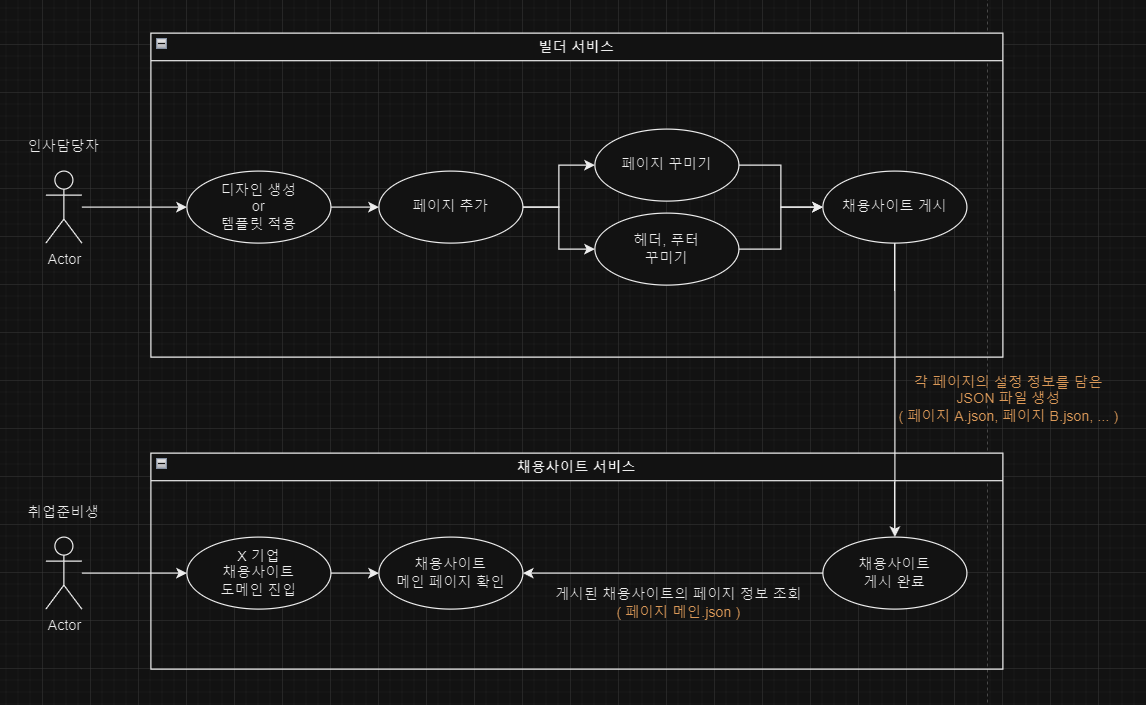
가장 집중해야 할 부분은 채용사이트 게시 시 각각의 페이지 정보를 JSON 파일로 저장하여 캐싱의 역할이 될 수 있도록 구현하였다.
취준생들이 기업의 채용사이트에 접근했을 때는 라우팅된 페이지의 정보(헤더, 푸터, 바디)가 담긴 JSON 파일 1개만 가져와 렌더링한다.
문제 상황
위의 유저 시나리오에서 채용사이트 게시하는 부분에서 병목이 발생한다.
대부분의 디자인들은 약 6개 정도의 페이지를 갖고 있다. 게시 단계에서 6개의 JSON 파일을 만드는 데는 큰 성능의 문제는 없었다. 하지만 Worst-Case에서는 페이지의 개수가 한없이 늘었났을 때는 확실하게 문제가 된다.
현재 페이지의 개수 제한은 81개이다.
게시 API의 Response Time
Worst-Case 페이지 81개 기준에서 성능 체크를 진행하였다. 페이지의 내용물에 따라 성능에 영향을 미치기 때문에 템플릿에 있는 페이지의 내용물로 고정하여 측정하였기 때문에 고려하지 않아도 된다.
A. 페이지 81개의 JSON 파일을 싱글 스레드에서 생성

싱글 스레드에서 순차적으로 DB 조회 후 JSON 파일을 업로드하였다. 한 번의 API 요청에 의해 9분 동안 서버 자원을 점유하였고 유저 대기함으로서 시나리오가 망가졌다고 볼 수 있다. 사용 불가.
B. 페이지당 1 Thread로 병렬 처리
기존에는 1차 개선 방안으로 CompletableFuture를 사용하여 병렬 처리하여 사용해왔다.
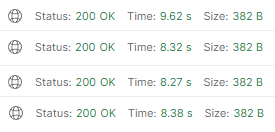
평균 8.64s의 응답시간이 측정되었다. 최대 81개의 페이지를 만든다는 부분을 고려하면 나쁘지 않을 수도 있다.
어플리케이션의 커넥션과 스레드는 괜찮은가? 전혀 그렇지 않다. 커넥션풀이 감당하지 못해 간헐적으로 Timeout을 발생시켰다. (사용 가능한 환경과 비용에 따라 설정이 다르겠지만)
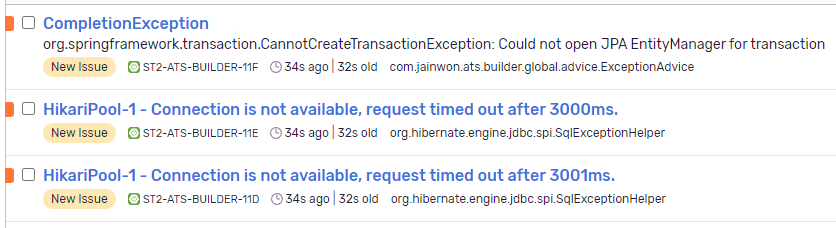
그렇다고 2 페이지당 1 Thread로 변경하면 응답시간은 비례해서 증가할 것이다.
병렬 처리의 한계
1차 개선을 진행하면서 가장 크게 와닿은 점이 있었다.
Q. 지금의 아키텍처는 트래픽 증가 시에 대응할 수 있는가?
대량의 페이지를 가진 유저가 동일 시점에 채용사이트 게시 요청을 진행하면 처리되지 못하는 것이 분명했다.
트래픽이 증가할 때마다 서버 자원(커넥션, 스레드)의 증가는 어찌보면 당연할 수 있고 비용을 더 사용하여 처리량을 늘리는 방안도 있다. 하지만, 비용적인 측면은 항상 제한이 된다. 무제한 처리량을 늘릴 수 있는 것도 아니다.
가장 결정적인 부분은 대부분이 유저가 사용하는 페이지 개수와 Peek치에 대해서도 10배를 초과하고 있다. 편차가 커서 일부의 유저를 위해 사용하지 않는 대부분의 시간동안 자원들을 과하게 점유하게 된다.
동시 요청 시에 자원 점유를 위한 대기를 진행하게 되고 응답시간에 직결된다.
동시 요청 TEST
| 동시 요청 수 | Response Time |
|---|---|
| 1번 | 8.64s |
| 3번 | 13.32s |
| 10번 | 35.08s |
| 15번 | 1m 3.72s |
현재는 1m을 넘어갈 시 504 Gateway Timeout이 발생하고 유저에겐 이상현상에 대한 안내창이 나가고 있다.
중간 회고
병렬 처리는 필요한 부분에선 필요하고 효율적인 선택지는 맞다. 하지만 8.64s도 이미 개선이 필요한 상태이고 30s 이상에 대해서는 사용 불가하다고 느꼈다.
병렬 처리를 고집하고 작업량이 많으니 당연한 결과라고 생각하기에는 내 프로젝트의 한계를 내가 제한하고 있다는 생각이 문득 들었다.
제 프로젝트는 100명까지 밖에 사용 못해요... 천천히 사용해주세요. 말도 안된다.
아키텍처 개선 >>> 병렬 처리
가장 병목이 발생하는 지점은 채용사이트 게시 단계이다. 결과를 먼저 언급하면 병목 지점에서의 처리량을 유저 시나리오 전반에 걸쳐 분산하기로 했다.
JSON 파일 생성 시점을 모든 시나리오에서 생성한다.
JSON 파일 81개를 반드시 동일 시점에 생성해야 하는가? 지금의 형상으로는 할 수 밖에 없었다.
1. 처리량이 집중되는 원인을 찾자.
// 참고: 1개 페이지 의 JSON 파일 내부 구조
{
"header": {...},
"footer": {...},
"logo": {...},
"body": {...}
}
- 채용사이트를 게시 한다.
- 디자인을 추가적으로 꾸미면 실시간으로 채용사이트에 반영되어야 한다.
- 꾸미는 페이지는 `헤더` + `바디` + `푸터` + `...`로 이루어진다.
- 헤더, 푸터 정보는 모든 페이지가 동일하다.
- 1개의 페이지에서 헤더가 변경되면 모든 페이지에 실시간 반영되어야 한다.
- 때문에 81개의 페이지를 모두 재생성한다.2. JSON 구조를 분리하자.
공통 객체인 header, footer 등을 HEAD.json 으로 분리하고 body 부분만을 BODY.json으로 분리했다.
// BODY.json
{
"body": {...}
}
// HEAD.json
{
"header": {...},
"footer": {...},
"logo": {...}
}3. JSON 파일 생성 시점 추가
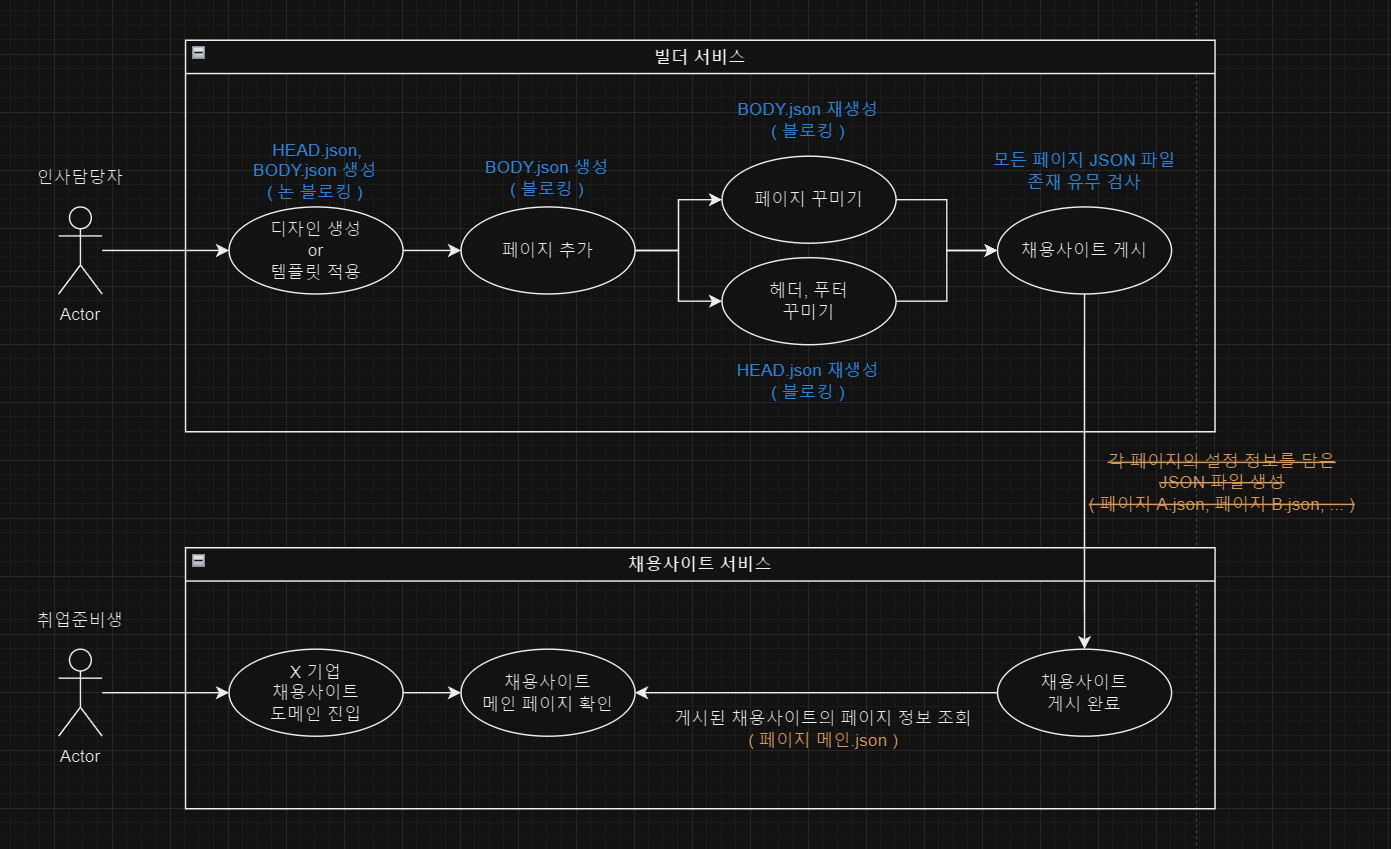
변경점은 간단하다. 유저 시나리오를 분석하여 JSON 파일의 생성 시점을 분기한다. 결과적으로 병목이 발생했던 채용사이트 게시 단계에서는 파일의 존재 유무만 검사한다. 정상 시나리오에서는 병목 없이 즉시 게시될 것이다.
유저의 대기 시간을 최소화 했기 때문에 유저 경험 또한 긍정적일 것이다.
✨성능 TEST
반드시 검토해야할 부분은 3가지가 있다.
- 병목 지점의 응답시간는 개선되었는가?
- 증가한 파일 생성 시점으로 인해 기존 API들의 응답시간 증가는 유저에게 불편함을 주는가?
- 서버에서 필요한 자원(커넥션, 스레드)의 편차는 줄었는가?
병목 지점의 Response Time 개선
기존의 유저 시나리오에서 긴 응답시간을 갖던 시점들은 모두 급격하게 감소된 모습을 보인다. 병목 현상은 사라졌고 전체 시나리오에서 응답속도의 낮은 편차를 기반으로 유저는 막힘 없이 서비스를 이용할 수 있다.
| API | Before | After |
|---|---|---|
| 채용사이트 게시 | 8.64s | 20ms |
| 게시 상태에서의 추가 변경 | 9.46s | 1s |
기존 API의 Response Time 비교
아래의 API들은 기존과 비교하여 HEAD 또는 HEAD, BODY 에 대한 JSON 파일을 만들고 S3에 업로드 하는 과정이 추가되기 때문에 응답시간의 증가가 예상된다.
실제로 50ms~150ms 정도의 증가가 확인되지만, 유저가 변화를 인지하고 불편함을 초래하는 수준은 아닌 것으로 판단된다.
도허티 임계 (Doherty threshold)
"사용자의 주의가 분산되는 것을 막고 생산성을 높이려면 시스템의 반응은 0.4초 이내에 이루어져야 한다."
응답속도 비교
| API | Before | After |
|---|---|---|
| 페이지 복제 | 1.33s | 1.41s |
| 페이지 순서 이동 | 48ms | 85ms |
| 메인 페이지 변경 | 43.5ms | 115.5ms |
| 페이지 생성 | 42ms | 176.7ms |
| 페이지 수정 | 40.7ms | 145.ms |
자원 편차
서버에서는 더이상 10배가 넘는 Peek치를 대응하지 않는다. 편차를 줄였다는 것은 어플리케이션의 커넥션과 스레드가 특정 시점에 치솟는 현상이 사라지고 필요한 자원의 수를 활성 유저(DAU)와 비례해서 적절하게 조율할 수 있음을 의미한다.
즉, 대기 상태의 자원들을 확실하게 감소시킬 수 있었다.
불필요한 JSON 파일
예상대로 기존보다 많은 S3 오브젝트들을 생성하다보니 관리의 필요성이 높아진다.
얼마전에 포스팅한 글로 관리에 대한 문제를 해결했으니 참고하길 바란다.
🎁 기대효과 및 회고
이번 개선은 서비스에 큰 변화를 가져왔다고 생각한다. 작은 변경점에서 시작했지만 유저 시나리오 전반에 대한 개선이 이루어졌다. 유저의 불편함을 야기하던 대기시간 또한 확연하게 줄었다.
추가적인 기대효과로 최대 81개의 페이지의 제한을 없앨 수 있다. 성능상의 이슈 때문에 유저의 기능을 제한하던 부분을 없애고 온전히 UX의 관점에서만 고려할 수 있게 되었다.
얼마 전에 여러 포스팅을 보다가 다음과 같은 글귀를 봤었다.
"유저 친화적이고 확장성 있는 API 개발"
유저 시나리오를 기반으로 더 많은 트래픽을 처리하고 대응할 수 있는 서비스로 발전시키고자 한다. 10년 넘게 지속 가능하고 확장 가능한 서비스를 만들기 위해.
